基于混合推薦和隱馬爾科夫模型的服務推薦方法
2016-06-24 07:13:47馬建威陳洪輝STEPHANReiffMarganiec國防科學技術大學信息系統工程重點實驗室湖南長沙4007第三軍醫大學衛勤教研室重慶40008萊斯特大學計算機科學與技術系英國萊斯特
中南大學學報(自然科學版) 2016年1期
馬建威,陳洪輝, STEPHAN Reiff-Marganiec(.國防科學技術大學 信息系統工程重點實驗室,湖南 長沙,4007;2.第三軍醫大學衛勤教研室,重慶,40008;.萊斯特大學 計算機科學與技術系,英國 萊斯特)
?
基于混合推薦和隱馬爾科夫模型的服務推薦方法
馬建威1,2,陳洪輝1, STEPHAN Reiff-Marganiec3
(1.國防科學技術大學 信息系統工程重點實驗室,湖南 長沙,410073;2.第三軍醫大學衛勤教研室,重慶,400038;3.萊斯特大學 計算機科學與技術系,英國 萊斯特)
摘要:針對現階段越來越多的服務開始部署于云環境,服務數量呈幾何級增長,必須獲取并推薦最優服務,而傳統的基于內容的過濾或協同過濾方法缺乏對新用戶和冗余服務的有效處理方法,提出一種在云環境下對最優服務進行有效推薦的方法。首先,分析2種協同過濾方法的優缺點,并提出改進的混合推薦算法;其次,針對常常被忽略的新用戶學習策略,提出新用戶偏好的確定方法;針對服務的動態變化情況,基于隱馬爾科夫模型(hidden Markov model)提出一種冗余服務消解策略。最后,基于真實數據集和通過公開API獲取的公共服務集進行實驗。研究結果表明:所提出的算法與其他方法相比具有更高的準確度和更好的服務質量,能更有效地提高系統性能。
關鍵詞:協同過濾;服務選擇;新用戶學習;隱馬爾科夫模型;冗余檢測
近年來,大量的分布式系統部署環境不斷向云環境遷移,越來越多的服務開始以云服務的形式展現,服務的用戶也呈現出幾何量級式快速增長,并且這種趨勢仍在加劇。然而,隨著大量云服務的出現,諸如服務提供者的虛假惡意行為、服務使用高峰時所出現的瓶頸以及云環境的動態性等都會造成信息質量發生動態變化,甚至對用戶變得不可知,當前擺在面向服務應用面前的最大挑戰已經轉變為如何最大化地利用服務資源,并且充分保證用戶的滿意度。對服務質量進行預測并推薦適當的服務成為解決問題的關鍵。推薦系統在解決以上問題方面正發揮著越來越重要的作用[1]。協同過濾方法(collaborative filtering)是推薦系統的一種信息推薦方法,在學習用戶偏好以及預測用戶興趣等方面得到廣泛應用,并且取得了非常好的應用效果。然而,傳統的協同過濾方法通常通過記錄用戶交易歷史的方法計算用戶之間的相似性,從而進行過濾推薦,卻無法有效地對新用戶進行推薦,這就出現所謂的“冷啟動”(cold start)問題。冷啟動問題在云環境條件下更加容易發生,原因在于每天都有數以百萬級的新用戶在開始使用互聯網尋找合適的服務資源。此外,由于拷貝與轉載操作簡單,因此,互聯網上經常會出現大量的冗余服務資源,而傳統的協同過濾方法無法有效區分冗余資源,這也使得用戶常常受限于大量冗余的資源列表,而無法從中找出合適的資源,進而極大地降低了用戶的使用滿意度。為此,本文作者提出一種基于混合推薦算法和隱馬爾科夫模型的信息推薦方法。首先提出一種混合協同過濾方法,利用隨機行走(random walk)策略進行云環境下的信息推薦;然后,基于受歡迎度和信息熵的方法提出新用戶興趣判定的方法;最后,基于隱馬爾科夫模型(hidden Markov model)提出服務冗余的判定方法,并進行實驗驗證。
1 問題描述
由于網絡服務數據急劇上升,海量的資源使得用戶無法去嘗試使用每一個服務,因此,對服務質量進行預測并推薦服務資源成為了一個急需解決的關鍵問題。近年來,人們對服務選擇和服務推薦的研究較多,如自適應資源管理[2]、 歷史信息分析[3]以及各種統計方法[4]已在服務選擇領域得到廣泛應用并取得了較好的研究成果。用戶一般服務矩陣見表1。
這里所提出的服務質量預測和推薦方法主要是基于對服務使用者與服務提供者和服務推薦者之間進行相似度計算的思想提出的。原因在于:在QoS信息相對穩定的前提下,服務的歷史數據統計能夠對服務的選擇和推薦產生巨大而有意義的影響。在當前研究中,有很多關于用戶相似度計算的技術如基于內容的過濾[5]和協同過濾[6?8]。但對云環境下的超大規模用戶數量而言,基于內容的過濾方法將面臨巨大的計算復雜度問題,無法有效地建立用戶配置文件,因此,基于協同過濾的思想是該種情況下服務推薦的有效手段。協同過濾主要有2類:基于用戶的協同過濾(user-basedCollaborative filtering)和基于項目的協同過濾(item-basedCollaborative filtering)。

表1 用戶?服務矩陣Table1 User?service matrix
1)基于用戶的協同過濾(user-basedCollaborative filtering)的基本思想是計算用戶與用戶之間的相似度Sim(a,u),典型的方法包括最近 K 鄰居算法(K-nearest neighbor algorithm)以及皮爾森相關系數算法(PearsonCorrelationCoefficient algorithm)[9]。
2)基于項目的協同過濾(item-basedCollaborative filtering)與基于用戶的方法不同,其主要集中于服務集,通過計算服務之間的相似度來完成預測和推薦。由于服務之間的關系相對來說較固定,因此,該方法可以進行預計算(pre-computing),從而可以有效地緩解大規模數據條件下的計算復雜度問題[11],但仍缺乏滿足新用戶需求的有效手段。任意2個服務i與服務j之間的相似度(Sim(i,j))可以通過下式進行計算:
2 基于受歡迎度和互信息熵理論的信息推薦方法
2.1混合協同過濾方法(hybridCollaborative filtering method)
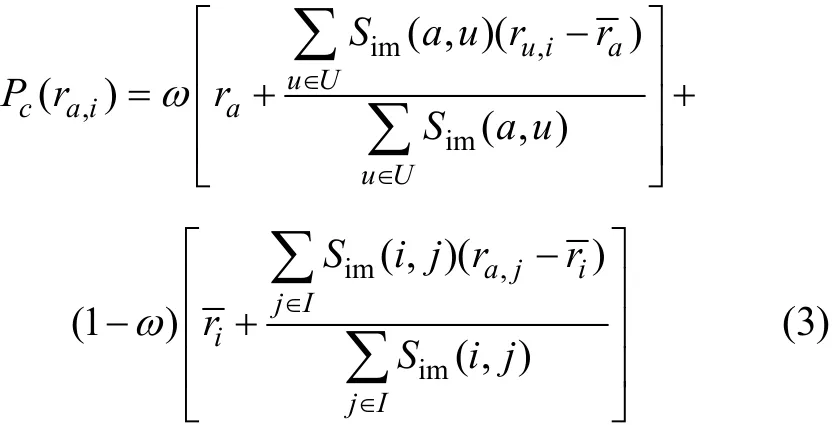
其中:ω為可信(confidence)權重,ω∈ [0,1],通常在數據規模較小時設置為較大值,當數據規模很大時設置為較小值,主要用于調節這 2種方法在混合推薦中所占的權重,從而充分發揮這 2種推薦方法各自的優勢。
Algorithm1: Greedy search for Top-N services
Input: Service set R
Output: Top-N similarity services set X
1.for j→1to m
2.for i→1to m.
