基于大數據的時間序列預測研究與應用
2016-02-27 03:52:16程艷云張守超
計算機技術與發(fā)展 2016年6期
程艷云,張守超,楊 楊
(南京郵電大學 自動化學院,江蘇 南京 210023)
基于大數據的時間序列預測研究與應用
程艷云,張守超,楊 楊
(南京郵電大學 自動化學院,江蘇 南京 210023)
針對傳統(tǒng)時間序列預測算法在分析海量數據時預測精度與預測速率低下的問題,提出一種全新的時間序列預測算法,研究如何將大數據技術應用到移動通信網時間序列形式的核心性能指標(KPI)預測中。文中首先介紹了移動通信網性能指標預測的意義及傳統(tǒng)時間序列預測算法的缺陷。其次,基于移動通信網及時間序列特性,給出了基于大數據的時間序列預測算法的理論推導過程,通過大數據方法將時間序列分解為四個不同分量并進行特征提取,根據提取結果進行預測分析。最后,介紹了方法的實現過程,采用真實網絡核心性能指標進行實驗對比分析,驗證該方法的可行性與效率。實驗結果表明,基于大數據的時間序列預測算法相比于傳統(tǒng)的時間序列預測算法,具有更高的預測精度、更快的預測速率。
大數據;時間序列;預測分析;移動通信
0 引 言
通信網絡中的各項核心性能指標[1](KPI)的預測分析對于通信網絡優(yōu)化至關重要,而通信網絡中的各項KPI一般均以時間序列形式[2]表示。傳統(tǒng)的時間序列分析預測方法包括Holt-Winters[3]、ARIMA[4]、AR、MA、Vector Auto Regression、梯度回歸等。然而,傳統(tǒng)的通信網性能預測分析所選用的數據量很小且缺乏實時性,實驗結果的準確率也有待提高,而且隨著時間的推移,通信網絡中的數據量越來越大。到2020年,全球以電子形式存儲的數據量將達35 ZB,是2009年全球存儲量的40倍[5]。如此大的數據量,傳統(tǒng)的數據庫工具無法負擔,必須采用專用數據挖掘與分析工具進行分析處理。不過,盡管這些數據挖掘工具價格昂貴,挖掘效果卻仍有待提高。
因此,必須采用新的方法來解決這一問題。文中提出的基于統(tǒng)計模型的大數據算法分析利用真實的測量數據而不是模擬仿真數據或假設場景來研究無線網絡的預測問題。文中首先利用統(tǒng)計模型對海量數據進行分類處理,并進行特征提取,區(qū)分小區(qū)類別,然后采用大數據算法分析海量實時數據,并對建立的模型進行參數優(yōu)化,最終得到預測模型。
1 大數據算法分析
時間序列預測算法主要包括趨勢分量預測、季節(jié)性分量預測、突發(fā)分量預測以及隨機誤差分量預測。以傳統(tǒng)的時間序列預測算法為例,Holt-Winters算法中α,β,γ分別為水平項、趨勢項、周期項的平滑參數。由于α,β,γ一旦確定就不可以改變,且需要反復試驗確定最佳值,因此傳統(tǒng)的Holt-Winters算法對于長期大量的數據分析是不適合的[6]。而ARIMA僅在短期預測中有較好的預測結果,隨著預測時間的推遲,其預測誤差會越來越大[7],因此ARIMA對于長期數據預測是不符合要求的。文獻[8-9]對Holt-Winters進行了一些改進,文獻[10]對ARIMA進行了一些改進,但是對于海量數據的長時間預測效果,其結果仍然不符合要求,所以必須采用新的時間序列預測模型來進行預測分析。
