互聯(lián)網(wǎng)商品匹配算法
2016-09-21 08:30:34上海交通大學電子信息與電氣工程學院上海200240南通大學計算機科學與技術(shù)學院江蘇南通22609
上海大學學報(自然科學版) 2016年1期
顧 頎,朱 燦,曹 健(.上海交通大學電子信息與電氣工程學院,上海200240;2.南通大學計算機科學與技術(shù)學院,江蘇南通22609)
互聯(lián)網(wǎng)商品匹配算法
顧頎1,2,朱燦1,曹健1
(1.上海交通大學電子信息與電氣工程學院,上海200240;2.南通大學計算機科學與技術(shù)學院,江蘇南通226019)
實體解析是指識別同一實體的不同描述形式的過程,旨在保障數(shù)據(jù)質(zhì)量,是數(shù)據(jù)清理、數(shù)據(jù)集成及數(shù)據(jù)挖掘中的關(guān)鍵技術(shù).隨著電子商務的不斷發(fā)展和成熟,商品的多樣性和消費者靈活的購買方式,使得對網(wǎng)絡商品的精確識別和匹配成為大數(shù)據(jù)時代亟待解決的問題.與傳統(tǒng)實體解析主要針對結(jié)構(gòu)化數(shù)據(jù)不同,網(wǎng)絡數(shù)據(jù)具有非結(jié)構(gòu)化、異構(gòu)和海量的特性,為此設計了綜合相似度算法(synthesized similarity method,SSM)來計算網(wǎng)絡商品數(shù)據(jù)間的相似度,同時引入凝聚的層次聚類框架,以匹配來自不同數(shù)據(jù)源的異構(gòu)商品.此外,為了解決大數(shù)據(jù)環(huán)境下對執(zhí)行效率的要求,從字符串相似度緩存、約束知識庫和分塊策略三個方面對SSM進行優(yōu)化,基于真實數(shù)據(jù)集的實驗結(jié)果驗證了SSM的執(zhí)行效率和有效性.
實體解析;大數(shù)據(jù);非結(jié)構(gòu)化數(shù)據(jù);商品匹配
電子商務的持續(xù)發(fā)展給人們帶來了龐大的數(shù)據(jù)總量以及復雜的數(shù)據(jù)形式,數(shù)據(jù)的關(guān)聯(lián)形態(tài)正在發(fā)生變化,這些都給數(shù)據(jù)處理帶來了極大的挑戰(zhàn).以互聯(lián)網(wǎng)環(huán)境下豐富的網(wǎng)絡商品為例,隨著商品多樣性的提升,同一網(wǎng)絡商品在不同網(wǎng)絡平臺往往以各種形式存在著,相似商品信息散落在各個網(wǎng)絡平臺,網(wǎng)絡商品的搜索空間不斷增加,使得消費者在感興趣的商品信息的搜索與整合上耗費了大量精力.如將散落在各個網(wǎng)絡平臺的商品信息關(guān)聯(lián)起來,勢必有利于商品信息的搜索與整合,從而免去消費者繁重的搜索工作.而為了將來自不同網(wǎng)絡平臺的商品信息進行關(guān)聯(lián),首要任務是完成商品的匹配,即從不同網(wǎng)絡平臺中找出同一網(wǎng)絡商品的不同表述,將這一過程稱為實體解析(entity resolution)[1],或稱為記錄連接(record linkage)、對象匹配(object matching)、重復檢測(duplicate detection)等[2].
實體解析是以數(shù)據(jù)為中心的各項工作(如數(shù)據(jù)清理、數(shù)據(jù)集成、數(shù)據(jù)挖掘等)中至關(guān)重要的步驟,是數(shù)據(jù)質(zhì)量的保障.不同網(wǎng)絡平臺(數(shù)據(jù)提供方)對同一網(wǎng)絡商品(實體)可能會有不同的描述,如數(shù)據(jù)格式、表示方法等.將實體的描述稱為實體的引用,實體解析是指從引用集合中解析并映射到現(xiàn)實世界中實體的過程.傳統(tǒng)的實體解析方法可以分為成對實體解析[3]、集合實體解析[4]和時態(tài)實體解析[5].這三種實體解析方法適用于結(jié)構(gòu)化數(shù)據(jù)的解析,例如一般關(guān)系數(shù)據(jù)庫中的元組.事實上,在真實的網(wǎng)絡商品匹配中,需處理的數(shù)據(jù)沒有統(tǒng)一的模式,也沒有預定義的“鍵”和“值”,將這樣的數(shù)據(jù)稱為非結(jié)構(gòu)化數(shù)據(jù),其匹配策略與傳統(tǒng)的面向結(jié)構(gòu)化數(shù)據(jù)的解析方法相比有很大差別.本研究正是以此為切入點,對現(xiàn)有商品匹配算法存在的不足進行了深入剖析,并提出了有效的解決方案.
