基于MapReduce的混合推薦算法及應用
2016-02-24 10:45:06李程,曹菡,師軍
計算機技術與發展 2016年4期
李 程,曹 菡,師 軍
(陜西師范大學 計算機科學學院,陜西 西安 710119)
基于MapReduce的混合推薦算法及應用
李 程,曹 菡,師 軍
(陜西師范大學 計算機科學學院,陜西 西安 710119)
針對基于項目與基于用戶兩種傳統協同過濾算法的不足,文中結合基于用戶以及基于項目的兩種傳統協同過濾算法,并加以合理改進,提出了一種新型的混合型并行推薦算法。通過對新算法MapReduce編譯,使新算法能夠在Hadoop云平臺下順利運行。在可以利用以基于用戶的方法為基礎劃定出定量的鄰居范圍,保證了推薦的個性化,同時,利用基于項目的協同過濾算法進行推薦,最終根據綜合因素調整評分預測方法得出符合實際的推薦結果。實驗結果表明,在數據量相對較大時新算法不僅在處理速度上表現更加優越,而且明顯提高了推薦精確度。同時文中將該算法應用在西安本土旅游推薦服務上,針對西安市幾大景點進行推薦,使新算法的準確性在實際應用中得到驗證。
MapReduce;Hadoop;混合推薦算法;云計算
0 引 言
隨著互聯網的不斷迅速發展,每日產生的數據量呈指數級增長。在面對大數據的大容量、多類型天然特性時,尤其是處理GB級乃至PB級及以非結構化為主的數據時,要滿足這樣的高時效性變得尤為困難[1]。在稍縱即逝的市場機會和變幻莫測的大自然面前,大數據的高時效性猶如皇冠上那顆最炫耀奪目的寶石,吸引了從業者的目光。
大數據在給技術開發者帶來大量豐富數據的同時,也給技術人員增加了從大數據中得到有效的用戶信息與相關興趣數據的難度[2]。將推薦系統個性化不僅能夠從海量的帶有很多干擾的數據中挖掘到有用信息,使得推薦具有更好的服務,也可大幅提升推薦的速度及準確度[3]。伴隨著數據存儲需求的不斷提升,智能化商業的不斷擴大,基于大數據挖掘的應用也得到了越來越廣泛的研究與應用。
在云平臺領域,Hadoop是目前較為熱門的研究平臺[4],它以存儲的廉價以及計算的高效著稱。文中以大數據為背景、以云計算為手段,提出了一種新的混合推薦算法,并深入研究個性化推薦的內在原理,且在Hadoop云平臺下設計了并行的個性化推薦算法,通過實驗驗證了其理論意義與實際應用價值[5]。
1 基于鄰域的推薦算法
在眾多的推薦算法之中,最基本的推薦算法就是基于鄰域的推薦算法[6]。此類算法不僅僅是在應用領域得到了推廣,而且還在研究者之間得到了較為深入的研究。此類算法包含兩大類,分別為基于項目的協同過濾算法和基于用戶的協同過濾算法。
1.1 基于用戶的協同過濾算法
最基本的基于用戶的協同過濾系統,是以興趣相似為基礎,先得到一組用戶,在這個組中的用戶對其命名為“鄰居”。因為這些鄰居是以興趣相似劃分的,所以他們之間的歷史評分帶有非常強的相似相關性[7]。由這些鄰居之間的得分而推出的結果稱之為Top-N推薦。為了得到更為精確的結果,可以用余弦相似法和皮爾遜相似法來測量每組用戶或者鄰居之間的相似度[8]。
基于用戶的協同過濾算法由以下兩步組成:
(1)以目標用戶為中心尋找相似度高的鄰居用戶形成一個用戶集;
(2)以這個用戶集為中心向目標用戶推薦用戶集中目標用戶沒有涉及的物品或項目。
第1步的重點在于計算目標用戶與測試用戶之間的相似度。在這一步中,利用的主要是行為的相似,通過行為相似度推導出興趣的相似度。假設有u和v兩個用戶,設N(u)代表一個集合,這個集合是得到u用戶正反饋的物品集合,設N(v)也代表一個集合,這個集合是v用戶正反饋的物品集合。進而通過式(1)計算出u和v的相似度:
(1)
也可用余弦相似度計算:
(2)
在計算出用戶與用戶的興趣相似度后,基于用戶的協同過濾算法就默認給一個用戶推薦一個與他興趣最相似的K個用戶喜歡的物品。式(3)度量了算法中用戶u對物品i的感興趣程度:
(3)