文中提出的大數據算法采用全新的方法來對四個分量進行預測。利用海量數據的優(yōu)點,將隱藏在數據背后的有效信息挖掘出來,具體推導過程如下所示:
(1)趨勢分量T(t)的預測。
將每一段的起始無線網絡話務量歷史數據Xk和斜率Slopek擬合為一條直線,每個擬合線間首尾連續(xù),將無線網絡話務量歷史數據作為訓練樣本進行建模,獲得趨勢分量T(t)預測模型:
(1)
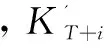
圖1展示了趨勢分量預測過程。

圖1 趨勢分量預測過程
如此一來,對于趨勢分量T(t)的預測,預測值之前數據的權重變成由歷史數據Xk和斜率Slopek決定。
(2)季節(jié)性分量S(t)的預測。
文中首先需要確認的是周期時間,通過統(tǒng)計分析對海量數據進行特征提取,按照式(2)進行差分運算,得到矩陣A。
(2)
對矩陣A的每一行進行線性擬合,得到不同的擬合直線Y=aX+b,其中擬合誤差最小的行數即為周期L。p表示每個周期L里的樣本數,每個q(q=1,2,…,p)位置處的季節(jié)分量可表示為p樣本中相同位置q處的數據的平均值,利用式(3)可得出季節(jié)性分量。
(3)
(3)突發(fā)分量B的預測。
突發(fā)分量B產生的原因一般是由于突發(fā)事件,比如重大節(jié)日、活動、會議等。一般情況下,突發(fā)分量具有可列舉性,即每個小區(qū)的KPI對應的突發(fā)分量B都可以用特定的類別對應特定的數值表示,如式(4):
B(t)value={Burstv1,Burstv2,…,Burstvn}
(4)
在KPI分析預測中,只需要根據小區(qū)的ID號,查找對應的突發(fā)分量B(t)帶入預測公式即可。
(4)隨機誤差分量R的預測。
在大數據預測模型中,隨機誤差分量不再是獨立分布,而是根據無線網絡話務量歷史數據減去趨勢分量、季節(jié)性分量和突發(fā)分量得到隨機誤差分量的預估值。處理的結果確保了隨機誤差分量更具有實際性。
(5)KPI預測。
預測目標KPI時,利用公式X(t)=(1+B(t))×(T(t)+S(t)+R(t))即可得到目標結果。
2 大數據算法在KPI預測中的實現
在通信網中,每個RNC下包含大量的小區(qū)(一般為500~1 000),而每個小區(qū)的KPI又數量眾多(一般為200個)。以一年時間為周期計算,每個KPI每年數據值為17 520個,單個RNC內所有小區(qū)的一年內所有KPI總數將過億。考慮到數據量巨大,采用大數據進行的KPI預測分析,需要對小區(qū)數據進行一定的處理,具體步驟如圖2所示。
