什么影響學生就業:大數據模型告訴你
2016-09-14 05:55:28韓霖金健宇方丹丹
中國教育網絡 2016年7期
文/韓霖 金健宇 方丹丹
什么影響學生就業:大數據模型告訴你
文/韓霖 金健宇 方丹丹
隨著計算機技術和信息技術的發展,高校各業務管理系統經過多年的運行和使用積累了大量數據,包括大學生在校期間學習生活等各方面的詳細數據,其中部分因素對就業有著或多或少的影響。可以利用對大數據的挖掘和處理得到海量數據里面蘊含的有價值的數據。
基于以上背景,本文針對大學生就業過程中亟需提高就業服務質量,提升就業數據的信息價值問題,以及大學生就業之前的求學過程中有利于就業的個性化發展問題,建立影響因素的數學模型,并用于就業工作的改進,包括就業時根據個人情況的就業方向和就業單位的個性化建議以及求學過程中根據個人就業意愿對個人發展的建議等。
數據收集
1.數據的收集范圍
本文以大學生就業為研究對象,最終要根據建立的數學模型對學校就業政策提出建議,對大學生就業和就業前的發展提出建議,所有與之相關的所有數據都在收集的范圍之內。收集的數據經過處理之后,其中影響比較大的因素作為主要研究對象。另外,在此過程長期的運行中,各因素的影響程度會有所變化,建議也要隨著實際情況而動態變化。
各相關數據存在于學校不同部門的業務系統中。其中招聘信息和學生就業信息在學生就業系統中,學生基本信息、成績等信息在學工和教務系統中,校園卡消費信息在財務系統中,圖書借閱信息在圖書館系統中,學生日常上網信息在網絡計費系統中,學生科研信息在科研信息系統中。
2.數據的收集和存儲
由于各個業務系統都是相對獨立的,所以數據不僅是分散的,其記錄方式和格式也都各不相同,為了解決這個問題,先建立數據中心,再將數據中心的數據庫與各個業務系統的數據庫對接,實現數據的同步,將分散的數據復制到數據中心統一存儲,并在同步的過程中建立好對應關系,在數據中心的數據庫中按照便于處理的形式進行存儲,例如:同一字段在不同的業務系統中其存儲格式是不同的,那么數據中心會指定一種標準的存儲格式,并在數據庫同步的過程中將不符合標準的數據進行對應的格式轉換。
數據處理
搜集的數據將作為數學模型的輸入和輸出進行運算,數據的質量好壞在一定程度上影響了數學模型能夠優化到的程度的高低,所以在進行計算之前,要對數據進行質量的優化即數據清洗和數據規范化。
1. 數據清洗
核心企業的地位重要,存在沒有及時回款的情況,產生應收賬款。下游經銷商需要大量存貨,需要付出預付款,導致存貨成本。上下游企業的信用較低,難以獲得相應的貸款,阻礙了發展。降低成本、信用傳遞、背書分享,在這樣的背景下產生了供應鏈金融。
數據清洗就是把“臟”的部分數據“洗掉”,發現并糾正數據文件中可識別的錯誤的最后一道程序,包括檢查數據一致性,處理無效值和缺失值等。數據倉庫中的數據是面向某一主題的數據的集合,這些數據從多個業務系統中抽取而來并包含歷史數據,有的數據是錯誤數據、有的數據相互之間有沖突,此類錯誤的或有沖突的數據稱為“臟數據”。需要按照一定的規則把“臟數據”“洗掉”,這就是數據清洗。不符合要求的數據主要是有不完整的數據、錯誤的數據、重復的數據三大類。
