共詞分析中的詞匯遴選方法研究
2016-03-21 11:08:08,,,,
中華醫(yī)學(xué)圖書(shū)情報(bào)雜志 2016年4期
,,, ,
共詞分析方法屬于內(nèi)容分析方法的一種,其原理是當(dāng)兩個(gè)能夠表達(dá)某一學(xué)科領(lǐng)域研究主題或研究方向的專(zhuān)業(yè)術(shù)語(yǔ)(一般為主題詞或關(guān)鍵詞)在同一篇文獻(xiàn)中出現(xiàn)時(shí),表明這兩個(gè)詞之間具有一定的內(nèi)在關(guān)系,并且出現(xiàn)的次數(shù)越多,表明它們的距離越近、關(guān)系越密切[1-2],據(jù)此可以歸納出該學(xué)科的研究熱點(diǎn)、結(jié)構(gòu)與范式。由于共詞分析方法靈活、結(jié)果直觀,所尋找的是當(dāng)前研究重點(diǎn)關(guān)注的主題,在揭示文本數(shù)據(jù)的信息單元之間的關(guān)系方面更加有效,能夠反映研究前沿,并且對(duì)當(dāng)前發(fā)表的文獻(xiàn)直接進(jìn)行統(tǒng)計(jì),不需要龐大的引文索引作為基礎(chǔ),具有較好的時(shí)間效應(yīng)。因此成為快速識(shí)別學(xué)科發(fā)展的重要方法,在各學(xué)科領(lǐng)域得到了廣泛的應(yīng)用。
1 詞匯遴選和閾值確定方法研究現(xiàn)狀
在共詞分析中,詞匯遴選是共詞分析的重要階段。如果將所有的詞匯用于分析,不僅會(huì)造成巨大的運(yùn)算量,而且由此帶來(lái)的稀疏矩陣會(huì)對(duì)結(jié)果的準(zhǔn)確性造成影響。因此用于分析的詞匯能在多大程度上代表文獻(xiàn)內(nèi)容,同時(shí)又能夠確保分析過(guò)程快速及結(jié)果準(zhǔn)確是一個(gè)需要研究的問(wèn)題。為了了解目前共詞分析中的詞匯遴選方法,筆者對(duì)CNKI數(shù)據(jù)庫(kù)中的相關(guān)論文進(jìn)行了分析。檢索式為:SU='共現(xiàn)' or SU='聚類(lèi)分析' or SU='共詞' or TI='共現(xiàn)'or TI='聚類(lèi)分析' or TI='共詞',時(shí)間選擇2001-01-01到2012-12-31,學(xué)科領(lǐng)域選擇“圖書(shū)情報(bào)與數(shù)字圖書(shū)館”,共檢索到640條記錄(檢索時(shí)間為2013年12月)。