基于大數據平臺的用戶行為分析研究
2016-09-21 05:40:29李嘉彬施勇薛質
信息安全與通信保密 2016年4期
李嘉彬,施勇,薛質
(上海交通大學電子信息與電氣工程學院,上海200240)
基于大數據平臺的用戶行為分析研究
李嘉彬,施勇,薛質
(上海交通大學電子信息與電氣工程學院,上海200240)
近年來,大數據分析已經成為了越來越多企業、政府和各類組織所鐘愛的重要技術,通過對體量巨大的網絡數據信息進行分析可以直觀、有效地描繪出互聯網個體的上網行為軌跡。本文介紹了一種基于對網絡數據報文進行分析的大數據分析方法,進一步得到網絡用戶群體的行為方式以及行為趨勢預測,從而為改善政府民生治理、企業商業運營以及網絡安全管理等領域提供有價值的信息參考。
大數據;用戶行為分析;網絡數據報文;行為趨勢預測;網絡安全管理
0 引言
近年來,大數據分析已經成為了越來越多企業、政府和各類組織所鐘愛的重要技術,通過對龐大的數據流量進行分析能夠有效地描繪出用戶的習慣、愛好、消費水平、上網的活躍時間等等信息,進一步構建出用戶的行為模型,以更好地對消費者或用戶行為進行預測、設計出更加優化、便利的系統。
大數據分析不僅在民生信息統計[1]、消費者行為預測等領域十分活躍,也是互聯網安全領域的一大利器。安全部門可以通過對網絡用戶的日常上網行為進行分析,對異常流量進行實時辨別與監測、企業也可以通過分析用戶對服務器的海量訪問數據來歸納正常用戶模型,進而對經常出現的惡意訪問行為進行過濾或攔截;或對個人用戶進行長時間的跟蹤統計,進而研究出完整的單一用戶行為模型,并對多個用戶的模型進行比對,歸納出更為豐富的行為分析結果……因此,如何設計一套行之有效的基于大數據平臺的用戶行為分析方法與系統成為重中之重。
1 使用大數據平臺的合理性分析
隨著互聯網應用的迅猛發展,網絡、數據等概念已經十分緊密地耦合于人們的生活、學習和工作中。一個大學生使用移動設備一天產生的數據流量可能高達數百兆、一家中小型公司一天產生的網絡日志動輒幾十G、而似社交網站Facebook這類社交網站的用戶每天發出的日志以及分享的資料更是不計其數,數據量已經達到PB級別……在這種超大體量的數據海洋面前,傳統關系型數據庫已經難以做到流暢地讀寫與存儲數據、傳統的單機數據分析系統也無法高效地完成數據分析工作。針對上述超大體量的數據,業界以4V特性——海量性(Volume)、多樣性(Variety)、實時性(Velocity)和低密度性(Value)——對大數據進行了定義。
數據挖掘技術可用于對大量數據進行分析處理,并且已經發展了很長時間,但是并不能用于解決4V問題,主要原因在于海量數據的存儲以及大規模的運算所需要的成本過于高昂。
在以前,解決一些跨學科的、極富挑戰性的、人類急待解決的科研課題是非常困難的。其中較為著名的有:
1.解決較為復雜的數學問題,例如:GIMPS(尋找最大的梅森素數)。
2.研究尋找最為安全的密碼系統,例如:RC-72(密碼破解)。
3.生物病理研究,例如:Folding@home(研究蛋白質折疊,誤解,聚合及由此引起的相關疾病)。
4.各種各樣疾病的藥物研究,例如:United Devices(尋找對抗癌癥的有效的藥物)。
5.信號處理,例如:SETI@Home(在家尋找地外文明)。
這些項目都很龐大,需要驚人的計算量,僅僅由單個的電腦或是個人在一個能讓人接受的時間內計算完成是決不可能的,需要解決這些問題應該且只能由超級計算機來解決。但是超級計算機的造價和維護非常昂貴,這不是一個普通的科研組織或者商業公司所能承受的。
為應對這類需求,分布式的思想應運而生,成為了一套行之有效的大數據解決方案。分布式思想主要包括分布式數據庫以及分布式算法兩個方面:
分布式數據庫是指利用高速計算機網絡將物理上分散的多個數據存儲單元連接起來組成一個邏輯上統一的數據庫。分布式數據庫的基本思想是將原來集中式數據庫中的數據分散存儲到多個通過網絡連接的數據存儲節點上,以獲取更大的存儲容量和更高的并發訪問量。
分布式算法是局部算法的集合。在解決一個需要非常巨大的計算能力才能解決的問題時,首先將價格低廉的服務器(甚至是個人主機、筆記本電腦)的計算能力動態地聚合起來建立成一個龐大的計算集群,再通過分布式算法將問題劃分成許多小的部分,然后把這些部分分配給集群中的各節點進行單獨處理,最后把這些計算結果綜合起來得到最終的結果。這套方法不僅在成本上比以往組建超級計算機或超級計算陣列等方式廉價許多,在時間開銷上也由于超高的并發性得到了長足的優化。
現在,在大量成熟的第三方開源工具(如ElasticSearch、MongoDB、Hadoop等)的支持下,通過部署計算機集群、安裝大數據分析工具并針對自身需求進行配置后,就可以得到一套基礎的大數據分析平臺。分布式的存儲和計算可以確保數據的海量性與實時性得到完美解決,而非結構化的數據庫存儲則在提供可擴展性的同時也解決了數據多樣性的問題。最后的低密度性,則需要通過人工地進行數據建模與定義以及制定數據查詢策略來解決。
2 用戶行為數據的分析方法
對于平臺中用戶的行為主要可以通過對網絡數據包的數據字段進行分析、拆解與重組來刻畫[2]。有用的常見字段如表1給出。
可以根據表1提供的信息,簡單地描述一個數據包于何時從何處發往何處、請求或響應了什么樣的數據,根據實際的需求,還可以對http包的正文內容進行進一步的采集和分析(如通過標簽提取出訪問頁面的標題),從而使對用戶的行為分析更加精細化[3]