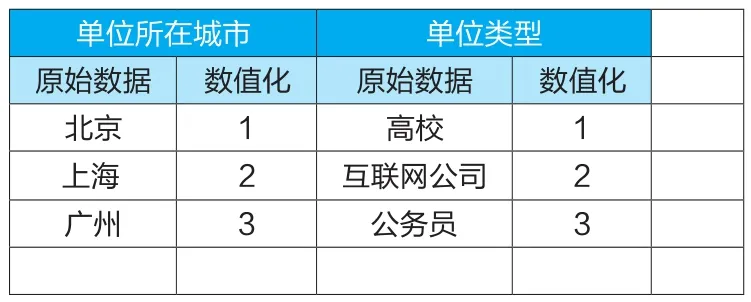
表1 數據數值化
2. 數據規范化
數據規范化包括數據數值化和標準化兩步,先對非數值部分的數據進行數值化處理,然后再對所有數據進行標準化處理,得到的數據作為數學模型的數據基礎。
3. 數據數值化
數據數值化顧名思義是針對那些不是以數值來存儲的數據,要將其以一定的規則轉換成數值,方可作為數學模型的數據基礎,便于進行計算。例如就業結果數據的數值化過程見表1,對于不同的指標分別將其非數值的數據按照統一的標準一一對應成為數值,數值并不代表何種實際意義,只是為了便于運算。
4. 數據標準化
在多指標評價體系中,由于各評價指標的性質不同,通常具有不同的量綱和數量級。當各指標間的水平相差很大時,如果直接用原始指標值進行分析,就會突出數值較高的指標在綜合分析中的作用,相對削弱數值水平較低指標的作用。因此,為了保證結果的可靠性,需要對原始指標數據進行標準化處理。
例如某門課程的成績t1取值范圍是從0至100,另外一門課程成績t2的取值范圍是從0至150,在直接使用數據進行運算時會造成權重的不均衡,所以按公式1進行處理得到t1'和t2',其取值范圍都是0 至1且代表某成績樣本在取值范圍中所處位置高低的百分比。
應用公式: t'=t/(tmax-tmin)
就業影響因素數學模型
1. 機器學習
機器學習是人工智能的核心,是使計算機具有智能的根本途徑,它研究了計算機怎樣模擬或實現人類的學習行為,以獲取新的知識或技能,重新組織已有的知識結構使之不斷改善自身的性能。在本文中,機器學習利用了計算機的高性能和大數據處理的優勢,模擬人類對指標的評判,經過不斷的優化和迭代從而建立指標體系,并據此進行智能推薦。
2.遺傳算法優化的人工神經網絡
人工神經網絡是對人類大腦的一種物理結構上的模擬,即以計算機仿真的方法,從物理結構上模擬人腦,以使系統具有人腦的某些智能。
遺傳算法以生物進化過程為背景,模擬生物進化的步驟,將繁殖、雜交、變異、競爭和選擇等概念引入到算法中,通過維持一組可行解,并通過對可行解的重新組合,改進可行解在多維空間內的移動軌跡或趨向,最終走向最優解。它克服了傳統優化方法的缺點,是一種全局優化算法。
基于遺傳算法的人工神經網絡的基本原理是用遺傳算法對神經網絡的連接權值進行優化學習,利用遺傳算法的尋優能力來獲取最佳權值。由于遺傳算法具有魯棒性強、隨機性、全局性以及適于并行處理的優點,所以被廣泛應用于神經網絡中。
對于本文研究的大學生就業影響因素的指標體系,為基于遺傳算法的神經網絡模型準備數據基礎,首先要明確政策可控類數據和個人可控類數據以及學生就業結果數據。其中,政策可控類數據是指政策的制定和管理者可以進行調控的數據類別,個人可控類數據是指個人在發展和規劃中可以進行改進和控制的數據類別,學生就業結果數據是指不可直接進行改變的學生就業結果類數據。本文建立數學模型并研究大學生就業因素,最終目的在于利用對可控類數據的調控和改進,對不可直接改變的就業結果類數據進行間接的影響,幫助廣大學生實現更好的就業目標。
