一種基于深度學習的異構多模態目標識別方法
2016-09-12 01:54:22文孟飛胡超劉偉榮
中南大學學報(自然科學版) 2016年5期
文孟飛,胡超,劉偉榮
(1. 中南大學 信息科學與工程學院,湖南 長沙,410083;2. 湖南省教育科學研究院,湖南 長沙,410005;3. 中南大學 信息與網絡中心,湖南 長沙,410083;4. 中南大學 醫學信息研究湖南省普通高等學校重點實驗室,湖南 長沙,410083)
一種基于深度學習的異構多模態目標識別方法
文孟飛1,2,胡超3,4,劉偉榮1
(1. 中南大學 信息科學與工程學院,湖南 長沙,410083;2. 湖南省教育科學研究院,湖南 長沙,410005;3. 中南大學 信息與網絡中心,湖南 長沙,410083;4. 中南大學 醫學信息研究湖南省普通高等學校重點實驗室,湖南 長沙,410083)
提出一種基于深度學習的異構多模態目標識別方法。首先針對媒體流中同時存在音頻和視頻信息的特征,建立一種異構多模態深度學習結構;結合卷積神經網絡和限制波爾茲曼機的算法優點,對音頻信息和視頻信息分別并行處理,生成基于典型關聯分析的共享特征表示,并進一步利用時間相關特性進行參數的優化。分別使用標準語音人臉庫和截取的實際電影視頻對算法進行實驗。研究結果表明:對于這2種視頻來源,所提出方法在目標識別的精度方面都有顯著提高。
目標識別;深度學習;卷積神經網絡;限制玻爾茲曼機;典型關聯分析
網絡技術的發展使互聯網上各種非結構化的海量媒體數據流業務迅速增長[1]。如何建立起一種高效、準確的媒體數據流目標識別方法已成為國內外學者的研究熱點[2]。現今互聯網上 85%以上的數據業務包含了非結構化的圖像、音頻和視頻等媒體數據[3]。迫切需要根據媒體數據流的特性和規律,進行有效的特征提取和目標識別[4]。機器學習是目標識別的主要方法,目前已經從淺層學習[5-9]發展到深度學習。淺層結構需要依靠人工來抽取樣本的特征,難以將其擴展到視頻的特征提取[10]且自糾錯能力比較有限[11]。而HINTON等[12]提出的深層學習結構,可表征復雜高維函數并提取多重水平的特征[13]。深度學習的2種典型結構為限制波爾茲曼機(restricted boltzmann machines,RBM)和卷積神經網絡(convolutional neural network,CNN)。RBM在語音識別體現了較好優勢[14]。而LECUN等[15]使用 CNN在處理識別圖像信息取得了比其他學習方法更好的結果。目前,隨著互聯網的發展以及視頻編解碼技術的成熟,視頻數據呈現出爆炸式的增長[16]。目前已經有將深度學習方法應用到視頻數據目標識別的若干研究成果[17-19]。但上述的研究成果往往針對視頻的視覺信號進行單一模態的處理。而對于一段視頻來說,視覺和聽覺信號都能夠為目標識別提供重要的信息。因此,出現了結合各種不同的模態之間的有效信息的多模態學習方法。如LEONARDI等[20]使用底層的視覺和音頻特征來檢測足球視頻中的進球鏡頭。