生物醫學文本挖掘研究熱點分析
2016-03-23 06:08:32,,
中華醫學圖書情報雜志 2016年2期
,,
隨著生物醫學科學的飛速發展,生物醫學領域的實驗數據和文獻數量急劇增加。常用的檢索方式通常會消耗大量時間,并且需要對檢索詞進行仔細篩選及恰當組合。文本挖掘是通過計算機發現以前未知的新信息,即在現有文獻資源中自動提取相關信息,并揭示另外隱含的意義[1]。利用文本挖掘能夠有效地從生物醫學數據庫中提取相關知識進行研究進而提出新的實驗假設,得到新的科學結論,因此文本挖掘在生物科學領域具有很大的應用價值。以檢索詞“text mining”在 PubMed檢索(2015年 6月 9日)相關文獻,結果顯示文獻累積數量隨著年代的分布呈現典型的指數分布,說明文本挖掘在生物醫學領域中正處在飛速發展中,是當前的研究熱點。
基于以上原因,我們運用共詞分析的方法,對 2000年1月至 2015年 3月MEDLINE數據庫收錄的有關文本挖掘在生物醫學領域應用的論文中的高頻主題詞進行了共現聚類分析,總結出當前國際上文本挖掘在生物醫學領域應用的研究熱點,并對其進行分析。
1 資料與方法
數據樣本為 MEDLINE數據庫收錄的生物醫學領域文本挖掘研究文獻。MEDLINE是國際上生物醫學領域的權威數據庫,迄今收錄文獻達2 400萬篇,通過該數據庫可以檢測到含有確切關鍵詞的文獻[2]。采用檢索策略為:“text mining”[tiab] AND ((“2000/01/01”[PDAT] :“2015/03/31”[PDAT]) AND medline[sb]),共得到 879篇相關文獻記錄。
以 xml格式將全部相關文獻記錄套錄下來,運用文獻計量學統計分析軟件BICOMB[3]抽取和統計以上文獻中的主要主題詞及副主題詞及每個詞在以上全部文獻中的出現頻次,按照它們的出現頻次由高到低進行排序,選取其中出現頻次高于13次的 40個主題詞/副主題詞作為高頻主題詞(表1)。

表1 PubMed中與文本挖掘有關的高頻主題詞/副主題詞(n=40,頻次≥13)
由于這些文獻的篇名或摘要中含有“文本挖掘”被檢出,且被收錄于 MEDLINE,其主要內容都與生物醫學文本挖掘有關,因此得到的主題詞和副主題詞可反映文本挖掘在生物醫學領域中的應用情況。
對所有高頻主題詞做進一步處理,統計每一個高頻詞在文獻中的出現情況,形成高頻詞-文獻矩陣,輸入到gCLUTO軟件,采用系統聚類法對所得相似矩陣進行聚類分析,聚類分析的結果可以反映出這些高頻詞之間的親疏關系,分析這些高頻主題詞能夠獲得生物醫學領域文本挖掘研究的熱點。聚類結果如圖1所示,其中橫軸代表 PubMed數據庫中文獻,縱軸代表進行聚類的主題詞/副主題詞。如果兩詞聚集到一起的距離短,說明它們的關系越密切[4]。
首先,根據每一類高頻主題詞的含義以及這些主題詞之間的語義關系,總結出每一類主題詞所代表的研究熱點,即當前醫學領域文本挖掘研究的熱點。例如,主題詞 Natural Language Processing(自然語言處理)和 Periodicals as Topic(期刊作為主題)距離較近,關系密切,首先聚成一類;Artificial Intelligence(人工智能)再與前面兩個詞合成一類,這一類再與 MEDLINE組成的一類再聚成一大類,以此類推。通過分析這些主題詞的語義關系就能得出它們所代表的類團含義標簽,綜合各個類別的類標簽可以得出當前醫學領域文本挖掘研究的熱點。其次,利用 gCLUTO軟件計算各類成員對聚類貢獻率的指標(描述度Descriptive和區分度 Descriminating),選取對每一類形成貢獻最大的來源文獻作為表示該類內容的類標簽文獻,通過文獻內容進一步闡釋該研究方向的具體內容。
