圖書自動分類技術研究與實現
2016-05-14 22:04:23劉高軍陳東河
軟件導刊 2016年5期
劉高軍 陳東河
摘要:提出使用TF-IDF算法與樸素貝葉斯算法相結合,實現圖書的自動分類。首先需從互聯網中爬取圖書信息,主要包括圖書基本信息、圖書簡介、圖書目錄等;其次,需要對爬取到的圖書信息進行預處理,將同類圖書的基本信息聚在一起,并進行分詞去噪;然后使用TF-IDF算法對每一類圖書進行特征提取,獲得每一類圖書的特征;最后使用樸素貝葉斯算法,并利用訓練好的分類特征,計算某本新書的具體分類。實驗結果表明,該方法可以簡化復雜的圖書自動分類過程,提高分類效率,也能保證圖書分類的準確性。
關鍵詞:圖書分類;TF-IDF;樸素貝葉斯
DOIDOI:10.11907/rjdk.161108
中圖分類號:TP319
文獻標識碼:A 文章編號:1672-7800(2016)005-0150-03
0 引言
在圖書館工作中,最復雜、重要且耗時最長的工作就是圖書分類工作。圖書分類工作通常是由人手工進行,但是由于圖書分類的復雜性、多樣性、模糊性等因素,使圖書分類工作更加困難,準確性也不能夠得到絕對保證,僅僅提高工作人員的素質是根本不夠的。隨著科技的迅速發展,使用新的計算機技術來解決圖書分類問題是十分必要的,其中一種比較有效的方法是采用專家系統技術對圖書進行自動分類[1]。但是專家系統需要一個覆蓋面廣、內容充足的知識庫,以及擁有強大推理能力的系統支撐,還需要邏輯嚴謹、類別清晰的規則庫才能保證系統的正常運行。因此,構建專家系統是十分困難的,建立知識庫與規則庫也需要耗費大量的人力、物力。
1 圖書分類算法介紹
1.1 TF-IDF算法
TF-IDF是一種用于資訊檢索與資訊探勘的常用加權技術。TF-IDF是一種統計方法,用于評估字詞對于一個文件集或一個語料庫中一份文件的重要程度。
在一份給定的文件里,詞頻指某個給定的詞語在該文件中出現的頻率。該數字是對詞數的歸一化,以防止其偏向長的文件。逆向文件頻率是一個詞語普遍重要性的度量。某一特定詞語的IDF,可以由總文件數目除以包含該詞語文件的數目,再將得到的商取對數得到。
某一特定文件內的高詞語頻率,以及該詞語在整個文件集合中的低文件頻率,可以產生出高權重的TF-IDF。因此,TF-IDF傾向于過濾掉常見詞語,保留重要詞語。
1.2 樸素貝葉斯算法
樸素貝葉斯法是基于貝葉斯定理與特征條件獨立假設的分類方法。樸素貝葉斯分類是一種十分簡單的分類算法,被稱為樸素貝葉斯分類是因為該方法的思想非常樸素。其思想基礎如下:對于給出的待分類項,求解在此項出現的條件下各個類別出現的概率,哪個最大則認為此待分類項屬于哪個類別。
樸素貝葉斯分類的正式定義如下:①設{a1,a2,…,am}為m個待分類項,而每個a為x的一個特征屬性;②有n個類別的集合{y1,y2,…,yn};③計算當x出現時屬于y1的概率,x出現時屬于y2的概率,…,直到x出現時屬于yn的概率;④如果當x出現時屬于yk的概率最大,則x屬于yk。
2 圖書分類設計與實現
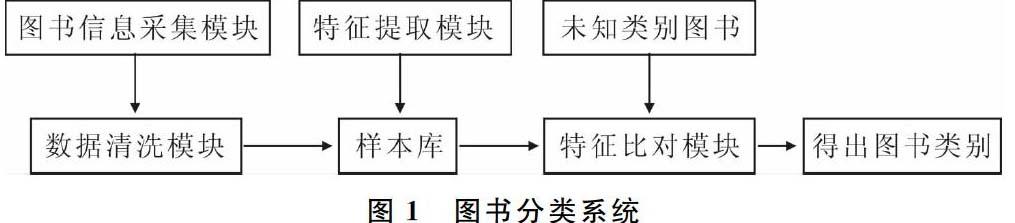
圖書分類系統主要分為4大模塊,如圖1所示。
(1) 圖書信息采集模塊。圖書信息采集模塊主要用于圖書信息的收集工作。主要功能是從圖書電商網站中將圖書信息相關頁面內容采集到本地,并按照圖書電商提供的圖書類別將采集到的圖書信息聚類在一起。
