一種多機器人的任務分配和自動協商的方法
2016-05-16 10:58:18皮玉珍苑全德舒英利
長春工程學院學報(自然科學版) 2016年1期
皮玉珍,苑全德,舒英利
(1.長春工程學院; 2.吉林省配電設備自動化產業公共技術研發中心,長春 130012)
?
一種多機器人的任務分配和自動協商的方法
皮玉珍1,2,苑全德1,2,舒英利1
(1.長春工程學院; 2.吉林省配電設備自動化產業公共技術研發中心,長春 130012)
摘要:提出了一種多機器人的任務分配和自動協商的方法。在進行任務分配時充分考慮機器人的真正性能;構建自動協商的模型時,改進最小二乘法支持向量回歸算法(LSSVR),用于估計對手的談判效用,并采用魯棒控制器的輸出反饋變量來限制優化實用性能指標,然后提出協商和再分配的協議來提高實時性和任務分配效率。最后,通過仿真實驗來驗證次方法的有效性。
關鍵詞:多機器人;任務分配;協商
在多機器人技術中,任務分配和協商一直是研究的關鍵問題之一。其研究主要集中在任務分配的方法、資源能力的推理、自主合作、系統通信流量、學習和雙向多問題協商等方面。例如,在參考文獻[1]中劉淑華等提出的任務分配方法是基于群體智能的采用分層架構的帶有寬松和緊密耦合任務的大規模多機器人系統;在參考文獻[2]中提出分布式同質的多機器人系統,以實現以負載平衡為目的的任務分配方案;在參考文獻[3]中Elango開發了一個仿真模型包括任務優先級和機器人的利用率,把它做為一個平衡的多機器人任務分配問題的優先級;在參考文獻[4]中Jouandeau提出一個以貿易為基礎的多機器人任務分配方法,這個方法模擬了買家和賣家通過使用一種機械的主動競價方式完成動態的任務分配,等等。
本文提出的任務分配和協商方法,考慮機器人的實際能力和性能。并改進了競爭性投標效用函數,實現了快速學習。
1機器人的能力和任務分配的原則
1.1機器人能力的描述
在多機器人中,設R={R1…,Ri,…Rm},每一個機器人與其他機器人之間可以是同型的或是非異構的,但是至少保證Ri={PR,SR,BR},其中,PR是機器人的位置和方向,SR是傳感器的類型,BR是處理任務的能力。
BR=g(bi,τi) 是Ri里bi的實際能力,與能力狀態τi有關,0≤τi≤1。
映射perfi∨timei∨bandwidthi∨poweri→τi的意思是τi受性能、執行時間、帶寬、電源等的影響。Ri完成任務的能力t用式(1)表示:
j(τi,bi,t)=τiω(bi)-u(t)
(1)
式中:ω(bi)是消耗能力;u(t)是完成時的成本t。
ComCost∨ResCost∨RisCost∨ChaCost→ω(t) 表示ω(t)受很多因素的影響,ComCost是通信成本,ResCost是資源成本,RisCost是執行任務風險成本t,ChaCost是機會成本,j(τi,bi,t)被用來判斷t是否已經完成。如果j(τi,bi,t)≥0說明Ri能夠完成t,否則不能完成。
1.2任務分配的原則
在理想的狀態下,τi=1,遍歷n任務。對于任務tj,如果(ω(b1)+…+ω(bm))/m-u(tj)≥0,說明tj通過單個機器人能夠完成,所以tj被看是一個單一的任務。如果(ω(b1)+…+ω(bm))/m-u(tj)≤0,說明tj通過很多機器人能被完成,tj被視為一個團隊任務。因此進行單一任務設IT={it1,…,itx,…itu},團隊任務設CT={ct1,…cty,…ctv},同時?(itx∧cty)=φ。