目前常用的面向網(wǎng)絡商品匹配的算法主要有WHIRL(word-based heterogeneous information retrieval logic)算法[6]和TMWM(title model words method)[7].WHIRL算法主要采用TF-IDF以及向量空間模型對商品引用進行建模,并計算商品之間的相似度;TMWM結(jié)合了商品名稱間的歸一化編輯距離,以及從名稱中抽取的“模式詞”集合之間的相似度.WHIRL算法和TMWM存在以下兩個缺陷:①網(wǎng)絡商品往往遍布于不同的網(wǎng)絡平臺,算法只能處理來自兩個數(shù)據(jù)提供方的商品數(shù)據(jù),而無法處理來自多個網(wǎng)絡平臺的商品數(shù)據(jù);②網(wǎng)絡商品數(shù)據(jù)具有非結(jié)構(gòu)化、異構(gòu)性等特征,算法只能針對結(jié)構(gòu)化數(shù)據(jù)進行商品名稱的比對,而無法對非結(jié)構(gòu)化商品數(shù)據(jù)計算相似度.
為了應對網(wǎng)絡商品數(shù)據(jù)給商品匹配帶來的挑戰(zhàn),本研究提出了一種基于凝聚層次聚類框架的商品匹配方法,使用綜合相似度算法(synthesized similarity method,SSM)計算商品之間的相似度.SSM將從商品名稱中獲取的信息以及從商品屬性的鍵值對中獲取的信息有效結(jié)合起來,構(gòu)造綜合的相似度計算方法,最終根據(jù)相似度的值確定商品是否匹配.引入的凝聚層次聚類(agglomerate hierarchical clustering,AHC)框架可以在不影響匹配準確度的前提下實現(xiàn)多源商品數(shù)據(jù)匹配.為了解決大數(shù)據(jù)對執(zhí)行效率的要求,從以下三個方面對所提出算法進行了優(yōu)化:使用字符串相似度緩存、添加約束知識庫以及應用分塊策略.最后,基于真實數(shù)據(jù)集的實驗結(jié)果驗證了所提出算法的執(zhí)行效率和有效性.
本研究的主要工作及貢獻可總結(jié)如下.
(1)提出了基于凝聚層次聚類的商品匹配框架,解決了傳統(tǒng)算法無法處理多源商品匹配的問題.
(2)基于非結(jié)構(gòu)化網(wǎng)絡商品數(shù)據(jù)設計開發(fā)了綜合相似度算法,將商品的有效信息充分結(jié)合起來,提高了商品匹配的準確度.
(3)為了適應大數(shù)據(jù)環(huán)境下對執(zhí)行效率的要求,從三個方面對所提出算法進行優(yōu)化,通過大量實驗表明了所提出算法在性能上有明顯提升.
1 相關(guān)工作
1.1實體解析概念
1946年,Dunn[8]提出了記錄鏈接(record linkage)的概念;其后,Newcombe等[9]在1959年提出了實體解析的概念;之后,F(xiàn)ellegi等[10]將這個問題規(guī)范化并進行深入研究.經(jīng)過幾十年的發(fā)展,實體解析技術(shù)已經(jīng)廣泛應用于國民醫(yī)療系統(tǒng)、人口普查、多媒體數(shù)據(jù)庫整合以及銀行信貸系統(tǒng)等各個領(lǐng)域.常用的實體解析方法包括成對實體解析、集合實體解析以及時態(tài)實體解析.
1.1.1成對實體解析
成對實體解析通過計算一對記錄各屬性間的相似度衡量記錄是否匹配.衡量方法包括基于規(guī)則、基于屬性權(quán)重以及基于機器學習(包括決策樹、支持向量機、嵌套分類器、條件隨機場等).成對實體解析適用于對數(shù)據(jù)庫內(nèi)重復記錄的檢測以及數(shù)據(jù)庫間的記錄匹配.
