基于HodgeRank的人臉美貌度預(yù)測(cè)①
2016-06-15 03:50:22蔣婷朱明中國(guó)科學(xué)技術(shù)大學(xué)信息科學(xué)技術(shù)學(xué)院合肥230022
計(jì)算機(jī)系統(tǒng)應(yīng)用 2016年4期
蔣婷,朱明(中國(guó)科學(xué)技術(shù)大學(xué) 信息科學(xué)技術(shù)學(xué)院,合肥 230022)
?
基于HodgeRank的人臉美貌度預(yù)測(cè)①
蔣婷,朱明
(中國(guó)科學(xué)技術(shù)大學(xué) 信息科學(xué)技術(shù)學(xué)院,合肥 230022)
摘 要:隨著計(jì)算機(jī)技術(shù)的迅速發(fā)展以及人臉識(shí)別技術(shù)的成熟,人臉美貌度受到越來(lái)越多的關(guān)注和研究.針對(duì)目前的研究方法中存在的對(duì)訓(xùn)練數(shù)據(jù)集的評(píng)分過(guò)多依賴人工操作,以及對(duì)人臉美貌度的預(yù)測(cè)結(jié)果不夠詳細(xì)等問(wèn)題,本文提出基于HodgeRank的人臉美貌度預(yù)測(cè)系統(tǒng),利用數(shù)據(jù)挖掘方法學(xué)習(xí)女性人臉的美貌度特征,構(gòu)造一個(gè)模擬預(yù)測(cè)人臉美貌度的系統(tǒng).明顯區(qū)別于之前的研究,該系統(tǒng)訓(xùn)練和測(cè)試時(shí)采用的人臉數(shù)據(jù)集放寬了對(duì)姿態(tài)、光照以及所處環(huán)境等條件的限制,評(píng)分所需的人工操作大大減少,無(wú)需進(jìn)行大量的人工標(biāo)定,使用圖像的原始像素或紋理特征作為輸入,分別采用聚類和改進(jìn)的BP網(wǎng)絡(luò)的方法,得到更符合人類特征的美貌度預(yù)測(cè)結(jié)果.
關(guān)鍵詞:美貌度預(yù)測(cè); HodgeRank排序; 聚類思想; 改進(jìn)的BP網(wǎng)絡(luò); 人臉特征
美可以給人帶來(lái)心靈的愉悅,愛(ài)美更是人類的天性.人類對(duì)面部美麗的追求吸引了不同領(lǐng)域?qū)W者對(duì)美的研究,哲學(xué)、醫(yī)學(xué)、認(rèn)知心理學(xué)方面的專家對(duì)人臉美麗進(jìn)行了很多年的研究工作,但什么樣的人臉才算是美麗的,到目前為止都沒(méi)有給出科學(xué)的解釋,如何更好的計(jì)算美,將有助于人類美麗得到科學(xué)、客觀、可量化的描述,使人臉美麗研究得到長(zhǎng)足的發(fā)展.隨著社會(huì)的發(fā)展,人們不僅滿足于物質(zhì)生活,還不斷關(guān)注自己的外表.越來(lái)越多的人正尋求不同的方法,力圖使美貌度上升.整容行業(yè)和化妝品行業(yè)的興起,使對(duì)人臉美貌度的研究具有巨大的經(jīng)濟(jì)和社會(huì)效益,在臉部創(chuàng)傷修復(fù)手術(shù)以及計(jì)算機(jī)動(dòng)畫和游戲的角色設(shè)計(jì)中有著重要的參考價(jià)值.可見(jiàn),人臉美貌度的研究應(yīng)用已深入我們生活中,具有重要的實(shí)用價(jià)值.
