徐州醫學院圖書館自建麻醉學特色數據庫關鍵技術
2016-03-22 05:40:34
中華醫學圖書情報雜志 2016年5期
特色數據庫是指針對用戶的信息需求,對某一學科或某一專題有價值的信息進行收集、分析、評價、處理、儲存,并按照一定標準和規范將特色資源數字化,以滿足用戶個性化需求的信息資源庫。醫學院校圖書館必須根據本院的學科優勢、專業特點等因素,選擇特色專題并結合本館的相關應用實際進行特色數據庫的建設,使所建的特色數據庫既有較高的學術價值,又具有良好應用前景[1]。
1 建設麻醉學特色數據庫的背景及意義
徐州醫學院(以下簡稱“我校”) 圖書館目前館藏100余萬冊,其中麻醉學等方面的圖書有1 500多種,還購買了中國知網數據庫、萬方數據庫、維普期刊資源整合平臺等中文數據庫和Web of Science、Springer Link、PubMed等外文數據庫,但是這些資源較為分散,載體形式各樣,沒有形成具有專業特點的特色館藏。
麻醉學專業是我校的優勢學科,在全國名列前茅。1986年我校創辦了中國第一個麻醉學本科專業,建成了國內同行中規模最大、實力最強的麻醉學國家重點實驗室,開創了具有中國特色的麻醉學創新人才教育體系,積累了大量的麻醉學教學實踐資源。現任麻醉學院院長曹君利教授是“長江學者”,我校的麻醉學教學團隊是“國家級優秀教學團隊”。
建立麻醉學特色數據庫,集中收集、加工,形成內容豐富的、高質量的特色化資源,為讀者提供一站式高質量的麻醉學信息資源服務,有利于提高我校的地區影響力。
2 我校自建麻醉學特色數據庫的流程
特色庫的建設流程包括平臺的搭建、數據源選取、信息采集與加工、信息發布與更新等環節。圖書館將與麻醉學相關的書籍、論文、專題講座、教學課件等各類資源進行數字化處理后,按照統一的標準和規則,結合麻醉學專業特點和用戶個性化需求,對各類信息資源進行有機整合,形成麻醉學特色數據庫[2]。我校之前的碩士論文庫和隨書光盤庫采用的是暢想之星公司的特色數據庫平臺。為了兼容我校之前的數字資源建設成果,麻醉學特色數據庫也采用此平臺進行建設。
我校的麻醉特色數據庫數據來源主要包括圖書館紙質資源、數字資源、麻醉學院資源和網絡資源。紙質資源的選取主要依據圖書館收藏的麻醉學相關方面的1 500多種圖書,100多種專業期刊,報紙;數字資源的選取按照麻醉學專業學科分類體系逐步進行篩選,根據其內容質量、參考價值和使用頻率等因素進行選取[3];麻醉學院資源的選取主要來自其廣泛收集的高質量的麻醉學教學課件、講座視頻和學生獲獎作品;網絡資源的選取主要是登陸“中華麻醉在線”、“圍術期患者之家”等國內外麻醉學權威網站和北大第一醫院吳新民教授、華西醫院劉進教授、協和醫院黃宇光教授等麻醉學權威人士的個人主頁、博客等,收集文章觀點、講座視頻和會議視頻等麻醉相關優質資源。
將符合條件的麻醉學相關圖書、報刊、論文、標準規范等各類紙質文檔數字化,按統一的標準生成PDF文檔[4],利用虛擬打印機將搜集到的各種電子文檔(WORD、PPT、 TXT等)按統一的標準轉換成PDF文檔,講座等視頻和音頻資源采用Format Factory等軟件按統一的標準轉換為基于Windows Media的流媒體文件[5]。同時,還對數字對象進行分類、標引,把各種類型的數字對象加工成可供瀏覽和檢索的數字資源。
對麻醉學特色數據庫錄入的數字資源由專人負責進行審核、校對,對不符合要求的數字資源給出意見并反饋到加工環節,審核通過的數字資源按照規定統一進行發布[6-14]。我們利用Coreseek 技術實現了麻醉學特色數據庫的全文檢索服務[15],針對本科生、研究生、教師、醫生等不同的用戶群提供全文檢索、分類導航、欄目導航等功能,方便用戶查找相關數字資源 。