1.1.2集合實體解析
成對實體解析通過引入領(lǐng)域知識、機器學習等方法提高了匹配準確度,然而獨立的求解過程無法區(qū)別不同實體擁有相同屬性這一情形.集合實體解析使得求解過程不再獨立完成,而是借助關(guān)系的引入,使得更多關(guān)聯(lián)信息被用于解析過程中.
1.1.3時態(tài)實體解析
傳統(tǒng)的實體解析方法往往忽略了時態(tài)信息,而實際數(shù)據(jù)記錄中常用時間戳描述現(xiàn)實世界實體在特定時間的狀態(tài).時態(tài)實體解析通過定義與時間間隔相關(guān)的“衰變率”,來減少對高相似的獎勵和對低相似的懲罰,從而利用時態(tài)信息為實體解析提供更多的“證據(jù)”.
1.2商品匹配算法
隨著網(wǎng)絡商品數(shù)據(jù)的急速累積,網(wǎng)絡商品的搜索空間不斷增加,商品匹配變得愈發(fā)重要.目前,常用的網(wǎng)絡商品匹配算法主要有WHIRL算法和TMWM.
1.2.1WHIRL算法
WHIRL算法由Cohen[6]于1998年提出,該算法利用向量空間模型對商品信息進行建模,并計算商品之間的相似度.在向量空間模型中,現(xiàn)實世界中商品的自然語言描述可以用詞項構(gòu)成的文本向量表示.向量中的成分對應文本中的某個詞項,成分值與該詞項在文檔中的“重要性”相關(guān)聯(lián),詞項越重要則對應的成分值越大.如果兩個文檔具有很多相同的“重要性”相近的詞項,則可以認為它們是相似的.對詞項賦予權(quán)重的方法有很多,其中TF-IDF(term frequency-inverse document frequency)方法經(jīng)過改進后可以很方便地在向量空間模型中引用[6].盡管文本向量通常很長也很稀疏,但已有很多方法可以高效處理稀疏向量.
1.2.2TMWM
TMWM由Vandic等[7]于2012年提出,該算法結(jié)合了商品名稱間的歸一化編輯距離以及從名稱中抽取的“模式詞”集合之間的相似度.編輯距離是指將一個字符串轉(zhuǎn)換成另一個字符串所需進行的最少操作數(shù),已廣泛應用于字符串相似度或差異度的計算中.由于未考慮字符串的長度,這樣的編輯距離也稱為絕對編輯距離.通過對絕對編輯距離進行歸一化,可以處理長度較短的字符串.首先,計算兩個商品名稱間的余弦相似度,若相似度值高于閾值α,表明兩個商品為同一商品,返回“true”;若相似度低于閾值α,則分別提取兩個商品的模式詞形成相應的模式詞集合,再將兩個集合中的模式詞對進行逐一比較,如果存在一個模式詞對的非數(shù)字字符近似而數(shù)字字符不同,那么這兩個商品為不同商品,返回“false”,如果非數(shù)字字符和數(shù)字字符都一致,則更新兩個商品名稱之間的相似度,即求出兩個商品名稱的余弦相似度和兩個商品名稱所產(chǎn)生的兩個模式詞集合間的平均編輯距離相似度的加權(quán)和,最終相似度如果大于預設的閾值ε,則兩個商品為同一商品,返回“true”.
2 基于凝聚層次聚類的商品匹配框架
2.1凝聚層次聚類(AHC)方法
WHIRL算法和TMWM適用于分析兩個網(wǎng)絡商店的商品(假設同一網(wǎng)絡商店內(nèi)沒有重復商品).事實上,商品搜索往往涉及多個數(shù)據(jù)源,為此需要將算法的輸出從兩個商品間的相似度變?yōu)榇鎯Σ煌唐烽g的距離,或稱為相似度矩陣,在該矩陣上運行聚類算法.k-means算法和層次聚類算法是最常用的聚類算法.k-means算法將全部集中的個體分成k個子集,但在網(wǎng)絡商品搜索的應用背景下,無法預知確切的k值;層次聚類算法則不需要額外的先驗知識.傳統(tǒng)的層次聚類算法主要分為兩大類:①分離(自頂向下)的層次聚類,即初始時將所有的點視為一個簇,之后將簇的一部分分離出來形成一個新簇,重復這一過程直至每個簇中只包含單獨的點,此類算法需要確定哪個簇應該被分離以及如何被分離;②凝聚(自底向上)的層次聚類,即初始時將每個點作為單獨的簇,之后合并最相鄰的兩個簇,重復這一過程直至最后只剩下一個簇,此類算法需要預先定義簇之間的距離,以此作為簇合并的依據(jù).這兩種層次聚類方法中凝聚的層次聚類較為常用.
