一種用于教學的SQL編譯器設計與實現
2016-05-16 10:52:50袁明磊盛安元
長春工程學院學報(自然科學版) 2016年1期
袁明磊,盛安元
(1.安徽國防科技職業學院,安徽 六安 221600; 2.六安大江信息技術有限公司,安徽 六安 221600)
?
一種用于教學的SQL編譯器設計與實現
袁明磊1,2,盛安元1,2
(1.安徽國防科技職業學院,安徽 六安 221600; 2.六安大江信息技術有限公司,安徽 六安 221600)
摘要:SQL為數據庫的管理提供了極大的方便。目前已有一批優秀的數據庫管理軟件,如Oracal、Mysql、SQL server、Access等,然而國內數據庫管理軟件開發進程緩慢,目前尚未出現一個商用的國產數據庫管理軟件。這說明國內計算機教育方面存在“重理論,輕實踐”的問題。為了在教學中將編譯理論和編譯實踐相結合,設計并實現了一個簡化的基于FoxPro數據庫的SQL編譯器。該編譯器主要有詞法分析、語法分析、語義規約和數據庫文件操作等功能。
關鍵詞:詞法分析;語法分析;語句規約
0引言
1954年,IBM的John Backus帶領一批研究人員完成了世界上第一個編譯器的開發,將其命名為FORTRAN語言編譯器。在同一時期,Noam Chomsky也對自然語言的結構進行了研究,他將文法分為4類:0型文法、1型文法、2型文法和3型文法,最終使得編譯器的結構異常簡單。目前對編譯器的研究主要集中在面向對象編譯、并行編譯、自動編譯等技術方面。在編譯技術的發展過程中,國內對編譯技術的研究處于一個較為落后的階段,我國尚未有一個較為成熟的編譯器產品出現[1]。本文主要探討一個基于FoxPro2.6文件格式的簡化的SQL編譯器的實現過程,本產品只是一個用于教學的實驗產品,重點用來說明編譯器的基本原理。
FoxPro原名FoxBase,是美國Fox Software公司推出的數據庫產品,可在DOS上運行,與xBase系列相容,最高版本為2.6。Fox Software被微軟收購后,加以發展, 使其可以在 Windows 上運行, 并且更名為 Visual FoxPro[2]。
1總體設計
一個高級語言編譯器一般包括詞法分析、語法分析、語義分析、代碼生成、代碼優化等過程。該編譯器主要完成的工作是將相應的SQL語句進行詞法分析、語法分析、語義分析,然后根據語義完成數據庫文件的創建或修改。
該編譯器支持以下5種語法:1)創建數據表: CTEATE TABLE 數據表名 (字段列表);2)刪除數據表:DROP TABLE 數據表名;3)向數據表插入數據:INSERT INTO 數據表名 VALUE (字段值列表);4)查詢數據:SELECT 字段列表 FROM 數據表名 WHERE 查詢條件 ;5)刪除數據表記錄信息:DELETE FROM (數據表名) WHERE 查詢條件。該編譯器的工作流程如圖1所示。
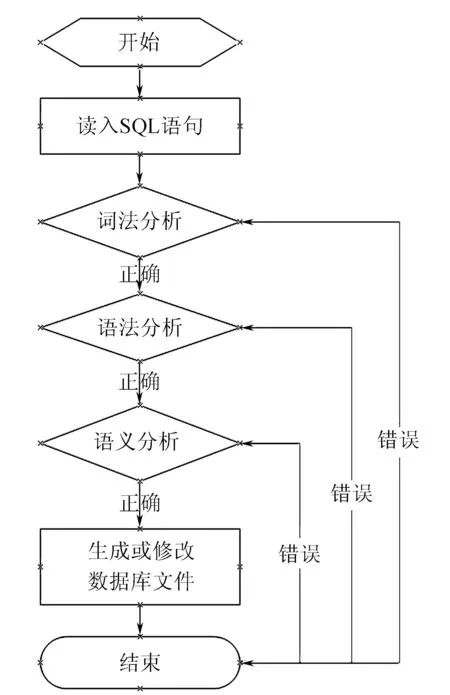
圖1 基于FoxPro2.6的SQL編譯器工作流程圖
2詞法分析的實現過程
詞法分析的主要作用是按照詞法分析的規則,對讀入的字符串進行第一階段的掃描,將字符串轉化為單詞屬性字的過程。最終將字符流轉化為詞法記號流。這個編譯器的關鍵字見表1。

表1 類FoxPro2.6的SQL編譯器關鍵字
該編譯器的界符和含義見表2所示。

表2 類FoxPro2.6的SQL編譯器的界符
該編譯器的運算符和含義如表3所示。

表3 類FoxPro2.6的SQL編譯器的運算符和含義表
該系統的常量主要有: 整數和字符串類型的常量。
系統的標識符要符合如下規則:
A->a|b|c…|A|B|C…|Z;
B->0|1|2|3…|9;
C->A(A|B)*。
系統實現時,使用<詞法記號, 屬性>這個二元組來描述一個詞法單元。該編譯器的詞法單元見表4所示。
