基于堆排序的重要關聯規則挖掘算法研究
2016-02-23 12:12:02張永梅
計算機技術與發展 2016年12期
張永梅,許 靜,郭 莎
(北方工業大學 計算機學院,北京 100144)
基于堆排序的重要關聯規則挖掘算法研究
張永梅,許 靜,郭 莎
(北方工業大學 計算機學院,北京 100144)
現有的關聯規則數據挖掘算法或方法中,獲取規則的計算時間很大一部分都耗費在關聯項目集的掃描、數據庫頻繁掃描和生成冗余候選頻繁項目集中。傳統方法雖然得到的挖掘結果比較全面,但并不是所有挖掘結果中的規則都是重要的,以往的方法沒有反映出重要的關聯規則而使得挖掘結果的有效性不高,不利于得到需要的重要目標結果。針對重要目標的挖掘,提出一種基于堆排序及鏈表結構的改進Apriori算法。算法通過掃描數據庫,統計得到各個項目集在所有事務集中出現的頻率,并按照項目集的頻率次數進行堆排序。然后根據建立的堆得到所有k階候選項目集并計算其相對應的支持度,將不同項目集的支持度與預先設定的最小支持度進行比較,若滿足最小支持度,就將對應的頻繁項目集加入鏈表中,否則依據剪枝策略剪去這個對應項,將通過連接運算生成的候選k+1階項目集采用同樣的操作可以生成k+1階頻繁項目集。這樣可以很大程度上優化算法的頻繁項目集的生成過程并加速了重要關聯規則的生成過程,從整體上提高了運算速度。
主要目標;Apriori算法;關聯規則;頻繁項目集;排序
0 引 言
隨著現代技術的飛速發展,知識正在以一種前所未有的方式飛速向前發展,如果還是按照以往的技術去分析所得到的知識,將很難得到所需要有價值的信息,即使能得到,也將會付出很大的代價,而這是所不希望的。
現有的數據挖掘算法及其改進算法,很多都是針對數據的存儲以及數據的結構進行相應優化,雖然能夠在一定程度上提高算法的挖掘效率,但是在一些方面還是不能夠滿足應用上的需求[1],因此改進算法還是有一定的需求。
堆排序是利用樹的一種結構,可以很快得到需要的數據,并且還可以動態調整堆的結構,保持堆排序的正常和維護堆的平衡,是一種具有很高效率的結構。鏈表是一種具有動態分配并且可以動態增長的數據結構,可以根據需要來調整鏈表。文中根據堆排序的結果來選取前n項(這個根據需要調整,比如前20%、前10%等),目的是為了得到重要的關聯規則,并且可以優化頻繁項目集的生成和掃描等操作。