隨著計(jì)算機(jī)技術(shù)的不斷發(fā)展,計(jì)算機(jī)視覺(jué)問(wèn)題越來(lái)越受到人們的關(guān)注,對(duì)2D和3D人臉圖片的研究更是熱點(diǎn),例如人臉識(shí)別[1,2],面部表情識(shí)別[3,4],性別識(shí)別[5],面部年齡估計(jì)[6,7]等,更加促進(jìn)了人們對(duì)美貌度的研究和關(guān)注.對(duì)人臉美貌度的預(yù)測(cè)是計(jì)算機(jī)視覺(jué)和生物學(xué)領(lǐng)域研究的熱門話題,然而人臉美貌度卻是個(gè)很難定義的概念,我們可以很容易判斷人眼看到的人臉照片是否美麗,但卻很難明確的定義人臉的美麗信息.目前對(duì)人臉美貌度的研究常用的方法是計(jì)算人臉各部位的比例作為人臉美貌度預(yù)測(cè)值或利用深度學(xué)習(xí)的方法來(lái)預(yù)測(cè)人臉的美貌度.根據(jù)人臉比例得到的人臉美貌度預(yù)測(cè)值是個(gè)固定的數(shù)值,無(wú)法反應(yīng)隨著區(qū)域,時(shí)間的變化人們審美的變化趨勢(shì).深度學(xué)習(xí)方法首先要對(duì)人臉數(shù)據(jù)集進(jìn)行評(píng)分,需要大量的人工操作且得到的人臉美貌度的預(yù)測(cè)值并不是一個(gè)具體的分值,只能說(shuō)明圖片所在的人臉美貌度的大致區(qū)域,不能直觀的展示人臉美貌度大小.針對(duì)上述問(wèn)題,我們提出基于HodgeRank的人臉美貌度預(yù)測(cè)系統(tǒng),該系統(tǒng)能在數(shù)據(jù)集處理上大大減少人工的評(píng)分操作,得到人臉美貌度的大致范圍,同時(shí)也得到表征人臉美貌度的0~100間的一個(gè)具體的值,更直觀的展示人臉美貌度大小.
文章下面的安排如下: 第一章介紹相關(guān)工作,第二章介紹提出的方法,第三章介紹實(shí)驗(yàn)及實(shí)驗(yàn)結(jié)果,第四章進(jìn)行總結(jié).
1 相關(guān)工作
人臉美貌度預(yù)測(cè)主要涉及三個(gè)方面: 數(shù)據(jù)集準(zhǔn)備、人臉特征提取、人臉美貌度預(yù)測(cè)方法.
1.1數(shù)據(jù)集準(zhǔn)備

1.2人臉特征提取
人臉美貌度的研究中選擇的人臉特征主要有: (1)幾何特征,在人臉圖片上提取有意義的特征點(diǎn),計(jì)算感興趣點(diǎn)之間的幾何距離和由這些距離所構(gòu)成的比率矢量.如[10,11]找出特征點(diǎn),計(jì)算各部分的比例作為特征值; 取人臉的68個(gè)關(guān)鍵特征點(diǎn)并歸一化作為特征值[12]; 文獻(xiàn)[13]利用面部的對(duì)稱信息等.(2)表觀特征,對(duì)美麗的分析不再局限于特征點(diǎn),也不局限于幾何距離,對(duì)人臉的美麗信息的描述采用圖片的原始像素或紋理信息等,并不涉及結(jié)構(gòu)和層次性特征表示.如文獻(xiàn)[14]中將整張圖片作為特征輸入.
方法(1)需要的人臉特征和人臉器官的位置相關(guān),要求人臉圖片必須是正面的,且由于要進(jìn)行人臉識(shí)別,環(huán)境因素如關(guān)照、人臉?biāo)幁h(huán)境的復(fù)雜性對(duì)實(shí)驗(yàn)的影響很大.方法(2)這種方法克服了要求人臉圖片為正面的要求,對(duì)環(huán)境條件的要求也相對(duì)變得比較寬.在本文中,我們對(duì)比幾何特征和表觀特征的實(shí)驗(yàn)結(jié)果.
