基于美食互動社區的用戶飲食行為模型研究
2016-02-23 12:12:08李越,曹菡
計算機技術與發展 2016年12期
李 越,曹 菡
(陜西師范大學 計算機科學學院,陜西 西安 710062)
基于美食互動社區的用戶飲食行為模型研究
李 越,曹 菡
(陜西師范大學 計算機科學學院,陜西 西安 710062)
隨著大數據、“互聯網+”時代的到來,互聯網美食互動社區的用戶原創內容呈爆發式增長,從海量飲食數據中發現自己希望尋找的內容越來越不容易,同時該部分數據沒有得到廣泛的利用和深度的挖掘;傳統的對于飲食行為的研究多采用問卷調查等形式,耗費了大量人力、物力、財力。針對以上問題,提出了基于LDA的用戶飲食行為模型:利用LDA模型的思想,分析互聯網美食互動社區的用戶原創內容,根據困惑度確定主題數,構建用戶飲食行為模型,進而可以計算用戶飲食行為相似度,以此為美食社區用戶進行好友和美食推薦提供模型基礎,同時為飲食行為研究提供了一個新思路。以爬蟲技術獲取互聯網美食互動社區上的用戶原創內容作為數據集,通過實驗驗證了這種算法的可行性和有效性。
飲食行為;美食互動社區;用戶模型;數據挖掘;LDA模型
0 引 言
隨著人民生活水平的不斷提高,吃飽已經不能滿足人們對飲食的需求,人們開始追求飲食的美味與健康。隨著互聯網技術和新的媒體形式的崛起,美食作為生活化互聯網的一項服務,逐漸和網絡社區結合成一種互聯網美食經濟產業鏈,由此催生的美食互動網站的設計和運營也變得越來越熱門[1]。美食互動社區的快速成長與發展是互聯網持續向社會生活滲透的寫照之一,為人們獲取更多關于飲食方面的信息提供了支撐,為美食愛好者提供了一個在線交流平臺。人們通過美食互動社區發現、分享和交流美食。美食互動社區是典型的用戶原創內容(User Generated Content,UGC)社區,其中80%的內容來自于用戶。人們在網絡中發布菜譜等這些線上行為一定程度上反映了用戶線下的飲食行為習慣,這部分數據如果能得到充分的利用和挖掘,對于飲食行為干預[2]、疾病預防和控制[3]、食品推薦等問題的解決將起到很大的幫助。
傳統的飲食行為研究方法通常是采用膳食調查[4]的方法,通過問卷及24小時食物記錄表[5]的方式進行,耗費大量的人力物力不說,對于食物攝入量測量、食物成分多樣性等復雜問題也得不到有效解決;第二類是對研究對象的調查,需要對研究對象進行跟蹤記錄,需要研究對象的主動參與。但上述方法均忽略了用戶在互聯網上留下的信息。
文中對美食社區數據進行統計分析,然后利用LDA模型構建用戶飲食行為模型,以此模型為基礎計算用戶的相似度,為美食社區用戶推薦和食品推薦提供模型基礎。
1 LDA模型的基本思想
LDA(Latent Dirichlet Allocation)是目前應用最廣泛的隱主題模型[6],具有扎實的概率基礎和可靠的擴展性,被廣泛應用于文本建模的各個領域。LDA是一個三層(文檔-主題-詞)貝葉斯模型,圖1為LDA圖模型表示。將文檔表示成隱主題上的分布,而每個主題又表示成詞的分布。
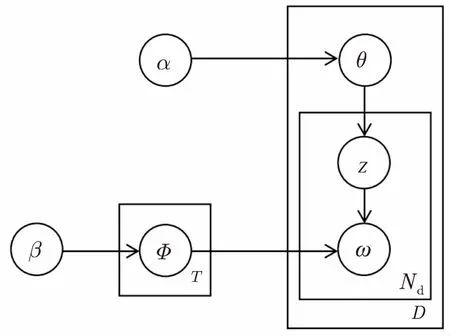
圖1 LDA的圖模型表示
其中,LDA模型采用Dirichlet分布作為概率主題模型中多項分布的先驗分布。D為整個文檔集,Nd為文檔d的單詞集,α和β分別為文檔-主題概率分布θ和主題-單詞概率分布Φ的先驗知識,Τ為隱主題數。
2 基于LDA模型的用戶飲食行為模型研究
2.1 基于LDA模型的用戶飲食行為模型
文中借助于LDA模型的思想,構建用戶飲食行為模型(Author-Eating Behavior Model)將原本的文檔建模推廣到用戶飲食行為建模之上。假設數據集中的每個用戶對應一個隱飲食行為的分布,而隱飲食行為則同樣由菜譜屬性詞的分布表示。
使用LDA模型構建用戶飲食行為模型時,需要將一個用戶下的所有菜譜合并成一個文檔進行飲食行為生成,從而得到用戶飲食行為的概率多項分布,即用戶的飲食行為模型。該模型將文檔-主題-詞的三層關系變成了用戶-飲食行為-詞的關系。