凝聚層次聚類中的關(guān)鍵問題是簇間距離的計算.不同的簇間距離計算方法又將凝聚層次聚類分為以下三種模式:單鏈模式(MIN)、全鏈模式(MAX)和組平均(group average)模式.單鏈模式又稱最小值模式,簇間距離等于簇中成員間的最短距離.這種策略容易造成“Chaining”效應,即兩個實際離得較遠的簇由于簇中個別距離較近的點而合并,使得離得較遠的點因為若干離得較近的“中介點”而被鏈接起來,并且這種效應可能會逐漸擴大.全鏈模式又稱最大值模式,簇間距離等于簇中成員間的最遠距離,與單鏈模式相反,全鏈模式中離得較近的簇可能因為其中個別離得較遠的點而無法合并.組平均模式是單鏈模式和全鏈模式的折中策略.本研究使用基于組平均策略的凝聚層次聚類作為商品匹配算法的框架.
2.2綜合相似度算法(SSM)
TMWM通過分析商品名稱判斷商品是否匹配,該算法要求將商品名稱以某種特定的方式進行編碼,盡可能將有辨別性的信息體現(xiàn)在商品名稱中.然而這一要求對真實數(shù)據(jù)卻過于嚴苛,在大多數(shù)情況下真實數(shù)據(jù)的商品名稱只提供商品的型號信息.顯然,在實驗數(shù)據(jù)集上僅僅利用商品名稱信息進行匹配,結(jié)果并不能讓人滿意.因此,本研究提出了綜合相似度算法(synthesized similarity method,SSM),也可將其看作是對TMWM的改進,即添加了更具體更詳細的商品信息比對,如商品屬性等.以相機為例,添加了相機的一系列參數(shù)比如相機像素、顯示屏尺寸、傳感器尺寸、光學變焦、感光元件類型等.顯然,相比單純利用商品名稱信息,這些額外信息能夠獲得更好的匹配結(jié)果.
所有商品屬性可以以鍵值對(key-value pair,KVP)的形式來表示,如“相機像素”、“2 000萬”.將從商品名稱中獲取的信息以及從商品屬性的鍵值對中獲取的信息結(jié)合起來,得到綜合相似度

式中,α+β+γ=1.綜合相似度算法共分三部分:titleSim,mKVPSim,nmPerc,其中第一部分titleSim是兩個商品名稱間的相似度,該相似度取自TMWM;第二部分mKVPSim和第三部分nmPerc是針對商品屬性鍵值對計算的相似度.SSM中的符號注釋如表1所示.

表1 算法符號注釋Table 1 Algorithm notations
SSM假設同一網(wǎng)絡平臺沒有重復商品,若兩個商品來自同一平臺,則它們之間的距離disti,j為∞;否則,繼續(xù)比較商品的屬性鍵值對.為了利用屬性鍵值對信息,選擇q-gram算法[11]衡量相似度,該算法能很好地應對拼寫錯誤,并且不需要額外的標簽.q-gram算法設置了一個大小為q個字符的滑動窗口,這些長度為q的子串構(gòu)成一個子串集合,然后比較兩個字符串生成的子串集合的相似度:假設字符串s1和s2相應的子串集合分別為C1和C2,則s1和s2的q-gram相似度為

根據(jù)calSim的定義可以看出,即使是部分匹配也會為最后的相似度作出貢獻,這在處理拼寫錯誤以及縮寫時很有優(yōu)勢.應用calSim計算相似度后,如果兩個鍵的相似度大于閾值μ,則計算這兩個鍵對應值的相似度:假設商品i和j的鍵值對集合分別為Ki和Kj,則Ki和Kj的相似度為

找出所有鍵匹配的鍵值對并計算相似度后,分析剩余的未匹配鍵值對.此時忽略這些鍵值對的鍵,分別抽取商品屬性值中的所有模式詞生成模式詞集合,接下來計算這兩個集合中匹配的模式詞所占比例為

由式(3)和(4)計算得到mKVPSim和nmPerc后,再采用TMWM計算商品名稱間的相似度titleSim.接著,按照式(1)計算得到綜合相似度,并將相似度轉(zhuǎn)換成距離.最后,使用凝聚層次聚類方法求得聚合后的簇集合.算法1總結(jié)了完整的構(gòu)造過程.