(2) 圖書數據清洗模塊。圖書數據清洗模塊主要功能是將圖書信息采集模塊收集到的圖書網頁信息進行分析,去除與圖書信息無關的內容,抽取出系統需要的圖書信息,并將其存入到樣本庫中。
(3) 特征提取模塊。圖書數據清洗模塊僅僅是將收集到的圖書頁面信息中與圖書相關的信息抽取出來,而特征提取模塊主要功能是從入庫后的圖書信息中提取出每一類圖書的特征,并將相關特征存入數據庫。
(4) 特征比對模塊。特征比對模塊的主要功能是根據樣本庫中的所有圖書類別特征將未知類別的圖書進行分類定位,得到該書的類別。
2.1 圖書信息采集模塊
圖書信息采集模塊主要是從圖書電商中采集圖書的基本信息,包括圖書名稱、作者、出版社、ISBN號、商品編碼、出版時間、內容簡介、編輯推薦、經典書評、書摘、前言等信息。
圖書信息采集模塊主要分為4個部分:①選擇一個圖書網站作為數據源;②將此圖書網站中的圖書分類采集到本地;③根據采集到的圖書分類地址,獲取到此類圖書的列表,再將圖書列表采集到本地;④將每一個圖書分類中的圖書信息采集到本地。圖書信息采集工作不是一次性將一個網站內的圖書全部采集完,而是分階段采集數據,采用這種模式的原因如下:①由于現在各個公司都開始對數據進行保護,很多大型網站都做了防爬取工作,當進行長時間、高頻率訪問時,將獲取不到數據,甚至會封IP,從而達不到數據采集的目的;②由于圖書信息采集的數據源多,采集流程較長,各個流程雖有一定聯系,但又相對獨立,所以采用數據分步落地的方式可以使工作更加安全、有效。
2.2 圖書數據清洗模塊
圖書信息清洗模塊主要是將采集到的圖書網頁信息進行數據清洗,抽取出有意義的圖書信息,主要包括圖書名稱、內容簡介、編輯推薦、文摘等。
在圖書信息采集模塊中,已將圖書所在頁面采集到本地,并且將同一類圖書的頁面信息存在同一文件夾下,所以在做數據清洗時,提取結構化信息則變得相對方便。
圖書信息清洗模塊主要分為3個步驟:①掃描本地圖書文件,即掃描爬取到本地的圖書網頁信息;②分析爬取的圖書網頁信息,清洗掉與圖書無關的信息,將每一本圖書的基本信息提取出來;③將抽取出的圖書信息存入數據庫,作為下一步研究的基本數據。
2.3 特征提取模塊
圖書結構化信息入庫后,需要將每一類的圖書特征抽取出來,并且將提取出的特征存入數據庫中。
(1) 提取同類圖書信息。提取同類圖書信息是指將同一類圖書的圖書名稱、內容簡介、編輯推薦、文摘信息提取到一個文件中。
(2) 分詞、清洗。分詞、清洗由兩部分組成,即信息分詞部分與通用詞、停用詞清洗部分。其中分詞部分是使用NLPIR漢語分詞系統進行分詞處理,通用詞、停用詞清洗部分是在分詞過程中一并處理的。預先準備通用詞和停用詞詞庫,在分詞過程中去除出現在通用詞和停用詞詞庫中的信息,最終得到確切的圖書描述詞匯。
(3) TF-IDF算法提取特征。當分詞、清洗環節結束時,每一個分類中每一本書的描述信息都已經過處理,得到了更加精煉的描述關鍵詞,再根據每一本圖書的關鍵詞,計算出在本類別中出現次數最多,但在其它類別中出現次數最少的詞,即可作為本類圖書的特征詞。其中,由于不同類別包含的圖書數量不一致,并不是某一關鍵詞出現在其它類別就不能當作本類圖書的關鍵詞,還需要看在本類別中出現的頻率是否較高。如在本類圖書中與其它圖書類別中出現頻率都較高,此種情況可視為此關鍵詞既屬于本類圖書,也可能屬于其它類別圖書。