按照被引次數(shù)降序排列,選擇被引10次以上,并且涉及共詞分析具體應(yīng)用的文獻(xiàn)37篇。對(duì)文獻(xiàn)所用詞匯遴選方法與步驟進(jìn)行了統(tǒng)計(jì)分析,去掉方法研究類(lèi)和綜述類(lèi)論文,最終篩選出30篇關(guān)于共詞分析方法應(yīng)用的高被引文獻(xiàn)。整理和統(tǒng)計(jì)了每篇文獻(xiàn)的詞匯遴選方法,包括高頻詞的閾值、用于分析的詞匯個(gè)數(shù),結(jié)果表明在共詞分析的詞匯選擇階段,特別是閾值確定環(huán)節(jié)存在問(wèn)題,主要表現(xiàn)在以下兩個(gè)方面。
一是高頻詞更受關(guān)注,中低頻詞鮮有涉及。所統(tǒng)計(jì)的30篇文獻(xiàn)均選取高頻詞進(jìn)行分析。雖然中低頻詞不利于聚類(lèi),但有助于觀測(cè)一些隱含主題或前瞻主題的外現(xiàn)[3],因此對(duì)于新興研究領(lǐng)域、研究現(xiàn)狀、研究前沿等方面的發(fā)現(xiàn)有一定的意義。如果完全忽略中低頻詞,結(jié)果的準(zhǔn)確性可能會(huì)受到影響。
二是高頻詞的閾值確定標(biāo)準(zhǔn)不一,主觀經(jīng)驗(yàn)成為主要方法。在筆者所調(diào)研的文獻(xiàn)中,90%的文獻(xiàn)均沒(méi)有對(duì)閾值選擇方法進(jìn)行說(shuō)明就直接給出了結(jié)果,所選擇的閾值從2到100不等。國(guó)內(nèi)學(xué)者對(duì)閾值選擇方法也有過(guò)研究[3],認(rèn)為目前國(guó)內(nèi)外高頻詞選取方法各異,大多數(shù)學(xué)者根據(jù)經(jīng)驗(yàn)直接選取高頻詞。除此之外,根據(jù)關(guān)鍵詞累積頻次選取一定比例以及齊普夫第二定律也被一些學(xué)者所采用。 如依據(jù)“二八定律”選擇占所有詞匯中前20%的高頻詞[4],或者在詞頻總數(shù)中選擇一定百分比的詞頻[5]。文獻(xiàn)[6-7]則根據(jù)齊普夫第二定律中高頻詞與低頻詞的界分公式得到高頻詞閾值。該方法相對(duì)于上述方法較為科學(xué),而且計(jì)算簡(jiǎn)單。但是齊普夫第二定律公式的依據(jù)和推理并不嚴(yán)密[8],因?yàn)橐黄墨I(xiàn)要受到多種隨機(jī)因素的影響,如語(yǔ)種、作者、文獻(xiàn)長(zhǎng)度等,要以一個(gè)簡(jiǎn)單的公式包容所有的情形是不可能的。