3 實驗結(jié)果與分析
3.1實驗設置

3.2商品匹配實驗結(jié)果分析
3.2.1SSM結(jié)果分析
SSM共有3個參數(shù)μ,γ和ε需要訓練,使用網(wǎng)格搜索訓練ε的最佳值,范圍為0.1~0.9,步長為0.1.在50個訓練集上,μ,γ和ε最佳值的平均值為0.792,0.638和0.612,將其應用于測試集后得到平均Precision為0.627,平均Recall為0.583,平均F1-measure為0.609.與WHIRL和TMWM兩個算法相比較可知:改進后的SSM在各方面效果都有所提升,詳細的算法性能比較如表2所示.

表2 3種算法的評價指標對比Table 2 Performance metrics of three different algorithms
3.2.2基于字符相似度緩存的算法實驗結(jié)果分析
WHIRL算法,TMWM和SSM的復雜度主要都集中在字符串間相似度的計算上,實驗中令每種算法在同一個數(shù)據(jù)集上運行50次,每個樣本都將數(shù)據(jù)集劃分為不同的訓練集和測試集.如果每次運行新樣本都要重新計算所有字符串間的相似度,顯然這會浪費大量的時間.因此,預先計算所有字符串間的相似度并保存在一個global cache中,之后每次運行時直接從global cache中讀取所需相似度,將會大大提高運行效率.為了預防系統(tǒng)崩潰或者重復測試,還可將global cache中的數(shù)據(jù)格式化地存儲在硬盤當中.在實驗數(shù)據(jù)集上應用此方法后,總運行時間從35 h 37 min減少到了6 h 19 min,速度為原來的5.63倍,可見添加global cache之后大大縮短了算法的運行時間,尤其是重復在同一數(shù)據(jù)集上運行時其優(yōu)勢更加明顯.
3.2.3基于添加知識約束的算法實驗結(jié)果分析
為提高算法準確性并避免多余計算,本研究為算法添加了根據(jù)常識或統(tǒng)計數(shù)據(jù)建立的約束庫,也稱知識庫.知識庫作為額外組件可靈活地參與到運算中,也可以根據(jù)新的數(shù)據(jù)和知識進行更新(擴充和改進),將參與到運算中的數(shù)據(jù)和知識統(tǒng)稱為知識約束(knowledge constraints,KC).在計算一對引用間的相似度之前,可以先使用約束知識庫的相關(guān)條目對目標引用對進行核查,若不符合其中任意一條約束,則終止比較,從而避免多余計算,縮短算法的運行時間.表3給出了應用于算法的知識庫中的幾個例子.
約束知識庫能為算法提供更多的信息,或者說是證據(jù).這些信息不同于字符串相似度,它們更直接也更可信.尤其值得注意的是,約束知識庫給出的通常是一些必要條件,即不滿足條件的引用對絕不可能指向相同的實體,應用這些知識約束可以篩除一些潛在的FP結(jié)果,從而提高算法的Precision.表4給出了SSM添加約束知識庫前后的性能對比.

表3 知識約束類型和例子Table 3 Types and examples of knowledge constraints

表4 SSM添加KC前后的性能對比Table 4 Performance comparison between SSM without and with KC
從表4可以看出,知識約束對算法的貢獻主要體現(xiàn)在Precision上.盡管添加約束知識庫后SSM的效率和性能均得到了提升,但不可否認的是,知識庫依賴于領(lǐng)域知識.由于不太可能復用跨領(lǐng)域的知識庫,不嚴謹或是過于嚴苛的約束又無疑將對算法產(chǎn)生負面影響(例如過于嚴苛的約束可能會增加FN的數(shù)目并影響Recall,從表3中可以看出Recall有輕微下降),因此領(lǐng)域知識庫的建立需要領(lǐng)域?qū)<业膮⑴c.