3.Calculate Sim(i,j)
4.x←Sim(i,j)
5.if x≠among the top-n largest values
6.x←0
7.else
8.add x to X
9.end if
10.end for
11.end for
12.Return X
在通常情況下,使用Top-N推薦算法確定與目標用戶最相似的N個用戶,并將這N個用戶的相關服務推薦給目標用戶。算法1給出了Top-N算法的貪婪搜索思想,當數據規模較小時,該種算法具有較好性能。
但在云環境下當服務規模及數量巨大時,上述方法的計算復雜度較大。因此,在這種情況下首先使用概率的潛在語義索引PLSI(probabilistic latent semantic indexing)對用戶進行社團劃分,而后使用最小優先獨立排列哈希MinHash(minwise independent permutation hashing)[10]建立用戶索引,從而保證可擴展性的需要,見圖1。然后,使用隨機行走策略(算法2)在社團中隨機行走,從而避免遍歷所有的服務集,大大降低計算復雜度,見圖2。
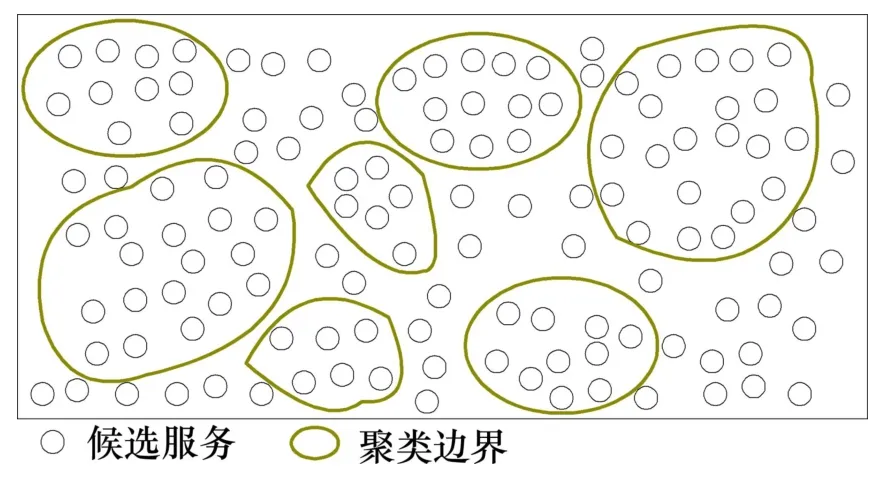
圖1 聚類分析Fig.1 ClusterClassification
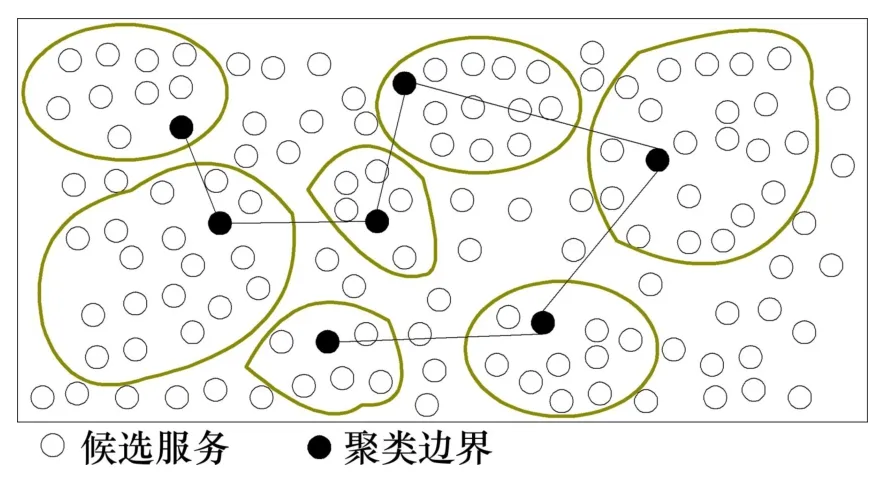
圖2類間的隨機行走策略Fig.2Random walk strategy inClusters
2.2新用戶推薦策略
對于新用戶,推薦系統中并不具備任何關于目標用戶的信息,因此,傳統的協同過濾算法無法有效地為新用戶進行服務推薦,即出現“冷啟動”(cold start)問題。為了有效地解決此類問題,推薦系統必須設法獲得用戶的一些信息,最有效的辦法就是直接向用戶提問題,并提供服務給用戶進行評價[12]。但在現實生活中應用這種方法存在著較大局限性:若向用戶提出太多的問題,則會極大地降低系統的可用性,導致用戶難以忍受復雜的使用流程;而若缺乏足夠的問題,則又無法有效地獲得用戶信息。
Algorithm 2: Service set selection algorithm
Input: Available services in theCloud,services number limit N
Output: Service set R
1.R={ }
2.Pick a random service with required functionality on theCloud,add it to R
3.While(n≤N)
4.Pick a random service on theCloud similar to selected service
5.n++
6.add it to R
7.Return R
基于歡迎度進行推薦的方法是一種對新用戶推薦較有效的方法,但該方法存在的主要問題是:若僅僅基于該策略進行信息推薦,則將使得推薦系統無法實現個性化推薦,因為最受歡迎的信息往往也會受到大家的歡迎,而這根本無法體現出個性之間的差異;另外,基于信息熵的推薦方法能夠從每次評價值中獲取大量的信息,從而能夠對新用戶推薦起到積極作用[13],但在海量數據規模下,被評價的信息數量所占的比例很低,常常出現數據稀疏性問題(sparsity problem),單獨使用基于信息熵的方法將導致沒有信息熵可以利用,從而無法進行推薦。可根據以下步驟解決這些問題:
1)將服務集 R 中的所有備選服務按照受歡迎度的降序排列。