進(jìn)入大數(shù)據(jù)時(shí)代,數(shù)據(jù)量越來(lái)越大,情報(bào)研究對(duì)數(shù)據(jù)分析粒度、分析時(shí)間和效率的要求也更高。因此要求計(jì)算機(jī)系統(tǒng)能夠?qū)崿F(xiàn)情報(bào)分析的自動(dòng)處理,而計(jì)算機(jī)需要標(biāo)準(zhǔn)化的流程和方法,盡量減少人為的干預(yù)。由此可見(jiàn),通過(guò)簡(jiǎn)便、規(guī)范的詞匯遴選和詞頻閾值選擇方法來(lái)確定待分析的詞匯是目前需要解決的重要課題。本文對(duì)詞匯遴選,特別是詞頻閾值選擇方法進(jìn)行分析,并提出了簡(jiǎn)便易行的確定方法。
2 共詞分析中的詞匯遴選方法研究
為了排除同義詞歸并、停用詞表構(gòu)建等問(wèn)題的干擾,確保詞匯能夠充分代表文獻(xiàn)內(nèi)容,本文選擇主題詞進(jìn)行分析,從而只考慮共詞分析在詞匯遴選過(guò)程中存在的問(wèn)題。在進(jìn)行文獻(xiàn)集合內(nèi)容分析時(shí),所選取的詞匯集合一定要最大程度地表示所選擇文獻(xiàn)集合的內(nèi)容。而文獻(xiàn)集合的最小單元是單篇文獻(xiàn),詞匯集合的最小單元是每個(gè)詞匯,因此我們基于詞匯與文獻(xiàn)的關(guān)系對(duì)詞匯選取方法進(jìn)行分析。
2.1 詞匯與文獻(xiàn)內(nèi)容的關(guān)系分析
應(yīng)用共詞分析方法的前提是文獻(xiàn)中的關(guān)鍵詞在一定程度上代表了文獻(xiàn)的內(nèi)容。在共詞分析方法之外,文本挖掘、文本分類(lèi)等多個(gè)領(lǐng)域中都涉及到選取特征值、選取特征向量的問(wèn)題。如在文本聚類(lèi)中通過(guò)tf-idf算法計(jì)算詞匯在文獻(xiàn)中的重要程度,在文本分類(lèi)中通過(guò)卡方值計(jì)算該詞與該類(lèi)間關(guān)系強(qiáng)度,卡方值被認(rèn)為是文本分類(lèi)中較為準(zhǔn)確的方法。盡管上述方法在文本分析中表現(xiàn)出色,但是并不適用于一般的共詞分析,因?yàn)槊總€(gè)關(guān)鍵詞或者主題詞只在一篇文獻(xiàn)中出現(xiàn)一次,每個(gè)詞相對(duì)于文檔的權(quán)重也是一樣的,因此并不能用上述的tf-idf等方法進(jìn)行詞匯遴選。