3.2.4基于分塊策略的算法實驗結(jié)果分析
本研究采用的真實實驗數(shù)據(jù)集共有1 933條相機數(shù)據(jù),計算規(guī)模(主要指字符串比較)已經(jīng)達到了千萬數(shù)量級,不難想象在大數(shù)據(jù)集上應用算法時將會面臨效率問題.為此引入分塊技術(shù)(block technique)對數(shù)據(jù)進行預處理,即根據(jù)某種知識或規(guī)則將數(shù)據(jù)集分成規(guī)模更小的數(shù)據(jù)塊(block),在數(shù)據(jù)塊里再進行商品匹配.
(1)基于hash函數(shù)的分塊.
定義一個關(guān)于商品的一項或多項屬性的hash函數(shù),每個塊都有一個hash值標識,將所有商品按照屬性求hash值后歸入互不相交的塊中,商品匹配在塊內(nèi)完成.hash函數(shù)的種類多種多樣,往往需要量身定制,可以將簡單的規(guī)則合并以滿足復雜的需求.minHash算法[12]就是基于多種hash鍵值進行分塊的算法.根據(jù)實驗數(shù)據(jù)集的特點,本研究選取品牌、像素以及顯示屏尺寸三個參數(shù)作為minHash算法的鍵值列表.表5為應用minHash算法進行分塊前后的SSM性能比較.

表5 SSM應用minHash算法進行分塊前后的性能對比Table 5 Performance comparison between SSM without and with minHash algorithm
應用minHash算法進行分塊后,算法運行速度從5.7 h縮短到3.5 h,提高了62.3%,但在Precision,Recall以及F1-measure三個性能指標上都有不同程度的降低.性能下降可能是由分塊錯誤造成的,即同一商品被分到不同塊中.在實驗數(shù)據(jù)集上,運行時間尚在可承受范圍之內(nèi),但若是面對極其龐大的數(shù)據(jù)集,這種性能與速度之間的權(quán)衡將至關(guān)重要.
(2)基于相似度與距離的分塊.
McCallum等[13]提出Canopy算法來加速重復檢測的過程.Canopy算法的基本思想是利用一些計算簡便的參數(shù)為依據(jù),將所有引用劃分成互相部分重疊的簇(Canopies).將引用集合中的每一條引用都映射到空間中的一點,再根據(jù)空間中各點的位置將聚集的點劃分到一個塊中.應用Canopy算法前需要預先設計一個距離函數(shù),如果使用之前計算的商品相似度作為分塊依據(jù),則函數(shù)代價太大,不妨以部分相似度或一些簡單參數(shù)為依據(jù),因此選擇商品名稱的q-gram相似度作為分塊依據(jù)(q=3).實驗中選擇k-means算法以及凝聚層次聚類方法.表6給出了應用k-means算法進行分塊前后的SSM性能比較.

表6 SSM應用k-means算法進行分塊前后的性能對比Table 6 Performance comparison between SSM without and with k-means algorithm
從表6可以看出,隨著k值(簇的個數(shù))的增大,Precision的變化呈現(xiàn)波形(當k=75時達到最大值),并且波形的前半段上升比較平緩,而后半段下滑明顯加劇.這可能是由于選取商品名稱的相似度作為分塊依據(jù)在實驗數(shù)據(jù)集上有較好區(qū)分度,并且在k=75時恰好與應該劃分的簇個數(shù)等同.另一方面,當k=100及125時,由于簇的個數(shù)超出理想簇個數(shù)過多,聚類的過程變得不穩(wěn)定,從而產(chǎn)生一系列連鎖反應,導致產(chǎn)生很多FP.隨著k值的增大,Recall逐漸下降并且趨于穩(wěn)定,這是由于隨著簇個數(shù)的增加,兩個應該指向同一實體的引用被劃分到同一個簇中的可能性減小,從而導致算法產(chǎn)生的FN逐漸增多,Recall逐漸減小.綜合Precision與Recall,F(xiàn)1-measure的變化也呈現(xiàn)波形.因此,在利用k-means算法進行分塊時,簇個數(shù)的設定需要根據(jù)數(shù)據(jù)集的特點以及對算法運行時間的要求進行權(quán)衡.不同分塊策略的性能比較如圖1所示.