2)基于文獻[14]提出的關系劃分方法將用戶按照不同關系劃分成若干社區。
3)當有新的待推薦用戶時,判斷該用戶是否與現有用戶存在關系。若存在關系,則進行用戶相似度計算;若不存在關系,則從服務集R中隨機抽選不同受歡迎度的服務提供給用戶進行評價。
采用前面提出的混合推薦方法進行新用戶推薦。
2.3基于隱馬爾科夫模型的冗余信息消解策略
前面討論了靜態條件下的信息推薦。然而,在實際生活中,服務的QoS數據隨時可能因環境的變化而發生改變;此外,服務的提供商也很可能對其他服務提供商所提供的服務進行簡單復制、 粘貼就發布出來,這導致大量的冗余服務出現,而這些冗余服務的質量無法得到保障,且可能存在大量的惡意行為。用戶被大量的冗余信息所掩蓋,無法區分到底哪一個才是真正需要的服務,隱藏在迷霧之后的就是用戶對系統的極大不信任。為了解決這些問題,提出一種在動態環境下預測和獲取服務真實QoS值的方法。該方法主要從冗余檢測(redundancy detection)和 QoS 控制(QoSControl)進行研究。文獻[15]討論了QoS控制問題,為此,這里研究冗余檢測的解決方法。
解決問題的關鍵就是確定冗余信息源,并且找出能夠符合用戶需求的數據信息。為此,收集可能會影響服務未來狀態的信息,并周期性地更新服務信息以獲取最新數據。
將數據源劃分為兩類:原始數據源(original data)和冗余數據源(redundant data)。
定義1:原始數據源。原始數據源指能夠自由改變和自主更新的數據源,不受其他服務的影響。
定義 2:冗余數據源。冗余數據源指從原始數據源復制信息(全部或部分)的數據源,有2種情況:一是冗余數據源從原始數據源復制信息后,自主進行更新,變成新的原始數據源;另一種是從原始數據源復制信息后停止更新[16],或者只在原始數據源更新信息后的部分時段進行更新。
由于第1種情況的冗余數據源在復制原始數據后變成了1個新的原始數據源,對它的數據判別主要是基于可信度判別,傳統的推薦系統可以解決此問題;而第2種情況的冗余數據源在復制完成后依然是冗余數據,且隨時可能進行變化和修改,傳統的推薦系統無法有效確定其冗余屬性,該結果依然會出現在推薦列表中,為此,這里主要研究第2種情況的冗余數據源并解決相關問題。
在通常情況下,當2個服務之間存在很多共同的錯誤時可以斷定存在冗余數據源,而一般的解決方法是記錄服務的使用和更新信息,通過記錄服務更新的頻率來判斷冗余數據源。這種方法簡單易行,但當冗余數據源存在惡意攻擊意圖時,它可以隨機更新,純粹依靠記錄更新頻率無法有效鑒別冗余數據源,為 此,引入隱馬爾科夫模型(hidden Markov model)[17]來解決此類問題。隱馬爾科夫模型可以解決 3類基本問題:evaluation problems,decoding problems 和 learning problems。與馬爾科夫模型不同是,隱馬爾科夫模型中的狀態對于用戶是不可見的,且每種狀態可以隨機生成1種觀察值,為此,首先給出隱馬爾科夫模型。
定義 3:隱馬爾科夫模型(HMM)。1個隱馬爾科夫模型可以定義為1個三元組 M=(A,B,π)。其中:A=(aij)為轉移概率矩陣,定義為從一個狀態轉移到另一個狀態的概率;B=(bij)為觀察值概率矩陣,定義為任意給定狀態下觀察值的概率分布;π=(πi)為初始概率分布,定義為每個狀態作為初始狀態的概率分布。設 O=(O1,O2,L,On)為觀察值序列,而S=(S1,S2,L,Sn)為狀態序列。
本文中用于確定冗余服務的 HMM 模型實例如下。