步驟1:插值處理。
在數據導入之前,需要對數據進行預處理,處理的主要工作為缺值插入。文中采用的插入方法為構建線性擬合曲線,具體做法為以缺失值前幾點、后幾點作為一個數據序列,做一個最小二乘法的線性回歸[11],將對應缺失的這點代入線性回歸方程,得出缺失點的值。

圖2 大數據預測模型流程圖
步驟2:小區(qū)分類。
對所有小區(qū)進行分類處理,將所有小區(qū)的忙時進行特征提取,得到不同忙時的特征,區(qū)分出不同類別的小區(qū),然后再對每種類型的小區(qū)進行分析預測。小區(qū)類別事先未知,文中采用統(tǒng)計方法,將所有RNC下所有小區(qū)的一天KPI特性進行統(tǒng)計分析,得到不同時間分布的忙時,從而得到不同類別的小區(qū)。
步驟3:異常值排除。
對于每種類型數據,取可信度95%,其邊界為u-2σ和u+2σ,來排除異常值。如果時間序列不符合正態(tài)分布,則不能通過測試,此時應該采用其他方法來排除異常值。
步驟4:預測分析。
排除異常值之后,根據特征提取結果確定一維周期值[12-13],利用大數據算法分別進行趨勢分量預測、季節(jié)性分量預測、突發(fā)分量預測及隨機誤差分量預測。
步驟5:結果判定。
對于分別預測得到的趨勢分量、季節(jié)性分量、突發(fā)分量以及隨機誤差分量,通過公式X(t)=(1+B(t))×(T(t)+S(t)+R(t))得到最終預測值,判別與真實值之間誤差是否在可接受范圍內,若是,則模型建立成功,若否,返回修改模型參數。
3 實驗結果
以通信網絡中某一性能指標(RRC設置成功率)為例。首先任取某一小區(qū),采用不用方法分別對該小區(qū)的RRC設置成功率進行長期預測和短期預測,并對結果進行對比分析;其次,對RNC內所有小區(qū)進行預測,并對結果進行分析比較。
首先對所有RNC內的小區(qū)進行分類處理,根據忙時不同特征分布可以區(qū)分得到7種不同類型的小區(qū)。選取某一類型小區(qū)的某一小區(qū)連續(xù)30天數據為初始數據集,分別采用不同算法預測不同長度值。先進行周期特征提取,按照式(2)得到矩陣A,并對A的每行數據進行線性擬合。對于每條擬合直線,采用最小二乘法計算誤差,通過計算得到當L=48時,誤差最小,即周期為48。
圖3展示了Bigdata算法對應不同周期L的預測結果。其中點代表預測值,線條代表真實值走勢,虛線表示初始值與預測值分界線。

圖3 Bigdata算法對應不同周期L的預測結果
圖4展示了RRC設置成功率的實際值與Holt-Winters算法、ARIMA算法以及基于大數據算法的預測值對比結果。顯而易見,基于大數據算法的預測結果與實際值具有很大的重合性。

圖4 單小區(qū)RRC設置成功率預測結果對比圖