2.4 特征比對模塊
在特征抽取模塊中,已經將每一類圖書的特征提取出來,并存入數據庫中。在特征比對模塊中,需要將某本未知分類的圖書進行定位,確認其分類,并將此本圖書的關鍵詞加入分類特征中。
(1)獲取待分類圖書信息。待分類圖書信息主要包括圖書名稱、圖書作者、圖書簡介等,其中圖書名稱和圖書簡介信息屬于關鍵信息,圖書作者信息屬于輔助信息。圖書作者信息的主要功能是可以根據作者查詢出其在哪些圖書類別中發行過哪些圖書,從而首先試圖在其擅長領域中定位新書,減少處理次數。
(2)待分類圖書關鍵詞提取。待分類圖書信息是未經處理的原始信息,要通過樸素貝葉斯算法進行圖書定位,必須先將圖書簡介信息進行分詞與去噪處理。其中分詞部分使用NLPIR漢語分詞系統進行處理,去噪部分指去除通用詞和停用詞。由于圖書簡介信息內容并不是很豐富,所以在關鍵詞提取階段應該盡量保留信息,以獲得更多圖書描述信息。
(3)樸素貝葉斯算法確定分類。根據對樸素貝葉斯算法的介紹,可以知道樸素貝葉斯算法是計算當每一個關鍵詞出現,確認是某一個分類的概率值,然后將每一個關鍵詞在某一個分類中出現的概率值相乘,找出乘積最大的分類,即可以確定此書屬于該分類。由于待分類的圖書信息有限,而某一個分類的特征詞又有很多,再將所求得的概率值相乘,最終會是一個極小的數字,并且當特征詞數量在一定的數量級時得到的結果將為0,所以在計算過程中,將每一個關鍵詞出現時確定是某個分類的概率值放大同等倍數,并不會影響計算結果的準確性。
3 實驗結果與分析
3.1 實驗數據及結果
本文選取從京東商城上爬取的180萬本圖書信息作為測試樣本。根據對樣本集的測試,得出每一類圖書的特征詞抽取個數范圍對圖書分類的效率和正確性影響最大,具體分析如下:
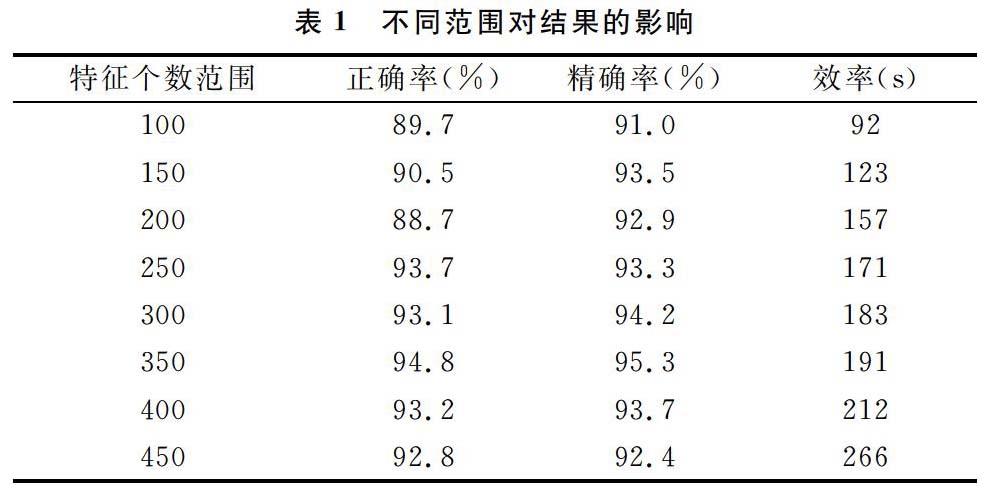
(1) 特征詞抽取個數范圍對數據結果的影響。在對圖書樣本集進行訓練的過程中,發現在提取不同個數的特征詞時,將對最終圖書定位產生影響,顯示出不同的效率值與準確率。經過不斷調整,最終得到了比較理想的效率值和準確率值。圖書樣本集在選取不同的特征詞抽取個數范圍時對效率值和準確值的影響如表1所示。
從表1中可以得出,訓練數據集中特征詞抽取個數對整體結果影響較大。從表中的結果數據不難看出,當特征詞抽取個數不夠時,雖然效率較高,但是正確性和精確性不高;然而當特征詞抽取個數過多時,關鍵詞過多,反而也會使正確性和精確性下降。
(2) 最優值分析。如何確定最優值,是在相同樣本訓練集情況下、提取特征詞個數不同時,產生不同的正確率和精確率以及效率值,再從這些值中選取出正確率、精確率及效率值表現相對較好的結果。
由表1可以判斷,當特征詞抽取個數為250~400時,正確率、精確率及效率值都相對較好。尤其是當特征詞抽取個數為350時,正確率、精確率最高,而效率值波動并不是很大。所以認為當樣本信息足夠多、數量足夠大時,選取350個特征詞進行特征比對能得出較為理想的結果。
3.2 實驗概述及結果分析
本次實驗的目的是希望通過特征提取及特征比對的方法來確定某本未知分類的圖書分類。由上述圖書分類系統整體結構設計可以看出,實驗主要分為3大部分:①圖書信息爬取及結構化信息提取;②使用TD-IDF算法提取每一類圖書的特征詞;③使用樸素貝葉斯算法定位未知圖書的分類。由實驗結果可知,當特征詞抽取個數較多或較少時都會影響最終結果的正確性和精確性。經過反復試驗,最終確定出一個較為合理的區間,在該區間中能夠得到一個較為準確的結果。