1.3人臉美貌度預(yù)測(cè)方法
人臉美貌度研究中常用的方法有: 根據(jù)黃金比例的美學(xué)標(biāo)準(zhǔn),將人臉各部分所得的比例和標(biāo)準(zhǔn)值進(jìn)行比較,得到人臉的美貌度[10]; 文獻(xiàn)[12]選定一個(gè)人眼認(rèn)定的美貌度高的人臉作為平均人臉,計(jì)算與平均人臉之間的距離(特征值間的距離)作為人臉的美貌度的預(yù)測(cè)值; 用深度學(xué)習(xí)的方法來(lái)訓(xùn)練人臉美貌度的模型從而得到人臉美貌度; 文獻(xiàn)[15]中提出的CSOR方法根據(jù)代價(jià)函數(shù)的結(jié)果來(lái)預(yù)測(cè)美貌度的類別等.在本文中分別采用聚類算法和BP神經(jīng)網(wǎng)絡(luò)的算法來(lái)預(yù)測(cè)人臉的美貌度.首先由于人臉美貌度類似的人臉圖片的特征是相近的,所以在對(duì)人臉圖片根據(jù)美貌度分類時(shí)可以采用聚類算法,將人臉?lè)殖伞昂苊馈薄ⅰ懊馈薄ⅰ耙话恪薄ⅰ俺蟆薄ⅰ昂艹蟆?大類,其次利用神經(jīng)網(wǎng)絡(luò)算法進(jìn)行特征上更加細(xì)致的匹配,得到更加細(xì)致的分類結(jié)果.
2 提出的方法
整個(gè)系統(tǒng)分為兩個(gè)部分: 圖片數(shù)據(jù)集處理和圖片分類,如圖1所示.

圖1 系統(tǒng)框圖
數(shù)據(jù)處理部分輸入圖片數(shù)據(jù)集,進(jìn)行隨機(jī)的圖片間的兩兩對(duì)比,使得至少一副圖片和其余三張圖片進(jìn)行了對(duì)比,得到對(duì)比矩陣.將該對(duì)比矩陣輸入HodgeRank排序算法,得到每幅圖片的相對(duì)分?jǐn)?shù).圖片分類部分輸入圖片的特征和對(duì)應(yīng)的分值,第一種方法根據(jù)圖片分值將某一范圍內(nèi)的圖片劃分為一類,根據(jù)聚類思想得到聚類中心,根據(jù)距離聚類中心的距離預(yù)測(cè)人臉美貌值.第二種方法直接將圖片特征作為訓(xùn)練輸入,圖片對(duì)應(yīng)的分值作為訓(xùn)練目標(biāo)矩陣,利用BP神經(jīng)網(wǎng)絡(luò)進(jìn)行訓(xùn)練得到圖片分值的學(xué)習(xí)模型,即我們所需要的美貌度預(yù)測(cè)模型.
2.1HodgeRank排序
HodgeRank[16]是2008年Yao,Jiang,Lim等人提出來(lái)的,作為一個(gè)分析數(shù)據(jù)排列尤其是針對(duì)不完整、不平衡數(shù)據(jù)集的有用的工具,可以解決選舉理論中的數(shù)據(jù)不一致以及非傳遞性的偏好關(guān)系.理論上來(lái)說(shuō),HodgeRank排序算法將比較結(jié)果空間分解為三個(gè)子空間: 梯度子空間、諧波子空間、卷曲子空間.梯度子空間包含傳遞性的比較結(jié)果,如類似A 令∧={1,2,…,m}是m個(gè)測(cè)試者,V={1,2,…,n}是圖片數(shù)據(jù)集.對(duì)比數(shù)據(jù)集是∧×V×V的函數(shù),對(duì)個(gè)測(cè)試者α結(jié)果是反對(duì)稱矩陣,如表示第α個(gè)測(cè)試者對(duì)比圖片i和圖片j的結(jié)果),用二值化表示為: 定義非負(fù)權(quán)函數(shù)ω:∧×V×V→[0,∞) 統(tǒng)計(jì)排名聚合問(wèn)題就轉(zhuǎn)變?yōu)榍笳w排名得分s:V→R 的問(wèn)題,即轉(zhuǎn)化為求 其中si,sj表示圖片i和圖片j的得分.上式等價(jià)的加權(quán)最小平方問(wèn)題為: 令G=( V,E)表示圖片對(duì)比形成的圖,V表示圖片節(jié)點(diǎn),E表示對(duì)比的兩節(jié)點(diǎn)間的邊,有 假設(shè)對(duì)于每一對(duì)比較的圖片{i,j}的對(duì)比次數(shù)是nij,有aij個(gè)評(píng)分者認(rèn)為圖片i比圖片j美麗(反之有aji個(gè)評(píng)分者認(rèn)為j比i美麗),則有aij+aji= nij(沒(méi)有交叉發(fā)生時(shí)).對(duì)每一條邊{i,j}∈E偏好概率為,(4)式可以寫為: 假設(shè)圖片的真實(shí)偏好概率可以被V上的線性變換函數(shù)代替,有 1)均勻分布模型: 2)Bradley-Terry模型: 3)Thurstone-Mosteller模型: 其中σ和ρ是常量,F是高斯誤差函數(shù) 4)三角變換模型: 這個(gè)模型表征了變量穩(wěn)定性,Yij只取決于邊{i,j}的數(shù)量或ωij,但不是真正的概率pij. HodgeRank提供了一個(gè)在不同數(shù)據(jù)模型下的總體分?jǐn)?shù)的排序以及獲得的總體排序的不一致性的測(cè)量值,在圖2中對(duì)比每種模型下美貌度的分布. 