基于信息熵的網絡課程學生分類模型研究
2016-05-30 01:29:35黃金晶黃黎
寧波職業技術學院學報 2016年5期
黃金晶 黃黎
摘 要: 在網絡課程教學中對學生進行分類,教師能為不同類別的學生制定相應的教學策略,提高教學質量。文章將信息熵理論運用于學生分類,在預處理之后的數據上,采用ID3算法構建了基于信息增益的決策樹,生成相應的決策規則,為新的輸入數據提供了分類依據。
關鍵詞: 網絡課程; 信息熵; 決策樹; 信息增益
中圖分類號: TP 393 文獻標志碼: A 文章編號: 1671-2153(2016)05-0084-03
0 引 言
網絡課程[1]教學是信息時代下課程新的表現形式,它以學生為主體,利用現代網絡技術,為學生提供多方面的學習素材,如文檔、視頻等;同時也支持多種形式的師生互動,如在線答疑、討論,使學生在任何時間任何地點都可以身臨其境的學習。此外,在線測試也提供了對學生學習效果的檢測。
隨著網絡學習人群的增加,網絡教學平臺中留下了大量的數據,利用數據挖掘技術[2]可以從中獲取有用的信息。登錄網絡教學平臺學生的基礎數據不同,如訪問時長、論壇活躍度、學習能力等。若對學生進行分類,對不同的類別的學生采取適合其特點的教學策略,這為個性化學習、因材施教提供了可能。本文主要探討數據挖掘技術中的信息熵[3]在學生分類模型中的應用,通過對已知樣本的學習,預測未知類別學生的分類。
1 學生分類數據挖掘流程
學生登錄網絡教學平臺后,留下了大量的訪問數據,比如學號、訪問資源、訪問時長等,在這些數據中用人工的方式提取有價值的數據是一件非常困難的事,因而可以借助數據挖掘技術對數據進行分析,整體流程如圖1所示。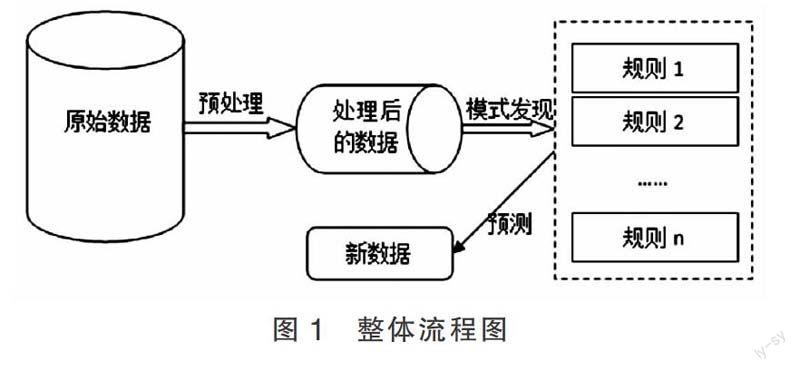
圖1中,整個流程分為數據采集與預處理、模式發現、規則分析。原始數據中包含了大量帶有噪聲的和冗余的信息,這些數據的存在會對分析的結果造成干擾,所以必須對其進行過濾和清洗,并將其變成高質量的數據。在模式發現階段,使用決策樹[4]的分類算法對數據集進行分析,獲得不同的分類規則,規則1、規則2…規則n,當新的學生數據進來后,根據已有的規則進行匹配,獲得新數據所在的類別,即對新數據進行預測。
2 分類模型構建與分析
2.1 學生分類模型構建
分類模型的構建有多種方法,本文使用ID3算法[5]進行分類的構建。構建學生的分類模型,首先要獲得參與決策的相關屬性,為每個屬性計算信息增益[6],選擇最大信息增益的屬性進行劃分。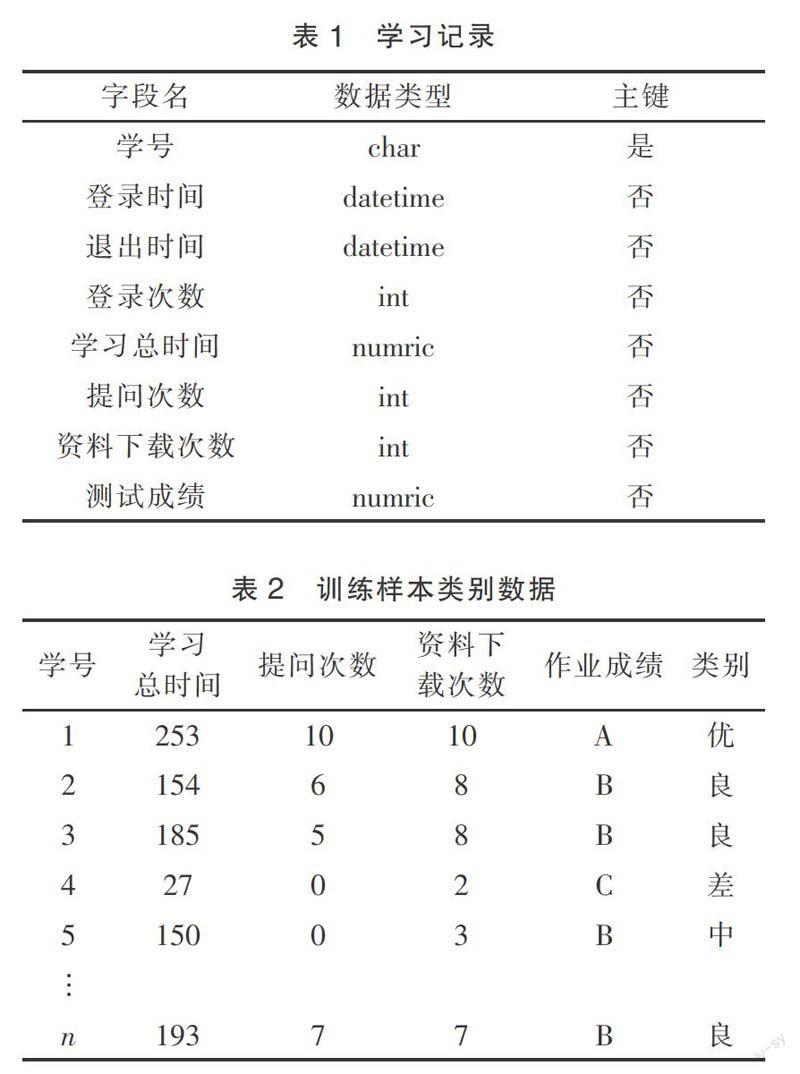