NGIAM 等[21]使用多模態方法并行處理人物口型和所發出的音節。目前這2種多模態學習方法都采用同一中深層結構處理音頻和視頻信號。但在多模態方法中使用不同深層結構將會取得更好的效果。如RBM對聲音的識別具有較好的識別效果。而卷積神經網絡對時間相關的動態視覺信號有較強的魯棒性[22]。為此,本文作者提出一種基于深度學習的異構多模態目標識別方法,綜合RBM的語音識別能力和卷積神經網絡的圖像處理能力,并建立RBM和卷積神經網絡的共享關聯表示,以便更有效地識別視頻中的目標。在對視覺信號進行處理時,進一步利用視頻中相鄰兩幀的時間相關性,優化神經網絡多層結構的參數,提高目標識別的準確度。
1 異構多模態深度學習的目標識別方法
多媒體數據中目標識別的關鍵是能夠獲取數據的主要特征。網絡資源中的多媒體視頻數據具有較大的復雜性與多樣性。僅僅利用視頻數據中單一模態進行處理往往難以得到較好的效果。使用多模態結合的方法提取數據特征能夠更有效應用于媒體數據流的特征提取:將視覺圖像和音頻數據分別作為2種模態輸入,并行進行處理,同時得到2種模態的高層特征,進而通過最大化2種模態之間的關聯性建立模態間的共享表示。可得到更好的識別效果。
由于視頻信息中視覺信息和聽覺信息的特點不同,本文建立了多模態的異構深度學習神經網絡,分別利用RBM和卷積神經網絡CNN處理視頻數據流的音頻信號和視頻圖像信號。
1.1 基于RBM的深度學習模型
RBM是一種特殊形式的玻爾茲曼機,可通過輸入數據集學習概率分布的隨機生成神經網絡,具有較好的泛化能力。而由多個RBM結構堆疊而成的深度信念網絡能提取出多層抽象的特征,從而用于分類和目標識別。
本文采用RBM模型進行音頻處理,RBM的結構如圖1所示,整體是一個二分圖的結構,分為2層:一層為可見層(visible units),也稱為輸入層;另一層為隱層(hidden units)。
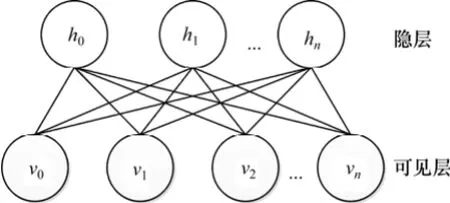
圖1 RBM的結構圖Fig.1 Structure of RBM
RBM的隱藏變量h和可見變量v之間存在對稱性的連接(Wi,j),但是隱藏變量之間或者可見變量之間沒有連接。該模型通過模擬熱力學能量定義了基于h和v的聯合概率分布(方程(1))。由于同層變量之間沒有連接,因此根據聯合概率分布可方便計算出每一個單元的激發概率。

根據方程(1),可定義隱層和可見層的概率分布:

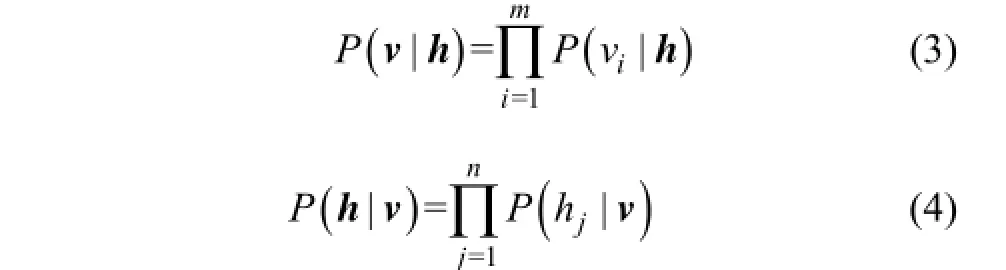
每一個單元的激發概率為:
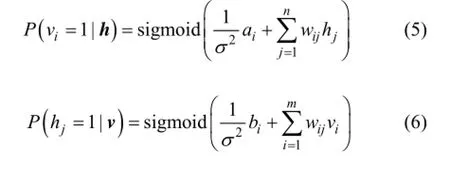
1.2 基于CNN的深度學習模型
CNN是多層感知機(MLP)的一個變種模型,是近幾年來快速發展并引起廣泛重視的一種高效識別方法。它是從生物學概念中演化而來的。20世紀60年代,HUBEL等[23]在研究貓腦皮層中用于局部敏感和方向選擇的神經元時發現其獨特的網絡結構可以有效地降低反饋神經網絡的復雜性,繼而提出了CNN。