式中:S(u,K)為與u用戶興趣度較相近的K個用戶;N(i)為與i物品有過打分記錄的用戶集合;wuv為u用戶和v用戶相互間的興趣相似度;rvi代表用戶v對物品i的興趣。
盡管以用戶為基礎的協同過濾算法流行度很廣,但同時也存在自身局限,例如可擴展性和響應性等方面[9]。為了解決這里的局限性問題,誕生出了基于項目的協同過濾算法,這種協同過濾算法就是以項目為基礎建立推薦模型[10]。
1.2 基于項目的協同過濾算法
與基于用戶的協同過濾算法不同,基于項目的協同過濾算法是以得分來進行推薦的,比較的是用戶與用戶之間對同一個項目的打分。該算法的核心是得到不同用戶都打分的K個最相似項目[11]。基于項目的協同過濾算法采用以下兩步:
(1)通過算法計算,得到項目與項目間的相似度;
(2)通過項目與項目之間的相似度再加上用戶行為綜合生成一個推薦列表給用戶。
項目相似度定義為:
(4)
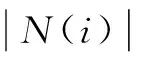
因此式(4)可以看成是喜歡項目i的用戶中有多少比例的用戶同時也喜歡項目j。
該式存在一定的缺陷,就是當j項目為熱門項目時,其結果就會接近1,因為很多人喜歡。這就會導致無論什么物品都會跟這種熱門項目有著相似度較大的情況。為了不使這種情況出現,可以運用改進后的公式:
(5)
從式(5)可以看出,在此公式中對j項目的權重進行了懲罰,從而可以降低熱門項目與其他項目相似的可能。
通過計算得出項目與項目之間的相似度后,通過式(6)得出u用戶是否對j項目感興趣:
(6)
式中:N(u)是一個物品集合,代表著用戶喜歡的物品;S(j,k)是和j物品相似度最高的k個物品集合;wji是物品j和i相互之間的相似度;rui是u用戶對i物品的感興趣程度。
1.3 基于用戶-物品的混合推薦算法
總結以上兩節的分析描述,可以利用兩種方法的優點,通過融合兩種算法,演變出一個新的混合型協同過濾算法。這種新算法的核心就是需要計算兩類推薦算法的推薦結果,進而進行結果的綜合運算[12]。通過這樣的綜合運算,可以確保以用戶與用戶相似度動態計算出個性化推薦結果,同時也只要用一小部分相似用戶便可以得到很好的推薦質量[13]。算法描述如下:
(1)計算目標用戶與其他鄰居用戶的相似度;
(2)預設相似度閾值m,若用戶bn的相似度大于閾值m,則作為鄰居;
(3)得到目標用戶a的鄰居數量l;
(4)根據鄰居利用算法進行預測推薦。
2 基于MapReduce的混合推薦算法
在分布式系統Hadoop運算中,第一步是初始化,將每一個MapReduce過程初始化為兩個階段[14],分別是一個Map過程和一個Reduce過程。其中,Map過程實際是一個Map函數,Reduce過程實際是一個Reduce函數。在整個MapReduce過程中,數據以一個
在混合協同過濾算法中,兩個核心步驟為基于用戶-項目評分矩陣計算相似度以及基于相似度預測為評分項目的評分。這兩個步驟與MapReduce并行處理思想是相契合的,可以編譯實現。因此,在計算過程中,輸入的鍵值對可以表示為
第一次MapReduce得出用戶對項目的評分,根據用戶名進行排列;該階段的Map函數將輸入數據轉換為相應
第二次MapReduce得出項目間的相似度,將用戶和項目的鍵值對轉換成項目和項目之間的鍵值對。該階段通過Map函數獲得各項目之間同一用戶的評分對比,隨后通過Reduce函數得出項目之間的相似度,如圖2所示。
最終得出用戶推薦的相似列表,使用Map函數對目標用戶評分進行預測,然后使用Reduce函數得出推薦結果,如圖3所示。

圖1 第一次MapReduce

圖2 第二次MapReduce
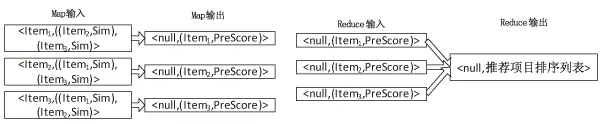
圖3 第三次MapReduce
3 實驗分析
3.1 實驗設計
(1)實驗準備。