2 結果與分析
通過對近2000-2015年 MEDLINE收錄的生物醫學領域文本挖掘研究文獻的高頻主題詞和副主題詞進行共現聚類分析(圖1),我們將該領域的研究熱點分為以下3大方面,14個主題。
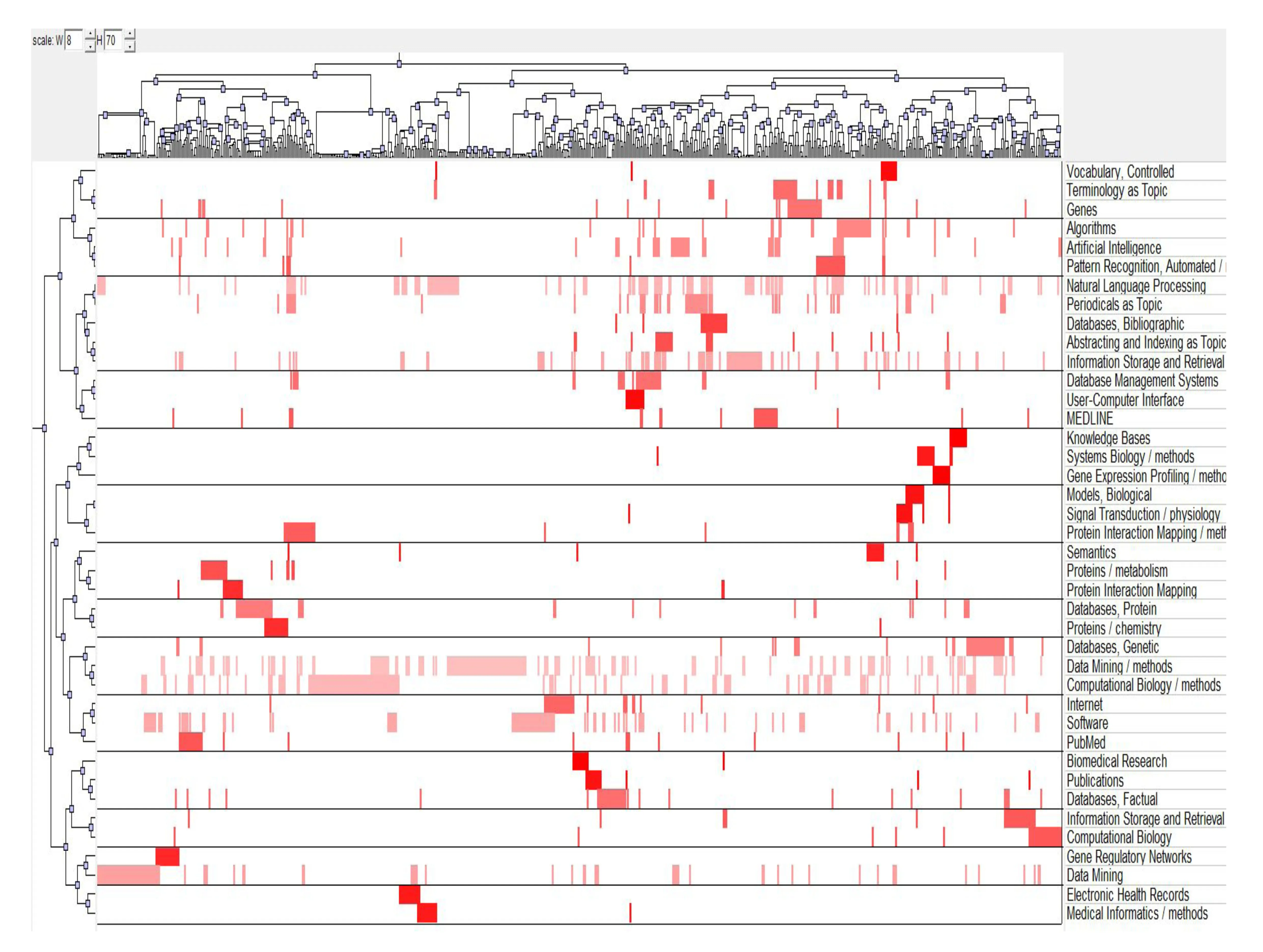
圖1 文本挖掘研究高頻主題詞的共現聚類圖
2.1 文本挖掘的基本技術
2.1.1 關于基因名稱識別的研究
該類所含的主題詞有 Genes;Terminology as Topics;Vocabulary, Controlled。研究內容如根據詞表對基因符號消歧,評價生物醫學命名體識別的各種標準[5-8],整合多種資源以規范基因名稱等 。
2.1.2 文本分類中高維特征的處理問題
該類包含Artificial Intelligence,Algorithms,Pattern Recognition,Automated/methods等主題詞。研究內容如利用Turku系統增強生物醫學事件抽取的新的特征選擇策略,Swanson的 ABC研究中定量計算 B詞的模型,如何把文本和手工構建通路聯系起來[9-12]。
2.1.3 文本挖掘中標引注釋問題
該類包括的主題詞有 Natural Language Processing;Information Storage and Retrieval/methods;Periodicals as Topic;Databases, Bibliographic;Abstracting and Indexing as Topic/methods。如用于生物文本挖掘語義注釋的語料庫GENIA,對文章中圖例進行標引和分類的系統,從全文中抽取生物學信息的工具。以上都涉及到文本挖掘語料的庫建設,需要事先注釋好的語料庫[13-16]。
2.1.4 文本挖掘初級階段的輔助工具
該類包括Database Management Systems,MEDLINE,User-Computer Interface等主題詞。研究內容如通過 Web服務進行文本處理的 Whatizit系統,對 MEDLINE/PubMed文獻記錄自動挖掘的輔助性工具 MedKit,文本中自動標記基因、蛋白質和其他實體名字的開源工具 ABNER,支持生物本體開發與分析的 API:ONTO-PERL。其中,基于 Web文本分析工具Whatizit是一種基于服務器的,用于分析文獻(如任何科學出版物或 MEDLINE摘要)中所含信息的模塊,它可以辨認術語并將其與生物醫學數據庫(如 UniProtKb/Swiss-Prot)中相應的條目和基因本體概念鏈接起來[17-19]。
2.2 文本挖掘在生物信息學研究中的應用
2.2.1 系統生物學的知識管理
涉及的主題詞有 Systems Biology/methods;Gene Expression Profiling/methods,Knowledge Bases。研究內容如以高通量 siRNA監測作為生物系統擾動和與復合物監測并存靶向通路的辨認的方法應用于轉化醫學的通用和可視化驅動的框架,藥物基因組學領域中的關系抽取,用于分析、整合和可視化人類轉錄組學[20-23]、蛋白質組學和代謝組學的 Web系統生物學工具。
2.2.2 生物學網絡:蛋白質相互作用網絡的構建和分析
涉及的主題詞有Protein Interaction Mapping/methods、Models,Biological和Signal Transduction/physiology。研究內容如利用文本挖掘的結果來構建PPI網絡,生物網絡推理和分析信息融合平臺 BioCAD;還有學者開發出基于網絡-上下文的文獻檢索系統(NcDocReSy)作為 Cytoscape的插件,可以通過間接相關的文獻幫助用戶手工構建網絡,該系統結合了用生物學網絡檢索文獻和根據網絡拓撲來排序檢索到的文獻[24-27]。