為了解決該問(wèn)題,一些研究者通過(guò)對(duì)標(biāo)題、摘要等內(nèi)容分詞,從而獲得更多的詞匯,但是引入自由詞之后,就出現(xiàn)更為復(fù)雜的詞匯規(guī)范問(wèn)題和語(yǔ)義問(wèn)題。同時(shí)由于缺少完善的詞表支持,不能保證除了關(guān)鍵詞之外,從標(biāo)題和摘要中獲取的其他詞匯能夠全面反映文獻(xiàn)內(nèi)容。因此該方法并不能夠?qū)崿F(xiàn)詞匯的自動(dòng)遴選。
2.2 詞匯集合與文獻(xiàn)集合的關(guān)系分析
在大部分共詞分析文獻(xiàn)中,都有選取X個(gè)詞來(lái)表示文獻(xiàn)的說(shuō)法。其假設(shè)是每篇文獻(xiàn)都用一定數(shù)量的詞來(lái)表示,那么所有詞匯構(gòu)成的集合就能很好地表示文獻(xiàn)集合的內(nèi)容,不過(guò)事實(shí)并非如此。假設(shè)我們?cè)诿科墨I(xiàn)中選取了小于平均關(guān)鍵詞個(gè)數(shù)的N個(gè)詞來(lái)代表該文獻(xiàn),但這并不能保證最終所得到的詞匯集合中的詞匯數(shù)量會(huì)減少很多,因?yàn)殡S著文獻(xiàn)數(shù)量的增加,詞匯增加趨勢(shì)越來(lái)越慢,在文獻(xiàn)量非常大(大于20 000篇)的情況下,甚至并不能明顯減小集合中的詞匯數(shù)量,況且目前還沒(méi)有能夠在每篇文獻(xiàn)中提取關(guān)鍵詞的統(tǒng)一標(biāo)準(zhǔn)和可靠方法。
還有一種方法就是在所有詞構(gòu)成的集合中進(jìn)行篩選其優(yōu)點(diǎn)是能夠精確地控制所選詞匯集合中的詞匯數(shù)量。如上文所述,根據(jù)詞頻的閾值選擇是最常用的方法。
在詞頻閾值的確定方法中,要確保選擇的詞能代表文獻(xiàn)的內(nèi)容,每篇文獻(xiàn)至少需要2-3個(gè)詞來(lái)進(jìn)行表示。如果所選擇詞不僅能夠覆蓋大部分文獻(xiàn)集合,同時(shí)也能夠確保大部分文獻(xiàn)集合中的每篇文獻(xiàn)有2-3個(gè)關(guān)鍵詞,我們就可以認(rèn)為所選擇的集合基本上代表了文獻(xiàn)集合的內(nèi)容。
鑒于以上觀點(diǎn),本文進(jìn)行了以下實(shí)驗(yàn)分析。
3 實(shí)驗(yàn)與分析