2.2圖片分類 經(jīng)過(guò)HodgeRank排序的分類后,得到訓(xùn)練數(shù)據(jù)集每張圖片對(duì)應(yīng)的分值,并將其作為圖片的分類結(jié)果.根據(jù)圖片分類結(jié)果的詳細(xì)程度有兩種預(yù)測(cè)方法: 粗分類,細(xì)分類. 2.2.1粗分類 采用聚類思想.經(jīng)過(guò)分類后得到的分值歸一化后分布在0~100,將分值每隔20分歸為一類,如0~20分作為第一類,21~40作為第二類,依次類推,分別對(duì)應(yīng)人臉美貌度的“很丑”、“丑”、“一般”、“美”、“很美”.在分值分類的同時(shí)相應(yīng)的圖片也進(jìn)行分類,且提取每個(gè)類別的圖片特征.計(jì)算每個(gè)類別中每個(gè)樣本間的相互距離,取到各樣本點(diǎn)距離最近的點(diǎn)為該類別的聚類中心.輸入待測(cè)圖片時(shí),提取其相應(yīng)的特征,計(jì)算其與各聚類中心的距離,取距離最近的聚類中心的類別為該測(cè)試樣本的類別. 2.2.2細(xì)分類 對(duì)圖片進(jìn)行更加細(xì)致的分類采用BP神經(jīng)網(wǎng)絡(luò)算法.標(biāo)準(zhǔn)的神經(jīng)網(wǎng)絡(luò)算法因簡(jiǎn)單、宜行、計(jì)算量小、并行性強(qiáng)等優(yōu)點(diǎn)受到廣泛的應(yīng)用.但在長(zhǎng)期的使用過(guò)程中發(fā)現(xiàn)BP算法存在訓(xùn)練時(shí)間長(zhǎng)、收斂速度慢、易陷入局部最小點(diǎn)等缺陷.針對(duì)以上問(wèn)題采用改進(jìn)的BP算法,從以下三個(gè)方面來(lái)改進(jìn)標(biāo)準(zhǔn)的BP網(wǎng)絡(luò). 1)增加動(dòng)量項(xiàng)[17]: 從前一次的權(quán)值調(diào)整中取出一部分疊加到本次的權(quán)值調(diào)整中,如 其中α是動(dòng)量系數(shù),α∈(0,1).動(dòng)量項(xiàng)反應(yīng)了以前積累的調(diào)整經(jīng)驗(yàn),對(duì)于t時(shí)刻的調(diào)整起阻尼作用,當(dāng)誤差曲面出現(xiàn)驟然起伏時(shí),可以減小震蕩趨勢(shì),提高訓(xùn)練速度. 2)自適應(yīng)調(diào)節(jié)學(xué)習(xí)率: 學(xué)習(xí)率h就是步長(zhǎng),從誤差曲面上來(lái)看,在平坦區(qū)域η太小會(huì)使訓(xùn)練次數(shù)增加,在誤差變化劇烈區(qū)域,η太大或跨過(guò)較窄的坑凹處,使訓(xùn)練出現(xiàn)震蕩,反而增加了迭代次數(shù).這里采用自適應(yīng)調(diào)節(jié)算法,經(jīng)過(guò)權(quán)值調(diào)整后如果總誤差上升,則本次調(diào)整無(wú)效即η·β(β<1),當(dāng)總誤差開(kāi)始下降后,再進(jìn)行η·θ(θ>1). 根據(jù)得到的圖片類別和提取的圖片特征直接進(jìn)行BP網(wǎng)絡(luò)訓(xùn)練.這里輸入圖片特征,輸出是對(duì)應(yīng)的類別最終得到一個(gè)0~100間的數(shù)值作為最終的分值. 圖2 常用F模型HodgeRank排序結(jié)果分布 3.1實(shí)驗(yàn)數(shù)據(jù)的HodgeRank排序 使用六個(gè)測(cè)試者(三個(gè)男性,三個(gè)女性)對(duì)2000張圖片進(jìn)行隨機(jī)的兩兩對(duì)比實(shí)驗(yàn),保證每張圖片都進(jìn)行了至少3次和其余圖片的對(duì)比,平均每人進(jìn)行的比較次數(shù)為6010次,比次的全連接比較大大減少了測(cè)試者的工作量.對(duì)實(shí)驗(yàn)結(jié)果進(jìn)行HodgeRank排序時(shí),每張人臉圖片作為一個(gè)節(jié)點(diǎn),測(cè)試者的一次比較就是連接任意兩個(gè)節(jié)點(diǎn)構(gòu)成一條邊,這相當(dāng)于進(jìn)行了6010次獨(dú)立同分布的(I.I.D)的對(duì)比實(shí)驗(yàn).HodgeRank將結(jié)果分解為三個(gè)正交的部分.即總體分?jǐn)?shù)的排序以及獲得的總體排序的不一致性的測(cè)量值.將實(shí)驗(yàn)得到的分?jǐn)?shù)值歸一化到0~100作為圖片的相對(duì)分值.