隱藏狀態 S=(S1,S2)。
觀察值 O=(O1,O2)。
轉移概率 aij=P(si|sj),表示服務在t時刻從一種狀態si轉移到另一種狀態sj的概率。
觀察概率 bi=P(oj|si) ,表 示服務在狀態si觀察值發生變化的概率。
初始概率 πi=P(si)表示服務處在初始狀態 si的概率。
至此得到 HMM 模型求解所需的所有必備要素。在 HMM 模型的求解過程中,由于可以得到服務的若干觀察值,如 O=(O1,O2,L,On),這樣,實際 HMM的求解過程就可以轉化為 HMM 的經典問題 learning problem 的求解過程,能夠通過一系列方法求解出HMM 的所有參數 M=(A,B,π),并得出能夠最佳匹配觀察值序列的π。以下簡要介紹求解該問題的步驟(算法3),相關推導見文獻[17]。
第1步,定義前向變量 αt(i)為給定模型 M 時 t時刻以前的觀察值序列和在 t 時刻服務處在狀態 si的條件概率,如下式所示:
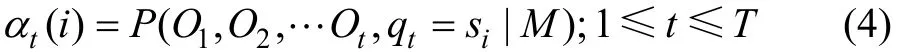
然后,通過使用歸納法求解 αt(i)。
1)在初始狀態下,
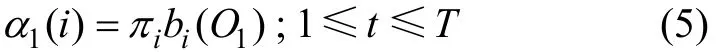
2)在歸納過程中,
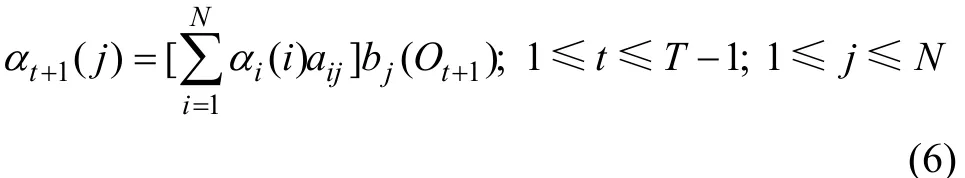
3)終止狀態為
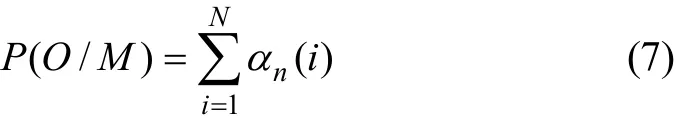
第2步,定義后向變量 βt(i)為給定模型 M 和 t時刻服務處在概率 si時從 t+1時刻到終止時刻的部分觀察值序列的條件概率:
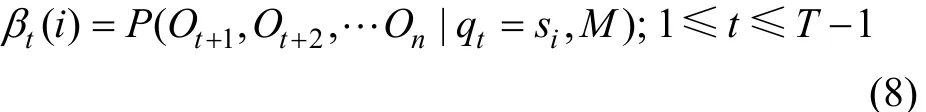
同樣,采用歸納法求解 βt(i)。
1)在初始狀態下,
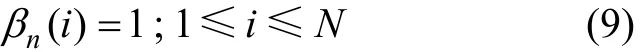
2)在歸納過程中,
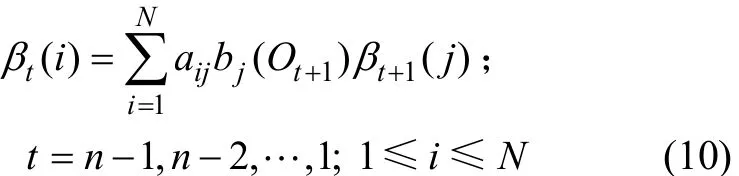
3)在終止狀態下,
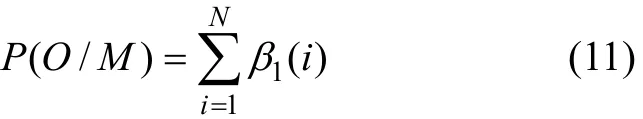
第3步,定義 θt(i,j)為給定觀察值序列和模型M時服務狀態從t時刻的 sj轉移為 t+1時刻的 sj的條件概率:
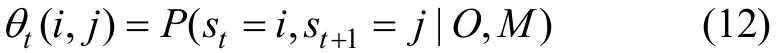
綜合利用式(5)~(12),可 以得到 θt(i,j)的表達式如下:
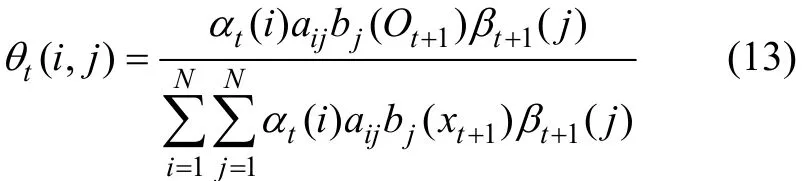
第4步,定 義 γt(i)為給定觀察值序列和模型M時服務在 t 時刻處在狀態 si的條件概率,則可以將 γt(i)與 θt(i,j)對應起來,如下式所示:
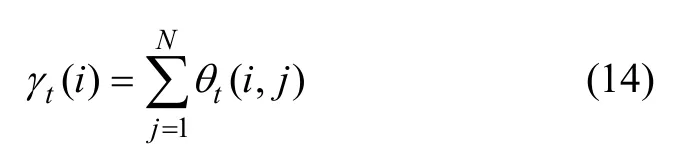
然后,依據式(15)~(17)獲得M的各個參數值:
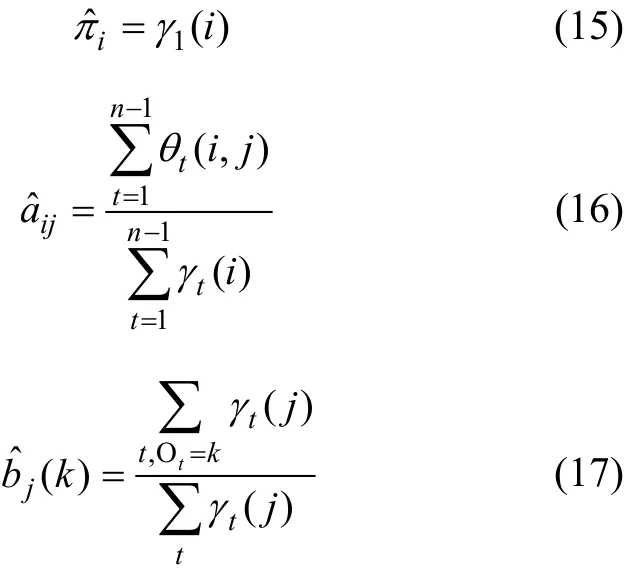
最后,利用 Baum-Welch 算法實現冗余服務的判斷。
Algorithm 3: RDM(redundancy detection method)
Input: Observable sequence O=(O1,O2,…,On)
Output: M=(A,B,π)
1.Sample the service set as theCandidate service St
2.Initial M0
3.Estimation