4 結語
在圖書館工作中,圖書分類工作十分復雜且耗時,為了解決圖書分類問題,已有很多學者開始從事圖書自動分類研究工作,并取得了一定成果。本文在這些已有技術的基礎上提出了基于TF-IDF及樸素貝葉斯算法來解決圖書分類問題。
本文采用互聯網圖書信息及圖書分類作為訓練樣本進行實驗,在圖書信息采集過程中遇到了網站防護及數據延遲加載等問題;在數據清洗過程中,分詞工具的選擇、通用詞及停用詞詞庫的構建都十分重要,如果分詞工具選擇與詞庫構建不合理,對最終結果正確性的影響將很大;在特征提取階段,最關鍵的問題是關鍵詞統計,以及此關鍵詞在其它文檔中出現的頻率。由于圖書種類較多,抽取出的圖書關鍵詞也很多,并且未采用分布式系統處理數據,所以在計算和統計時花費了很長時間。在整個系統設計中,特征比對之前的工作都是在做數據集的訓練工作。特征比對使用之前訓練好的數據來最終確定一本書的分類。由于使用樸素貝葉斯算法進行文本分類處理,并且圖書分類較多,每一個分類中的特征關鍵詞也較多,所以最終得到的概率乘積會非常小。當圖書分類的特征關鍵詞達到一定數量時,最終得到的結果值會被認為是零,影響結果判斷,所以在特征提取時,特征詞數量是決定結果正確與否的關鍵因素。在本文中,經過反復實驗,最終得到一個區間,當特征詞數量在該區間內時,最終得到相對準確的結果。
綜上所述,本文研究針對圖書館情報學圖書分類問題,雖然在圖書自動分類領域已有一些較為成熟的研究成果,但是本文從另外一種角度,嘗試使用不同的技術來分析研究該問題,并且取得了一定成果,對圖書館情報學研究有一定的參考借鑒意義。
參考文獻:
[1]張惠.圖書自動分類專家系統的研究[J].佛山科學技術學院學報:自然科學版,2001,19(2):37-40.
[2]李靜梅,孫麗華,張巧榮,等. 一種文本處理中的樸素貝葉斯分類器[J].哈爾濱工程大學學報,2003,24(1):71-74.
[3]涂茵.圖書分類中常見問題探討[J].河南圖書館學刊,2015(6):62-64.
[4]張笑.圖書分類中的問題及對策[J].卷宗,2015(3):21-21.
[5]程克非,張聰.基于特征加權的樸素貝葉斯分類器[J].計算機仿真,2006, 23(10):92-94.
[6]張紅蕊,張永,于靜雯.云計算環境下基于樸素貝葉斯的數據分類[J].計算機應用與軟件,2015(3):27-30.
[7]于秀麗,王陽,齊幸輝.基于樸素貝葉斯的垂直搜索引擎分類器設計[J].無線電工程,2015(11):13-16.
[8]羅欣,夏德麟, 晏蒲柳.基于詞頻差異的特征選取及改進的TF-IDF公式[J]. 計算機應用,2005,25(9):2031-2033.
[9]韓敏,唐常杰,段磊,等.基于TF-IDF相似度的標簽聚類方法[J].計算機科學與探索,2010(3):240-246.
[10]WU H C, LUK R W P, WONG K F,et al.Interpreting TF-IDF term weights as making relevance decisions[J].Acm Transactions on Information Systems, 2008,26(3):55-59.
(責任編輯:黃 健)