一臺計算機作為NameNode和JobTracker主機節點,其余九臺機器作為DateNode和TaskTracher從節點。每個節點配置如下:處理器為Intel(R) Core(TM)2 CPU 6320 @1.86 GHz;內存為1 GB;系統類型為Ubuntu12.10,32位操作系統。根據Hadoop官方網站介紹方法配置部署Hadoop集群版本Hadoop1.0.2。
(2)評估標準。
為了驗證實驗結果的精確度,這里采用平均絕對誤差(MAE)。MAE作為推薦系統的標準評判,能夠評判出推薦系統的預測精度,它的原理就是經過推導得出預測評分與實際評分的偏差來評測算法的準確性。
(7)
其中:IP(u)是推薦系統為用戶u推薦出的項目集;IR(u)是用戶u在測試集數據上進行評分的項目集;N是IP(u)與IR(u)交集的項目個數。
計算出每個用戶的MAUE,然后計算該系統的MAE:
(8)
由式(8)得出:當MAE值越小時證明預測值與實際值差異越小。
(3)實驗過程。
實驗以數據的80%作為訓練集,其余20%為測試集。為使實驗比較更加準確,將文中算法和基于MapReduce用戶推薦算法、基于MapReduce項目推薦算法,以及串行協同過濾算法一起進行實驗。
3.2 實驗結果
實驗一對比各算法之間的MAE平均值,見圖4。
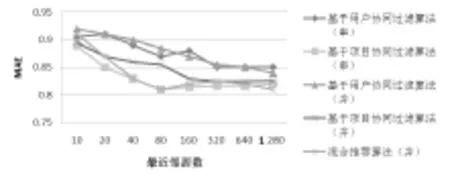
圖4 MAE對比圖
實驗二在單機環境下對比各算法之間的處理時效,見圖5。

圖5 單機時效對比圖
實驗三在集群環境下對比各并行算法處理時效,見圖6。

圖6 集群時效對比圖
從圖4可看出,隨著鄰居數的增多,新算法的推薦質量有顯著提高,與其他串行算法對比推薦質量并無較大差異,并且與同為并行算法的基于MapReduce的項目推薦算法和用戶推薦算法相比有較好表現。
從圖5可看出,在不同數據集中隨著數據量的加大,并行算法展現出其獨特優勢,即在較小數據集時需花費較多運算時間但在較大數據集時所需時間大大減少。
從圖6可看出,在不同節點數數據處理對比時,證明在多節點處理上并行算法更有出色的表現。
綜上得出,文中算法確實在處理大數據方面有著一定優勢。
4 實例分析
最近幾年,隨著人民的旅游需求不斷提高,旅游業蓬勃發展。“智慧旅游”以其智能、高效,得到了越來越多用戶的親睞。其中一個特色技術就是通過分析提取用戶的某些資料以及以往選擇,通過算法分析出一個此用戶可能感興趣的景點供其游覽。在此前提下,以西安作為背景,結合在驢友網上搜集的數據,對線上的1 785位網友,以及在一些景點的游客,做了關于西安十五個景點的評分,過濾掉無效評分得出了4 339條有效數據。其中景點編號從J1至J15分別為兵馬俑、華清池、回民街、半坡遺址、大雁塔、乾陵、鐘鼓樓、太白山、歷史博物館、驪山、小雁塔、翠華山、秦嶺野生動物園、曲江、南門,并生成評分矩陣。其中十五個景點評分為1~5分,不同人對不同景點心中有不同評分,其中有一些干擾數據已經排除。
從數據中可以看出,旅游者已經去過這些景點并對它們依次進行了打分,得分少的或許是沒有自己游覽或者只是聽說。若想要為某一用戶L推薦下一個可能喜歡的景點,使用文中算法為其推薦的是景點12,預測評分4.27。而實際數據其評分為4。從結果可以看出文中算法確實能夠根據旅游者的興趣得出推薦結果,但在小規模數據上速度確實存在不足,在集群環境下速度明顯低于串行算法,原因就在于Hadoop還需要一定時間在任務分配上,而真正的處理時間幾乎微乎其微。如果要想體現出Hadoop處理速度的優勢,數量至少要達到千萬級別數據才行。所以只有在大數據量時,才可以體現出該算法的高效性以及廉價設備性。
5 結束語
針對基于項目與基于用戶兩種傳統協同過濾算法的不足,文中提出了一種新型的混合型并行推薦算法。實驗結果表明,新算法不僅在處理速度上表現更加優越,而且明顯提高了推薦精確度。同時該算法在西安本土旅游推薦服務上的應用也驗證了算法的準確性。
[1] 陳如明.大數據時代的挑戰,價值與應對策略[J].移動通信,2012(17):14-15.