我們選擇了干細(xì)胞領(lǐng)域進(jìn)行實(shí)驗(yàn)研究,并選擇了造血干細(xì)胞和結(jié)核病兩個(gè)領(lǐng)域進(jìn)行了驗(yàn)證。干細(xì)胞研究從2000年左右到現(xiàn)在得到了快速發(fā)展,新的研究方法、技術(shù)和發(fā)現(xiàn)層出不窮,文獻(xiàn)量豐富,并且能夠滿(mǎn)足我們從干細(xì)胞領(lǐng)域中選擇較小領(lǐng)域進(jìn)行驗(yàn)證的需求。
3.1 數(shù)據(jù)獲取
選擇“中國(guó)生物醫(yī)學(xué)文獻(xiàn)數(shù)據(jù)庫(kù)”(CBMdisc)為來(lái)源數(shù)據(jù)庫(kù),時(shí)間范圍為2000-2009年,檢索主題詞為干細(xì)胞/全部樹(shù)/全部副主題詞,檢出22 698篇文獻(xiàn)。提取文獻(xiàn)中的主題詞,去掉副主題詞,共得到6 245個(gè)主要主題詞,累計(jì)詞頻155 289,平均每篇文獻(xiàn)6.8個(gè)主題詞。
3.2 高頻詞獲取
對(duì)比分析上文中提到的各種高頻詞獲取方法。
文獻(xiàn)集合內(nèi)詞頻為1的詞共2 073個(gè)(即I1=2073)。根據(jù)齊普夫第二定律公式 ,計(jì)算得到T=142.6,則高頻詞和低頻詞的臨界值為143(表1)。
3.3 高頻詞個(gè)數(shù)與文獻(xiàn)比例關(guān)系分析
按照詞頻順序從高到低排序, Top N個(gè)詞覆蓋的文檔所占總文檔數(shù)的比例見(jiàn)圖1。

表1 二八定律和齊普夫定律計(jì)算結(jié)果
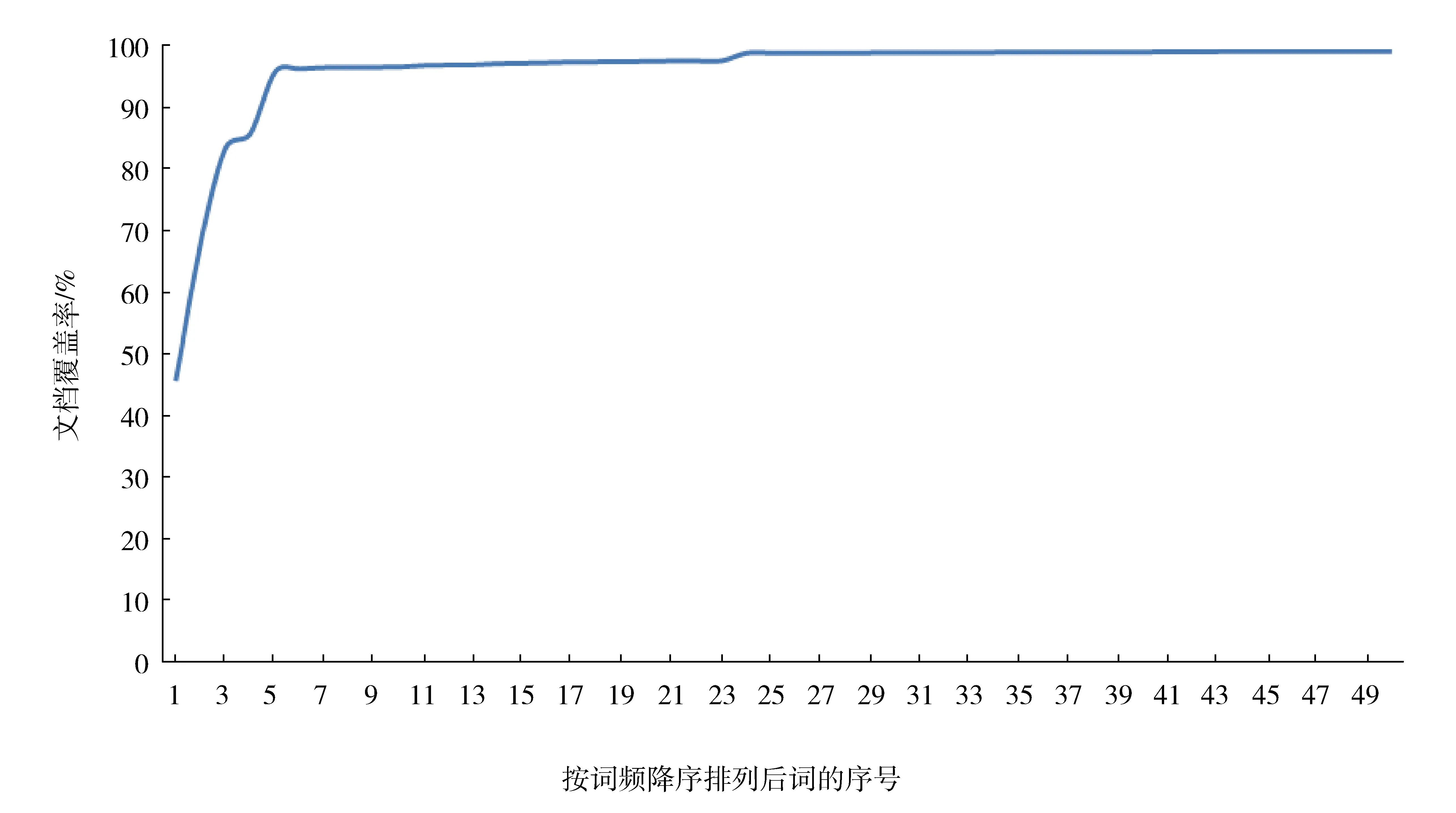
圖1 Top N個(gè)詞的文檔覆蓋率
以往一些研究經(jīng)常會(huì)提到所選擇的詞匯集占整個(gè)文獻(xiàn)集合的比例,這個(gè)結(jié)論會(huì)讓我們誤以為所選擇的詞能夠代表大部分文檔內(nèi)容。通過(guò)該圖我們發(fā)現(xiàn),極少數(shù)的特高頻詞就能覆蓋95%以上的文獻(xiàn),但并不能夠代表所覆蓋文獻(xiàn)的內(nèi)容,可見(jiàn)選擇詞匯數(shù)量和覆蓋文獻(xiàn)比例的相關(guān)關(guān)系并不明顯。