4.If lgP(O|M)?lgP(O|M0)<σ
5.M=M0
6.Else
7.M0=M
8.got step 4,re-estimation
9.End if
10.Output
圖3所示為本文所提算法的系統實現模型。圖 3主要表現了系統的各個組成構件、構件之間的關系以及各種輸入輸出數據等。首先用 PLSI 對候選服務進行聚類,而后采用混合推薦算法和基于 random walk策略的Top-N貪婪搜索方法獲取最符合需求的服務。為提高服務質量,還綜合考慮新用戶推薦、QoS 控制和冗余檢測等多項工作。
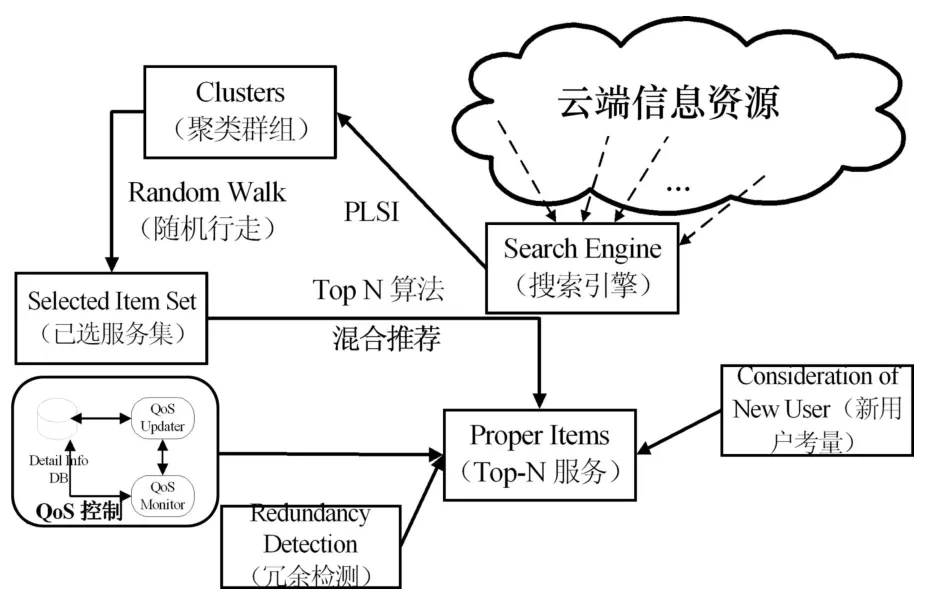
圖3 服務搜索的系統模型框架Fig.3 System model for services search
3 實驗及性能分析
3.1實驗設計
為驗證本文所提算法的性能,設計一組實驗,實驗采用 Matlab R2009a 進行編程,相關服務部署在Axis1.4.2上。實驗數據為MovieLens數據集[18]和通過公開 API 收集到的10 000 條 Web 服務數據。其中MovieLens數據集包含6 040個用戶和3 900部電影,以及每個用戶對電影進行1~5星的評分,該數據集被廣泛用于驗證推薦系統性能。而對于實驗使用的Web服務數據,只計算其中響應時間及可用性這2 項 QoS指標。并且在實驗過程中,采用文獻[19]中描述的方法對每個服務的QoS數據進行歸一化處理。
實驗的評價指標是在信息推薦領域廣泛使用的指標EMA,其表達式如下:
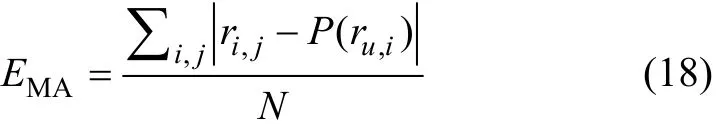
其中:ri, j為服務的實際 QoS 值;P(ru, i)為預測值。EMA越小,表示預測精度越高。
3.2實驗結果及分析
實驗的對比方法包括基于用戶的協同過濾方法(user-basedCF)、平均預測方法(average prediction)、貪婪搜索算法(greedy)和隨機預測方法(random)等。用這些方法進行準確率對比分析實驗、新用戶影響分析實驗、冗余消減策略應用分析實驗和延遲分析實驗。
3.2.1準確率對比分析
主要基于MovieLens數據集進行實驗,以用戶鄰居數為橫坐標,以EMA為縱坐標驗證算法性能。實驗結果如圖4所示。
從圖4可見:1)當服務數量增加時,可供評價的服務數量也增加,而這將同時提供混合推薦算法和基于用戶方法的推薦準確性,但對平均預測方法不造成影響;2)混合推薦算法很好地平衡了基于用戶的協同過濾方法和基于項目的協同過濾方法的優缺點,因此,對于性能的改善有積極作用。
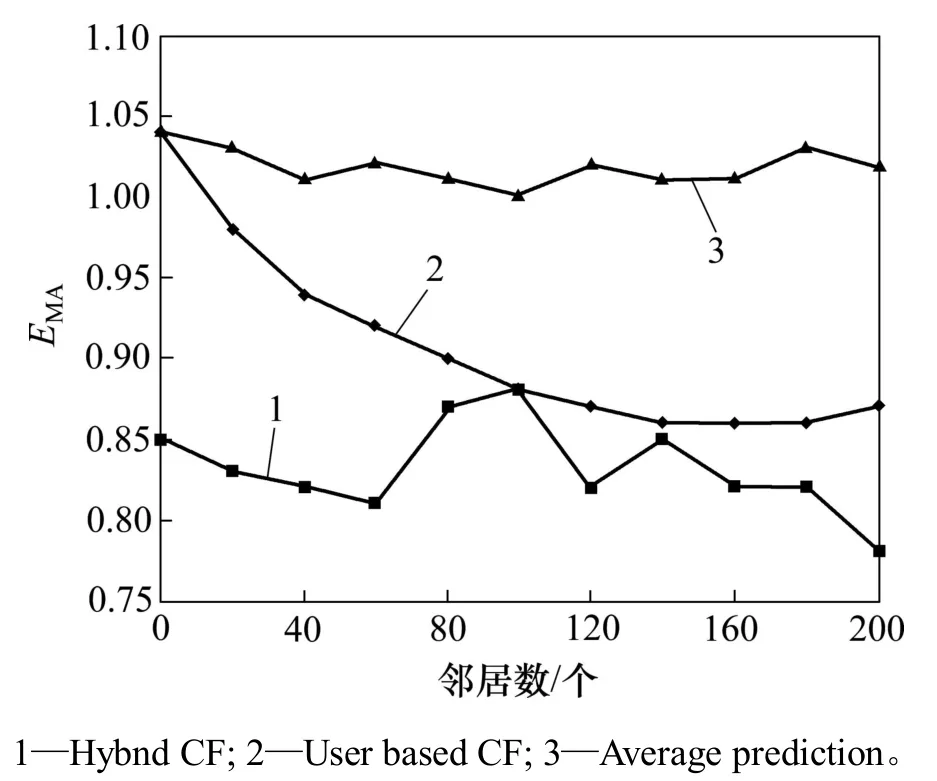
圖4不同方法的準確率對比分析Fig.4AccuracyComparison of different methods
3.2.2新用戶影響分析
該實驗建立在公共服務數據集上,結果如圖 5所示。實驗結果表明:考慮了新用戶偏好的混合推薦算法性能明顯優于未考慮新用戶偏好的算法性能。而由于新用戶沒有歷史信息,因此,基于熵的方法無法提供有效的推薦。
3.2.3冗余消減策略應用分析
在該實驗中,使用 HMM 模型檢測冗余服務。實驗結果見圖 6。從圖6可見:使用了冗余檢測方法的算法性能明顯優于未使用冗余檢測方法的算法性能,而當冗余服務比例較大時該算法的性能優勢更加突出。
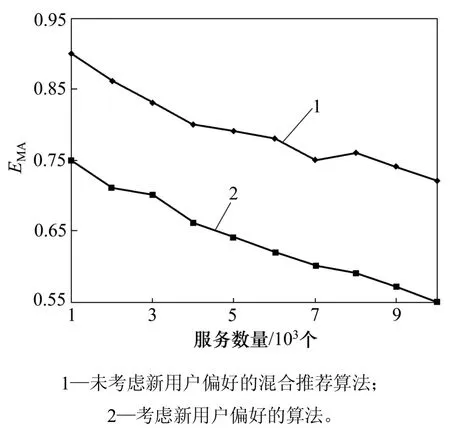
圖5 新用戶影響分析Fig.5 Impact of new user
