車輛通行數據的分布式存儲系統淺析
2016-08-04 21:58:34郭旭衛彪江建宇
科技傳播 2016年13期
關鍵詞:特征
郭旭+衛彪+江建宇
摘 要 卡口車輛通行數據的分布式存儲方法,包括配置計算節點和數據節點服務器,搭建并行計算集群環境;按照需要采集的車輛特征建立表結構,在表結構中選取至少兩個特征作為主鍵,由主鍵組成一條卡口數據信息;對主鍵和常用查詢字段建立分布式可變索引,再針對車牌號建立分布式檢索索引;接入待存儲的各個卡口的過車信息數據源;用戶以包含索引的字段進行查詢,系統在100m/s之內返回相應數據。滿足日常業務中卡口系統對海量過車信息數據存儲的需求,而且通過對過車信息的數據結構的索引數據結構設計實現了快速查詢的功能,大大提高了查詢速率,增強了用戶體驗。
關鍵詞 分布式存儲;Hadoop分布式計算框架;海量過車信息
中圖分類號 TP31 文獻標識碼 A 文章編號 1674-6708(2016)166-0074-01
1 系統架構和實現步驟
1.1 系統架構圖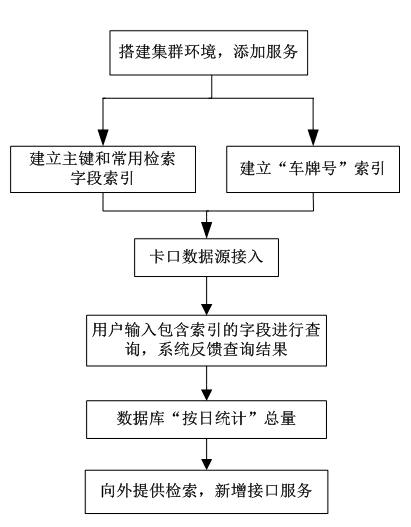
1.2 系統實現步驟
1)配置計算節點和數據節點服務器,搭建并行計算集群環境,安裝與集群環境版本匹配的數據訪問中間件。
2)按照需要采集的車輛特征建立表結構,在表結構中選取至少2個特征作為主鍵,由主鍵組成一條卡口數據信息。
3)對主鍵和常用查詢字段建立分布式可變索引,再針對車牌號建立分布式檢索索引。
4)接入待存儲的各個卡口的過車信息數據源。
2 系統實現功能綜述
2.1 過車數量統計
卡口車輛通行數據的分布式存儲方法,其特征在于:設定定時任務,自動統計前一天各個卡口的過車數據總量。
2.2 過車信息格式
卡口車輛通行數據的分布式存儲方法,其特征在于:將車牌號、通過時間、卡口編號這3個特征作為主鍵,由車牌號、通過時間和卡口編號共同組成一條能被用戶查詢到的卡口數據信息,卡口數據信息格式為:車牌號+通過時間取反+卡口編號。
2.3 模糊查詢
卡口車輛通行數據的分布式存儲方法,其特征在于:用戶輸入一個車牌號的其中任意一段連續字符,便可通過分布式索引文件的查詢返回相似度最高的前20個車牌號;返回車牌號之后,系統再根據相似度最高的車牌號列表進行全字段的匹配查詢;車牌號的分布式索引存儲在大數據集群中的分布式文件系統中。
3 具體實施方式
3.1 配置計算節點和數據節點服務器
首先,配置計算節點和數據節點服務器,搭建并行計算集群環境,安裝與集群環境版本匹配的數據訪問中間件,Apache Phoenix數據訪問中間件把傳統數據庫的SQL語句編譯成HBase存儲所需要的操作語句,加快了開發效率,降低了開發難度;其次,按照需要采集的車輛特征建立表結構,在表結構中選取至少兩個特征作為主鍵,由主鍵組成一條卡口數據信息。
3.2 表結構建立
如圖1所示,按照業務需求采集的車輛特征建立表結構,采集到字段有“車牌號”“通信時間”“卡口編號”,“車輛顏色”“車輛大小”“通行方向”“數據來源”等存儲字段;根據具體業務需求,整理需要持久化的所有數據信息字段,同時選取能夠唯一標志一條記錄的字段作為主鍵,這里將車牌號、通過時間、卡口編號這3個特征作為主鍵,由車牌號、通過時間和卡口編號共同組成一條能被用戶查詢到的卡口數據信息。
3.3 大數據集群配置
大數據集群運行在Linux內核的服務器,計算節點、備份計算節點和數據節點使用Hadoop分布式計算框架,采用HDFS的分布式文件系統,利用MapReduce算法實現“分而治之”的計算模型,所有數據通過Phoenix中間件存儲在HBase數據庫內,整個Hadoop框架內的計算轉發、監控和策略決定都由ZooKeeper管理。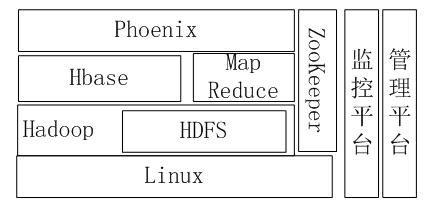
參考文獻
[1]Tom Wbite.hadoop權威指南第三版[M].北京:人民教育出版社,2014(7).
[2]涂子沛.大數據應用實例[M].桂林:廣西師范大學出版社,2015(6).
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