其中,pzk,v為給定飲食行為z時生成詞w的概率。
2.2 用戶飲食行為相似性計算
相似用戶具有相近的飲食行為。計算用戶間的相似度,可以將其應用于美食社區進行用戶和食品的推薦。
KL(Kullback Leibler)散度,俗稱KL距離[7],常用來衡量兩個概率分布的距離,其計算公式如下:

(1)
KL散度是不對稱的,即:
DKL(P‖Q)≠DKL(Q‖P)
(2)
可以將其轉換為對稱的,如下所示:
D(P,Q)=[DKL(P‖Q)+DKL(Q‖P)]/2
(3)
在基于LDA的用戶飲食行為模型中,如用戶主題矩陣所示,用戶間的相似程度可以由各用戶飲食行為分布之間的KL距離表示,用戶相似度計算如下所示:
(4)
其中,sij為用戶ui和uj的相似度;Ui和Uj分別是他們的飲食行為概率分布。sij越大,表示兩個用戶越相似。
3 實驗結果與分析
3.1 實驗準備
應用爬蟲技術,從某美食互動社區網站上隨機獲取2014年4月到2015年3月期間6 834篇美食博客數據,數據概要如表1所示。
通過統計分析發現:
(1)工藝為“炒”的菜譜最多,占總數的24.5%,其次為“煮”,占16.4%,“拌”占12%。在中國,大部分家庭蔬菜烹飪以炒菜為主[8],數據統計符合中國人的傳統飲食習慣。
(2)最多食類主料依次為豬肉、雞蛋、面粉、胡蘿卜、土豆、蝦、大米、西紅柿、豆腐、木耳、青椒、洋蔥、牛奶、低筋面粉、香菇。均為日常生活中常見食材,便于獲取,烹飪簡單。
(3)“兩人份”菜譜占49.2%,“三人份”菜譜占25%。與中國家庭結構吻合。

表1 數據概要
(4)準備時間在“15分鐘”以下的菜譜占78.9%,烹飪時間在“30分鐘”以下的占菜譜數的69.3%。說明人們傾向于簡單易烹飪的食物。
(5)口味方面:“家常味”占36.5%,“咸鮮味”占19.9%,“甜味”占15.1%。
以上統計分析結果均與實際相符合,說明了網絡數據的真實性、實用性,具有研究價值。
3.2 困惑度
困惑度[9]是用來評價主題模型的一個重要指標,主題模型用概率分布來描述一個文本的生成過程,因此理所當然地會想到用熵的概念來評判主題模型是否有效。直觀的解釋即為:若詞表中所有的詞都具有統一的概率分布,即每個詞出現的概率都是一樣的,這種情況下是最難預測的,而由熵的概念知此時的熵最大。而概率分布越不均勻,熵值越小。
文中應用LDA模型構建的用戶飲食行為模型屬于主題模型的一種,故也選用困惑度作為衡量算法的標準。該模型中困惑度的公式如下:
(5)
(6)
(7)
其中,M為測試集D中的用戶數;p(Wd)為用戶d的菜譜詞向量;Nd為該詞向量的長度;K為飲食行為數;p(zn=k|d)為用戶d產生飲食行為z的概率;p(wn|zn=k)為飲食行為z生成詞w的概率;θ為飲食行為的概率分布矩陣(見2.1節);φ為詞的概率分布矩陣(見2.1節)。
LDA模型的求解過程使用基于吉布斯(Gibbs)抽樣的參數估計方法[10-11],模型參數根據文獻[12-15]選取經驗值。其中,α=50/K(K為主題數,對應文中用戶飲食行為模型中的隱飲食行為數),β=0.01。根據困惑度的結果確定最佳的K值。首先,嘗試設置K為10,20,…,110時的情況,如圖2(a)所示。模型的困惑度隨著K的增大而減小,當K為40時困惑度最小,模型的效果最好。隨著K不斷增大,困惑度也隨之增大。因此認為K的最優值在40附近。為進一步確定K的值,以1為間隔,選取K為30~50時計算困惑度,如圖2(b)所示。最終確定文中構建用戶飲食模型時的K為47。

圖2 不同主題數下的困惑度
3.3 用戶相似度
對采集到的數據進行隨機篩選,以30個用戶為例,應用飲食行為模型分析用戶間的相似度,設置飲食行為K=47,得到相似度矩陣。隨機抽取一位用戶,列出與其相似度最高的十位用戶,如表1所示。可根據用戶之間的相似關系提供食品推薦服務、群體飲食行為研究等。