詞法分析的過程下:1)首先讀取待編譯的文本文件;2)將文件讀取到Buf[MAXSIZE]數組內;3)查找開始符“{”,“{”之前的所有內容均為無效內容,如果整個文本均無“{”則報錯:“沒有開始符” ;4)依次取字符串,并判斷字符串的屬性值,記錄<詞法記號,屬性>二元組到words[MAXSIZE]數組內;5)記錄不合法的字符串,并將其記錄到一個錯誤詞法記號數組內;6)找到“}”,詞法分析結束。詞法分析完成后得到一個<詞法記號, 屬性>二元組隊列。該隊列為語法分析提供基礎數據。
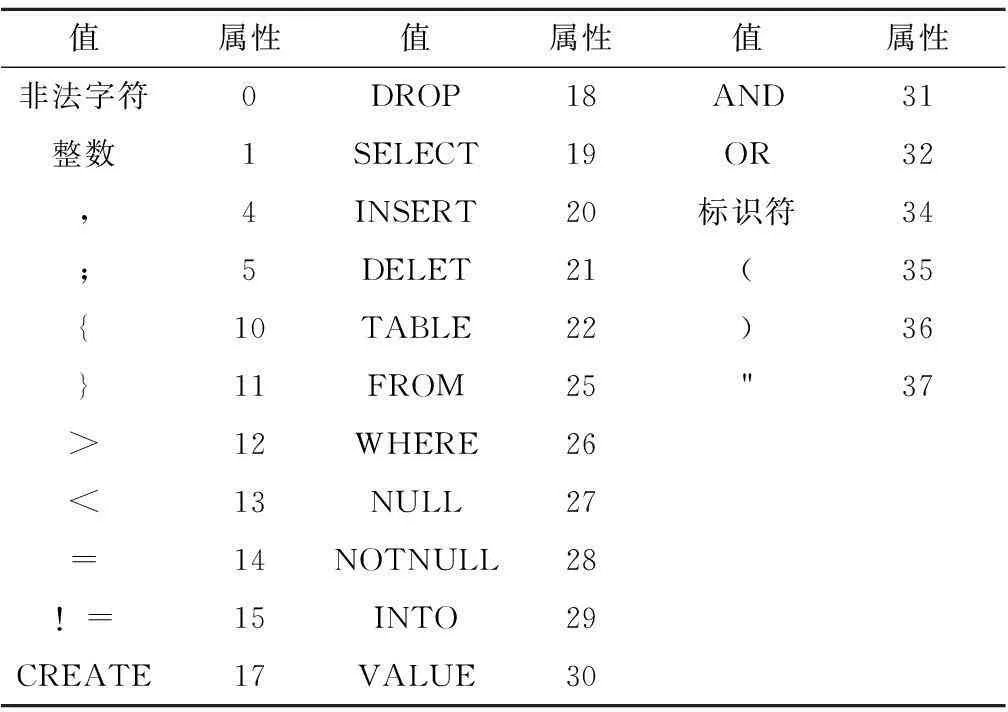
表4 類FoxPro2.6的SQL編譯器的詞法單元表
3語法分析
該系統的語法分析部分主要對5種語法的子句進行分析,分析結果如下:
1)CREATE TABLE<表名>(屬性列,…)
S->E:
E->CREATE TABLE 標識符(A)
A->標識符,A | ξ
2)DROPTANBLE <表名>
S2->E
E->DROPTABLE 標識符
3)SELECT *|(列名,…)
FROM (表名)
WHERE子句AND|OR子句…
S3->E
E->SELECT A FROM 標識符 B
A->*|標識符,C|標識符
C->標識符,C|標識符
B->ξ|WHERE D
D->I|IFD
I->G|GHI
H-> >|<|!|=
G->標識符
4)INSERT
INTO(表名)
VALLE(值|…);
S4->INSERT INTO 標識符 VALLUE(A)
A->字符串,A|字符串
5)DELETE
FROM(表名)
WHERE子句
S5->E
E->DELETE FROM 標識符
WHERE D
D->I|IFD
I->G|GHI
H-> >|<|!|=
G->標識符
根據上面的構造產生式,然后依據SLR技術來構造分析表。
分析表的結構用一個數組表示,數組中的值為1~101時表示將要進行移進操作。如果分析表中的值為0,就表示在歸約的過程中出現了錯誤,要進行相應的處理,此時為了不使語法分析的過程中斷,在這里采用了忽略錯誤子句的處理方法,即如果遇到錯誤的句子就提示有語法錯誤,然后跳到分號后的句子繼續進行歸約。如果在分析表數組中遇到負數則執行相應的歸約操作。
如果數組中的值為200~204,就表明此時已經歸約成功了,就調用相應的數據庫文件操作函數。
歸約過程中要用到一個非常關鍵的手動構造的SLR表,用一個101行47列的數組來表示SLR表。表的結構如下所示(由于表的值是不允許改變的所以將它定義為const 類型):
const int analyse_table[101][47]
{{0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0},
……
}; //手動構造的分析表;
具體歸約的過程如圖2所示,該模型的核心部分是一張分析表,這張分析表包括兩部分:一部分是“動作”ACTION表,另一部分是狀態轉換表GOTO表。他們都是二維數組。ACTION[s,a]規定了當狀態s面臨輸入符號a時應采取什么動作,GOTO[s,X]規定了狀態s面臨文法符號Xn(終結符號或非終結符) 時下一個狀態是什么。該分析器的總控程序的任何一步操作只需依照棧頂狀態和現在輸入的符號a執行ACTION[s,a]所規定的動作。
該部分的入口參數是:從詞法分析傳來的words[MAXSIZE]結構體數組。
出口操作是:調用數據庫操作函數用到的全體參數。
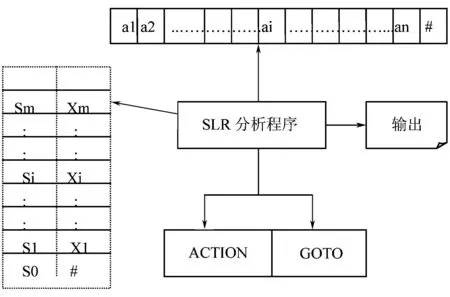
圖2 SLR分析器模型
4系統用到的主要數據結構
1)word_num的作用是紀錄詞法分析過程遇到的單詞數量。
2)words[MAXSIZE]用于記錄在詞法分析時所分析的單詞信息、單詞所處的行列和單詞的屬性。