一般來說,CNN的基本結構包括2層:一層為特征提取層,每個神經元的輸入與前一層的局部接受域相連,并提取該局部的特征。一旦該局部特征被提取后,它與其他特征間的位置關系也隨之確定下來;另一層為特征映射層,網絡的每個計算層由多個特征映射組成,每個特征映射是一個平面,平面上所有神經元的權值相等。
特征映射結構采用的 sigmoid函數作為卷積網絡的激活函數,使得特征映射具有位移不變性。此外,由于一個映射面上的神經元共享權值,因而減少了網絡自由參數的個數。卷積神經網絡中的每一個卷積層都緊跟著一個用來求局部平均與二次提取的計算層,這種特有的兩次特征提取結構減小了特征分辨率。其具體結構圖如圖2所示。




1.3 基于深度編碼器和關聯分析的異構學習
首先將視頻模型描述為視聽雙模態,其中該模型的輸入是視頻幀和與視頻幀同步的連續聲譜。本文采用基于稀疏理論的深度自動編碼器異構多模態的深度學習方法。
深度自動編碼器是一種利用無監督逐層貪心預訓練和系統性參數優化的多層非線性網絡,能夠從無標簽數據中提取高維復雜輸入數據的分層特征,并得到原始數據的分布式特征表示的深度學習神經網絡結構,其由編碼器、解碼器和隱含層組成。
基于稀疏理論的深度自動編碼器[10]對原始自動編碼器的隱含層添加了約束條件并增加了隱含層數量,能提取高維數據變量的稀疏解釋性因子,保留原始輸入的非零特征,增加表示算法的魯棒性,增強數據的線性可分性,使物體邊界變得更加清晰。
該識別模型分為輸入層、共享表示層以及輸出層。
輸入層:為視頻資源的2個模態,即聲譜和視頻幀,其中聲譜采用RBM訓練,視頻幀采用CNN訓練。
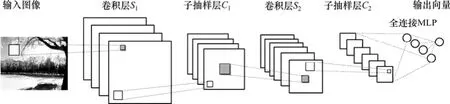
圖2 卷積神經網絡多層卷積運算和采樣過程圖Fig.2 Multilayer convolution operation and sampling process of convolution neural network
共享表示層:這一層的關鍵是找到特征模態的轉換表示從而最大化模態之間的關聯性。本文采用典型關聯分析(canonical correlation analysis, CCA,)的方法尋找聲譜波和視頻幀數據的線性轉換從而形成性能優良的共享表示。
CCA是先將較多變量轉化為少數幾個典型變量,再通過其間的典型相關系數來綜合描述兩組多元隨機變量之間關系的統計方法,有助于綜合地描述兩組變量之間的典型相關關系。基本過程是從兩組變量各自的線性函數中各抽取一個組成一對,它們應是相關系數達到最大值的一對,稱為第1對典型變量,類似地就可以求出第2對、第3對等,這些成對變量之間互不相關,各對典型變量的相關系數稱為典型相關系數。所得到的典型相關系數的數目不超過原兩組變量中任何一組變量的數目。
輸出層:這一層為聲譜和視頻的重構。還原視頻信息的同時,識別視頻中的物體。
2 基于視頻時間相關特性的參數優化
2.1 視頻相關性描述