關聯規則挖掘是從大量的事物集中發現事物之間潛在的關聯關系,以發現隱藏在其中的客戶行為模式等[2]。通常頻繁率越高的規則在實際中具有越重要的價值。基于此,文中要挖掘事物之間聯系最密切的關聯規則,即重要關聯規則,以便于發現事物集中最緊密的關聯關系,而不是得到所有與之相聯系的關系,需要的是精確而又有所針對性的關聯關系,這才是日益需要挖掘的結果[3]。
文中提出一種基于堆排序算法以及鏈表相結合的方法[4],以優化頻繁項目集的產生以及生成過程,從而可以快速得到數據挖掘結果。首先算法通過掃描數據庫,統計得到各個項目集在所有事務集中出現的頻率,并按照項目集的頻率次數進行堆排序,然后可以從建立的堆中選取前n項并計算它們的支持度,比較項目集的支持度是否滿足最小支持度。若滿足最小支持度,就將對應的頻繁項目集加入鏈表中,否則依據剪枝策略剪去這個對應項,這樣就可以得到相對應的k階頻繁項目集[5-7]。確定的k階頻繁項目集是從已經生成的頻繁項目集中選取前n項得到的。而k+1階項目集的生成是根據已經確定的k階頻繁項目集進行連接操作而得到的。至于k+1階頻繁項目集則是進行前面相同的操作得到的,而沒有新的項目集生成是終止操作的條件。進行排序操作是為了便于得到前n項,而選取n項是為了縮減頻繁項目集的掃描及生成運算。
1 Apriori算法及其改進
1.1 關聯規則相關概念
關聯規則可以簡單表示為在已有的數據集D中,若由X出現可以得出Y的出現,并且X∩Y=0,則稱X為規則的前提,Y為結果。一般情況下將每一個可能出現的情況稱為一項項目集[8-10]。
(1)支持度:在數據集D中,項目集X的支持度為項目集X出現的總次數除以項目集D上的總次數,即sup(X)=X/D。一般用Minsup表示最小支持度。
(2)頻繁項目集:若項目集X的支持度滿足預先設定的最小支持度,則稱項目集X為頻繁項目集。
1.2 Apriori算法步驟
Apriori算法為了得到所有的頻繁項目集需要對數據集進行多次掃描。算法開始時,為了得到1階項目集,需要對數據集進行第一次掃描,計算支持度并比較計算的支持度是否滿足最小支持度的要求,若滿足就得到了1階頻繁項目集,然后2階項目集是由1階頻繁項目集進行擴展得到的。生成2頻繁項目集的條件是對已經得到的2階項目集需要計算其支持度,而支持度滿足最小支持度的要求。這樣k+1階項目集每次都是由k階頻繁項目集得到的,而通過得到的k+1階項目集又可以確定k+1頻繁項目集,直到滿足結束條件時結束,從而得到所有的頻繁項目集[11-12]。算法流程圖如圖1所示。
