基于模糊C均值聚類的嵌入式數據庫并行推薦算法
2016-05-14 21:05:59林海霞
軟件導刊 2016年5期
關鍵詞:數據挖掘
林海霞
摘要:嵌入式網絡數據庫優化訪問的關鍵是對訪問目標數據的準確推薦和挖掘,以實現數據的準確檢索。提出一種基于模糊C均值聚類的嵌入式數據庫并行推薦算法,構建嵌入式數據的數據結構模型,進行數據信息流屬性集特征提取。采用模糊C均值聚類算法實現屬性分類,以此實現嵌入式數據的庫并行推薦和挖掘。仿真結果表明,采用該算法進行數據庫訪問,精度較高,執行時間較短,性能優越。
關鍵詞:模糊C均值聚類;嵌入式數據庫;數據挖掘
DOIDOI:10.11907/rjdk.161332
中圖分類號:TP312
文獻標識碼:A 文章編號:1672-7800(2016)005-0050-03
0 引言
在嵌入式網絡數據庫技術廣泛應用的今天,嵌入式網絡數據庫已經成為互聯網、局域網和大規模集成系統的重要數據存儲介質。嵌入式網絡數據庫通過分布式云計算和云存儲方法進行數據調度和管理,在嵌入式數據庫中,需要對網絡存儲介質中的數據進行有效地分類管理和信息獲取,并對獲取的信息進行有機分類和聚合,以實現對嵌入式數據庫的準確檢索和數據的并行挖掘。
傳統方法中,對嵌入式網絡數據庫中的待檢索數據挖掘模型主要采用如高階累積量特征提取方法、時頻分析與特征提取方法、小波分析方法、支持向量機分類挖掘算法等[1-3]。上述方法通過對嵌入式網絡數據庫中的數據進行相空間重構分析,在高維相空間中進行數據的特征分類和數據融合,以實現特定數據的典型性特征提取,達到數據匹配挖掘的目的,具有較好的應用性能。但是傳統方法具有計算開銷過大、抗干擾性不好等缺點,對此相關文獻進行了算法改進設計。其中,文獻[4]提出一種基于決策時分類搜索引擎構建的嵌入式網絡數據庫中的數據挖掘和文本檢索方法,建立了嵌入式網絡數據庫中的待推薦檢索數據的分布結構和數據信息流模型,對數據信息流進行抗干擾濾波處理,實現嵌入式網絡數據庫的數據訪問和挖掘。