改進的免疫克隆算法在入侵檢測中的應用
2016-02-24 03:45:08牛永潔薛寧靜
計算機技術與發展 2016年5期
牛永潔,薛寧靜
(延安大學 數學與計算機學院,陜西 延安 716000)
改進的免疫克隆算法在入侵檢測中的應用
牛永潔,薛寧靜
(延安大學 數學與計算機學院,陜西 延安 716000)
為了提高入侵檢測系統的正確率,降低誤檢率,對基本的免疫克隆選擇算法采用抗體的克隆數目與親和度成正比且克隆數目線性遞減、變異概率線性遞減、新的替換策略、變異概率和抗體克隆數量突變進行改進。對抗體克隆策略的改進保證了算法的收斂速度,避免了算法后期的震蕩,變異概率的自適應變化加強了算法后期的收斂,新的替換策略、變異概率和抗體克隆數量突變能夠有效地避免算法陷入局部最優。經過KDDCup1999數據集的訓練和檢驗數據的仿真測試,改進后的算法具有較高的檢測正確率和較低的誤檢率,而且新算法收斂速度快,不易“早熟”。
入侵檢測;克隆選擇;變異概率;克隆策略;自適應
1 概 述
目前,計算機網絡已經滲透到人們工作生活的各個方面,特別是最近電子商務的興起和普及,越來越多的敏感信息在網絡中傳輸,為了保證這些信息的安全性,網絡安全問題越來越受到人們的關注。隨著網絡技術的發展,新型的網絡攻擊方法層出不窮,讓現有的防御技術防不勝防,因此用戶的計算機系統可能隨時都有被新型的攻擊方法攻擊的危險。
入侵檢測系統(IntrusionDetectionSystem,IDS)是一種能夠主動發現并進行防御的系統,它能發現新型、現有未知的攻擊方法。相對于其他安全措施而言,入侵檢測系統不僅在防御性上具有主動性的優點,而且還具有能夠識別新型的、未知的攻擊方法的特性。一般的入侵檢測系統能夠同時防御系統內外兩個方面的攻擊,其運行的基本原理是首先在計算機系統或者外部網絡的關鍵點位置放置探測裝置收集相關的信息,然后對收集的信息使用相關技術進行分析,從而得出系統是否遭到攻擊的判斷。一旦發現受到攻擊,系統將會根據受攻擊的類別或者嚴重程度依據事先制定好的規則做出不同的反應,如:報警、攔截運行或者直接刪除、丟棄相應的數據。因此得出結論:入侵檢測系統的整個關鍵步驟是對收集的相關信息進行信息解析、分析處理,然后得出這些行為是否異常[1-3]。
對流經計算機系統的數據包進行抓取和數據處理,然后使用適當的數據分析算法,判斷出數據包屬于正常或者非正常數據,針對非正常的數據采取報警或者其他的措施對用戶進行警告或者提示。所以對數據包進行分析,用來分辨數據是否正常的算法是入侵檢測系統的核心。
在對人體免疫系統運行機理進行深入研究的基礎上,按照仿生學的原理,研究人員提出了人工免疫系統算法。目前已經發展成多種不同的算法,比較典型的有克隆選擇算法、B細胞網絡算法、陰性選擇算法和免疫遺傳算法。其中應用最為廣泛和經典的算法是免疫克隆選擇算法,該算法由DeCastro等根據生物免疫系統理論中的克隆選擇學說而提出[4-5]。這種算法被人們稱為CLONALG算法。CLONALG算法在應用過程中逐漸暴露出很多的缺點和弊端,比如收斂速度慢、搜索能力差而且容易陷入局部最優,也就是通常所說的“早熟”現象。
雖然CLONALG有上述的一些缺點,但是本身也有很多其他算法不具有的獨特優勢,比如算法本身具有并行性、自適應性,能夠主動學習、識別和記憶,所以該算法被迅速地應用到很多領域。這些領域主要包括復雜函數的優化[6-7]、多維數據的特征選擇[8-9]、網絡安全監測[10]、圖像的分割[11-12]和機器學習[13]等。
文中將免疫克隆算法應用到入侵檢測系統中。為了避免CLONALG算法的缺點進而獲得較高的正確率和較低的誤檢率,詳細研究了CLONALG算法的運行過程并對造成其缺陷的原因進行了深入分析,對算法進行了四個方面的優化和改進。改進后的算法不僅收斂速度快、全局搜索能力強,而且不易陷入局部最優點,即使算法陷入到局部最優點,算法仍有較大的幾率跳出并繼續進行全局搜索,在算法運行后期,能夠迅速收斂到最優值,不會造成算法后期運行的震蕩。最后通過在模擬數據下的仿真實驗,發現算法運行高效、快捷,效果良好。