2.2.3 通過文本挖掘獲得蛋白質相互作用網絡圖,并對該圖中節點間的關系進行語義上的注釋
涉及Proteins/metabolism,Protein Interaction Mapping,Semantics等主題詞。研究內容如利用上下文模型和句子格式對基因提名加以規范并提取相互作用,把文獻挖掘和從各種來源的相互作用證據結合起來構建鼠蛋白相互作用網絡,語言特征在從 PubMed中抽取相互作用時的有用程度,以及從文獻中抽取人類蛋白質因果關系的挖掘工具 PPInter Finder[28-31]。
2.2.4 利用文本挖掘進行的蛋白質功能研究
涉及的主題詞有Databases, Protein;Proteins/chemistry。研究內容如基于Web的蛋白質序列功能注釋工具 ProFat,利用圖雙字相關自動抽取蛋白質點突變,PPI與文本挖掘集成用于蛋白質功能預測;用整合后的全局相關評分改善 PPI對排序[32-35]等。
2.2.5 文本挖掘方法在生物信息學中應用的概述
它涉及到 Data Mining /methods;Computational Biology /methods;Databases, Genetic等主題詞。文本挖掘是生物信息學的重要研究方法之一,有助于構建基因數據庫和知識庫。研究內容如從自文本中抽取事實的研究,文本挖掘是否能用成倍提高手工構建基因產品的效率。在 OMIM中檢索臨床綱要的 CSI-OMIM系統,利用 PharmGKB訓練文本挖掘方法以在藥物基因組研究中確認潛在基因靶標的研究[36-39]。
2.2.6 圍繞 PubMed的挖掘系統和工具
涉及到的主題詞有 Software,Internet,PubMed。本類所研究系統和工具與文獻挖掘的輔助工具相似,都是基于文獻數據庫開發的工具,但是輔助工具關注的是 MEDLINE數據庫,而本類則關注其網絡版,因此更具有網絡應用的性質。眾多工具不再是輔助性的文本處理工具,而是針對 PubMed的檢索和挖掘工具,尤其是基于 Web的 PubMed檢索工具,如GeneView,PPInterFinder等。與挖掘有關的工具則有書目分析工具,如Pipeline Pilot就是一種基于 Web的 PubMed書目分析工具等,可以進行交互式的文本挖掘[31,40-42]。
以上 6個主題也可以歸為一個大類,即在生物信息學研究中的應用,側重系統生物學的挖掘分析,即通過蛋白質相互作用網絡的分析來預測蛋白質的功能。這是文本挖掘當前在生物醫學應用的主流,也是文本挖掘在生物醫學應用中的重中之重。
2.3 文本挖掘在事實抽取中的應用
2.3.1 如何從文本中抽取事實(關系),即從文獻中發現醫學知識的方法學研究
涉及 Databases, Factual;Publications;Biomedical Research等主題詞。研究內容如利用文本挖掘給文獻打分和排序,以改善毒理基因組學比較數據庫中藥物-基因-疾病關系的建立;利用用戶定制的支持互操作格式的 Web服務來處理生物學文獻;無監督文本挖掘方法抽取生物醫學文獻中的關系等[43-46]。
2.3.2 利用文本挖掘幫助文獻檢索和整理,滿足用戶信息需求的研究
涉及主題詞有 Computational Biology,Information Storage and Retrieval。文本挖掘應用于生物信息學的信息檢索,如利用生物醫學本體改善生物醫學文獻聚類效果,利用計算機跟蹤知識與內容,利用文本挖掘開展人類重要疾病的整合基因組分析,藥物開發中的信息需求與文本挖掘的作用等[47-50]。