如果只選擇能覆蓋文檔95%的詞匯,就會(huì)造成一些文獻(xiàn)中只有一個(gè)詞來(lái)表示。如在該數(shù)據(jù)集中“干細(xì)胞”的詞頻最高,如果選擇5個(gè)詞來(lái)表示,那么大多數(shù)文獻(xiàn)只能用“干細(xì)胞”來(lái)表示,與結(jié)合數(shù)據(jù)集內(nèi)容進(jìn)行分析的目標(biāo)相去甚遠(yuǎn)。
因此我們必須保證選擇的詞能夠代表整個(gè)數(shù)據(jù)集合中每篇文獻(xiàn)的內(nèi)容,而這一點(diǎn)通過(guò)每篇文獻(xiàn)都需要2-3個(gè)詞來(lái)進(jìn)行表示。為了實(shí)現(xiàn)該目標(biāo),我們首先選擇能夠覆蓋文獻(xiàn)90%的Top N個(gè)詞,構(gòu)成第一個(gè)集合;然后從Top N+1個(gè)詞開(kāi)始,重新選擇能夠覆蓋文獻(xiàn)90%的第二個(gè)集合。依照該方法,在選擇了3次集合之后,該集合可以保證至少有73%的文獻(xiàn)至少有3個(gè)詞來(lái)表示,同時(shí)詞頻的選擇方法滿(mǎn)足高頻詞的確定方法。
干細(xì)胞領(lǐng)域的3個(gè)詞頻集合隨選詞個(gè)數(shù)增加的累積文獻(xiàn)覆蓋率增長(zhǎng)曲線(xiàn)見(jiàn)圖2。我們最終選中了1 536個(gè)詞作為篩選結(jié)果。
每個(gè)區(qū)間中選擇詞匯數(shù)量及相關(guān)數(shù)據(jù)見(jiàn)表2。
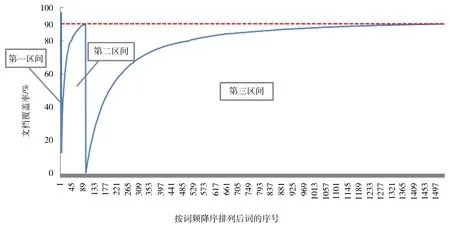
圖2 干細(xì)胞領(lǐng)域詞匯集合的三個(gè)區(qū)間詞匯累積文檔覆蓋率

/%/%1(1-5)50.08336695.72(6-102)971.5324390.03(103-1536)143422.901090.0
最終選取的1 536個(gè)詞匯與傳統(tǒng)的二八定律的結(jié)果接近,但是這種方法能更清楚地說(shuō)明選擇該數(shù)字的意義。
從圖1我們發(fā)現(xiàn),區(qū)間1中曲線(xiàn)接近直線(xiàn),增長(zhǎng)速度極快,我們可以將該區(qū)間定義為高頻詞;區(qū)間2和區(qū)間3接近對(duì)數(shù)函數(shù),表明增長(zhǎng)穩(wěn)定,我們可以將該區(qū)域看作是中頻次區(qū)域。在共詞分析時(shí),可以根據(jù)目的的不同,選擇恰當(dāng)?shù)膮^(qū)域以選取詞匯。
3.4 方法驗(yàn)證