視頻是由一系列圖像所組成,圖像中目標識別的方法可以用來對視頻進行識別,一段視頻可以分解成很多幀,同一視頻中連續的2個視頻幀很有可能表示同樣的內容,視頻的這種特性稱之為相關特性。將這視頻的這種特性用于視頻的目標識別,可以使識別效果得到很大程度的提高[22]。
利用視頻的時間相關性來提高識別準確性已成功用于視頻的動作識別[23]。實驗表明具有時間相關性視頻卷積網絡的識別效果明顯比采用視頻單幀進行訓練的卷積網絡效果優越。
2.2 利用視頻相關特性的優化
CNN中在每個卷積層和子采樣層之后都運用了一個非線性函數tanh(·),最后使用經典的全連接層輸出識別標簽向量,為了解釋這些向量的概率,引入“softmax”層,計算公式如下:
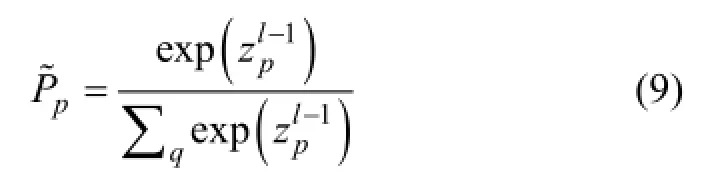
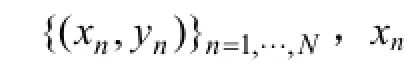

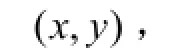
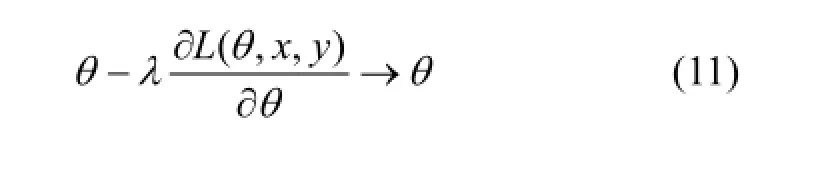
得到的新參數θ能使卷積神經網絡對視頻中目標識別的性能更準確。其中λ是根據實驗選擇的學習率。
為了使CNN更好地訓練θ,以達到更好的識別正確率,利用視頻中存在的時間相關性進一步對似然函數L(θ)進行優化。

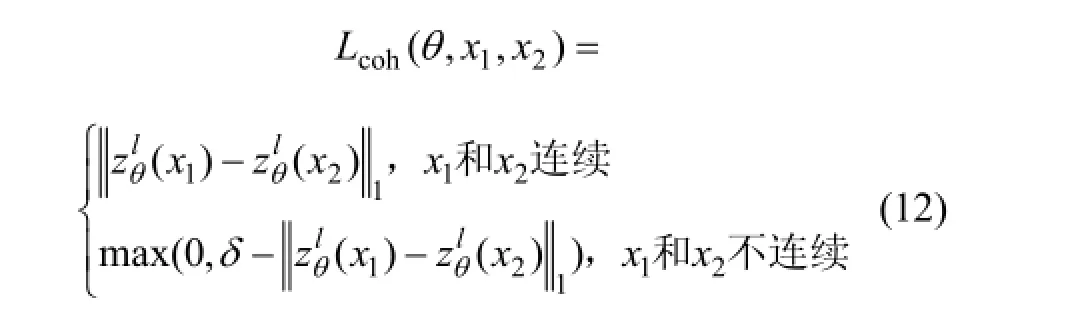
δ為邊緣尺寸,是一個提前選取好的超參數,例如δ=1。

圖3 利用相鄰幀的相關特性對深度學習參數進行優化Fig.3 Deep learning parameter optimization by using related characteristic of adjacent video frames


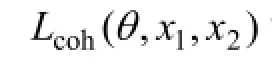
3 基于時間相關的異構多模態深度學習算法
基于時間相關性的異構多模態的結構如圖4所示,將視頻中的 2個模態視頻和音頻分別采用 CCN和RBM進行處理得到相應的識別標簽向量。
RBM 網絡的輸入為與視頻幀相對應的同步連續聲譜,采用深度自動編碼的學習模型對音頻進行處理,該學習模型仍然與1.3節中類似,分為輸入層、共享表示層以及輸出層。
RBM的目標是最大化訓練樣本集V中的概率之積:

CNN的優化目標則是最大化式(9)中的概率,則基于時間相關的異構多模態深度學習算法的目的就是對參數w, θ,優化RBM和CNN的聯合概率:

圖4 基于時間相關的異構多模態深度學習結構Fig.4 Heterogeneous multimodal structure of deep learning based on time correlation
利用時間相關性的優化算法如下:

Input:標簽數據(an, xn, yn), n=1, 2, …, N,非標簽視頻數據an, xn,n=N+1, …, N+U。Output: 神經網絡的參數w, θ和識別標簽label repeat:step1: 取1個隨機標簽樣本(an, xn, yn);step2: 針對音頻輸入an,執行1次梯度下降迭代優化RBM的連接參數w。step3: 對視頻輸入幀中連續的 xn, yn和似然函數L(θ, xn, yn),執行1次梯度下降迭代;step4: 對視頻輸入幀中不連續的 xn, xm和相關似然函數Lcoh(θ, xm, yn),執行1次梯度下降迭代;step5: 針對音頻輸入an,再執行1次梯度下降迭代優化RBM的連接參數w。選擇參數w, θ最大化式(15)中的聯合概率。until:迭代誤差小于設置的閾值。
上述算法就是通過交替更新目標識別任務的聲譜識別和視頻圖像幀識別的參數來實現優化,在視頻圖像幀中同時利用了連續幀和非連續幀的特征進行優化。以達到提高識別效率的目的。
4 實驗與分析
為了驗證本文提出的異構多模態深度學習的目標識別方法的性能,利用如下圖像和聲音數據庫作為測試視頻的聲音和圖像幀信息。
1) Stanford Dataset:是來自于斯坦福大學的1個網絡數據庫。選用其中的語音數據部分,使用庫中23名志愿者朗讀從 0~9的數字,從 A~Z的字母和從TIMIT標準語音庫里挑選的語句,以作為聲音訓練和測試數據。
2) Olivetti Faces:是紐約大學的1個人臉數據庫,由40個人的400張圖片構成,即每個人的人臉圖片為10張。每張圖片的灰度級為8位,每個像素的灰度位于0~255之間,每張圖片為64×64。使用圖片構造被測視頻的圖像幀。采用人工設定視頻中的人臉視頻與語音數據的對應關系。視頻幀中的1,4,5幀作為標簽數據,其余的圖像作為非標簽數據。
此外,為了驗證算法的有效性,將所提出異構多模態深度學習方法同已有的近鄰取樣、支持向量機和傳統的卷積神經網絡和玻爾茲曼機等目標識別方法進行比較。其中傳統的卷積神經網絡和波爾茲曼機即采用同構多模態的方式。將所用圖像和語音數據平均分成6組,分為訓練組L和測試組T,進行如下操作:1) L=1,T=5。2) L=2,T=4。3) L=5,T=1。實驗將對這3種情況比較這些方法對被測對象的識別率。測試的識別結果如表1所示。
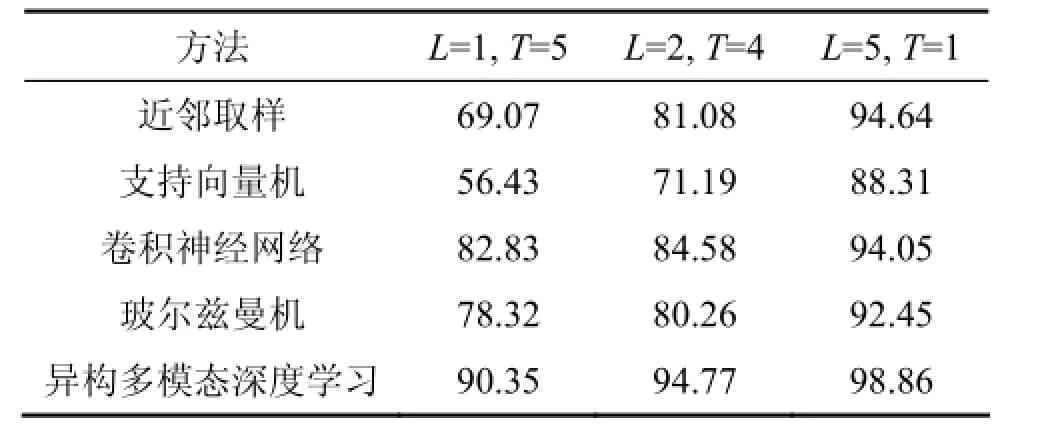
表1 基于Stanford Dataset和Olivetti Faces數據庫測試的算法識別率結果比較Table 1 Comparison of algorithm tests results based on Stanford Dataset and Olivetti Faces database %
由表1可以看出:隨著訓練集的規模增大,所有目標識別方法的識別率都得到了顯著提高。與傳統的4種目標識別方法相比,由于本文提出的異構多模態深度學習方法能夠抽象地學習目標與時間相關的特性信息,能不依賴大量對象集進行目標識別訓練,所以異構多模態深度學習方法能始終獲得最高的識別率。在訓練組較小L=1,T=5時,異構多模態深度學習方法的測試精度是90.35%,在訓練組較多L=5,T=1時,識別率提升了8.51%,誤差率只有1.14%。