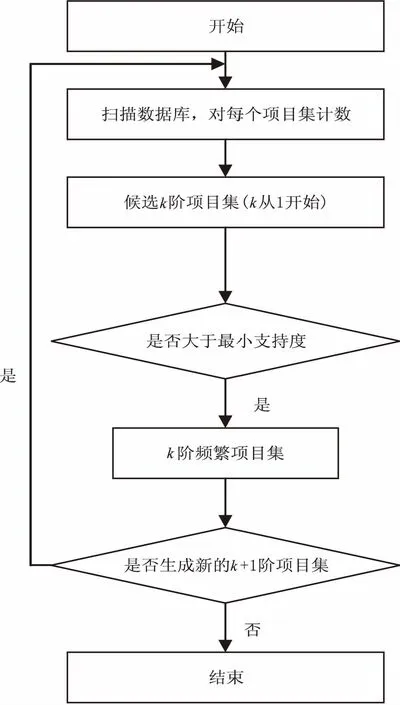
圖1 Apriori算法流程圖
Apriori算法可以通過挖掘數據集得到數據集中的聯系。但是Apriori算法需要重復掃描數據庫,消耗了很多運算時間在數據的掃描上,且在生成每個候選規則時都需要判斷低階項目集是否是頻繁項目集導致大量重復操作,并且由k階頻繁項目集生成k+1階項目集的過程中需要重復比較項目集是否滿足要求,然而滿足要求的項目集需要再次掃描數據集。這是Apriori算法的不足之處。
2 算法的改進及分析
2.1 算法的改進
由于在實際應用的數據庫中是不斷增長的,并且具有不確定性,而且每次掃描數據集都十分浪費資源,不能夠滿足生產和生活的需求,所以文中針對傳統算法的缺點以及應用進行了改進:
(1)標記每一個項目集的數目;
(2)采用基于動態堆排序的方法獲取滿足要求的前n項;
(3)將以后新收集到的數據集加入到已有的結果中,而不用再重新計算。
具體策略為在掃描數據集的過程中,需要標記每一個項目集出現的總數目,并計算該項目集的支持度[13]。若支持度大于預先設定的最小支持度,則對該項目集進行標記并加入隊列,然后進行堆排序(文中采用大堆方式,這樣便于選取前n項以及合并后來的選項)。采用這種方式可以很快地找到滿足要求的頻繁項目集[14],而且對以后收集到新的數據集,如果要加入現有的結果中,也是十分方便的。
2.2 算法改進的步驟
(1)確定n值和最小支持度。這樣可以進行后續的相關操作,否則無法選取數據,進行后續計算。
(2)開始第一次掃描數據集D,標記每一個項目集出現的次數,并進行堆排序。首先從1階項目集的堆排序序列開始,計算1階項目集的支持度并將其支持度與最小支持度進行比較。若大于最小支持度,則加入堆排序隊列,并標記出現的次數,否則將其忽略,進行下一個項目集的掃描和計算,直到完成所有的1階項目集的掃描和計算[15]。根據確定的n值從已經得到的1階頻繁項目集中選取前n項。若得到的1階頻繁項目集數目小于n,則全部加入,否則選取前n項1階頻繁項目集,然后根據1階頻繁項目集生成2階項目集。為了得到2階頻繁項目集需要進行同樣的操作運算[16-17]。
(3)根據上一步確定的k階頻繁項目集產生新的k+1階項目集,計算支持度,然后與最小支持度進行比較,若滿足要求,則進行堆排序。而算法結束的條件是沒有新的頻繁項目集生成。