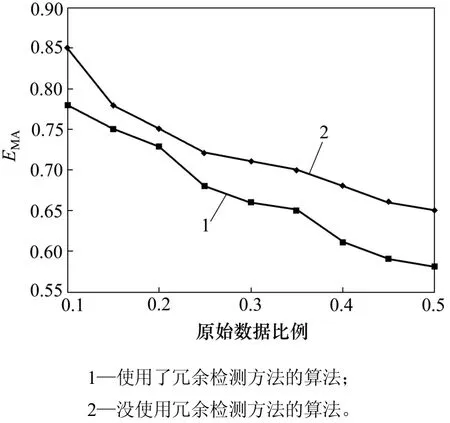
圖6 冗余消解策略應用分析Fig.6 Impact of redundancy detection
3.2.4延遲分析
進一步地進行延遲分析(圖 7)以及平均 QoS 值比較,結果分別見圖7和圖 8。對比方法為貪婪搜索算法(greedy)、隨機預測方法(random)和冗余檢測算法(RDM)。由于服務數量增加,搜索最優服務的時間必然會延長,因此,貪婪搜索算法在延遲上呈指數級增加是用戶無法接受的,而 RDM 算法的延遲僅僅稍高于Random算法的延遲,平均QoS值卻得到極大提升,這表明 RDM 對于最優服務的選擇和推薦具有很重要的所用。而其原因在于 RDM 使用了有效的聚類方法和隨機行走策略。
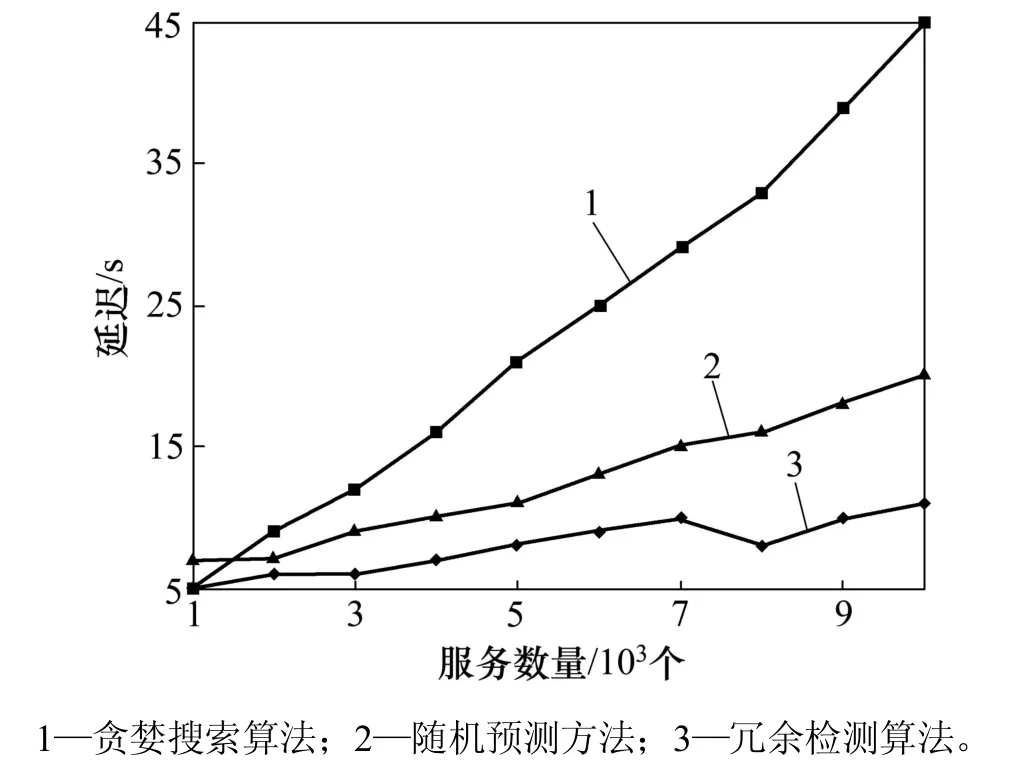
圖7 不同算法的延遲分析Fig.7 DelayComparison of different algorithms
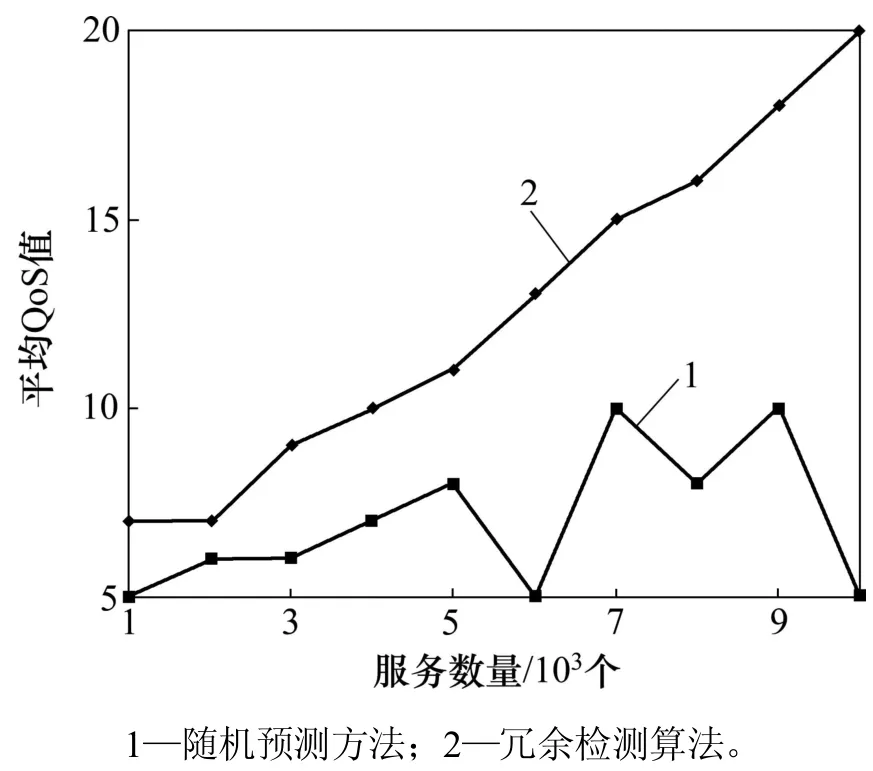
圖8 不同算法的平均QoS指標對比分析Fig.8 Average QoSComparison of different algorithms
4 相關工作
與本文工作相關的研究主要包括:基于QoS的服務選擇(QoS-based service selection)、協同過濾推薦(collaborative filtering based recommendation)、新用戶偏好識別(learning of new user needs)和冗余檢測(redundancy detection)。
近年來,基于QoS服務選擇的研究很多[2,4,5,20?21]。BALKE 等[20]綜合利用了服務使用模式和用戶需求偏好來擴大服務發現的范圍,并借此提高候選服務的質量;文獻[22]提出了一種基于預測的 QoS 管理算法,通過使用在線配置文件以及抽樣方法來評估動態服務數據的代價并借此調整服務QoS,以滿足不同需求。
協同過濾推薦已被廣泛用于發現相似用戶或相似產品[6-8,22]。主要的協同過濾方法包括基于用戶的協同過濾方法和基于項目的協同過濾方法,但這 2種方法各自存在無法克服的缺點。為此,文獻[23]提出了一種混合推薦算法以給出準確的推薦,但該方法對新用戶偏好欠考量;文獻[24]利用了貝葉斯網絡(Bayesian network inference)進行信息推薦;而文獻[25]利用社會信譽度模型來進行在線社會網絡中的信息推薦。
對于新用戶偏好的缺點,絕大多數的研究集中于信息的受歡迎度分析,但由于將最受歡迎的信息推薦給用戶無法有效地發現用戶的個性偏好,因此,這種方法并不可靠。為此,文獻[12]提出一種綜合利用信息熵(entropy)和受歡迎度的方法;而文獻[10]則利用“訪問了這件商品的用戶,又訪問了另一件商品”的模式(co-visitation)進行了新用戶的推薦。
目前人們對信息冗余檢測的研究很少,部分相關研究包括:文獻[1]提出了一種通過構建用戶相關度來過濾無關信息的方法,而文獻[14]則提出了一種用戶社會關系劃分的方法,并通過這種方法有效地發現用戶的興趣,以過濾無關信息。
5 結論
1)為有效發現云環境下的最優服務,提出了一系列信息推薦方法。首先對協同過濾方法進行分析,并基于歷史信息提出混合推薦方法;而后通過對新用戶特點進行分析,提出了新用戶的偏好獲取方法;由于冗余信息會對最優服務的選擇造成巨大影響,因此,基于隱馬爾科夫模型進一步提出冗余信息的消解方法。最后,依托真實數據集和通過公共API獲取的服務進行實驗,實驗結果表明上述算法在推薦的準確性和時效性等方面都取得了較大提升。