此外,利用以下3種具有復雜場景和多種表情動作的視頻數據集以驗證本算法的有效性:UCF sport actions, Hollywood2和YouTube action。這些數據集提取自實際場景,具有場景復雜,待識別目標具有移動性,目標捕捉困難,面對干擾較大等特性。在本次實驗中利用較多訓練組L=5,T=1來驗證算法的性能,其指標仍然是目標識別率。比較結果如表2和圖5所示。
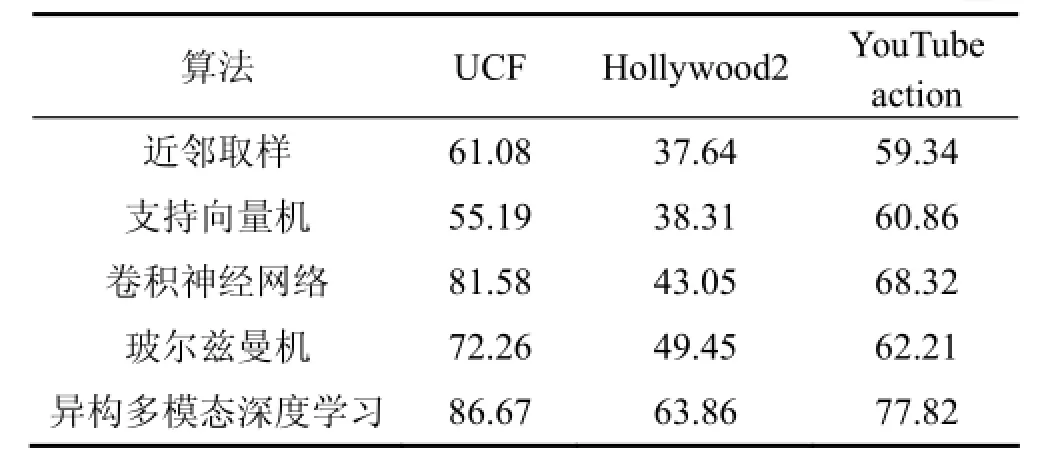
表2 基于UCF,Hollywood2和YouTube action視頻庫的算法識別率結果比較Table 2 Comparison of algorithm tests results based on video database coming from UCF, Hollywood2 and YouTube action %

圖5 標準視頻庫和電影視頻庫的結果對比Fig.5 Comparison of algorithm tests results between standard video database and movie fragment database
由表2和圖5可以看出:在更復雜的場景下,4種方法的目標識別都更加困難。特別是針對高度復雜的好萊塢電影場景,目標識別精度最高只有63.86%。由于4種數據集場景具有較大的干擾,所以具有濾波作用的玻爾茲曼機方法和異構多模態深度學習方法具有更高的識別精度。此外本文提出的異構多模態深度學習方法能夠抽象出目標與時間相關的特性信息,特別適用于移動場景目標的識別,能獲得最高的目標識別精度。
5 結論
1) 針對網絡媒體數據中同時包含音頻信號和時間相關的視頻圖像信號的特點,提出了一種異構的多模態深度學習機制,結合RBM和CNN,通過共享特征建立關聯。比單模態的處理更能獲得有效信息。
2) 在異構多模態的結構中進一步利用相鄰視頻幀之間的時間相關性提高識別率。通過引入了“softmax”層定義相鄰幀的極大似然函數,通過迭代的梯度下降法求解優化的深度學習參數。
3) 分別使用了標準語音人臉庫和截取的電影視頻對算法進行實驗,對比了不同數量訓練用例的分組。其中截取的電影視頻有更復雜的背景和表情動作。對于這2種視頻來源,所提出方法相對于所比較的方法在目標識別的精度方面都有顯著提高,顯示了本文算法的有效性與優越性。
[1] 王元卓, 靳小龍, 程學旗. 網絡大數據: 現狀與展望[J]. 計算機學報, 2013, 36(6): 1125-1138. WANG Yuanzhuo, JIN Xiaolong, CHENG Xueqi. Network big data: present and future[J]. Chinese Journal of Computers, 2013,36(6): 1125-1138.