2 入侵檢測
入侵是指除了正常使用計算機資源的各種活動的集合,這些活動往往企圖對計算機資源在完整性、機密性和可用性等方面進行破壞。入侵檢測系統的任務就是從各種使用計算機的活動中識別出入侵的活動。為了進行識別,系統必須對通信數據或用戶的行為進行實時監視并檢測這些數據,以此來判斷是否有入侵行為的發生。
入侵檢測技術按照檢測方法可以分為兩種基本的方法,分別是誤用檢測(misusedetection)和異常檢測(anomalydetection)。
誤用檢測是指識別入侵者使用現有已經知道的攻擊方法或者利用系統安全漏洞采用合法的命令進行攻擊的檢測過程。異常檢測主要檢測的攻擊方式是利用系統正常運行的日志記錄或者利用網絡交互數據中具有識別性的數據來假冒系統正常運行這兩種方式。IDS根據對數據的偵聽策略不同又可以分為基于網絡的入侵檢測系統和基于主機的入侵檢測系統。網絡入侵檢測系統是在網絡上利用網絡偵聽技術抓取數據包,然后對收集的數據包進行信息解析,從里面分析行為是否異常。而基于主機的IDS的數據來源主要是主機系統和系統本地用戶的審計數據和系統的日志。
文中研究的入侵檢測系統的數據來源于網絡中的數據包[11],所以是一種基于網絡的IDS。系統的運行原理機制如圖1所示。
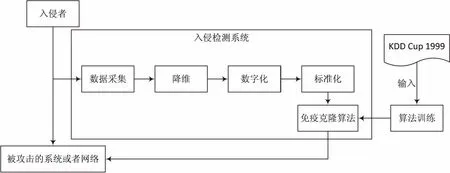
圖1 入侵檢測系統的運行機制
為了進行入侵檢測,首先應該得到需要分析的數據,即數據采集。對網絡數據的采集使用一種叫嗅探器的工具。嗅探器有硬件和軟件兩種實現方式。硬件網絡嗅探器靈活性比較差,但是其性能高而且價格比較昂貴。軟件網絡嗅探器具有實現方便、布置靈活和成本低的優勢。不同的軟件版本需要不同的平臺支持,比較常見的嗅探器有:Linux系統下的Tcpdump,HP-UX系統平臺下的NfSwatch和Windows系統平臺下的lpman、FoxSniffe、Wireshark、WinPcap等。SharpPcap是一個基于著名的WinPcap庫,在.NET環境下開發而成的網絡包捕獲應用程序包。該開發包提供了網絡包的捕獲、數據注入、數據包解析和生成的功能,適用于.NET開發平臺。文中對數據包的抓取基于SharpPcap庫進行。
對抓取的數據包進行數據預處理的過程主要包含3個步驟,它們分別是降維、數字化、標準化。由于抓取的數據包一般維數比較大,為了減少后續算法的運算量,同時還不能影響算法的準確度,文中采用主成分分析(PrincipalComponentAnalysis,PCA)方法對網絡數據包進行降維處理。在獲得的網絡數據包中,每一條記錄中,對有些屬性的描述往往會采用字符串進行,這些字符串對后面要進行的數據分析和處理不利,因此首先需要對這些屬性進行數字化處理,如為了表示目標主機的網絡服務類型,會對記錄的網絡服務類型標記為HTTP、SMTP、SQL_NET、POP_3等。為了后續更好地進行數據處理和分析,需要對文本字符進行轉換,使之成為數值型數據。最后還需要考慮每條記錄中不同屬性采用的量綱不同,數值大小的不同會嚴重影響數據處理過程中屬性權重的大小,所以需要消除不同屬性量綱的不同,因此還需要對轉換以后的數據進行標準化處理。處理過程使用式(1)、(2)進行。

(1)
(2)
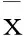
經過標準化處理消除了不同屬性之間量綱對數據分析的影響。
3 免疫克隆算法的改進
3.1 基本免疫克隆算法