2.3.3 利用文本挖掘方法(尤其是文獻計量學方法)構建藥物-基因-疾病等調節網絡
該類主題詞有 Data Mining和Gene Regulatory Networks。研究內容如利用文本挖掘方法幫助構建 E.coli K-12菌株中 OxyR蛋白的調節作用和生長條件的數據庫,文獻計量學網絡重建應用程序和服務器 Biblio-MetReS,比較性毒理基因組學數[51-54]據庫中藥物-基因-疾病網絡的文本挖掘和手工構建等。
2.3.4 臨床記錄中各種信息(特別是時間信息)的抽取
涉及到Medical Informatics /methods,Electronic Health Records等主題詞。該研究內容如從臨床記錄中抽取時間關系而生成患者時間軸,結合使用規則和機器學習方法從患者出院小結中抽取時間關系的 TEMPTING系統,從臨床文本中自動抽取巴士指數的研究,對瑞士語臨床文本的線索斷言分類,為 pyConTextSwe系統開發詞匯表等[55-58]。
以上 4類的共同特征是偏重從文本中抽取事實,尤其是與藥物和毒理(藥物副作用)有關的事實抽取方法的研究,同時也涉及到基因等信息。
3 結論
通過對 14個主題的高頻主題詞進行梳理,可以看到文本挖掘在生物醫學領域應用主要在 3個方面。一是文本挖掘的基本技術研究。研究內容從語料庫建設中的標引注釋問題到文本分類中的特征提取,一直到這些技術在基因名稱的命名體識別中的應用,最后涉及到可以在命名體識別等基本技術上幫助文本挖掘的工具。文本挖掘基本技術研究未來的發展應更加注重采用規范化和標準化的工具。
二是文本挖掘在生物信息學領域里的應用。該研究方向側重于將挖掘方法應用到系統生物學分析中,如在轉化醫學、藥物基因組學、人類轉錄組學、蛋白質組學和代謝組學等領域中的應用,利用免費而權威的PubMed文獻數據庫開發挖掘系統和工具。其中通過蛋白質相互作用網絡分析來預測蛋白質的功能是當前文本挖掘在生物醫學領域應用中的重中之重。另外,對生物學網絡(尤其是蛋白質相互作用PPI網絡)的屬性分析已經成為一種新的生長點。其中通過對文本挖掘獲得文獻網絡,由此獲得蛋白質功能的信息,并將其與生物整合起來的研究也是值得注意的新動向。
三是文本挖掘在相關事實抽取中的應用。文本挖掘也常用于從文本中抽取事實,尤其是與藥物、毒理(藥物副作用)、疾病有關的事實抽取方法的研究,同時也涉及到基因信息研究。包括對從文獻中發現醫學知識的具體技術的探討,如構建各種生物醫學相關的數據庫和知識庫,Web服務器處理文獻;利用文本挖掘技術幫助用戶文獻檢索和整理文獻也是當前引起廣泛關注的服務。此外,在文本挖掘算法上比較突出的方向是利用文本挖掘方法以及文獻計量學方法構建藥物-基因-疾病等調節網絡,以及有關臨床記錄中各種信息(特別是時間信息)的抽取問題。
綜上所述,生物醫學文本挖掘研究熱點主要集中在文本挖掘基本方法和技術研究、生物信息學中的應用和在藥物相關研究中的應用,未來發展方向應當是以詞表標準、復雜網絡分析等方法為主。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
制造技術與機床(2019年10期)2019-10-26 02:48:08
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
電子制作(2018年18期)2018-11-14 01:48:06
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