表1 網絡數據包中的常見字段與含義
根據上述數據定義,可以總結出歸納出如圖1所示的關系模型:

圖1 用戶(群)行為分析關系模型
對于用戶的分析總體分為兩類,一類是用戶屬性描述,該類分析描述了用戶的一些具體屬性,如:消費水平、最關注內容等;另一類是用戶行為描述,該類分析描述了用戶的某類趨勢或習慣,如:數據包的時間與空間分布、訪問對象的群體分布等[4]。
第一類描述可以幫助分析師刻畫用戶(個體或群體)的形象,進而為用戶(群)進行分類或歸納;第二類描述則動態地展示了用戶(群)的階段性特點,可以幫助分析師了解用戶的行為模式。在具體的行為分析中,需要將兩類描述相互結合,才能得到完整的用戶行為刻畫結果。以下給出基于表1定義的字段的行為分析方法。
2.1 面向整個網絡平臺的分析方法
面向全平臺的分析,可以刻畫出一個或多個用戶群體的行為軌跡,或通過歸納眾數群體的數據特征得出用戶群體的行為模式。
2.1.1 主要被訪問域名的群體分布
分析目的:通過對平臺內用戶訪問的目標站點進行排序,得出最受用戶歡迎的站點列表。
分析策略:通過對Host字段進行聚合,按照聚合結果降序排列,得到所有被訪問的域名列表。可以通過該結果得到平臺內全體用戶最熱門的訪問站點。
2.1.2 移動終端設備
分析目的:通過對平臺內用戶使用的移動終端設備進行分析,得出當前用戶普遍使用的設備品牌或類型。
分析策略:通過對User-Agent字段進行過濾,按照結果降序排列,得到結果。
2.1.3 頁面訪問內容
分析目的:通過對平臺內用戶總體訪問的網頁內容進行統計,得出當前用戶群體最關注的熱點內容。
分析策略:通過對Title字段聚合,結果按降序排列得到所有被訪問頁面的標題,并通過正則表達式過濾去除了結果中諸如“404 Not Found”、“302 Found”等于分析無意義的結果。
2.2 面向單一對象的行為刻畫分析方法
除了面向整個平臺進行群體性用戶行為描述,還可以通過指定源、目的IP地址、源、目的MAC地址等方式將研究對象轉為面向單一對象進行行為刻畫。通過這種方式,可以精確、有效地描繪出具體的某個用戶的完整行為模式,從而實現更加具有針對性、準確性的用戶行為分析。
可以根據已有的攻擊模型對用戶行為進行進一步的比對:如在時間上周期性地對某對象進行訪問、或持續性地對某對象進行訪問、或大量的對某對象發出特定的(尤其是非標準的)網絡數據請求等,則可將該源IP列為重點觀測對象,查看是否確實存在網絡攻擊行為。
2.2.1 針對單一IP的網絡流量在時間上的分布進行監測
分析目的:通過對某源IP地址發出的請求報文進行分析,檢查數據流在時間分布上是否存在異常數據流,進而對可能存在的異常網絡行為進行監測。比如,抓取用戶在每周一的網絡流量分布,如果某個周一的某時段網絡流量遠高于其他周一該時段的流量,則認為在這一天該用戶的網絡訪問出現異常情況,可將該源IP列為觀測對象,查看是否確實存在網絡攻擊行為。