[2] CHEN X W, LIN X. Big data deep learning: challenges and pers pectives[J]. Access, IEEE, 2014(2): 514-525.
[3] 李國杰. 大數據研究的科學價值[J]. 中國計算機學會通訊, 2012, 8(9): 8-15. LI Guojie. The scientific value in the study of the big data[J]. China Computer Federation, 2012, 8(9): 8-15.
[4] LOWE D G. Object recognition from local scale-invariant features[C]// Proceedings of the Seventh IEEE International Conference on Computer Vision. Kerkyra, Greece: IEEE, 1999:1150-1157.
[5] DENG L, YU D. Deep learning: methods and applications[J]. Foundations and Trends in Signal Processing, 2014, 7(3/4):197-387.
[6] ZIVKOVIC Z. Improved adaptive Gaussian mixture model for background subtraction[C]// Proceedings of the 17th International Conference on Pattern Recognition. Cambridge,UK: IEEE, 2004: 28-31.
[7] QUATTONI A, COLLINS M, DARRELL T. Conditional random fields for object recognition[C]// 18th Annual Conference on Neural Information Processing Systems. Vancouver, British Columbia, Canada, 2004: 1097-1104.
[8] SUYKENS J A K, VANDEWALLE J. Least squares support vector machine classifiers[J]. Neural Processing Letters, 1999,9(3): 293-300.
[9] MORGAN N, BOURLARD H. Continuous speech recognition using multilayer perceptrons with hidden Markov models[C]// International Conference on Acoustics, Speech, and Signal Processing. Albuquerque, New Mexico, USA: IEEE, 1990:413-416.
[10] LE Q V, ZOU W Y, YEUNG S Y, et al. Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis[C]// Computer Vision and Pattern Recognition (CVPR). Providence, Rhode Island, USA: IEEE,2011: 3361-3368.
[11] AREL I, ROSE D C, KARNOWSKI T P. Deep machine learning-a new frontier in artificial intelligence research[research frontier][J]. Computational Intelligence Magazine,IEEE, 2010, 5(4): 13-18.
[12] HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006,313(5786): 504-507.
[13] 劉建偉, 劉媛, 羅雄麟. 深度學習研究進展[J]. 計算機應用研究, 2014, 31(7): 1921-1930. LIU Jianwei, LIU Yuan, LUO Xionglin. The research and progress of deep learning[J]. Application Research of Computers,2014, 31(7): 1921-1930.
[14] HINTON G, DENG L, YU D, et al. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups[J]. Signal Processing Magazine, IEEE,2012, 29(6): 82-97.
[15] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[16] 程東陽. 基于無監督特征學習的多媒體內容算法研究[D]. 上海: 上海交通大學信息安全工程學院, 2014: 1-93. CHEND Dongyang. Multimedia content analysis based on unsupervised feature learning[D]. Shanghai: Shanghai Jiao Tong University. School of Information Security Engineering, 2014:1-93.