參考文獻在[5]中祖麗楠等設計用競爭性競標效用函數去實現機器人的任務分配,但是這個方法沒有考慮當機器人加入到實際的合作時機器人實際性能的變化和對機器人的能力補償。在此我們根據以上的分析對這種方法做了進一步的改進。
(2)式中:p(bil,itxi)是初始化Ril到處理itxi階段的成本,它隨著距離和時間的增加而增加;α和β是映射比例系數;Δb(τil)是對Ril的性能補償;τ是補償等級,τ∈R+。ρxi且隨著p(bil,itxi)和ω(bil)的減少而增加,表明選取Ril有適合的性能去處理itxi的原理。
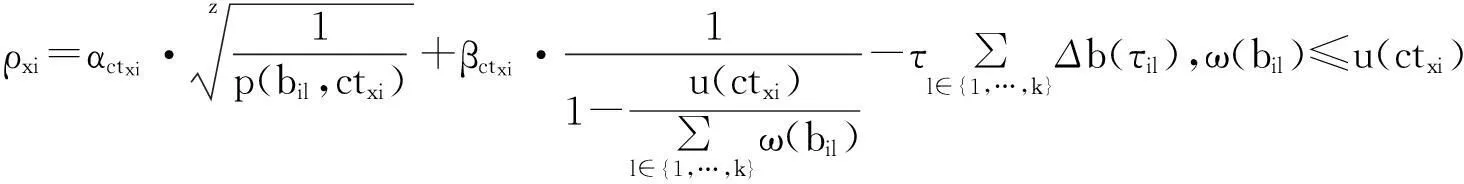
(3)
2自主協商
2.1協商模型
單一的機器人被指派去完成itxi可以實現單一任務的指派分配,在這里我們考慮多機器人的協商情況。下面將分析機器人在處理ct時如何建立它們之間的協商關系。基本步驟如下:
從自由機器人{R1,…,Rz}中選擇有最小ω(bp)的機器人Rp(1≤p≤z)作為申請人;
Rp輪流選擇自由機器人依據機器人的能力進行降序排列和向他們發送協商方案,在tKk和Rq協商成功后做出處理Ck,1≤q≤z,q≠p;
Rp選擇tKk+1,重復步驟2直到全部任務都被分配了。
在多機器人上定義協商模型NMM={R,CT,E},其中R={R1,…,RP,…,RZ}是被許可加入協商的機器人。CT是合作任務,E是合作效用評估。
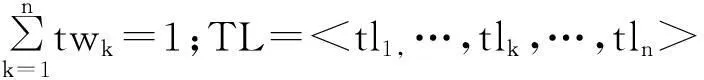
2.2協商效用的估計
盡管最小二乘法向量回歸幫助解決了在理想狀態下小樣本的快速學習問題,但是當用在實際的協商狀態下卻變得不穩定,多機器人帶有很多不確定的干擾信息會引起無休止的學習。為了維持最小二乘法向量回歸的穩定性,在此我們選擇徑向基函數核函數,采用魯棒反饋控制器抑制不確定的干擾信息以保持系統的穩定性。
vi(t+1)=fvi(t)+c1r1(Pi-xi(t))+c2r2(Pg-xi(t))
xi(t+1)=xi(t)+vi(t+1)
(5)
式中:vi(t+1)、vi(t)分別是在t+1和t時刻第i個粒子的速度;f是慣性權重;c1、c2是兩個常數,r1、r2是在[0,1]之間的隨機數;Pi、Pg分別是第i個粒子和全部粒子的最佳位置;xi(t+1)、xi(t)分別是第i個粒子在t+1和t時刻的位置。
為了優化在多機器人協商系統實際的性能指標,LMI被用來設計魯棒控制器的H輸出反饋。當LSSVMI有誤差或者學習過程不完全收斂,魯棒控制器輸出錯誤路徑,產生反饋信號確保協商過程的連續性和閉環系統的穩定性。
權重理解之后,對手的效用估計
EUp→q(·)=κfr+(1-κ)gr
(6)
式中:fr是LSSVMC的輸出;gr是魯棒控制器的輸出,κ是魯棒因素值。
κ=e-φEm,
(7)
式中:φ是魯棒系數,φ∈(0,1)。
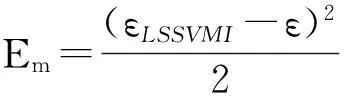
(8)
2.3協商協議和再分配
由于高實時性的要求,在協商中機器人數量的控制和協商回合應該被升級,避免在頻繁的協商時通信帶寬的擁擠和信號延遲。設Rp到提議通過局部廣播只在relative net內和僅僅那些屬于這個區域的空閑機器人可以加入到這個協商中。L(Rq)∈NRp(rp)是指Rq屬于Rp的relative net ,L(Rq)是Rq的當前位置,NRp(rp)是在半徑rp到Rprelative net 覆蓋的區域。0≤p,q≤z′≤z,q≠p,z′是在relative net 中包括Rp的機器人數量。Rp通過局部廣播網在tkk上提出協商協議。如果L(Rq)∈NRp(rp),Rq返回響應d(Rq),