表1為學生學習記錄表,從該表中可以獲得影響決策的屬性,如學習總時間、提問次數、資料下載次數以及測試成績。利用聚類算法[7]對預處理后的訓練數據進行聚類,得到數據集對應的分類,優、良、中、差4個類別,如表2所示。
根據訓練樣本數據計算各屬性的信息熵。表2中部分屬性以數值的方式呈現,比如學習總時間,可以對其進行相應轉換,轉換規則:≥180為學習時間長,100~179學習時間中等,小于100為學習時間短。其他屬性可以做同樣的轉換。以前10條記錄為例進行分類模型構建,數據如表3所示。
在屬性“學習總時間”上的信息增益:Gain(S,A)=lnfo(S)-lnfo(S,A)=1.295-0.59=0.705位。
同理,為剩余的每個屬性計算信息增益,選擇最大信息增益的屬性進行劃分。
Gain(S,“提問次數”)=0.345位;Gain(S,“資料下載次數”)=0.81位;Gain(S,“作業成績”)=0.97位。因而選擇作業成績作為決策樹根節點的劃分屬性。而后,按照相同的方法進行遞歸選擇,直到數據不能進一步劃分為止,最終的決策樹如圖2所示。
2.2 分類規則描述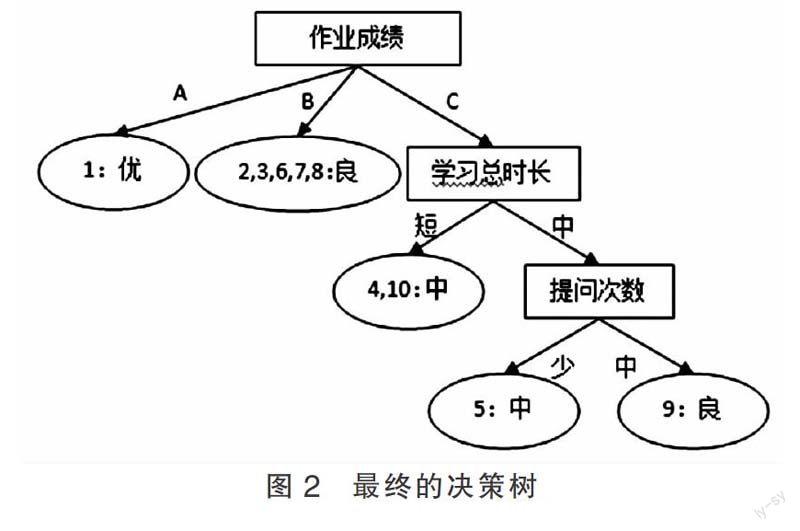
根據最終構建的決策樹,可以描述相應的規則,以此作為新數據分類的依據。圖2所示的決策樹,規則如下:
(1)作業成績為A,類別為優;
(2)作業成績為B,類別為良;
(3)作業成績為C,且學習時長為短,類別為中;
(4)作業成績為C,學習時長為中,且提問次數為中,類別為良。
(5)作業成績為C,學習時長為中,且提問次數為少,類別為中。
當有新的學生數據時,可以根據相關的規則推斷學生所屬的類別。比如一個新的學生數據,學習時長200 min,提問次數3次,資料下載8次,作業成績A,根據分類得出的規則,該生的作業成績為A,類別為優。以上結論是由例子中的10條訓練數據得出的,當訓練樣本數據達到一定數據量,所得的規則是有意義和有價值的,可以用來預測新數據所屬的類別。
3 結束語
網絡遠程教育是建立在現代信息技術平臺上的一種教學模式,是傳統教育的補充。隨著計算機技術、網絡技術等的不斷發展,網絡教育也逐漸展現了它的優勢。將信息熵理論用于網絡教學的學生分類,可以幫助教師為每個群組學生制定不同教學策略,因材施教。
參考文獻:
[1] 李青,劉洪沛. 網絡課程的設計模式[J]. 北京郵電大學學報(社會科學版),2009,11(1):96-100.