(4)若在現有的運行條件下又有新的數據集E加入,則只需掃描新加入的數據集E,得到各個新加入的項目集的計數,并將新加入的項目集的計數與原來項目集的計數進行合并,然后比較前n項是否改變。若前n項有所改變,則重新計算該階頻繁項目集,若沒有添加或新增新的項目集到前n項,則該階頻繁項目集是不需要改變的。
(5)綜合上述步驟,可以很快得到頻繁項目集,并且有新的數據集加入時,也可以很快得到結果。
圖2為改進后的算法流程圖。
在算法的執行過程中,主要操作是掃描、排序及比較操作。具體內容如下:
(1)掃描。通過對數據庫的預處理,掃描數據集,標記每一項目集的計數,并對同一長度的項目集進行堆排序,這樣便于查找前n項的項目集,為后續操作提供基礎。
(2)排序。主要是針對同最小支持度比較以后,通過堆排序算法將頻繁項目集進行排序,因為堆排序可以很方便地找到前n項,并且可以很快地調整前n項的順序,便于動態增長和刪除頻繁項目集。
(3)比較。主要包含兩部分:第一部分是項目集的支持度與最小支持度的比較,如果某一項目集的支持度大于最小支持度,則將該項目集加入頻繁項目集的堆排序的序列中,否則,刪減掉該項目集。第二部分是比較新加入的數據集的項目集是否影響已經選取的前n項的頻繁項目集。對新加入的數據集進行統計分析,從1階項目集開始,合并已有的和新加入的1階項目集的數目,看是否影響了前n項的項目集,若更改了前n項,則需對1階頻繁項目集進行調整。對調整后的2階項目集需要進行同樣的操作運算。
經過上面的幾步操作,避免了重復掃描數據集,不僅優化了剪枝方案,而且可以得到重要的關聯規則。
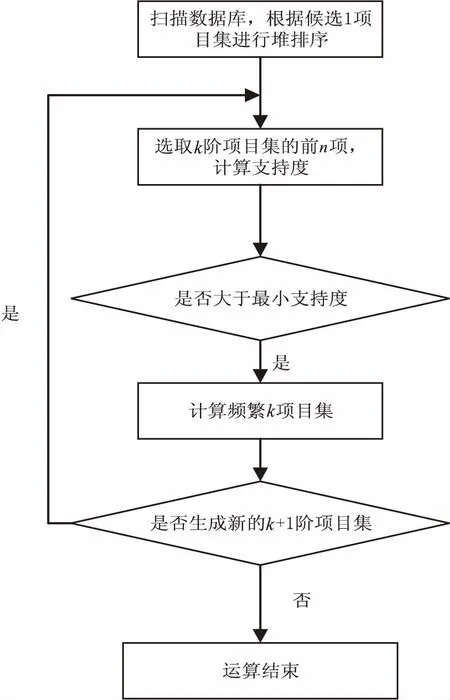
圖2 改進算法的流程圖
3 實驗結果及分析
為了檢驗改進算法效率的提升程度,需要在同樣的實驗條件下,將改進前與改進后的算法進行比較。文中在實驗中采用的是人工模擬隨機產生的數據集。
根據實驗條件選取了一定量的事務集,對改進前后的算法的挖掘結果進行比較,如圖3所示。
從圖中可以很明顯地看出,改進算法的挖掘結果比Apriori算法的結果在頻繁項目集上有所縮減,開始縮減的程度比較高,但是隨著支持度的不斷提高這種差異越來越小。從改進算法所得到的挖掘結果中可以看到,文中所提算法的實驗結果中明顯減少了一些不太重要的關聯規則,降低了結果的冗余性,提高了挖掘結果的有效性。

圖3 運行結果對比圖
為了驗證改進后算法效率的提升程度,將改進前和改進后的算法在挖掘結果的運行時間上進行比較,如圖4所示。