(9)
在協商過程中,當ξmin≤EU(·)≤ξmax連續拒絕或停止協商。協商申請人升級協商廣播網區域以尋求更多的候選人,其中ξmin和ξmax是最小效用和最大效用。協商的步驟如下:
準備階段i=1 表示開始第一回合協商。
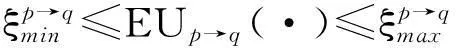
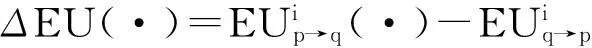
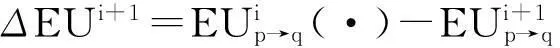
步驟4?d(Rq)=拒絕,轉到步驟1。
步驟5?d(Rq)=等待∧?d(Rq)≠同意。Rp在特定的等待時間δ階段接受提議響應,且?d(Rq)=同意,轉到步驟2。如果?d(Rq)≠同意在δ時間段轉到步驟6。
步驟6如果rp>rmax,協商失敗,或者Rp擴大半徑到rp=rp+βΔr,β是放大比例系數,Δr是半徑增加量。Rp通過局部廣播在次發送廣播。轉到步驟1。
步驟7 在tkk上Rp同Rq建立任務分配關系Ck(tkk,Rp,Rq)。協商成功結束。
3多機器人追逐仿真實驗
實驗在矩形方格區域進行,在矩形方格區域內隨機創建不同形狀的障礙物。多機器人協商去追逐目標機器人(獵物)。如圖1所示,是追逐初始化階段圖。目標機器人通過智能策略逃跑。在追逐者和獵物間的視野半徑比例為1∶1。聲波定位儀的范圍比例為1∶2。當協商時廣播是唯一的通信方式,LSSVR常常被用來評估對手的談判效用。
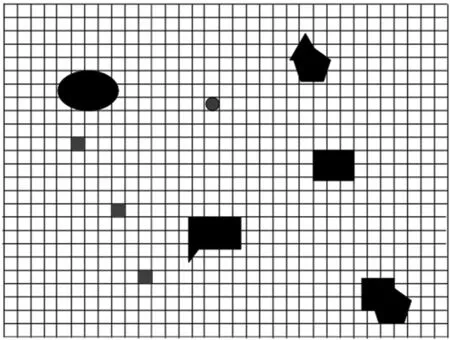
圖1 追逐初始化階段
追逐過程中,算法中分別設計了沒有協商的追逐和有協商的追逐兩種。在沒有協商的追逐過程中,追逐者追逐獵物是依靠局部的優化算法。而有協商的追逐過程,機器人之間互相協商去包圍獵物。協商的條目有向前移動的距離d,向后移動的距離d,向左轉的角度θ,向右轉過的角度θ。他們的權重因子是(0.25,0.25,0.25,0.25)。機器人預測獵物的移動方向,提供計數提議。協商的記錄儲存在協商歷史數據庫里作為協商雙方效用評估樣本。
表1表示的是60個沒有協商的追逐過程的時間數據。表2表示的是60個有協商的追逐過程時間數據。其中,vp和ve分別是追逐者和獵物的速度,它明顯地表明有協商的追逐過程的成功率要高于沒協商的追逐過程。表中,SR是成功比率,F表示失敗。

表1 沒有協商的追逐過程的時間數據
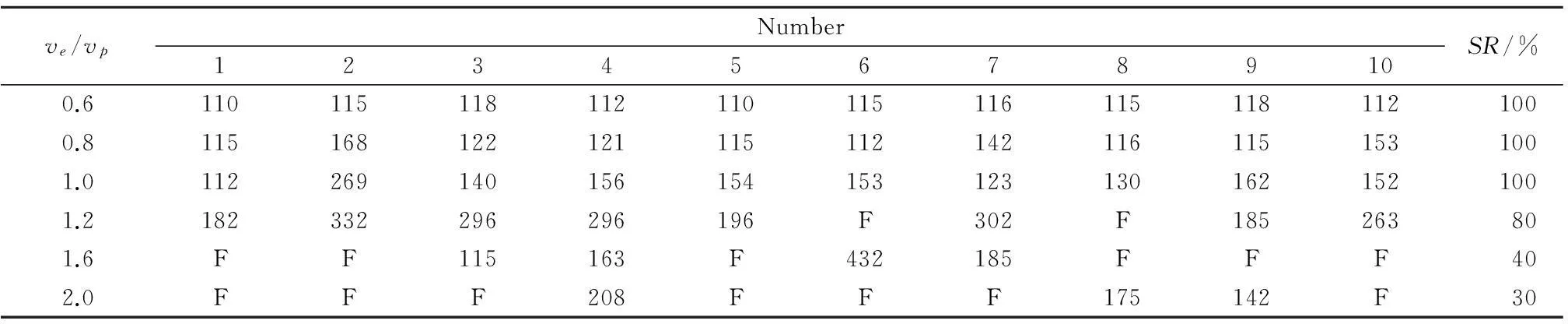
表2 有協商的追逐過程的時間數據
4 結語
在多機器人任務分配中,傳統的競爭性招標效用函數僅考慮機器人的理想性能而不能補償機器人的實際性能,忽略了由外部不確定干擾因素引起的協商系統穩定性問題。本文提出的基于機器人的真實性能的多機器人任務分配和協商的方法,改進了競爭性投標效用函數。改進的LSSVR實現了快速學習,魯棒控制器實現了維持系統穩定性。本方法的有效性已經在實驗中得到證明,實驗表明這個方法改進了任務分配的效率。
[1] 劉淑華,張崳,吳洪巖,等. 基于群體智能的多機器人任務分配[J].吉林大學學報:工學版本,2010(1): 123-129.
[2] 周菁,慕德俊. 多機器人系統任務分配研究[J].西北大學學報:自然科學版,2014(6): 403-410.
[3] Elango M,Nachiappan S P.Balancing multi-robot prioritized task allocation: A simulation ap-proach[C]//2011 IEEE International Conference on In-dustrial Engineering and Engineering Management. Singapore:IEEE, 2011: 1725-1729.