分析策略:首先對時間戳字段timestamp按照Date Histogram方法進行聚合,將分組級別設置為周級(weekly),并設置觀察的起訖時間區間(可選)。之后迭代一層聚合,繼續對timestamp字段按照Date Histogram方式進行聚合,此時分組級別設置為小時(hourly),最后迭代一層過濾器,指定需要觀察的用戶。如,以src_ip字段作為過濾標志,最終得到從某源目的IP發出的所有網絡數據請求按時間的分布結果。
2.2.2 針對單一IP的網絡流量在空間上的分布進行監測
分析目的:通過對某IP地址的訪問趨勢進行對比,通過發現數據流在空間分布上是否存在異常數據流,進而對可能存在的異常網絡行為進行監測。如,某IP的常規訪問群體分布在某些IP地址組成的集合內,當某一次分析時突然出現了大量該集合之外的新IP地址或IP地址群,則可認為可能出現了由這些新IP地址(群)發起的對該IP地址的網絡攻擊。
分析策略:首先對時間戳字段timestamp按照Date Histogram方法進行聚合,將分組級別設置為周級(weekly),并設置觀察的起訖時間區間(可選)。之后迭代一層聚合,繼續對Host字段按照Terms方式進行聚合,篩選出統計結果前十的訪問域名,最后迭代一層過濾器,指定需要觀察的用戶,本例以src_MAC字段作為過濾標志,最終得到了通過某源MAC地址發出的所有網絡數據請求按空間的分布結果。
2.2.3 單一用戶的搜索引擎使用偏好分析
分析目的:通過對用戶的搜索引擎使用情況進行分析,了解用戶的搜索引擎使用習慣與偏好。
分析策略:通過對常用搜索引擎的URL進行匯總,并在查詢語句中利用Filter方法對Host字段進行過濾,并迭代篩選出指定用戶的數據,得到結果。
2.2.4 單一用戶的最關注的視頻排序
分析目的:通過對某源IP地址對視頻網站的訪問進行統計,獲得其最常瀏覽的視頻網站或視頻進行聚合,從而分析出其瀏覽習慣。
分析策略:首先對Title字段進行聚合,得到站點標題組成的結果集,在此基礎上對Host字段迭代過濾器,篩選出來自視頻網站的數據包,最后再次迭代過濾器篩選出制定用戶的數據,得到結果。
3 基于大數據平臺的用戶行為分析方法與分析系統設計
3.1 基于大數據平臺的用戶行為分析方法
基于大數據平臺的用戶行為分析[5],指的是基于大數據平臺的分布式存儲與分析技術支持,通過對平臺覆蓋范圍內的所有用戶產生的海量網絡數據報文或服務器產生的日志文件進行高效快速地采集、過濾、篩選和分析,并從分析結果中得到用戶數據與用戶行為之間的關系,從而總結出分析師所需要得到的行為模型或行為趨勢。