通過統(tǒng)計計算可以得到,在大數據預測模型中,初始數據預測的平均絕對百分比精度[14](誤差結果在1%以內)是95.28%,預測結果平均絕對百分比精度是90.47%。相比于Holt-Winters算法、ARIMA算法的78.28%和70.1%均有很大提高。
表1展示了Bigdata算法、Holt-Winters算法和ARIMA算法三者在長/短期初始數據預測與結果預測精度對比。
通過表中數據可以得到,基于大數據的方法在長期預測跟短期預測的精度差距很小,尤其在預測結果精度方面,而基于Holt-Winters方法和ARIMA方法的預測在長期跟短期結果出現大幅度的下降,即基于大數據方法相比于Holt-Winters方法和ARIMA方法更加適用于長期的時間序列預測。此外,短期預測中三種方法所需時間均在20s內,但是在長期大量數據預測時,基于大數據的方法所需時間僅為另外兩種方法的一半,約為100s。

表1 不同方法對應長/短期預測結果對比 %
同樣選取商業(yè)型小區(qū)的某一RNC級別內所有小區(qū)(共計478),預測某天(周一)忙時(晚上8點)所有小區(qū)的性能指標值。圖5展示了RNC內所有小區(qū)的實際值與預測值對比,其中點代表預測,線條代表真實值走勢。
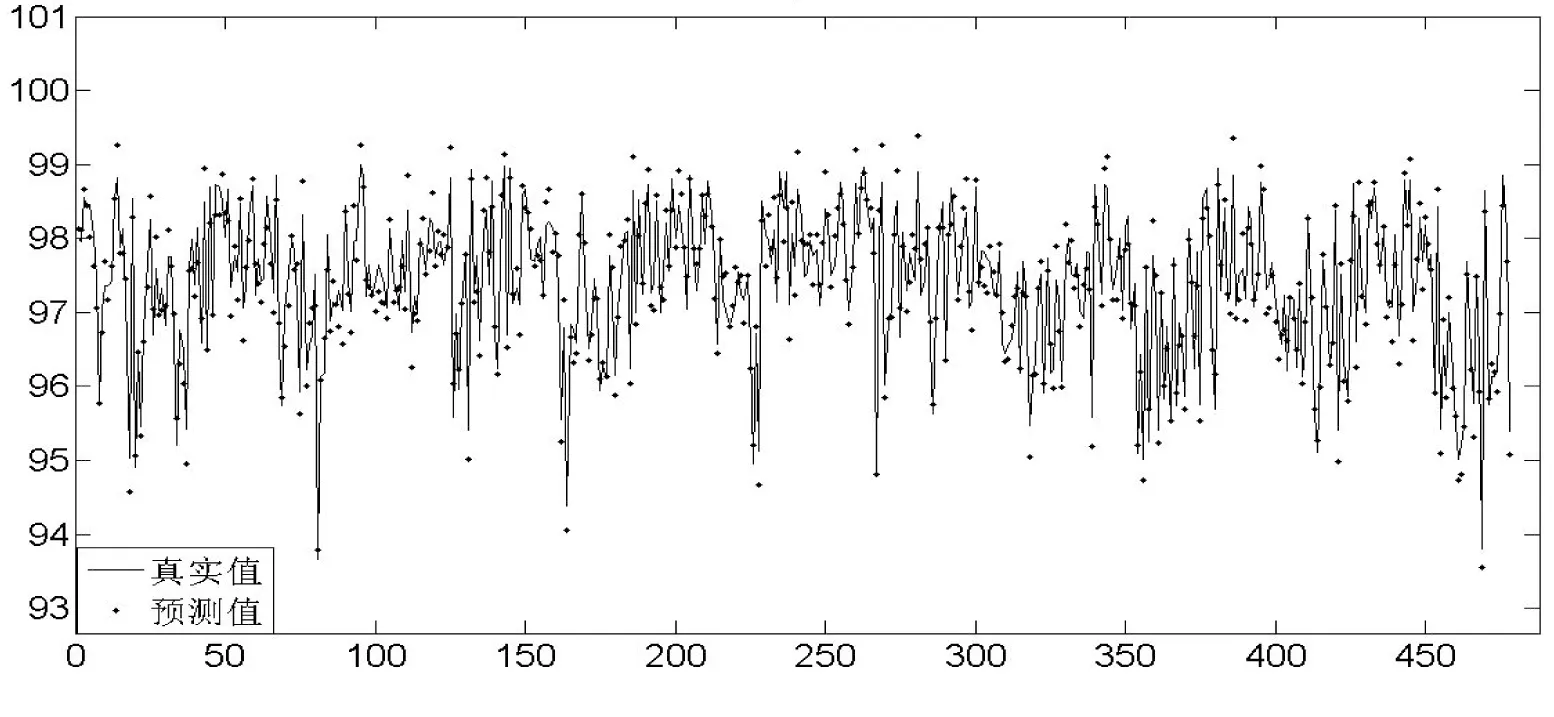
圖5 RNC級小區(qū)RRC預測值對比圖
在大數據預測模型中,所有小區(qū)性能指標的預測值平均絕對百分比精度是84.66%,高于傳統(tǒng)方法的預測精度。
通過分析比較結果可以得出,基于大數據的預測模型的預測結果在長時間預測、大范圍預測均能滿足要求,相比于傳統(tǒng)的預測方法,采用大數據技術的預測模型具有更高的精度以及更快的速度。總體來說,通信網絡中的KPI都可以通過預測模型得到結果,這兩項數值都在可以接受的范圍內,并且未來還有提高的空間,尤其對于單小區(qū)的長時間預測結果精度。
4 結束語
新穎的大數據技術及其算法可以克服傳統(tǒng)網絡仿真中的缺點,基于統(tǒng)計模型的大數據算法的無線網絡性能分析將使得網絡特征、用戶特征、話務流量特征等在網絡性能分析評估中得到最準確和最真實的反應[15]。文中的大數據算法模型將使得埋藏在海量數據背后的網絡行為特征得以準確挖掘出來,從而使得傳統(tǒng)的網絡性能分析這一領域到達一個新的臺階。
文中僅對網絡KPI進行預測分析,對于網絡優(yōu)化中的其他問題,還有待進一步的研究,包括:
(1)預測網絡話務和流量的短期—長期趨勢;
(2)基于網絡話務來推測網絡容量的變化趨勢。
中國從2013開始大規(guī)模商用TDDLTE網絡,此方法采用基于大數據的算法分析的網絡性能以及質量評估系統(tǒng),采用實時數據進行預測分析,預測結果也能夠滿足需求,在未來具有很高的應用前景。
[1]RAN14.0KPI參考手冊—2版[M].出版地不詳:華為技術有限公司,2012.
[2] 林國華.時間序列分析法在移動通信數據分析中的研究與應用[D].廣州:廣州工業(yè)大學,2013.