[2] SOMAN K P,SHYAM D,AJAY V. Insight into Data Mining Theory and Practice[M]. 北京:機械工業出版社,2009:4-23.
[3] HU Q H,GUO M Z,YU D R,et al. Information entropy for ordinal classification[J]. 2010,53(6):1188-1200.
[4] Potharst R,Bioch J C. Decision trees for ordinal classification[J]. Intell Data Anal,2000,4:97-111.
[5] 劉紅巖,陳劍,陳國青. 數據挖掘中的數據分類算法綜述[J]. 清華大學學報(自然科學版),2002,42(6):727-730.
[6] BRESLOW L A,AHA W. Dayid simplifying decision tree:a survey[J]. KnowledgeEngineering Review,1997,12(1):1-40.
[7] 呂曉鈴,謝邦昌. 數據挖掘方法與應用[M]. 北京:中國人民大學出版社,2009:77-86.
Abstract: According to the students classification in the network courses teaching, teachers can make corresponding teaching strategies for different kind of students and improve teaching quality. The paper classifies students based on the information entropy theory, constructs decision tree based on information gain by using ID3 algorithm on thedata after preprocessing and generate the corresponding decision rules, which are the basis for the new input data.
Keywords: network course; information entropy; decision tree; information gain
(責任編輯:徐興華)