但上述方法在進行數據挖掘過程中,采用關聯特征提取方法進行數據庫特定數據推薦,在大規模數據分布和分布式云存儲數據的外界干擾下,數據挖掘的準確度不高。針對上述問題,本文提出一種基于模糊C均值聚類的嵌入式數據庫并行推薦算法,構建嵌入式數據的數據結構模型,進行數據信息流屬性集特征提取。采用模糊C均值聚類算法實現屬性分類,以此實現嵌入式數據的庫并行推薦和挖掘。仿真結果表明,采用該算法進行數據庫訪問,精度較高。
1 嵌入式網絡數據庫結構與數據信息流模型構建
1.1 嵌入式網絡數據庫結構分析
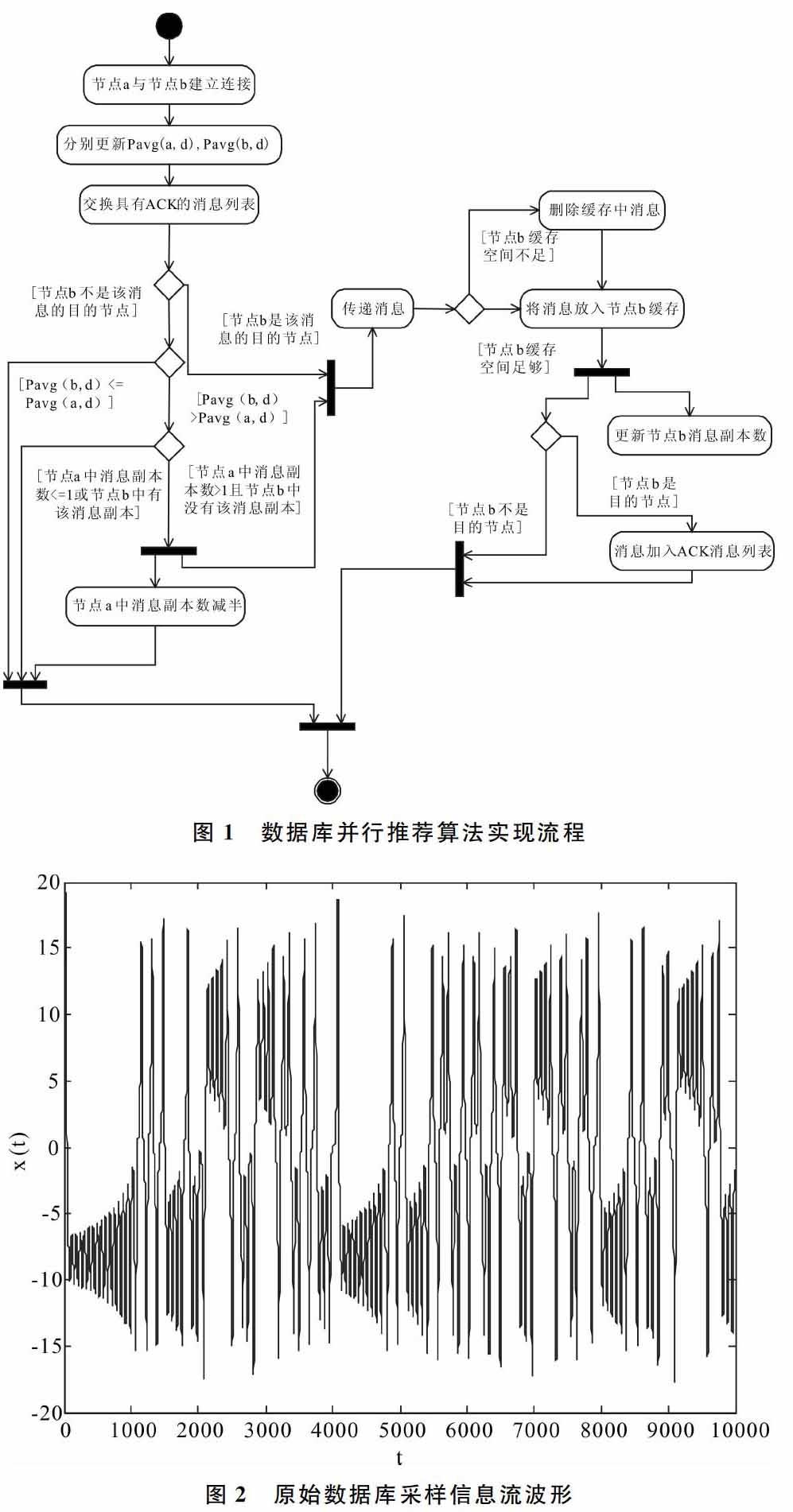
假設V=[v1,v2,….,vn]表示同階匹配的向量,即一個存儲調度方案。經過模糊C均值聚類結合Fourier變換,對嵌入式數據庫系統而言,vi代表第i個存儲狀態集合的資源節點,β為K-L特征壓縮系數。采用K-L變換進行特征壓縮,在數據庫存儲空間進行模糊C均值聚類屬性特征重組的基礎上,在幅值穩態下,使數據庫內部的狀態和行為控制能力可以自動運作,并用計算機相關語言進行控制管理。通過上述處理實現了對數據庫并行推薦算法的改進,改進算法實現流程如圖1所示。
3 仿真實驗與結果分析
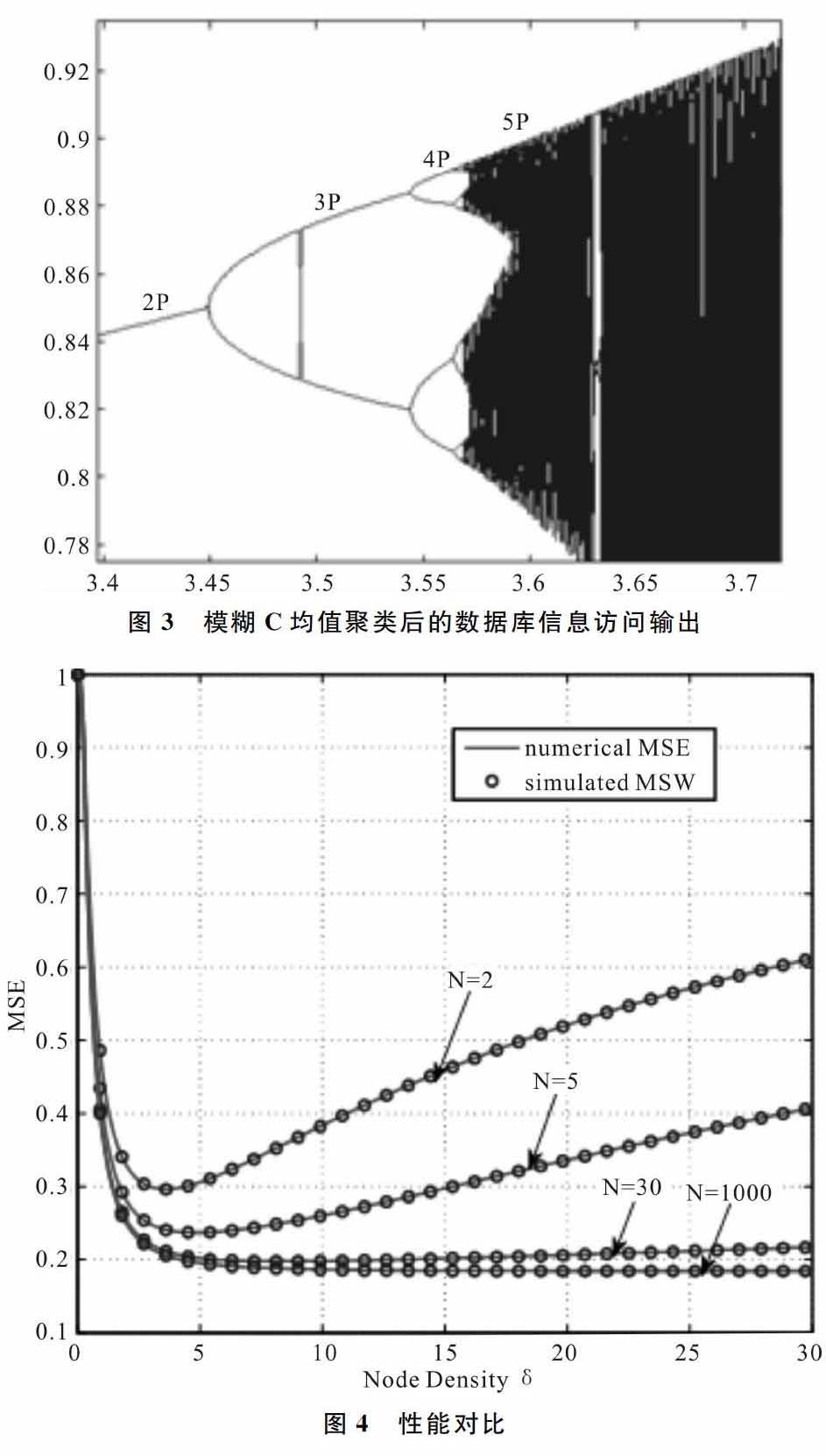
為了測試本文設計的算法在實現嵌入式網絡數據庫訪問和并行數據推薦中的性能,進行仿真實驗。實驗建立在Matlab仿真軟件程序基礎上,嵌入式數據庫的并行測試數據來自大型KDDP2015網絡數據庫,以8個通道數據為一個數據文件進行數據采樣。在數據采樣過程中,系統的CPU主頻較低,各個通道數據的排列格式采用均勻分布排列。假設數據采樣的時間間隔為1.2s,頻帶為3~15 KHz,通過上述實驗參數和環境描述,啟動VISA資源管理器進行數據加載,并進行仿真,得到原始數據庫采樣信息流波形如圖2所示。
由圖2可見,原始的嵌入式數據庫信息流受干擾較大, 難以實現準確訪問。采用模糊C均值聚類算法進行數據聚類處理,得到模糊C均值聚類后的數據輸入如圖3所示。