2)基于混合推薦的方法僅僅考慮了基于內存的協同過濾方法(memory-basedCollaborative filtering),還沒有考慮網絡的本身的結構拓撲,在下一步工作中,需綜合考慮網絡拓撲,并預測動態服務和推薦上以準確捕捉用戶偏好的動態變化。
參考文獻:
[1]LV Y H,MOON T,KOLARI P,et al.Learning to model relatedness for news recommendation[C]//Proceedings of the 20th InternationalConference on World Wide Web.Hyderabad,India: ACM,2011: 57?66.
[2]HUH E,WELCH L R,TJADEN B,et al.Accommodating QoS prediction in an adaptive resource management framework[C]//Parallel and Distributed Processing-15 IPDPS 2000 Workshops.Cancun,Mexico: IEEE,2000: 792?799.
[3]SMITH W,FOSTER I,TAYLOR V.Predicting application run times using historical information[J].Journal of Parallel and DistributedComputing,2004,64(9):1007?1016.
[4]BLAKE M B,NOWLAN M F.Predicting service mashupCandidates using enhanced syntactical message management[C]//2008 IEEE InternationalConference on ServicesComputing.Honolulu,USA: IEEE,2008: 229?236.
[5]MOONEY R J,ROY L.Content-based book recommendation using learning for textCategorization[C]//Proceedings of the ACM InternationalConference on Digital Libraries.Kyoto,Japan: ACM,2000:195?204.
[6]SHAO L S,ZHANG J,WEI Y,et al.Personalized QoS prediction for web services viaCollaborative filtering[C]//IEEE InternationalConference on Web Services.Salt LakeCity,USA: IEEE,2007:1?8.
[7]SU X Y,KHOSHGOFTAAR T M.A survey ofCollaborative filtering techniques[J].Advances in Artificial Intelligence Archive,2009.doi:10.1155/2009/421425.