對人工免疫系統(ArtificialImmuneSystem,AIS)的研究,起步相對較晚,但近年來發展迅速。人工免疫算法將抗原視為問題域中需要進行優化的問題的目標函數,而抗體恰好是該目標函數對應的可行解。不同的抗體對抗原的親和力不同,而問題域中,可行解對目標函數的匹配程度恰好可以使用這種親和力來表示:抗體對抗原親和力的不同能夠保證問題域中可行解的多樣性,計算不同抗體的期望生存率,使用期望生存率高的抗體進行下一代抗體的遺傳,為了防止可行解陷入局部最優,遺傳下來的抗體必須保持一定的變異率,用來繼續保證抗體對抗原親和力的多樣性,但是變異概率不應過大,不然算法很容易陷入震蕩而造成算法最后的不收斂。同時使用記憶細胞記錄這些優秀的可行解,記憶細胞中的數據可以用來防止后續可行解產生過程中相似可行解的繼續出現,進而可以使算法快速地搜索到全局最優解,保證了算法的收斂速度。當算法再次遇到相似問題時,可以從記憶細胞中快速地產生與抗原親和力很高的抗體,能快速地產生問題的較優解甚至最優解,這就是算法的免疫性。
比較經典的人工免疫算法—克隆選擇算法主要步驟為:算法起始階段、優良抗體的選擇、抗體的復制克隆、變異、種群抗體替換等。在算法的起始化步驟中,采用隨機化的方法隨機產生N個抗體,這些抗體對應于問題域中的N個可能解,隨機產生的抗體群又被分為功能不同的兩個子群體,其中一個子群體作為記憶細胞M,而剩下的群體被稱為剩余種群R。然后計算每個抗體與抗原的親和度,這個親和度用來作為每個抗體優劣性的衡量指標,親和度高的抗體表示是抗原表示問題的優秀解,即親和度高的抗體更可能是問題域的可能解,從抗體群中篩選出n個結合度較高的抗體,下一步對這n個抗體進行復制即為克隆。為了預防算法的局部最優,需要對復制后的抗體進行高概率的隨機變異。在變異后的群體中隨機選擇其中的C個抗體,然后重新隨機生成C個抗體,用新生成的C個抗體替換掉變異后群體中被選中的C個抗體,然后算法再次進入起始化階段,計算抗體對抗原的親和度,選擇,復制克隆,等等。算法進入迭代循環,直到算法找到最優解或者循環達到一定要求為止。
經典的克隆選擇算法的運行步驟如下:
(1)候選抗體集合H的生成。根據問題的定義域要求,使用隨機化的方法,得到一個含有N個抗體的種群集合H。其中N即為候選抗體種群的大小,即在定義域中得到N個可行解的點。
(2)計算抗體集合H中每個抗體對抗原的親和度,即計算每個可行解在適應度函數中的值,根據值的大小從抗體集合H中選擇n個最優的抗體,選中的抗體稱為集合Rn,其中選擇的n與抗體規模滿足n≤N的要求。
(3)克隆復制操作。將集合Rn中的每個抗體重復克隆復制k個,n個抗體復制的個數為n*k,n*k個抗體組成了臨時的克隆集合C。
(4)對克隆集合C以一定的概率m進行高頻變異,變異后抗體群構成了一個新的集合Cn。
(5)對集合Cn中變異后的每個抗體再次計算適應度函數值,選擇與集合Rn相同個數的最優抗體,選中的變異后的這些抗體就構成了另一個集合,這個集合被稱為記憶細胞集合M,然后將集合M的抗體替換掉集合Rn中的抗體。
(6)從集合H中選擇d個低親和度的抗體,將這些抗體丟棄,然后使用完全隨機化的方法重新生成d個新的抗體,將這些新抗體加入集合H中,同時將原先選中的d個低親和度的抗體丟掉。
3.2 新的免疫克隆算法
新的免疫克隆算法對經典的算法進行了四個方面的優化和改進[13]。
(1)采用新的抗體克隆方法[14]。
新的抗體克隆方法分兩個階段進行。經典的免疫克隆算法對集合Rn中的每個抗體采用相同的克隆辦法,即每個抗體都復制c個,新的方法為了讓優秀的抗體更多地帶到下一代,采用根據抗體自身的親和度大小進行正比例的復制,親和度越大復制的數量越多,而親和度低的抗體復制的數目要少。對任意一個抗體t的克隆數量的計算使用式(3)。
(3)
式中:Ct為第t個抗體需要克隆復制的個數;ft為該抗體的親和度;fmax為所有種群的最大親和度;N為種群數量的大小;α為對克隆進行調節的參數。