常用的F模型得到的排序結(jié)果分布如圖2所示.在實(shí)驗(yàn)結(jié)果,考慮到分類結(jié)果的均勻性,選取Bradley-Terry模型和三角變換模型的平均值作分值.如圖3所示,HodgeRank得到的圖片的分?jǐn)?shù)結(jié)果. 圖3 圖片分類結(jié)果: (1)人工分類屬于第一類的7張圖片,(2)HodgeRank排序分類得到的7張第一類圖片,(3)人工分類屬于第五類的7張圖片,(4)HodgeRank排序分類得到的7張第五類圖片,(5)實(shí)驗(yàn)得到的圖片相對(duì)分值 3.2人臉美貌度預(yù)測(cè)的實(shí)驗(yàn)結(jié)果及分析 圖片特征對(duì)實(shí)驗(yàn)結(jié)果有很大的影響,我們采用如下的圖片特征進(jìn)行對(duì)比實(shí)驗(yàn): 1)基于密度: 直接將整張圖片的原始像素作為圖片特征的輸入,圖片大小為100×100,得到的特征向量為10000×1維. 2)LBP特征: 使用常用的8鄰域基本的LBP,并將LBP的結(jié)果進(jìn)行直方圖均衡化,得到特征向量為256×1維 3)基于特征點(diǎn): 使用ASM算法提取人臉上68個(gè)點(diǎn)作為圖片特征,得到特征向量為136×1維. 3.2.1粗分類 針對(duì)聚類算法,將2000張圖片按照分值分為5類,在實(shí)驗(yàn)中每個(gè)類別所占的比例如下: 16%、19%、24%、24%、17%,圖片分布大致均勻.分別計(jì)算圖片所對(duì)應(yīng)的以上三種特征,得到對(duì)應(yīng)類別圖片的聚類中心.選擇100張圖片進(jìn)行測(cè)試,統(tǒng)計(jì)錯(cuò)誤預(yù)測(cè)的圖片張數(shù),計(jì)算誤差,如表3中方法一所示. 3.2.2細(xì)分類 針對(duì)BP網(wǎng)絡(luò),激活函數(shù)采用單極形Sigmoid函數(shù),為了提高系統(tǒng)的穩(wěn)定性和效率采用交叉驗(yàn)證的方法來(lái)進(jìn)行網(wǎng)絡(luò)訓(xùn)練,誤差取所有樣本的均方誤差和.針對(duì)不同的圖片特征網(wǎng)絡(luò)的輸入層、隱含層、輸出層的節(jié)點(diǎn)數(shù)如表1所示. 表1 不同的圖片特征對(duì)應(yīng)的網(wǎng)絡(luò)各層的節(jié)點(diǎn)數(shù) 隱含層節(jié)點(diǎn)數(shù)對(duì)比取值200,150,100,50,30,20時(shí)的實(shí)驗(yàn)結(jié)果來(lái)取值.表2顯示了標(biāo)準(zhǔn)BP網(wǎng)絡(luò)和改進(jìn)的BP網(wǎng)絡(luò)在LBP特征下的迭代次數(shù)的對(duì)比. 表2 標(biāo)準(zhǔn)BP和改進(jìn)BP迭代次數(shù)對(duì)比(LBP特征) 由于人臉美麗的主觀性,每個(gè)人對(duì)同樣的人臉給定的分值是不同的,但總是基于某個(gè)分值上上下波動(dòng),所以在測(cè)試實(shí)驗(yàn)結(jié)果的準(zhǔn)確率時(shí),我們定義誤差的計(jì)算方式時(shí)考慮如下兩點(diǎn): 1)實(shí)驗(yàn)結(jié)果和期望值之間的誤差在5的范圍內(nèi),我們都認(rèn)為是可接受的,即數(shù)據(jù)是正確的; 2)實(shí)驗(yàn)結(jié)果和期望值之間的誤差不是簡(jiǎn)單的0-1的結(jié)果,而是將計(jì)算結(jié)果和期望值之間的差值的相對(duì)值作為誤差的結(jié)果.即定義誤差計(jì)算公式為: 其中shope表示期望的分值,smax是可達(dá)到的分值的最大值即100,smin是可達(dá)到的分值的最小值即0. 在表3對(duì)比了幾種特征提取方法利用改進(jìn)BP網(wǎng)絡(luò)的實(shí)驗(yàn)結(jié)果以及運(yùn)算的耗時(shí),圖4顯示了聚類算法和改進(jìn)的BP算法對(duì)圖片LBP特征進(jìn)行分類的實(shí)驗(yàn)結(jié)果. 表3 使用不同特征提取算法的實(shí)驗(yàn)結(jié)果準(zhǔn)確率以及計(jì)算耗時(shí)(取平均值) 圖4 測(cè)試樣本的美貌度預(yù)測(cè)分值: (1)粗分類得到的美貌度預(yù)測(cè)結(jié)果; (2)細(xì)分類得到的美貌度預(yù)測(cè)結(jié)果 通過(guò)實(shí)驗(yàn)可以看出文中所提的方法在數(shù)據(jù)集處理時(shí)體現(xiàn)出很大的優(yōu)勢(shì),采用改進(jìn)的BP網(wǎng)絡(luò)以及人臉的LBP特征進(jìn)行的人臉美貌度的預(yù)測(cè),其效果也很顯著. 