由圖3可見,采用本文方法進行數據庫的信息流聚類處理,有效提高了待檢索數據的推薦能力,提高了數據庫訪問精度。為了對比算法性能,采用本文算法和傳統算法,以數據庫并行推薦訪問的收斂度為測試指標,得到性能對比結構如圖4所示。由圖可見,采用本文算法,收斂性較好,執行時間較短,數據庫訪問和檢索數據推薦的準確度較高。
參考文獻:
[1]王曉初,王士同,包芳,等.最小化類內距離和分類算法[J].電子與信息學報,2016,38(3):532-540.
[2]WU X,ZHU X,WU G,et al.Data mining with big data[J]. IEEE Transactions on Knowledge and Data Engineering,2014,26(1):97-107.
[3]王永貴,李鴻緒,宋曉.MapReduce模型下的模糊C均值算法研究[J].計算機工程,2014,40(10):47-51.
[4]GU R,YANG X,YAN J,et al.SHadoop:improving MapReduce performance by optimizing job execution mechanism in Hadoop clusters[J].Journal of Parallel and Distributed Computing,2014,74(3):2166-2179.
[5]GU R,HU W,HUANG Y H.Rainbow:a distributed and hierarchical RDF triple store with dynamic scalability[C].Proceedings of the 2014 IEEE International Conference on Big Data. Washington,DC:IEEE Computer Society,2014:561-566.
(責任編輯:黃 健)
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