隨著算法的迭代進行,一方面保持按照親和度正比例克隆的方法,同時根據迭代次數遞減抗體的克隆數目,即在上一代中抗體t的親和度為q,復制的數量為p',但是在下一代的克隆過程中,有一個抗體的親和度也為q,但是其復制的數量為p'',其中p''和p'滿足p'' 新的抗體克隆方法總體上能夠保證算法是收斂的,而且能夠保證算法的收斂速度。在算法的運行后期,由于采用復制克隆數量遞減的策略,避免了算法在收斂到全局最優點時的震蕩現象。對式(3)進行調整,用來遞減克隆抗體,調整以后為: (4) 式中:Iter為算法的迭代次數;β為一個負值的調節參數;λ為復制克隆階段第一次迭代時的復制克隆數值。 因此新算法在進行抗體克隆時,一方面要保持抗體克隆數量與自己親和度的正比例關系,而且隨著算法的迭代,使得每個抗體的克隆數量呈線性遞減趨勢。 (2)變異概率的自適應[15]。 克隆復制后的集合Rn為了保持種群的多樣性,對集合中的抗體進行高頻變異操作。經典的算法其變異的概率始終保持不變,新的算法采用在算法的初期采用比較高的變異概率,用來保持種群的多樣性,對問題的空間進行充分搜索,但是在算法運行后期,算法已經進入收斂階段,如果仍然采用高的變異概率,這些新的種群往往會造成算法的震蕩,使算法在長時間內得不到收斂。因此在新算法中采用變異概率的自適應變化,即隨著算法的迭代運行,變異概率隨著迭代次數線性遞減。新算法的變異概率為: mk+1=ρ×mk (5) 式中:mk為算法第k次運行時采用的變異概率;mk+1為第k+1次循環步驟使用的變異概率;參數ρ滿足0<ρ<1。 (3)抗體更新的新限制[16]。 經典的克隆選擇算法采用算法初始化時的方法隨機產生d個新的抗體,新產生的抗體直接替換掉集合H中的d個低親和度的抗體,沒有對新產生的d個抗體做任何限制。而新算法為了使算法在運行上向收斂的方向進行,對d個新產生的抗體提出了新的要求,即重新隨機生成d個新的抗體以后,計算每個抗體的親和度,求這些新抗體親和度的平均值,要求新抗體的平均親和度要大于等于目前種群的平均親和度,否則,重新隨機生成d個新的抗體。如果連續生成的d個抗體平均親和度都不符合要求的次數超過某個次數,采用基本的算法方式進行,這樣保證算法能夠向收斂的方向更快地進行。 (4)突變機制的引入[17-18]。 為了防止算法在運行過程中出現“早熟”現象,受到遺傳算法中的小生境的啟發,文中引入早熟檢測指數Dp。當早熟指數小于等于某一個數值ξ時,使用將變異概率突然放大為原先概率k倍的方法,同時將抗體的替換方法轉變為完全初始化的方式進行,即取消替換抗體集合的平均親和度必須大于等于種群平均親和度的要求。這個策略是在算法陷入早熟的情況下,引入新的群體來增加算法跳出局部最優的一個常識,由于變異概率的突然增大和替換總群的完全初始化,引入的新群體將有機會帶領算法向全局最優收斂。而當早熟檢測指數Dp重新大于ξ時,抗體的變異規律和替換策略繼續方法(2)和(3)進行。文中ξ取值為1.2。早熟檢測指數采用式(6)計算。 (6) 式中:fmax為本次迭代中抗體種群親和度的最大值;fmin為親和度的最小值;fave為本次迭代中抗體種群親和度的平均適應度。 采用KDDCup1999網絡數據集對新算法的效果進行了仿真實驗。該數據集是第三屆數據挖掘大會采用的官方測試入侵檢測的數據集,具有很高的通用性,實驗結果也具有很強的對比性,同時也有很高的問題說服力。數據集來源于美國麻省理工學院,是在對美國軍方的網絡環境模擬的情況下進行了各種網絡攻擊實驗,同時抓取了網絡流量數據包,進行整理而得到。 整個數據集被分成兩個部分,一部分是包含由500萬條記錄組成的訓練集,另一部分是由300萬條記錄組成的測試集。數據集中的每條記錄中由34個數值型字段和7個非數值型字段組成,這些記錄被分為五類,分別為正常、Probing攻擊、DoS攻擊、R2L攻擊和U2R。此次仿真實驗從訓練集中隨機抽取了4 500條正常的記錄,同時等比例抽取了攻擊數據記錄共2 000條,將這兩個集合合在一起作為整體訓練集。 