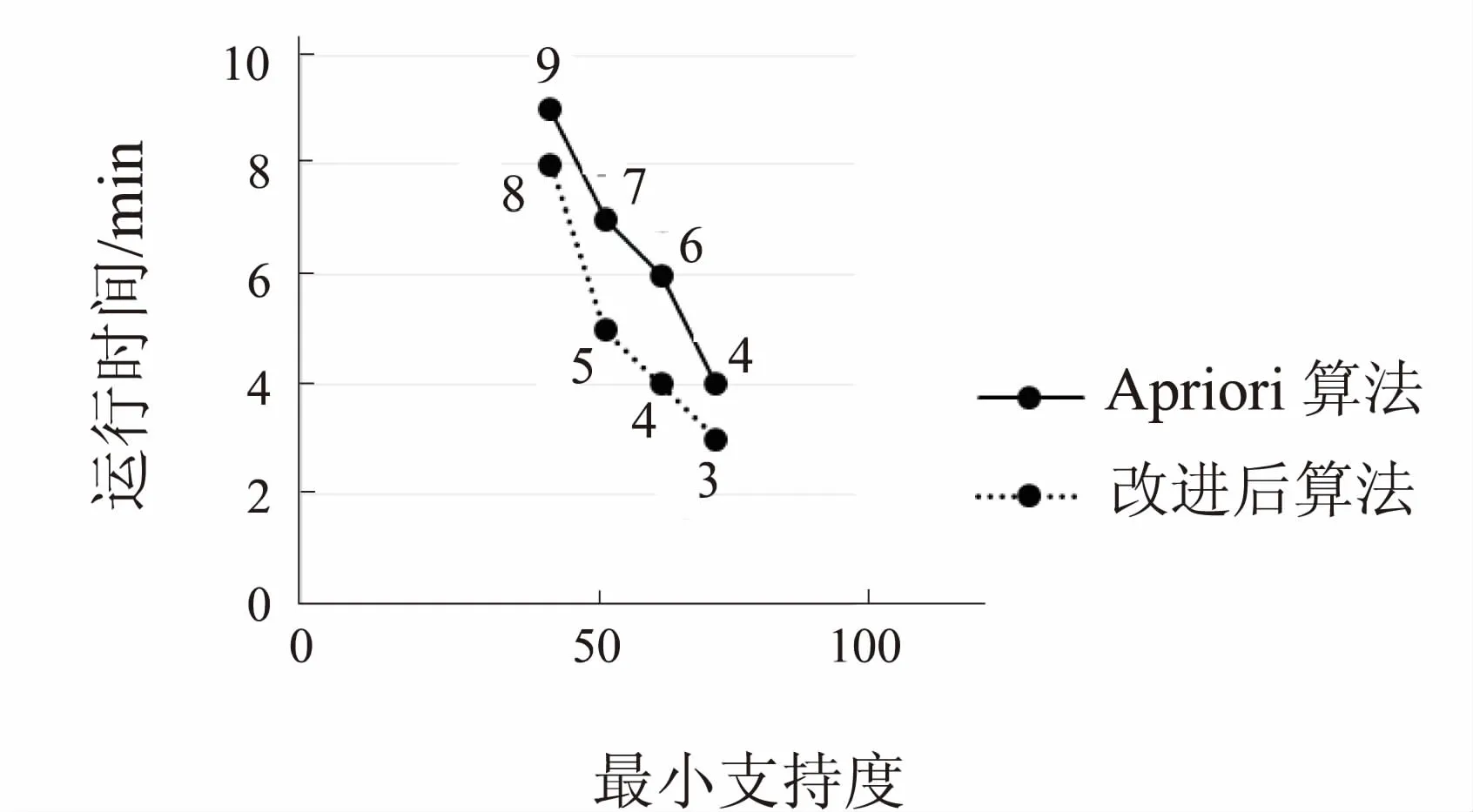
圖4 運行時間對比圖
從結果圖中可以看到,改進后的算法在同樣的最小支持度條件下,開始時時間提高的不是很明顯,但隨著支持度的加大,時間也隨之增長。這就是改進后的方法不用每次掃描數據集的優勢。
4 結束語
對重要關聯規則的挖掘算法進行了研究,采用一種基于堆排序及鏈表結構的改進Apriori算法。雖然Apriori算法是一種經典的關聯規則挖掘算法且在數據挖掘、數據分析及電商平臺等方面應用廣泛,但是存在數據挖掘效率低且難以適用于較大數據量的致命缺陷。通過研究Apriori算法和重要目標關聯規則的特征,結合堆排序的特點并將其應用于規則發現的過程中,優化了數據集的選擇以及生成候選集的運算,同時同剪枝策略的結合也優化了剪枝的過程。另外在一定程度上可以利用已有的挖掘結果,方便將現有的結果
和未來的數據集相結合,能更好地發現重要規則并利用其價值推斷相應的規律等。改進算法在挖掘速度上有了一定的提高,并且數據挖掘的結果有一定的縮減。
[1] 黃紅星.挖掘完全頻繁項集的蟻群算法[J].微電子學與計算機,2014,31(12):144-147.
[2] 馬玉玲.基于clustering算法的事務抽樣關聯規則挖掘算法[J].計算機應用,2015,35(S2):77-79.
[3] 孟海東,李丹丹,吳鵬飛.基于數據場的量化關聯規則挖掘研究與實現[J].計算機應用與軟件,2014,31(7):40-42.
[4] 楊繡丞,李 彤,趙 娜,等.計算排序算法設計與分析[J].計算機應用研究,2014,31(3):658-662.
[5] 鄭 麟.一種直接生成頻繁項集的分治Apriori算法[J].計算機應用與軟件,2014,31(4):297-301.
[6] 陳方健,張明新,楊 昆.一種具有跳躍式前進的Apriori算法[J].計算機應用與軟件,2015,32(3):34-36.
[7] 崔 亮,郭 靜,吳玲達.一種基于動態散列和事務壓縮的關聯規則挖掘算法[J].計算機科學,2015,42(9):41-44.
[8] 羅 丹,李陶深.一種基于壓縮矩陣的Apriori算法改進研究[J].計算機科學,2013,40(12):75-80.
[9] 吳 斌,肖 剛,陸佳煒.基于關聯規則挖掘領域的Apriori算法的優化研究[J].計算機工程與科學,2009,31(6):116-118.