圖2 大數據分析步驟與大數據分析系統
行為模型可以包括用戶的上網習慣、偏好、消費模式、作息規律等結果;行為趨勢可以包括區域(平臺)內數據流量走向趨勢、某(或某些)網站(或應用)的使用率走勢、異常行為發生總量變化趨勢等。
3.2 基于大數據平臺的用戶行為分析系統設計
本文設計的基于大數據平臺的用戶分析系統通過對大數據平臺提供的海量數據進行大規模數據處理,根據實際需求以及具體應用環境設計過濾條件與分析策略,最終實現對平臺內所有用戶發生的網絡數據報文進行分析,提供有效、實用的可視化數據報表[6]。
系統通過抓包工具在各個節點處捕獲數據流,并通過Hadoop平臺進行分布式處理,將數據存入HBase數據庫中。每一次在分析師指定的時間間隔后,分析系統開始運行,將HBase數據庫中的數據利用轉儲工具進行格式轉換為JSON格式文件。
將JSON文件批量導入開源的大數據處理工具并通過Web頁面在前端進行可視化的結果展示。
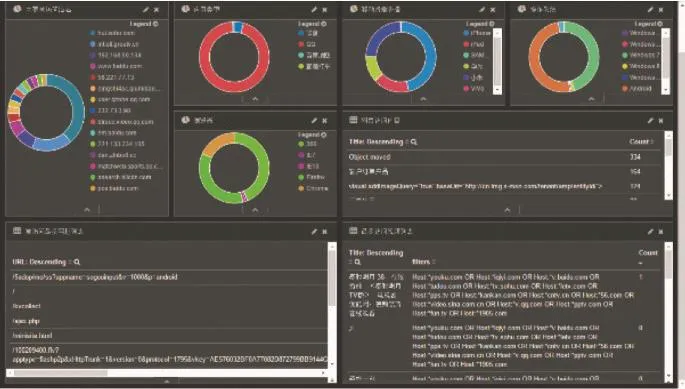
圖3 數據可視化呈現框架效果展示
4 用戶行為分析系統測試與分析
4.1 實測:面向整個網絡平臺的結果分析
4.1.1 主要被訪問域名的群體分布

圖4 主要被訪問域名群體分布分析結果
由上圖可以看出,平臺內用戶訪問最多的站點是“搜狐”,占比約40%。
4.1.2 移動終端設備

圖5 移動終端設備使用情況分析結果
由上圖可以看出,平臺內用戶使用最多的移動設備是iPhone,占比約46.45%,其次是小米,約占24.33%。
4.1.3 頁面訪問內容

圖6 頁面訪問內容的分析結果
由上圖可以看出,平臺內整體流量中占比最高的頁面內容是某購物網站的“客戶訂單產品”頁面,其次是“訂單出庫”頁面。
4.2 實測:面向單一對象的行為刻畫
4.2.1 針對單一IP的網絡流量在時間上的分布進行監測

圖7 網絡流量在時間上的分布情況分析結果
由上圖可以看出,IP地址為“10.161.35.249”的用戶在2016年1月17日(周日)至2016年1月24日(周日)的時間段內,工作日期間,上網最頻繁的時間段是23時至次日6時左右,而在9~17時期間幾乎沒有網絡數據流量產生。雙休日時,在22時以前,網絡數據流量都非常多,由此可見該用戶應該運行著一些持續后臺聯網的程序或應用,并且用戶的上網活躍期在午后。
4.2.1 針對單一IP的網絡流量在空間上的分布進行監測