[4] Jouandeau N, Yan Zhi. Improved trade-based multi-robot coordination[C]//2011 6th IEEE Joint International Information Technology and Artificial Intelligence Conference (ITAIC),Chongqing, China:ITAIC, 2011:500-503。
[5] 祖麗楠,田彥濤,梅昊.大規模多移動機器人合作任務的分布自主協作系統[J].機器人,2006,28(5):470-477.
A Method of Task Allocation and Automated Negotiation for Multi-robots
PI Yu-zhen, etc.
(ChangchunInstituteofTechnology,Changchun130012,China)
Abstract:A method of task allocation and automated negotiation for multi-robots has been proposed. In the paper, the principles of task allocation are described based on the real capability of robot. During the construction of automated negotiation model, Least-Squares Support Vector Regression (LSSVR) has been improved to estimate the opponent's negotiation utility, and the robust controller of output feedback has been employed to optimize the utility performance indicators. Then, the protocol of negotiation and reallocation has been proposed to improve the real-time capability and task allocation. Finally, the validity of method is proved through experiments.
Key words:multi-robot; task allocation; consultation
文獻標志碼:A
文章編號:1009-8984(2016)01-0053-04
中圖分類號:TP242.6
作者簡介:皮玉珍(1981-),女(漢),長春,講師
基金項目:吉林省科技廳項目(20150204008SF,20130206049GX,201301010052JC)吉林省教育廳項目(2013296,2014324,2014339,2014327,2014309)
收稿日期:2015-11-04
doi:10.3969/j.issn.1009-8984.2016.01.012
主要研究多智能體、智能電網。