在這篇文章中,我們提出了一種預(yù)測(cè)人臉美貌度算法.根據(jù)人臉的兩兩比較的結(jié)果得到基于HodgeRank排序的人臉?lè)诸?對(duì)人臉圖片進(jìn)行基于聚類思想的粗分類和基于改進(jìn)的BP網(wǎng)絡(luò)的細(xì)分類,得到人臉圖片的分類值,將其作為預(yù)測(cè)的美貌度.通過(guò)觀察實(shí)驗(yàn)結(jié)果,表明我們的算法有效,可行.在未來(lái)的工作中我們首先著力于利用大規(guī)模人臉美麗樣本庫(kù)進(jìn)行研究,提高實(shí)驗(yàn)結(jié)果的普適性; 其次由于人臉的美貌度不僅取決于人臉的簡(jiǎn)單特征、相關(guān)的比例還和膚色,形狀等很多因素有關(guān),如何更加有效的融入其他相關(guān)的人臉美貌度的元素進(jìn)行美貌度預(yù)測(cè)是今后重點(diǎn)研究課題. 參考文獻(xiàn) 1 Zhao W,Chellappa R,Phillips PJ,et al.Face recognition: A literature survey.ACM Computing Surveys (CSUR),2003,35(4): 399–458. 2Tan X,Chen S,Zhou ZH,et al.Face recognition from a single image per person: A survey.Pattern Recognition,2006,39(9): 1725–1745. 3Fasel B,Luettin J.Automatic facial expression analysis: a survey.Pattern Recognition,2003,36(1): 259–275. 4Shan C,Gong S,McOwan PW.Facial expression recognition based on local binary patterns: A comprehensive study.Image and Vision Computing,2009,27(6):803–816. 5Moghaddam B,Yang MH.Learning gender with support faces.IEEE Trans.on Pattern Analysis and Machine Intelligence,2002,24(5): 707–711. 6 Guo G,Fu Y,Dyer CR,et al.Image–based human age estimation by manifold learning and locally adjusted robust regression.IEEE Trans.on Image Processing,2008,17(7): 1178–1188. 7Fu Y,Huang TS.Human age estimation with regression on discriminative aging manifold.IEEE Trans.on Multimedia,2008,10(4): 578–584. 8Likert R.A technique for the measurement of attitudes.Archives of Psychology,1932. 9Oliva A,Torralba A.Modeling the shape of the scene: A holistic representation of the spatial envelope.International Journal of Computer Vision,2001,42(3): 145–175. 10管業(yè)鵬,夏慧明,時(shí)勇杰.非監(jiān)督人臉美貌度評(píng)價(jià).電子器件,2012,35(2):244–248. 11Milutinovic J,Zelic K,Nedeljkovic N.Evaluation of facial beauty using anthropometric proportions.The Scientific World Journal,2014. 12Zhang D,Zhao Q,Chen F.Quantitative analysis of human facial beauty using geometric features.Pattern Recognition,2011,44(4): 940–950. 13Grammer K,Thornhill R.Human (Homo sapiens)facial attractiveness and sexual selection: The role of symmetry and averageness.Journal of Comparative Psychology,1994,108(3): 233. 