3 自建麻醉學特色數據庫的關鍵技術
3.1 利用開源ETL工具——Kettle處理原圖書系統中的MARC數據
圖書館紙質資源數字化是一個浩大而繁瑣的工程。匯文系統中有麻醉學相關的紙質資源的MARC數據,圖書館紙質資源數字化、采集、加工的過程中要維護好相關著錄和標引信息。為了提高特色數據庫的建設效率,減少重復性操作,我館引入ETL工具,按照特色數據庫的相關數據標準進行MARC數據轉換,應用于新建的麻醉學特色數據庫中。
由于商業化的ETL工具(Informatica、Datastage等)費用昂貴,我們采用了ETL工具中的Kettle來處理MARC數據轉換。Kettle是一款開源免費的ETL工具,數據抽取高效穩定,完全能滿足我們建庫過程中轉換數據的技術要求。Kettle有transformation和job兩種腳本文件,transformation負責完成數據的提取與轉換,job負責完成整個處理流程的相關控制。
我們首先把篩選出的紙質資源的MARC數據導出到文本文件marc.txt,然后利用華云馬克數據轉換工具將MARC數據轉換為EXCEL文件marc.xls。轉換后的EXCEL格式的MARC數據主要包括書目名稱、作者、ISBN號、價格、出版地、出版社、出版時間、分類號、分類名、提要、頁數、附件等信息。將這些信息按照特色數據庫的數據標準智能導入麻醉學特色數據庫中,可以極大減少圖書館紙質資源數字化的工作量,加快建設進程。暢想之星特色數據庫的后臺表結構如下圖1所示。
最后利用Kettle建立transformation,將marc.xls的數據轉換為符合特色數據庫標準的數據,保存到特色數據庫中,以備在紙質資源加工時直接引用,減少重復操作,提高工作效率。由于麻醉學特色數據庫建設是一個長期的不斷完善的過程,所以我們對MARC數據的處理并不是一次簡單的數據轉化,而是建立一種機制,只需將要添加轉化的MARC數據放到指定位置的marc.xls中,系統自動完成相關的數據轉化處理。transformation的建立步驟如圖2所示。
第一,transformation中建立EXCEL輸入控件,提取指定位置的marc.xls里的MARC數據;第二,選取“插入/更新”控件將MARC數據按照特色數據庫的標準將數據更新到特色數據庫中時,需要設置好該控件的數據庫連接、目標模式和目標表等相關信息,然后以書名、作者、出版社、出版時間和ISBN號的組合條件為主鍵進行數據的添加或更新處理,將要處理的字段與麻醉特色數據庫的目標表的字段進行映射,建立對應關系。第三,匯文系統中MARC數據難免有數據不全或不符合標準的數據,需要給“插入/更新”控件建立錯誤處理,以確保數據處理過程中完成符合標準MARC數據的處理,輸出不符合標準的MARC數據的錯誤信息,以便查找和修正相關信息。
圖1 暢想之星特色數據庫后臺表結構
圖2 Kettle transformation建立設置
3.2 利用Coreseek + Python + Sql Server實現麻醉學特色數據庫的全文檢索服務
全文檢索有數據庫內置的全文檢索(Oracle,Mysql,SQL Server,等)和專業的開源全文檢索引擎(Sphinx,Lucene等)兩種模式。數據庫內置的全文檢索只需將需要全文檢索的相關字段建立全文索引,改變查詢條件即可實現全文檢索功能,但不支持中文分詞、智能關聯排序。Lucene是用Java語言開發的,性能相對較低,對硬件要求高,所以我們利用C++開發的高性能Sphinx全文檢索引擎進行開發,設計了麻醉學特色數據庫全文檢索系統,為用戶提供一站式智能檢索服務[16]。Coreseek全文檢索引擎是在Sphinx 基礎之上開發的,增強了中文分詞、中文編碼等中文支持,并根據中文的相關特點對搜索結果的排序進行了優化。Coreseek全文檢索引擎構成及功能見表1。