為了驗(yàn)證該方法在不同領(lǐng)域選詞的結(jié)果,我們重新選擇了兩個(gè)領(lǐng)域進(jìn)行分析,考慮到需要對(duì)不同數(shù)量的文獻(xiàn)集合進(jìn)行分析,因此選擇了結(jié)核病和造血干細(xì)胞領(lǐng)域(表3)。
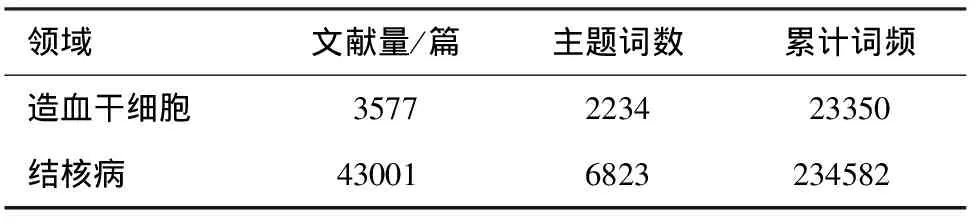
表3 結(jié)核病和造血干細(xì)胞文獻(xiàn)數(shù)據(jù)
結(jié)核病文獻(xiàn)量接近干細(xì)胞文獻(xiàn)集合的2倍,而主題詞個(gè)數(shù)卻很接近,再一次說(shuō)明了文獻(xiàn)量達(dá)到一定數(shù)量后,詞匯的增長(zhǎng)趨勢(shì)越來(lái)越緩慢,并接近于某一個(gè)值。
而造血干細(xì)胞領(lǐng)域的文獻(xiàn)較少,因此主題詞也較少。
為了便于顯示,每個(gè)區(qū)間用單獨(dú)的圖表示,造血干細(xì)胞領(lǐng)域和結(jié)核病領(lǐng)域中詞匯累積文檔覆蓋率見(jiàn)圖3和圖4。兩個(gè)文獻(xiàn)集合的3個(gè)區(qū)間及相關(guān)數(shù)值見(jiàn)表4。
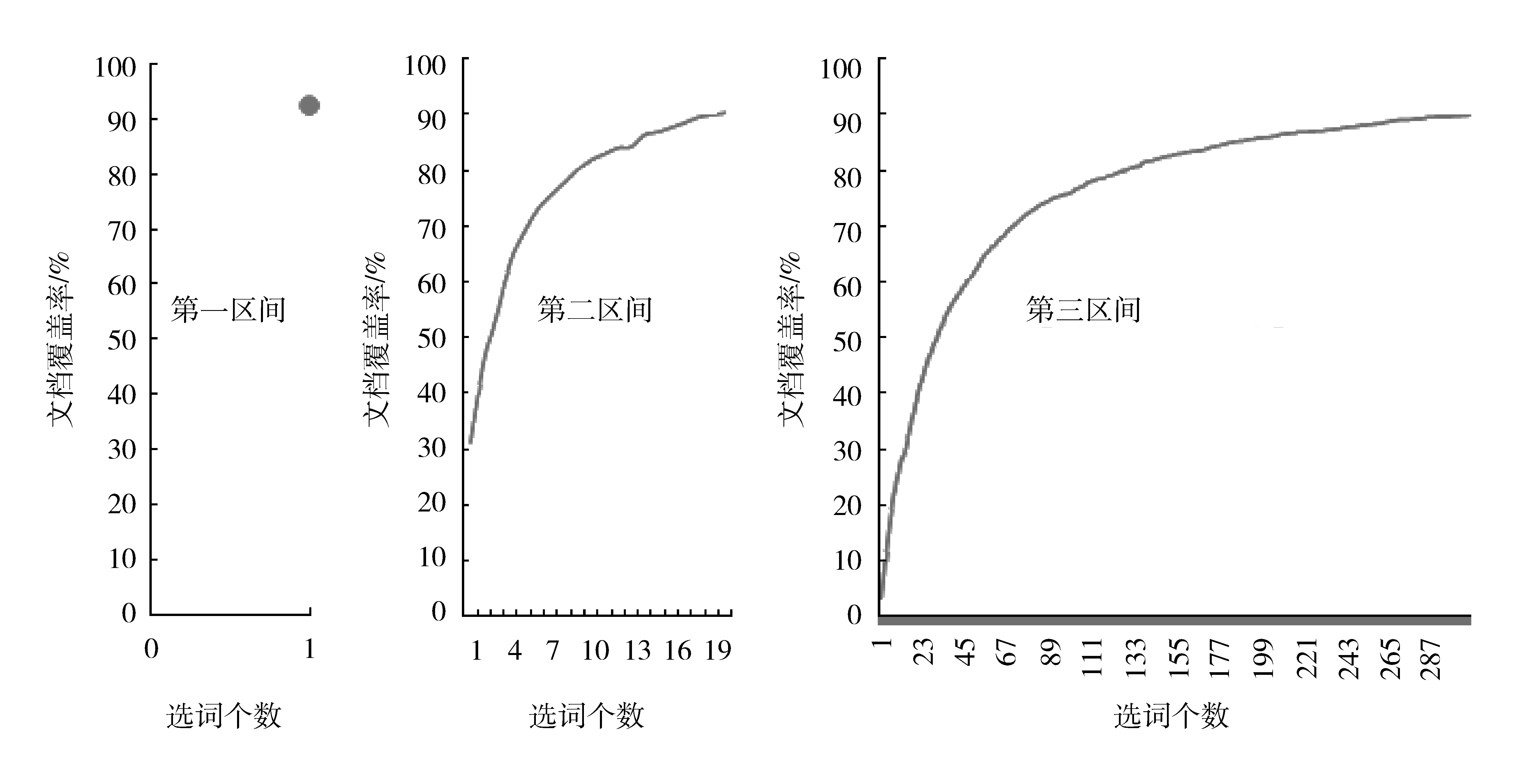
圖3 造血干細(xì)胞領(lǐng)域詞匯集合的三個(gè)區(qū)間詞匯累積文檔覆蓋率
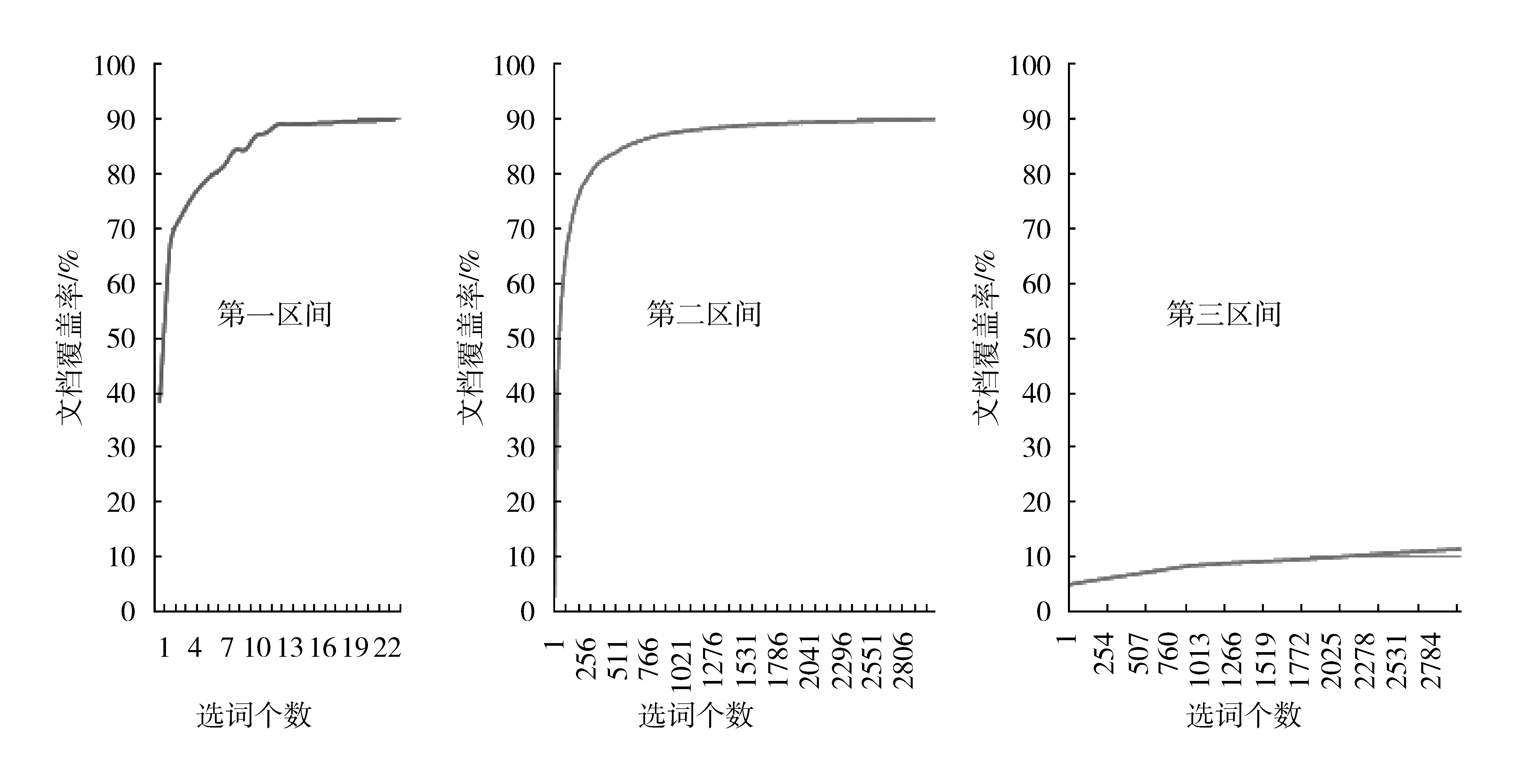
圖4 結(jié)核病領(lǐng)域詞匯集合的三個(gè)區(qū)間詞匯累積文檔覆蓋率
從圖3和表4可以看到,文獻(xiàn)數(shù)量較少的造血干細(xì)胞領(lǐng)域在3個(gè)區(qū)間中共選擇了329個(gè)詞,占總詞匯數(shù)的15%左右,同時(shí)3個(gè)區(qū)間所覆蓋的文獻(xiàn)都達(dá)到了90%,因此我們認(rèn)為這個(gè)詞的集合符合共詞分析的基礎(chǔ)。
從圖4和表4還可以看到,在結(jié)核病領(lǐng)域,前兩個(gè)區(qū)間的詞匯占所有詞匯總數(shù)的45%;第三個(gè)區(qū)間選定了剩下的所有詞,但是文獻(xiàn)比例才達(dá)到了11.4%,其原因是文獻(xiàn)量過(guò)多。這種情況不僅會(huì)造成選擇的詞匯量很大,而且文獻(xiàn)的覆蓋率較低,不能很好地表示文獻(xiàn)內(nèi)容。因此需要減少文獻(xiàn)集合數(shù)量,找到隨文獻(xiàn)增加而詞匯總量變化趨勢(shì)變緩的臨界點(diǎn),確定文獻(xiàn)的數(shù)量。