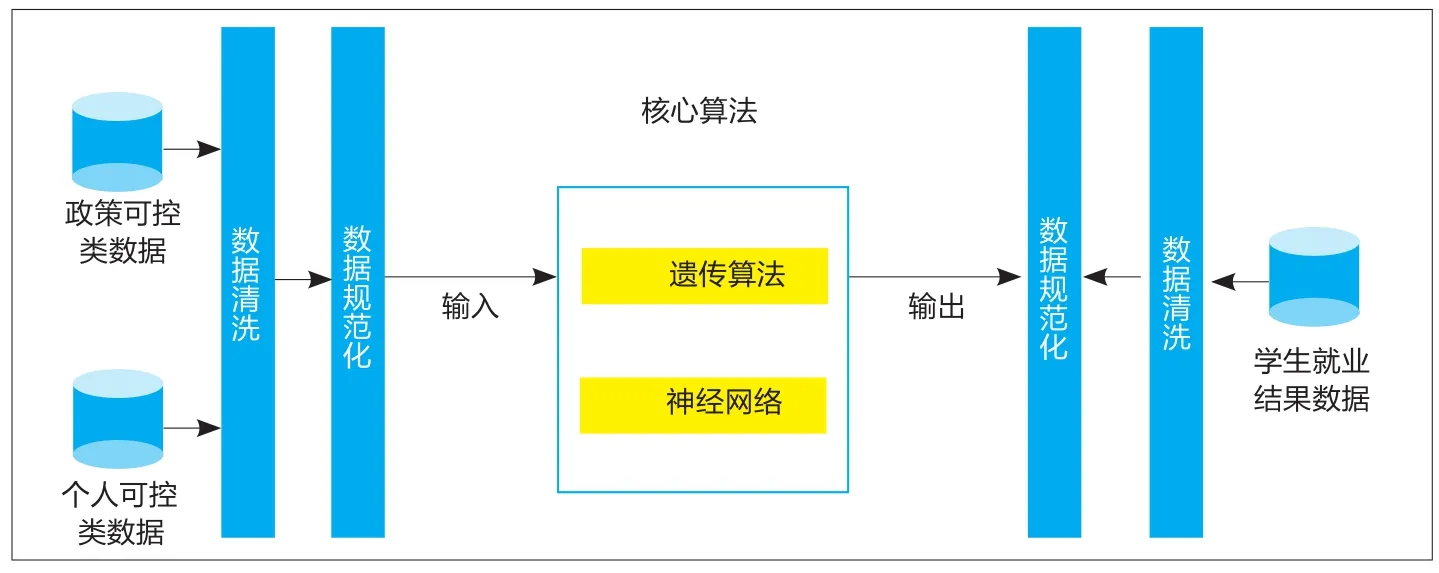
圖1 數學模型
3.數據模型的建立和優化
數學模型的建立如圖1所示,對政策可控類數據、個人可控類數據以及學生就業結果數據分別進行數據清洗和數據規范化處理,得到的結果數據分別作為核心算法的輸入和輸出,其中數據清洗的目的是為了將異常數據過濾掉以提高整個系統的運算準確率;數據規范化則包括非數值數據數值化、數據標準化等過程,規范化得到的數據作為核心算法的輸入,規范化做得越好則核心算法的效率和準確度也會更高;核心算法是由遺傳算法優化的神經網絡模型。
核心算法數學模型的建立和優化是以這三類大數據為基礎的,利用大量的數據樣本作為輸入和輸出來進行訓練得到相對比較成熟的數學模型,利用該模型可以在輸入新樣本時得到非常接近實際數據的輸出結果。為了保證核心算法數據模型的高準確性,隨著時間的流逝和大量新數據的獲取,需要不斷地用新樣本數據去繼續訓練以得到更加優化的數據模型并達到更高的準確率。
其次,基于理論研究和實踐經驗,根據學生就業方向和個人要求的不同,確立學生就業結果數據中的若干種標桿數據,標桿數據的確定并不是選取某個樣本,而是綜合考慮每項數據指標得到的理想的學生就業結果數據,同樣經過數據清洗和數據規范化得到核心算法的若干標桿輸出數據。
再次,對于某個樣本,在將其各項指標數據輸入核心算法后得到的輸出數據一般是偏離標桿輸出數據的,通過對樣本輸入的多個數據進行變化試驗,得到如何改變輸入才能更加接近目標的標桿輸出數據,在此過程中,通過單個指標數據變化而保持其他指標數據不變的試驗可以用來判定哪些指標更能影響輸出結果,以此為依據選取用于向用戶建議的指標項。
最后,通過數據規范化的逆運算得到輸入數據所對應的兩類可控數據的變化建議,再提供給被建議者。
在實際的應用當中,模型在不斷的迭代和優化,在其中某一時間被選取的個人可控類數據可能包括:每月圖書借閱數、每周到食堂早餐次數、每月逃課次數、每學期各科成績以及參加課外活動的次數及類型等數據,選取的政策可控類數據可能包括每年舉辦就業創業培訓講座的次數、對逃課行為的處理嚴重程度、對成績提高的學生設置獎勵的情況等數據。為了更好地利用機器學習運算客觀準確的優勢,將人為主觀判斷造成的不準確影響降到最低,在選取影響因素的過程中也要先考慮盡量多的因素,然后根據機器學習的運算結果來篩選,而不是按個人的印象來決定選取哪些不選取哪些,如此整個系統就能更加高效準確地運行起來并不斷地自我優化,同時提供越來越符合實際且效果好的建議。
(作者單位為對外經濟貿易大學)
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
商周刊(2017年23期)2017-11-24 03:24:09
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
中國衛生產業(2015年10期)2015-03-11 18:58:41
中國當代醫藥(2015年9期)2015-03-01 02:02:15