表1 Coreseek全文檢索引擎構成及功能
Sphinx主要支持MySQL 數據庫、PostgreSQL 數據庫。因為Python目前具備操作所有類型數據庫的能力,Coreseek為了擴展,增加了Python數據源功能[16]。
本數據庫利用Coreseek 全文檢索引擎和Python數據源程序接口,實現一個無限擴展Coreseek/Sphinx的數據獲取功能。以Sql Server數據庫為主,可兼容多種類型數據庫的分布式全文檢索引擎,向使用者提供更加快速、精確并具有良好數據兼容性的全文檢索服務,為以后整合管理自建數據庫和商業數據庫等相關數字資源鋪平了道路。系統架構見圖3。
由于麻醉學特色數據庫平臺是暢想之星,后臺為SQL SERVER數據庫,所以要安裝pymssql擴展包,然后利用Python的數據源功能操作SQL SERVER數據庫[6]。
麻醉學特色數據庫客戶端是采用PHP語言實現的,調用Sphinx API中的方法并構造SphinxClient對象實現全文檢索。守護進程searched負責接受查詢請求,對接收到的檢索內容利用LibMMSeg工具進行分詞,然后在服務器上的全文索引文件中進行檢索,并把檢索結果通過API返回給特色數據庫客戶端。
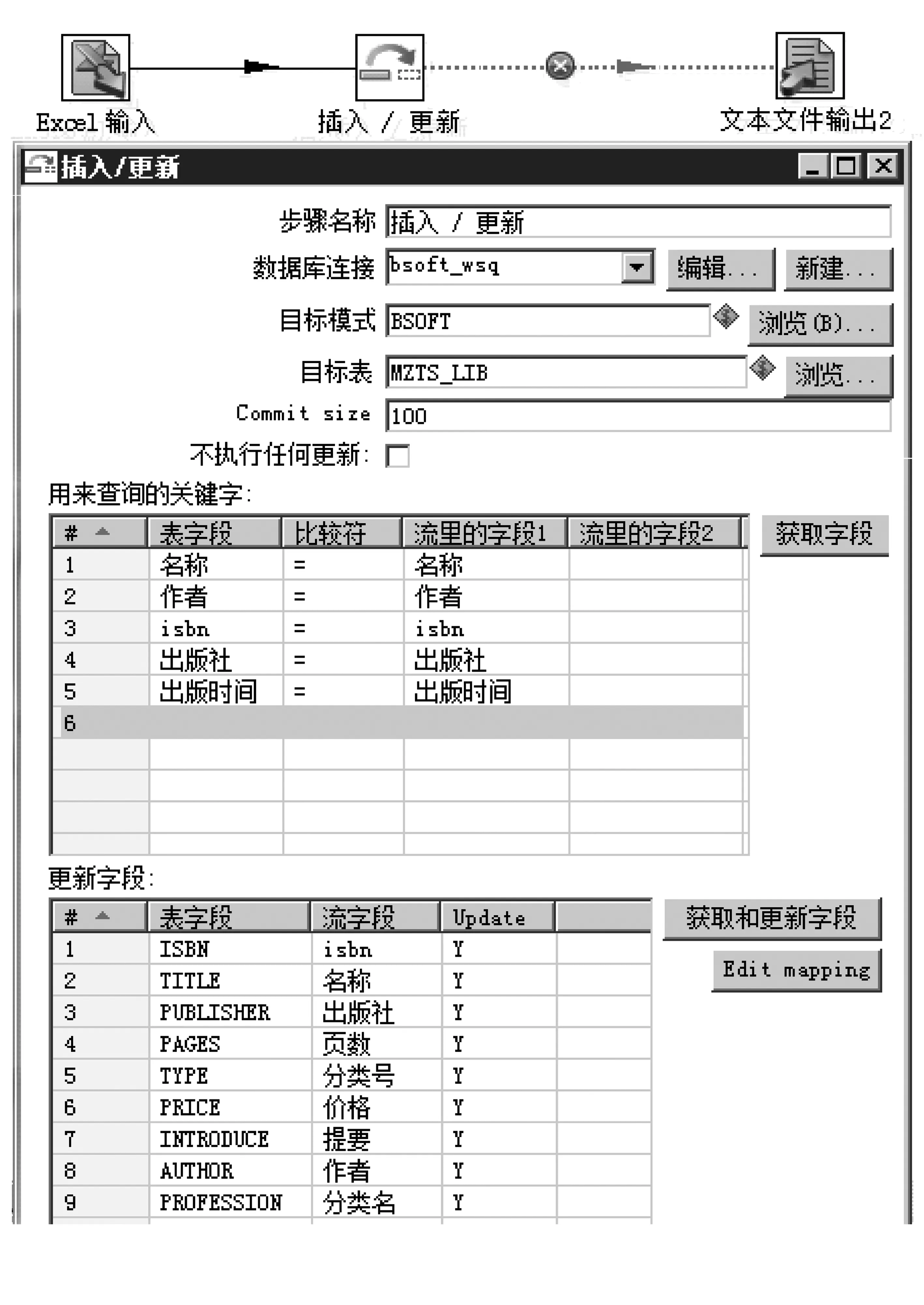
圖3 麻醉學特色數據庫全文索引系統模型

Sphinx api 函數說明SphinxClient為Sphinx提供了面向對象的接口SphinxClient::SetSerer指定所在服務器地址及端口號SphinxClient::SerMatchMode設置匹配模式SphinxClient::SetSortMode設置排序模式SphinxClient::SetWeights設置權重信息SphinxClient::Query進行全文檢
示例代碼如下:

4 總結與展望
本文論述了我校圖書館自建麻醉學特色數據庫的整體流程,并詳細分析了利用Kettle實現MARC數據共享,提高建庫效率和利用Coreseek等技術實現麻醉學特色數據庫的全文檢索,為讀者提供最佳的檢索服務。經過測試,本文建設的麻醉學特色數據庫全文檢索引擎在2GB-4GB 的文本建立的索引上搜索,平均0.1秒內獲得結果,相比Sql server自帶的全文檢索引擎,速度提升近10倍,檢索質量也明顯提高。其對Python 數據源的支持使我們的麻醉學特色數據庫可以兼容不同類型的異構數據庫,提高麻醉學特色數據庫的擴展性,有利于以后與碩博士論文庫、中國知網、萬方等數據庫進行資源整合,從而進一步促進我校麻醉學專業的建設與發展[17-20]。
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
今日農業(2021年17期)2021-11-26 23:38:44
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
英語學習(上半月)(2019年9期)2019-10-10 02:17:36
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
知識經濟·中國直銷(2017年10期)2017-11-07 02:39:51
資源再生(2017年3期)2017-06-01 12:20:59
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