這種方法并不適合所有領(lǐng)域,需要檢驗(yàn)文檔數(shù)和詞匯總個(gè)數(shù)之間的關(guān)系,從而確定是否使用這種方法。
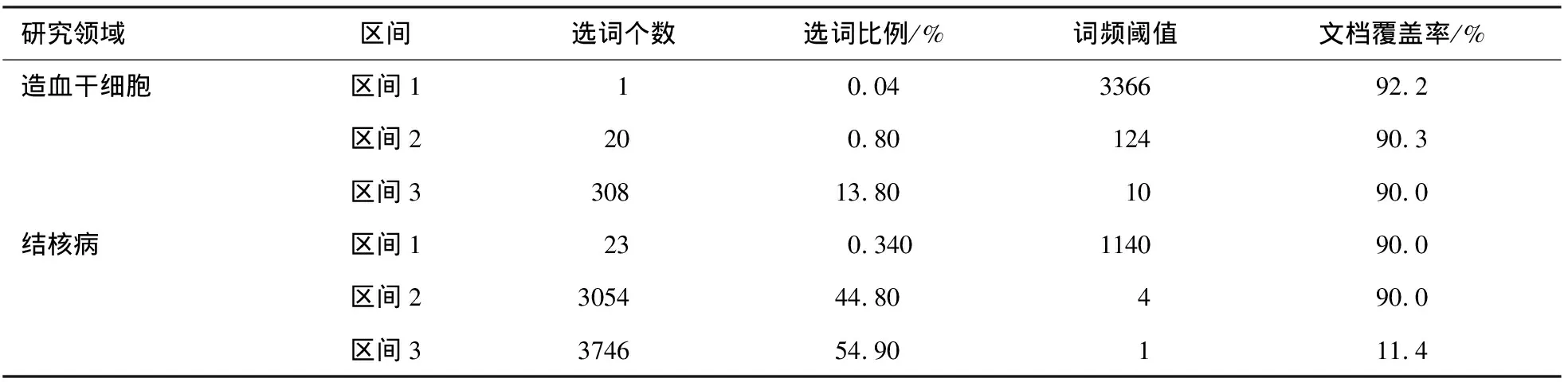
表4 造血干細(xì)胞和結(jié)核病領(lǐng)域的詞匯區(qū)間
通過(guò)以上分析可以發(fā)現(xiàn),文獻(xiàn)量越大,選擇占總詞匯相同百分比的詞覆蓋的文獻(xiàn)比例越小,所以選擇合適數(shù)量的文獻(xiàn)集合是重要的;在文獻(xiàn)達(dá)到一定數(shù)量后,文獻(xiàn)量的大小和詞匯總數(shù)之間是對(duì)數(shù)函數(shù)關(guān)系,這可以幫助我們確定文獻(xiàn)數(shù)量;通過(guò)上述方法,可以得到高頻詞和中頻詞。
4 結(jié)論
本文討論了影響共詞分析中詞匯遴選效果的眾多因素,并就如何確定詞匯集合提出了設(shè)想和驗(yàn)證分析。
該方法的基礎(chǔ)是按照詞頻降序排列,從中選取某一閾值以上的詞能夠表示文檔集合內(nèi)容,然后再確定詞的數(shù)量。該方法同時(shí)考慮了詞頻和文檔比例,并能夠確定大部分文檔都能夠用2-3個(gè)詞進(jìn)行表示,相對(duì)于僅僅依靠詞頻閾值來(lái)說(shuō),提出了較為科學(xué)的依據(jù)和方法。
但是該方法不適用大數(shù)據(jù)量文獻(xiàn)的問(wèn)題仍有待解決,按詞頻降序排列的詞匯能否表示文獻(xiàn)內(nèi)容也有待研究。
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
民用飛機(jī)設(shè)計(jì)與研究(2020年4期)2021-01-21 09:15:02
山東醫(yī)藥(2020年34期)2020-12-09 01:22:24
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
電子制作(2018年18期)2018-11-14 01:48:24
山東工業(yè)技術(shù)(2016年15期)2016-12-01 05:31:22
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
中華胰腺病雜志(2012年3期)2012-11-07 05:18:45