算法運行過程中,相關的參數設置如下: 種群的規模個數為150,從抗體群中篩選出的結合度較高的抗體數量為種群規模的1/3,克隆調節參數α取值為0.9,克隆數量遞減的負值調節參數取值-0.001,復制克隆階段第一次迭代時的復制克隆數為3,變異概率的線性遞減系數ρ取0.75,算法初始的變異概率設置成1%的概率。在抗體替換的步驟中,每次替換掉選中種群整體的1/5;在變異概率突變的步驟中,概率突變放大的倍數采用1.4倍。 為了進行對比,經典算法和改進算法分別獨立運行20次,每次運行算法的循環次數規定為150代。最后,對每種算法運行的結果求平均值作為其算法的最終結果。 表1列出了經典算法和改進算法在入侵檢測系統中應用后的檢測正確率和誤報率結果。 表1 經典算法與改進免疫克隆算法的對比結果 通過新的抗體克隆、變異概率的自適應、抗體更新的新限制和突變機制的引入,得到一種改進的新算法,并將新算法應用到了入侵檢測系統的數據分析過程中。新算法通過采用抗體的克隆數目與親和度成正比及克隆數目逐漸遞減的策略,能夠更有效地保留優良抗體,加速算法的收斂速度,克隆數目的遞減能夠有效地減少算法計算工作量;變異概率的自適應遞減策略能夠保證算法在運行初期有充分的搜索算法空間,而且由于克隆數目與親和度的正比關系,能夠保證優良抗體的充分保留;替換策略的改進保證了算法在運行期間既能引入新的抗體,又避免了算法運行后期的震蕩;變異概率和克隆數量的突變能夠有效防止算法的“早熟”現象。最后,通過KDDCup1999數據集對算法進行了仿真實驗。結果表明,改進后的新算法能夠有效地提高入侵檢測的正確率、降低錯誤率且具有收斂速度快和不易“早熟”的優勢。 [1] 牛永潔,趙耀鋒.改進的LF算法在入侵檢測中的應用[J].計算機與現代化,2013(6):57-59. [2] 肖 敏,柴 蓉,楊富平,等.基于可拓集的入侵檢測模型[J].重慶郵電大學學報:自然科學版,2010,22(3):345-349. [3] 吳思遠,劉孫俊,王電鋼.一種基于免疫的入侵檢測動態響應模型[J].重慶郵電大學學報:自然科學版,2007,19(5):635-638. [4]deCastroLN,TmanisJ.Artificialimmunesystems:anewcomputationalintelligenceapproach[M].British:SpringerPress,2002. [5] 羅印升,李人厚,張 雷,等.人工免疫算法在函數優化中的應用[J].西安交通大學學報,2003,37(8):840-843. [6] 陳 曦,賀建軍,萬 力,等.基于改進克隆選擇算法的函數優化問題[J].湖南理工學院學報:自然科學版,2012,25(1):34-37. [7] 張向榮,焦李成.基于免疫克隆選擇算法的特征選擇[J].復旦學報:自然科學版,2004,43(5):926-929. [8] 王 俊,田玉玲.用于入侵檢測的動態克隆選擇算法的研究[J].計算機與數字工程,2010,38(6):108-110. [9] 劉 倩,仇 賓.基于克隆選擇算法的花卉圖像分割[J].計算機工程與應用,2012,48(14):185-189. [10] 叢 琳,沙宇恒,焦李成.基于免疫克隆選擇算法的圖像分割[J].電子與信息學報,2006,28(7):1169-1173. [11] 徐 佳,張 衛.人工免疫系統中的抗體生成與匹配算法[J].計算機工程,2010,36(9):181-183. [12] 牛永潔,陳 莉.基于混合神經網絡的入侵檢測技術[J].微計算機信息,2006,22(12-3):92-95. [13] 牛永潔,馬亞玲.一種改進的免疫克隆選擇算法[J].電子設計工程,2014,22(4):23-25. [14] 劉 瓊,吳小俊.一種改進的免疫克隆選擇算法[J].山東大學學報:工學版,2009,39(6):8-12. [15] 高新龍.免疫入侵檢測鄰域空間檢測算法研究[D].