[2] 余肖生,孫 珊.基于網絡用戶信息行為的個性化推薦模型[J].重慶理工大學學報:自然科學,2013,27(1):47-50.
[3] 項 亮.推薦系統實踐[M].北京:人民郵電出版社,2012.
[4] 劉 剛.Hadoop應用開發技術詳解[M].北京:機械工業出版社,2014.
[5] 陶劍文.一種分布式智能推薦系統的設計與實現[J].計算機仿真,2007,24(7):296-300.
[6] 熊忠陽,劉 芹,張玉芳,等.基于項目分類的協同過濾改進算法[J].計算機應用研究,2012,29(2):493-496.
[7] 黃創光,印 鑒,汪 靜,等.不確定近鄰的協同過濾推薦算法[J].計算機學報,2010,33(8):1369-1377.
[8]WangJ,deVriesAP,ReindersMJT.Unifyinguser-basedanditem-basedcollaborativefilteringapproachesbysimilarityfusion[C]//Proceedingsofthe29thannualinternationalACMSIGIRconferenceonresearchanddevelopmentininformationretrieval.NewYork:ACM,2006:501-508.
[9]DeshpandeM,KarypisG.Item-basedtop-nrecommendationalgorithms[J].ACMTransactionsonInformationSystems,2004,22(1):143-177.
[10]LindenG,SmithB,YorkJ.Amazon.comrecommendations:item-to-itemcollaborativefiltering[J].IEEEInternetComputing,2003,7(1):76-80.
[11]LiuQ.ResearchonsomekeytechnologiesofChinese-Englishmachine-intranslation[D].Beijing:PekingUniversity,2004.
[12]SarwarB,KarypisG,KonstanJ,etal.Item-basedcollaborativefilteringrecommendationalgorithms[C]//Proceedingsofthe10thinternationalworldwidewebconference.[s.l.]:[s.n.],2001:285-295.
[13] 劉平峰,聶規劃,陳冬林.基于知識的電子商務智能推薦系統平臺設計[J].計算機工程與應用,2007,43(19):199-201.
[14] 李 莉,廖建偉,歐 靈.云計算初探[J].計算機應用研究,2010,27(12):4419-4422.
Hybrid Recommendation Algorithm Based on MapReduce and Its Application
LI Cheng,CAO Han,SHI Jun
(School of Computer Science,Shaanxi Normal University,Xi’an 710119,China)
For the shortcomings of traditional project-based and user-based collaborative filtering algorithm,a new parallel recommendation algorithm is proposed,combined user-based with project-based collaborative filtering algorithm and improved them.Through MapReduce compilation,the new algorithm can run in Hadoop cloud platform.To guarantee the personalized recommendation,it can take advantages of the collaborative filtering algorithm based on user defined a certain number of neighbors.At the same time,the project-based collaborative filtering algorithm is used to recommend.Finally,according to the comprehensive adjusted score prediction method,the recommended results are obtained.The experimental results show that the algorithm becomes more superior in the case of a large number of processing speed,and improves the accuracy of recommendation.Simultaneously,the algorithm is applied in local tourism of Xi’an referral service for several major attractions to recommend.The accuracy of the new algorithm has been verified in practical applications.
MapReduce;Hadoop;hybrid recommendation algorithm;cloud computing
2014-11-25
2015-04-15
時間:2016-04-00
國家自然科學基金資助項目(41271387);西安市科技計劃基金資助項目(SF1228-3)
李 程(1989-),男,碩士研究生,研究方向為高性能計算、云計算;曹 菡,博士,教授,研究方向為數據挖掘、智慧旅游、高性能計算;師 軍,副教授,研究方向為智能信息處理。
http://www.cnki.net/kcms/detail/61.1450.TP.20160322.1517.018.html
TP311
A
1673-629X(2016)04-0074-04
10.3969/j.issn.1673-629X.2016.04.016
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
商用汽車(2016年11期)2016-12-19 01:20:16
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