[3]SzmitM,SzmitA.Useofholt-wintersmethodintheanalysisofnetworktraffic:casestudy[J].CommunicationsinComputer&InformationScience,2011,160:224-231.
[4]BoxGEP,JenkinsGM,ReinselGC.時間序列分析:預測與控制[M].王成璋,尤梅芳,郝 楊,譯.上海:機械工業(yè)出版社,2011.
[5] 林 丹.4G移動通信技術的現狀與發(fā)展趨勢探討[J].科技信息,2013(24):241-241.
[6]RossiM,BrunelliD.ForecastingdatacenterspowerconsumptionwiththeHolt-Wintersmethod[C]//ProcofIEEEworkshoponenvironmental,energyandstructuralmonitoringsystems.[s.l.]:IEEE,2015.
[7] 張小斐,田金方.基于ARIMA模型的短時序預測模型研究與應用[J].統(tǒng)計教育,2006(10):7-9.
[8] 彭帥英,李廣杰,彭 文,等.基于改進遺傳算法的Holt-Winters模型在采空沉陷預測中的應用[J].吉林大學學報:地球科學版,2013,43(2):515-520.
[9] 吳越強,吳文傳,李 飛,等.基于魯棒Holt-Winter模型的超短期配變負荷預測方法[J].電網技術,2014,38(10):2810-2815.
[10]LiC,ChiangTW.ComplexneurofuzzyARIMAforecasting—anewapproachusingcomplexfuzzysets[J].IEEETransactionsonFuzzySystems,2013,21(3):567-584.
[11] 田 垅,劉宗田.最小二乘法分段直線擬合[J].計算機科學,2012,39(6A):482-484.
[12] 段江嬌.基于模型的時間序列數據挖掘—聚類和預測相關問題研究[D].上海:復旦大學,2008.
[13] 微軟中文.大數據挖掘算法之:Microsoft決策樹算法[EB/OL].[2014-10-13].http://www.thebigdata.cn/JieJueFangAn/12096.html.
[14]ZiebarthNL,AbbottKC,IvesAR.Weakpopulationregulationinecologicaltimeseries[J].EcologyLetters,2010,13(1):21-31.
[15]WuX,ZhuX,WuGQ,etal.Dataminingwithbigdata[J].IEEETransactionsonKnowledge&DataEngineering,2014,26(1):97-107.
Research and Application of Time Series Forecasting Based on Big Data
CHENG Yan-yun,ZHANG Shou-chao,YANG Yang
(College of Automation,Nanjing University of Posts and Telecommunications,Nanjing 210023,China)
According to the detection accuracy and efficiency limitation of traditional time series forecasting methods when dealing with a large amount of data,a new time series forecasting method is put forward to study how to apply the big data technology into Key Performance Index (KPI) prediction of mobile communication network,which is form of time series.First,it introduces the significance of KPI prediction for mobile communication network and the defects of traditional time series prediction algorithm in this paper.Secondly,the theoretical derivation of time series prediction algorithm based on the big data is presented according to the characteristics of mobile communication network and time series.The time series is decomposed into four different components and the feature is extracted by the big data method,and the forecasting analysis is carried out according to the results of the extraction.Finally it gives implementation process and uses the real network KPI to carry out experimental comparative analysis for verification of the feasibility and efficiency of the big data method.The experimental results show that the big data method has higher precision and rate compared with traditional methods.
big data;time series;forecasting analysis;mobile communication
2015-06-28
2015-10-13
時間:2016-03-22
江蘇省自然科學基金(BK20140877,BE2014803)
程艷云(1979-),女,副教授,碩士生導師,從事自動控制原理、網絡優(yōu)化的教學科研工作;張守超(1991-),男,碩士研究生,研究方向為大數據挖掘在通信網絡中的應用。
http://www.cnki.net/kcms/detail/61.1450.TP.20160322.1518.040.html
TN915.07
A
1673-629X(2016)06-0175-04
10.3969/j.issn.1673-629X.2016.04.039
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
山東工業(yè)技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中國中醫(yī)藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