表2 與用戶1相似度最高的十位用戶
4 結束語
針對美食互動社區中的UCG數據,結合LDA模型的文檔-主題-詞分層模型的特點,用UCG數據來代表用戶,進而提出了用戶-飲食行為-詞的用戶飲食行為模型,為數據挖掘在飲食行為方面的研究提供了一個新思路。今后的研究工作可結合更多的社交網絡特征,通過數據挖掘,為解決飲食行為干預、疾病預防和控制、食品推薦等問題提供更大的幫助。
[1] 毛 茅,王 洋,趙妤婕,等.基于社交網絡的美食互動網站設計與評估[C]//第七屆和諧人機環境聯合學術會議(HHME2011)論文集.出版地不詳:出版者不詳,2011.
[2] 楊正雄,趙文華,陳君石.飲食行為干預的研究進展[J].中國學校衛生,2008,29(6):573-576.
[3] 貢浩凌,戴莉敏,劉 媛,等.醫院-社區-家庭護理干預模式對2型糖尿病患者飲食控制的效果[J].中華護理雜志,2014,49(4):399-403.
[4] 張雅楠,丁 虹,杜玉萍.回顧性膳食調查輔助工具的應用現狀與評價方法[J].職業與健康,2015(9):1294-1296.
[5] 安宜沛.慢性心衰患者膳食現況調查及中醫藥膳調養研究[D].廣州:廣州中醫藥大學,2015.
[6]BleiDM,NgAY,JordanMI.LatentDirichletallocation[J].JournalofMachineLearningResearch,2003,3:993-1022.
[7] 孫昌年,鄭 誠,夏青松.基于LDA的中文文本相似度計算[J].計算機技術與發展,2013,23(1):217-220.
[8] 曾利明.中國民眾存在五大飲食“誤區”[N].光明日報,2004-11-26.
[9]HofmannT.Unsupervisedlearningbyprobabilisticlatentsemanticanalysis[J].MachineLearning,2001,42(1-2):177-196.
[10] 張 斌,張 引,高克寧,等.融合關系與內容分析的社會標簽推薦[J].軟件學報,2012,23(3):476-488.
[11]GriffithsT,SteyversM.Probabilistictopicmodels[M]//Latentsemanticanalysis.Hillsdale,NJ:LaurenceErlbaum,2006.
[12]AsuncionA,WellingM,SmythP,etal.Onsmoothingandinferencefortopicmodels[C]//Proceedingsofthetwenty-fifthconferenceonuncertaintyinartificialintelligence.[s.l.]:AUAIPress,2009:27-34.
[13] 石 晶,胡 明,石 鑫,等.基于LDA模型的文本分割[J].計算機學報,2008,31(10):1865-1873.
[14] 劉振鹿,王大玲,馮 時,等.一種基于LDA的潛在語義區劃分及Web文檔聚類算法[J].中文信息學報,2011,25(1):60-65.
[15] 李文峰.基于主題模型的用戶建模研究[D].北京:北京郵電大學,2013.
Research on User Eating Behavior Model Based on Food Interactive Community
LI Yue,CAO Han
(School of Computer Science,Shaanxi Normal University,Xi’an 710062,China)
As the time for big data and "Internet+" era is coming,user generated content of Internet food interactive community is experiencing the explosive growth.It is becoming more and more difficult for users to find the content of interest.And this part of the data has not been widely used and deeply mined.Traditional eating behavior research normally uses questionnaire,which spends a lot of manpower,material and financial resources.To solve the above problem,it presents user eating behavior model based on LDA.In order to build this model,the ideas of LDA model is used to analyze user generated content of Internet food interactive community,determining the subject number of model according to the perplexity,then calculating the user similarity of eating behavior,which can provide a basis of recommending friends or food for community users.It also provides a new way of eating behavior research.The user generated content from a Internet food interactive community is collected as data set.The experiments verify the feasibility and effectiveness of this method.
eating behavior;food interactive community;user model;data mining;LDA model
2016-01-20
2016-05-18
時間:2016-10-24
國家自然科學基金資助項目(41271387)
李 越(1991-),女,碩士研究生,研究方向為云計算、高性能計算、機器學習、數據挖掘;曹 菡,教授,研究方向為并行計算、大數據處理、空間數據挖掘、智慧旅游。
http://www.cnki.net/kcms/detail/61.1450.TP.20161024.1113.040.html
TP39
A
1673-629X(2016)12-0156-04
10.3969/j.issn.1673-629X.2016.12.034
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