[10] 張 敏,姚良威,侯 宇.基于向量和矩陣的頻繁項集挖掘算法研究[J].計算機工程與設計,2013,34(3):939-943.
[11] 畢 巖,章 韻,徐小龍.基于關系矩陣和頻集樹的關聯規則算法及動態更新算法[J].南京郵電大學學報:自然科學版,2015,35(4):96-103.
[12] 胡維華,馮 偉.基于分解事務矩陣的關聯規則挖掘算法[J].計算機應用,2014,34(S2):113-116.
[13]HuangYF,LaiCJ.Integratingfrequentpatternclusteringandbranch-and-boundapproachesfordatapartitioning[J].InformationSciences,2016,328:288-301.
[14]FerrerU.ThemultipleaprioriofsocialactsinAdolfReinach[J].LosmúltipleaprioridelosactossocialesenAdolfReinach,2015,49:209-230.
[15]QinShanshan,LiuFeng,WangChen.Spatial-temporalanalysisandprojectionofextremeparticulatematter(PM10andPM2.5)levelsusingassociationrules:acasestudyoftheJing-Jin-Jiregion,China[J].AtmosphericEnvironment,2015,120:339-350.
[16]KhaliliA,SamiA.SysDetect:asystematicapproachtocriticalstatedeterminationforindustrialintrusiondetectionsystemsusingApriorialgorithm[J].JournalofProcessControl,2015,32:154-160.
[17]LinJC,GanWensheng,HongTP.Efficientalgorithmsforminingup-to-datehigh-utilitypatterns[J].AdvancedEngineeringInformatics,2015,29(3):648-661.
Research on Association Rules Mining Algorithm for Main Target
ZHANG Yong-mei,XU Jing,GUO Sha
(School of Computer Science,North China University of Technology,Beijing 100144,China)
The existing association rule mining algorithms or methods waste most of their time on the correlation set database scanning,the frequent scanning and the generating of redundant frequent itemsets candidates during their rule acquisition computation.The traditional methods can get more comprehensive mining results,but not all of the rules that came from the mining result are important.Traditional methods don’t reflect the importance of association rules so as to have inefficiency for mining results,and they are not conducive to the gaining of main target results.Aimed at the mining of important goal,an improved Apriori algorithm based on linked list structure and heap sort is proposed.The algorithm scans the whole database to get the frequency of the appearance of each item set among the whole datasets and do the heap sort.Then,according to the established heap,all thekrankcandidatesetsareobtainedandtherelativesupportiscalculated.Thesupportdegreeofdifferentprojectsetsiscomparedwiththeminimumsupportdegree.Iftheminimumsupportismet,thecorrespondingfrequentitemsetshouldbeaddedtothelist,oritshouldbecutaccordingtotheshearorpruningstrategy.Byconnectingoperation,thecandidatek+1orderitemsetcanbeobtainedfromthegeneratedkorderfrequentitemsets,sotogeneratethek+1orderfrequentitemsets.Inthisway,thegenerationoffrequentitemsetscanbegreatlyimproved,andtheminingresultsofimportantassociationrulescanbeprovided,whichcanimprovethespeedofoperation.
main target;Apriori algorithm;association rules;frequent itemsets;sorting
2016-02-01
2016-06-02
時間:2016-11-22
國家自然科學基金資助項目(61371143);北京市自然科學基金項目(4132026)
張永梅(1967-),女,教授,碩士研究生導師,CCF會員,研究方向為圖像處理、人工智能、數據挖掘;許 靜(1990-),男,碩士研究生,研究方向為圖像處理、數據挖掘。
http://www.cnki.net/kcms/detail/61.1450.TP.20161122.1227.002.html
TP
A
1673-629X(2016)12-0045-04
10.3969/j.issn.1673-629X.2016.12.010
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
信息通信技術(2015年6期)2015-12-26 01:16:46