[8]MA H,KING I,LYU M R.Effective missing data prediction forCollaborative filtering[C]//Proceedings of the 30th Annual International ACM SIGIRConference on Research and Development in Information Retrieval.Amsterdam,Netherland: ACM,2007: 39?46.
[9]RESNICK P,LAKOVOU N,SUSHAK M,et al.GroupLens: An open architecture forCollaborative filtering of net news[C]//InternationalConference onComputer SupportedCooperative Work.Chapel Hill,USA: ACM,1994:175?186.
[10]DAS A,DATAR M,GARG A.Google news personalization: scalable onlineCollaborative filtering[C]//Proceedings of the16th InternationalConference on World Wide Web.Banff,Canada: ACM,2007: 271?280.
[11]SARWAR B,KARYPIS G,KONSTAN J,et al.Item-basedCollaborativefilteringrecommendationalgorithms[C]//Proceedings of the10th InternationalConference on World Wide Web.Hong Kong: ACM,2001: 285?295.
[12]RASHID A M,ALBERT I,COSLEY D,et al.Getting to know you: Learning new user preference in recommender systems[C]//InternationalConference on Intelligent User Interfaces.San Francisco,USA: ACM,2002:127?134.
[13]KOHRS A,MERIALDO B.ImprovingCollaborative filtering for new users by smart object selection[C]//Proceedings of InternationalConference on Media Feature.Florence,Italy: IEEE,2001.
[14]TANG S J,YUAN J,MAO X F,et al.RelationshipClassificationin large scale online social networks and its impact on information propagation[C]//IEEE InternationalConference onComputerCommunications.Shanghai,China: IEEE,2011: 2291?2299.
[15]CHEN H H,MA J W,HUANGFU X P,et al.Process reservation for service oriented application[C]//6th WorldCongress on Services.Miami,USA: IEEE,2010:162?163.
[16]DONG X L,BERTI-ENQULLE L,SRIVASTAVA D.Truth discovery andCopying detection in a dynamic world[J].Proceedings of the Vldb Endowment,2009,2: 562?573.
[17]RABINAR L R.A tutorial on hidden markov models and selected applications in speech recognition[J].Proceedings of the IEEE,1989,77(2): 257?286.
[18]Grouplens Research.MovieLens data sets[EB/OL].2010.http://grouplens.org/datasets/movielens/
[19]LIU Y T,NGU A,ZENG L Z.QoSComputation and policing in dynamic web service selection[C]//Proceedings of the13th InternationalConference on World Wide Web.New York,USA: ACM,2004: 66?73.
[20]BALKE W,MATTHIAS W.Towards personalized selection of web services[C]//Proceedings of the12th InternationalConference on World Wide Web.Budapest,Hungary: ACM,2003: 20-24.
[21]LI M,HUAI J P,GUO H P.An adaptive web services selection method based on the QoS prediction mechanism[C]//IEEE/WIC/ACM InternationalConference on Web Intelligence and Intelligent Agent Technology Workshops.Milan,Italy: IEEE,2009: 395?402.
[22]WEI Y,PRASAD V,SANG H,et al.Prediction-based QoS management for real-time data streams[C]//Proceedings of the 27th IEEE International Real-Time Systems Symposium.Rio de Janeiro,Brazil: IEEE,2006: 344?355.
[23]ZHENG Z B,MA H,LYU M R,et al.WSRec: ACollaborative filtering based web service recommender system[C]//2009 IEEE InternationalConference on Web Services.Los Angeles,USA: IEEE,2009: 437?444.
[24]YANG X W,GUO Y,LIU Y.Bayesian-inference based recommendation in online social networks[C]//IEEE InternationalConference onComputerCommunications.Shanghai,China: IEEE,2011: 551?555.
[25]CHEN RC,LUA E K,CAI Z H.Bring order to online social networks[C]//IEEE InternationalConference onComputerCommunications.Shanghai,China: IEEE,2011: 541?545.
(編輯 陳燦華)
Recommending services via hybrid recommendation algorithms and hidden Markov model inCloud
MA Jianwei1,2,CHEN Honghui1,STEPHAN Reiff-Marganiec3
(1.Science and Technology of Information System Engineering Laboratory,National University of Defense Technology,Changsha 410073,China? 2.Department of Health Service,Third Military Medical University,Chongqing 400038,China? 3.Department ofComputer Science,University of Leicester,Leicester,UK)
Abstract:With the increase of the number of users using web services for online activities through thousands of services,proper services must be obtained? however,the existing methods such asContent-based approaches orCollaborative filtering do notConsider new users and redundant services.An effective approach was proposed to recommend the most appropriate services in aCloudComputing environment.Firstly,a hybridCollaborative filtering method was proposed to recommend services.The method greatly enhances the prediction of theCurrent QoS value which may differ from that of the service publication phase.Secondly,a strategy was proposed to obtain the preferences of the new users who are neglected in other research.Thirdly,a HMM(hidden Markov model)-based approach was proposed to identify redundant services in a dynamic situation.Finally,several experiments were set up based on real data set and publicly published web services data set.The results show that the proposed algorithm has better performance than other methods.
Key words:Collaborative filtering?service selection?new user learning?hidden Markov model?redundancy detection
中圖分類號:TP393
文獻標志碼:A
文章編號:1672?7207(2016)01?0082?09
DOI:10.11817/j.issn.1672-7207.2016.01.013
收稿日期:2015?01?22;修回日期:2015?03?25
基金項目(Foundation item):國家自然科學基金資助項目(71071160);全軍后勤科研重點計劃項目(BWS14J032);湖南省優秀研究生創新項目(CX2011B024);國防科技大學優秀研究生創新項目(B110502);第三軍醫大學人文社科基金資助項目(2015XRW10)(Projects(61070216,71071160)supported by the National Natural Science Foundation ofChina? Project(BWS14J032)supported by the Logistics Research Plan ofChinese PLA? Project(CX2011B024)supported by the Outstanding Graduate Student Innovation Fund of Hunan Province? Project(B110502)supported by the Outstanding Graduate Student Innovation Fund of National University of Defense Technology? Project(2015XRW10)supported by Social Science Foundation of Third Military Medical University)
通信作者:馬建威,博士,講師,從事社會網絡分析、服務計算技術及衛勤信息化技術研究;E-mail: majianwei@nudt.edu.cn