[17] 由清圳. 基于深度學習的視頻人臉識別[D]. 哈爾濱: 哈爾濱工業大學計算機科學與技術學院, 2012: 3-20. YOU Qingzhen. The radio face recognition method based on the deep learning[D]. Harbin: Harbin Institute of Technology. School of Computer Science and Technology, 2012: 3-20.
[18] WANG Y S, FU H, SORKINE O, et al. Motion-aware temporal c oherence for video resizing[J]. ACM Transactions on Graphics, 2009, 28(5): 89-97.
[19] ZOU W, ZHU S, YU K, et al. Deep learning of invariant features via simulated fixations in video[C]// 26th Annual Conference on Neural Information Processing Systems. Lake Tahoe, Nevada,USA, 2012: 3212-3220.
[20] LEONARDI R, MIGLIORATI P, PRANDINI M. Semantic indexing of soccer audio-visual sequences: a multimodal approach based on controlled Markov chains[J]. Transactions on Circuits and Systems for Video Technology, IEEE, 2004, 14(5):634-643.
[21] NGIAM J, KHOSLA A, KIM M, et al. Multimodal deep learning[C]// Proceedings of the 28th International Conference on Machine Learning (ICML-11). Bellevue, Washington, USA,2011: 689-696.
[22] MOBAHI H, COLLOBERT R, WESTON J. Deep learning from temporal coherence in video[C]// Proceedings of the 26th Annual International Conference on Machine Learning. Montreal,Quebec, Canada: ACM, 2009: 737-744.
[23] HUBEL D H, WIESEL T N. Receptive fields, binocular interaction and functional architecture in the cat's visual cortex[J]. Journal of Physiology, 1962, 160(1): 106-154.
[24] SIMONYAN K, ZISSERMAN A. Two-stream convolutional networks for action recognition in videos[C]// 28th Annual Conference on Neural Information Processing Systems. Montreal, Quebec, Canada, 2014: 568-576.
(編輯 楊幼平)
Heterogeneous multimodal object recognition method based on deep learning
WEN Mengfei1,2, HU Chao3,4, LIU Weirong1
(1. School of Information Science and Engineering, Central South University, Changsha 410075, China 2. Hunan Provincial Research Institute of Education, Changsha 410005, China;3. Information and Network Center, Central South University, Changsha 410083, China 4. Key Laboratory of Medical Information Research of Hunan Province, Central South University,Changsha 410083, China)
The heterogeneous multimodal object recognition method was proposed based on deep learning. Firstly, based on the video and audio co-existing feature of media data, a heterogeneous multimodal structure was constructed to incorporate the convolutional neural network(CNN) and the restricted boltzmann machine(RBM). The audio and video information were processed respectively, generating the share characteristic representation by using the canonical correlation analysis(CCA). Then the temporal coherence of video frame was utilized to improve the recognizing accuracy further. The experiments were implemented based on the standard audio & face library and the actual movie video fragments. The results show that for both the two kinds of video sources, the proposed method improves the accuracy of target recognition significantly.
object recognition; deep learning; restricted boltzmann machine; convolutional neural network; canonical co rrelation analysis
TP391.4
A
1672-7207(2016)05-1580-08
10.11817/j.issn.1672-7207.2016.05.018
2015-08-17;
2015-10-14
湖南省教育科學“十二五”規劃重點項目(XJK014AJC001);國家自然科學基金資助項目(61379111,61003233,61202342);教育部-中國移動科研基金資助項目(MCM20121031) (Project(XJK014AJC001) supported by the Hunan Provincial Education Science Key Foundation during 12th Five-Year Plan; Projects(61379111, 61003233, 61202342) supported by the National Natural Science Foundation of China;Project(MCM20121031) supported by the Science Fund of Education Department-China Mobile)
胡超,博士,講師,從事網絡管理、機器學習、教育信息化研究;E-mail: huchao@csu.edu.cn
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