14Gray D,Yu K,Xu W,et al.Predicting facial beauty without landmarks.Computer Vision-ECCV 2010.Springer Berlin Heidelberg,2010: 434–447. 15Yan H.Cost-sensitive ordinal regression for fully automatic facial beauty assessment.Neurocomputing,2014,129: 334 –342. 16Sizemore RK.HodgeRank: Applying Combinatorial Hodge Theory to Sports Ranking.2013. 17胡泱.一種改進(jìn)型BP算法.信息系統(tǒng)工程,2015,(6):111–115. Prediction of Facial Beauty Based on HodgeRank JIANG Ting,ZHU Ming Abstract:In recent years,with the rapid development of computer technology,perception of human facial beauty is an important aspect of human intelligence and has attracted more and more attention of researchers.For the current study methods that exist in the training data set of scoring most depends on manual processes,and the facial beauty assessment is not detailed enough to predict the results,this paper aims to investigate and develop intelligent systems for learning the concept of female facial beauty with data mining learning and producing human-like predictors.Our work is notably different from and goes beyond previous works.We impose less restrictions in terms of pose,lighting,background on the face images used for training and testing,which greatly reduces the manual operation for classification and we do not require costly manual annotation of landmark facial features but simply take raw pixels or texture feature as inputs.We show that a biologically-inspired model with clustering and the improved BP network method can produce results that are much more human-like approach. Key words:facial beauty prediction; HodgeRank sorting; clustering idea; improved BP network; facial feature 基金項(xiàng)目:①中科院先導(dǎo)課題(XDA06011203) 收稿時(shí)間:2015-07-28;收到修改稿時(shí)間:2015-09-24

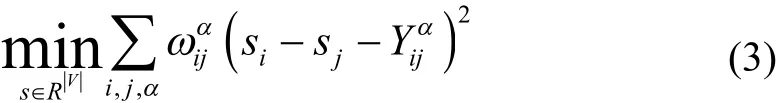
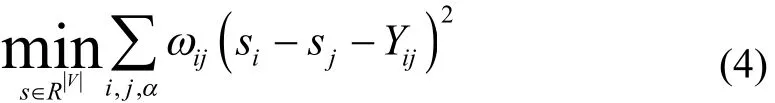


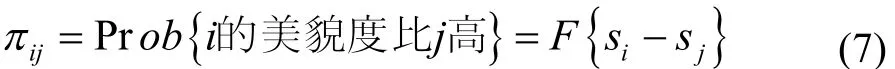




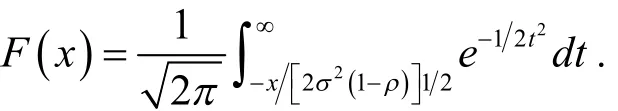



3 實(shí)驗(yàn)及結(jié)果分析






4 結(jié)語(yǔ)
(School of Information Science and Technology,University of Science and Technology of China,Hefei 230022,China)