哈爾濱:哈爾濱理工大學,2015. [16] 方賢進,李龍澍,錢 海.基于人工免疫的網絡入侵檢測中疫苗算子的作用研究[J].計算機科學,2010,37(1):239-242. [17] 馮 翔,馬美怡,趙天玲,等.基于復合免疫算法的入侵檢測系統[J].計算機科學,2014,41(12):43-47. [18] 伍海波,高勁松,唐啟濤,等.基于生物免疫原理的網絡入侵檢測研究[J].計算機技術與發展,2013,23(7):167-170. ApplicationofImprovedImmuneClonalSelectionAlgorithminIntrusionDetection NIUYong-jie,XUENing-jing (CollegeofMathematics&ComputerScience,Yan’anUniversity,Yan’an716000,China) Inordertoimprovethecorrectrateofintrusiondetectionsystemandreducefalsepositiverate,onthebasicimmuneclonalselectionalgorithmusingantibodyclonenumberandaffinityisproportionaltothedegreeandthenumberofcloneslineardecreasing,mutationprobabilitydecreasinglinearly,newreplacementstrategy,thenumberofmutationprobabilityandantibodyclonalmutationforimprovement.Theimprovementofantibodycloningstrategytoensuretheconvergencespeedofthealgorithmandavoidtheshockofthelate.Adaptivechangesinthemutationprobabilitystrengthentheconvergenceofthealgorithmforthelate.Newreplacementstrategyandthenumberofmutationprobabilityandantibodyclonalmutationscaneffectivelyavoidthealgorithmintoalocaloptimum.AfterthetrainingandtestingforCupKDD1999dataset,theimprovedalgorithmhastheadvantagesofhigherdetectionaccuracyrateandlowerfalsedetectionrate,withfastconvergencespeed,anditisnoteasyto“premature”. intrusiondetection;clonalselection;mutationprobability;cloningstrategy;adaptive 2015-06-19 2015-09-24 時間:2016-05-05 陜西省自然科學研究項目(14JK1828) 牛永潔(1977-),男,碩士,講師,CCF會員,研究方向為數據挖掘、智能算法、網絡安全。 http://www.cnki.net/kcms/detail/61.1450.TP.20160505.0815.036.html TP A 1673-629X(2016)05-0086-05 10.3969/j.issn.1673-629X.2016.05.018
4 仿真實驗

5 結束語
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