圖8 網絡流量在空間上的分布情況分析結果
由上圖可以看出,MAC地址為XXXX的用戶最常訪問的站點是int.ott.greatv.cn、www.baidu.com、192.168.50.134等三個站點。1月18日出現了相對大量的對101.226.141.199的訪問,可以對上述對象進行進一步分析,驗證是否有針對10.226.141.199的網絡安全事件發生。
4.2.3 單一用戶的搜索引擎使用偏好分析
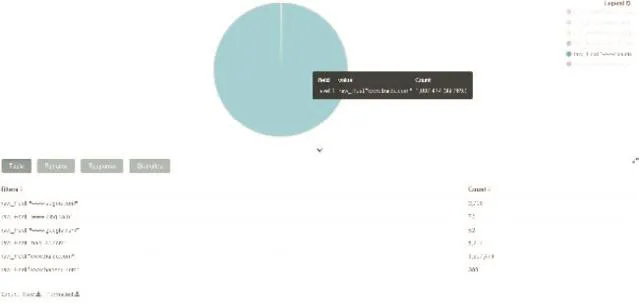
圖9 搜索引擎使用情況分析結果
由上圖可以看出,IP地址為10.226.141.199的用戶最常使用的搜索引擎是百度搜索引擎,占比高達99.76%,其次是搜狗搜索引擎,占比0.15%。
4.2.4 單一用戶的最關注的視頻排序

圖10 視頻瀏覽情況分析結果
由上圖可以看出,IP地址為“10.161.35.249”的用戶最常觀看的視頻為“中經在線”。
5 結語
大數據的分析本質上可以劃分為兩種類型,一是對現在已發生的數據進行總結,發現規律;二是對過往的數據進行歸納,預測未來的發展趨勢。大數據分析以其體量大、數據全、分析快等特性,已經成為行業共識,是未來發展的必然趨勢[7]。
本文介紹了一種基于對網絡數據報文進行分析的大數據分析方法,通過直觀的圖表展示方式進一步得到網絡用戶群體的行為方式以及行為趨勢預測,從而為改善政府民生治理、企業商業運營以及網絡安全管理等領域提供有價值的信息參考。
本文得到的結果可以廣泛的運用于各類實際應用的場景中,并可以通過對數據報頭以及非加密的數據報文進行較為準確的用戶行為分析和統計結果,然而對加密傳輸的報文或者通過隱蔽信道進行傳輸的信息還缺乏合適的分析手段,這將是下一階段嘗試攻克的課題。
[1]張璐,李曉勇,馬威等.政府大數據安全保護模型研究[J].信息網絡安全,2014(5):63-67.
[2]姜開達,李霄,孫強.基于網絡流量元數據的安全大數據分析[J].信息網絡安全,2014(5):37-40.
[3]陳臣.基于大數據的圖書館個性化服務用戶行為分析研究[J].圖書館工作與研究,2015(2):43-45.
[4]胡宇辰,郭宇.基于沙漏模型的移動互聯網用戶行為分析[J].管理世界,2013(7):184-185.
[5]任思穎,基于大數據的網絡用戶行為分析[D].北京郵電大學,2014.
[6]陶彩霞,謝曉軍,陳康等,基于云計算的移動互聯網大數據用戶行為分析引擎設計[J].電信科學,2013(3):32-35。
[7]陳建昌.大數據環境下的網絡安全分析[J].新聚焦,2013(17):13-16.
User Behavior Analysisbased on Big Data Platform
LI Jia-bin,SHI Yong,XUE Zhi
(School of Electronic Information and Electrical Engineering,Shanghai Jiao Tong University,Shanghai 200240,China)
Big data analysis becomes an important technology for more and more enterprises,governments and various associations.By analyzing the huge quantity of network data,the users’ internet behavior could be vividly and effectively traced out.A method of big data analysis method based on processing the network datagram is proposed,and the behavior of network users could be further acquired and the behavior trend also forecasted,thus providing valuable references for better governance of people’s livelihood,enterprise operating and security management.
big data; user behavior analysis; network datagram; behaviortrend forecast;network security management
TP309 [文獻標志碼]A [文章編號]1009-8054(2016)04-0087-05
2016-01-28
信息網絡安全公安部重點實驗室基金(No.C14612)
李嘉彬(1992—),男,碩士,主要研究方向為大數據分析、網絡攻防;
施勇(1979—),男,博士,講師,主要研究方向為網絡安全、網絡攻防;
薛質(1971—),男,博士,教授,主要研究方向為網絡安全、網絡攻防。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
商用汽車(2016年11期)2016-12-19 01:20:16
山東工業技術(2016年15期)2016-12-01 05:31:22
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