struct word_type
{
charword_name[10];
intcol;
intline;
inttype;
}words[MAXSIZE];
3)操作數據庫文件的參數結構,用一個結構體紀錄,在調用CREATE, DROP,SELECT,INSERT,DELETE時,該結構體都是有效的。其中table_name用來紀錄要操作表的名字,other_char用來紀錄其余的標識符,在不同的調用中有不同的含義。compare[10]用于記錄where子句中的比較符號如:>,<,=,!=; logic[10] 用于記錄where子句中的邏輯符號AND OR;num用于記錄接收標識符的個數;cmp_num用于記錄接收比較值的個數。
struct param
{
chartable_name[10];//記錄建立表的名字
charother_char[20][10];//記錄在歸約的過程中其他的標識符
int compare[10];//記錄在歸約過程中的比較符的值;
int logic[10] ;//用于接收邏輯符的值,AND與OR
int num;//用于記錄接收標識符的個數
int cmp_num;//接收比較值的個數
};
4)語法分析類,刻畫語法分析的過程,需要定義當前處理到了第幾句話和當前已經讀取的單詞的個數。
classLexicalAnalysis
{
private:
int sentence;//記錄當前歸約到了第幾句話
int ticket1;//標識當前已讀單詞的個數
int top;//棧頂指針
int stack[100][2];//棧;
struct guiyue_help r1,r2,r3,r4,r5,r6,r7,r8,r9,r10,r11,r12,r13,r14,r21,r22,r23,r31,r41,r42,r51,r52,r53,r54,r55,r56,r57,r58,r59,r60; //歸約時結構體
struct param x;//在歸約時記錄參數的數組
public:
SyntaxAnalysis()//語法分析的構造函數
{
top=0;
sentence=1; //記錄句子的值
//記錄讀入的單詞標識
ticket1=0;
//對歸約公式輔助值的初始化
r1.length=1; r1.type=39;
r2.length=3; r2.type=39;
r3.length=3; r3.type=41;
……
}
};
5數據庫文件的創建或修改
該模塊主要包括5個函數,分別完成創建數據表文件、刪除數據表文件、查詢數據記錄、插入數據記錄、刪除數據記錄的功能。這5個函數根據接收的參數對數據庫dbf文件進行讀寫操作,這部分是按照dbf文件格式對文件進行操作。
FoxPro表文件由結構描述和數據記錄兩大部分組成。而結構描述部分又分為文件整體描述部分和字段描述部分。
文件整體描述部分共占32個字節,各字節意義如下:第1字節為數據庫標志(03H),若有Memo字段,此字段就是F5H。第2~4字節為最后一次修改的日期,格式是年、月、日。第5~8字節為記錄個數。第9~10字節為結構描述部分的長度。第11~12字節為記錄長度。第29字節是結構復合索引文件的標志,若建立了結構索引文件,該字節為1,否則為0。第13~32字節除29字節外都保留。
文件整體描述部分之后緊接著字段描述部分,每一個字段用32個字節描述其字段名、字段類型、字段寬度、小數位。字段描述部分各字節的意義為:第1~11字節為字段名。第12字節為字段的數據類型。第13~16字節表示內存地址。第17字節表示字段寬度。第18字節表示小數位數。第19、20字節為FoxPro網絡專用。第21字節表示工作區。第24字節為SET FIELDS標志。其余字節保留。
庫文件結構描述部分有一個終止標志(0D),緊接此終止標志之后就是記錄部分,記錄部分按文本格式存放[3]。
按照以上格式,就可以對dbf文件進行讀寫操作。下面以創建為例介紹如何實現對dbf文件的操作。
void create(param x) //建立dbf文件的函數
首先按照文件整體描述的格式,用putc()函數和fprintf()函數一個字節一個字節地初始化前32個字節,緊接著進行初始化字段描述部分,在第12字節的時候統一規定字段的屬性為字符型。其他字節按照FroxPro格式要求讀寫。
6結語
實踐證明該系統可以實現對簡單的SQL語句進行分析,并可以生成Foxpro2.6格式的文件。該系統可以作為編譯原理教學時的實驗范例,將復雜的編譯原理和編程實踐進行結合,提高編譯原理課程的教學效果。
參考文獻
[1] 魏樂. 一個簡單語言編譯器的設計與實現[J]. 成都信息工程學院學報,2007, 22(3): 312-316.
[2] 簡聰海.高等C的解析[M].天津:天津大學出版社,1996.
[3] 姜靈敏.FoxPro2.6程序設計應用與技巧[M].北京:人民郵電出版社,1997.
The Design and Implementation of a SQL Compiler for Teaching
YUAN Ming-lei, etc.
(AnhuiVocationalCollegeofDefenseTechnology,LiuanAnhui221600,China)
Abstract:SQL provides a great convenience for the management of the database. At present, there is a number of excellent database management software, such as Oracal, Mysql, SQL, server, access, etc.. However, the development of database management software in China is slow, and there is not yet a commercial database management software by now. This shows that there is a problem of “emphasizing theory, neglecting practice” in computer education in China. In order to combine the computing theory and computing practice during teaching process, the design and implementation of a simple FoxPro database based SQL compiler are realized in this article. The compiler mainly has lexical analysis, syntax analysis, semantic specification, database file operations, and other functions.
Key words:lexical analysis; syntax analysis; statement specification
文獻標志碼:A
文章編號:1009-8984(2016)01-0114-05
中圖分類號:TP311.131
作者簡介:袁明磊(1985-),男(漢),江蘇徐州,碩士,講師
基金項目:安徽國防科技職業學院院級質量工程項目(gf2015ck03)
收稿日期:2015-11-16
doi:10.3969/j.issn.1009-8984.2016.01.026
主要研究計算機應用。