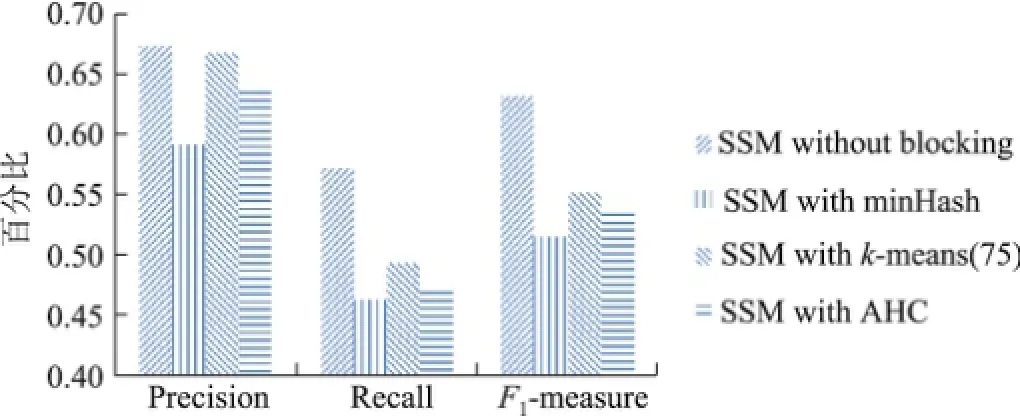
圖1 不同SSM應用AHC后的評價指標比較Fig.1 Performance metrics of different SSM with AHC
從圖1可以看出,在總體表現(xiàn)上,使用AHC算法進行分塊的效果優(yōu)于minHash算法,而與k-means算法相當.AHC算法相對于k-means算法的優(yōu)勢在于其通用性,一方面,AHC算法無需指定k值而且比k-means算法更穩(wěn)定;但是另一方面,如果事先確定了k值,則使用k-means算法可能會得到更好的效果.
4 總結(jié)與展望
實體解析是數(shù)據(jù)預處理過程中的重要步驟,為了解決網(wǎng)絡環(huán)境下非結(jié)構(gòu)化商品數(shù)據(jù)的匹配問題,本研究提出了基于凝聚層次聚類框架的綜合相似度算法,以識別不同網(wǎng)絡平臺的同一商品,本算法適用于非結(jié)構(gòu)、多來源的商品匹配.同時,引入字符串處理、添加約束及分塊策略的優(yōu)化方法,目的是在現(xiàn)有方法的基礎上提高大數(shù)據(jù)環(huán)境下商品匹配的執(zhí)行效率.在大量真實數(shù)據(jù)集上的實驗驗證了本算法的有效性.
目前,雖然商品匹配算法較多,但仍缺少有效的評價方法,用于測試的大規(guī)模真實數(shù)據(jù)集的缺失也是目前亟待解決的問題.在接下來的工作中,應著重設計新的衡量方法或指標來減少人工檢測帶來的資源浪費,同時構(gòu)造一個優(yōu)質(zhì)的大規(guī)模真實數(shù)據(jù)集,進一步提升算法與現(xiàn)實需求的契合度.
[1]ELMAGARMID A K,IPEIROTIS P G,VERYKIOS V S.Duplicate record detection:a survey[J]. IEEE Transactions on Knowledge and Data Engineering,2007,19(1):1-16.
[2]CHRISTEN P.Data matching:concepts and techniques for record linkage,entity resolution,and duplicate detection[M].Berlin:Springer Science and Business Media,2012.
[3]CHRISTEN P.Automatic record linkage using seeded nearest neighbour and support vector machine classification[C]//Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.2008:151-159.
[4]BHATTACHARYA I,GETOOR L.Collective entity resolution in relational data[J].ACM Transactions on Knowledge Discovery from Data(TKDD),2007,1(1):5.
[5]LI P,DONG X,MAURINO A,et al.Linking temporal records[J].Proceedings of the VLDB Endowment,2011,4(11):956-967.
[6]COHEN W W.Integration of heterogeneous databases without common domains using queries based on textual similarity[C]//ACM SIGMOD Record.1998:201-212.
[7]VANDIC D,VAN DAM J W,F(xiàn)RASINCAR F.Faceted product search powered by the Semantic Web[J].Decision Support Systems,2012,53(3):425-437.
[8]DUNN H L.Record linkage[J].American Journal of Public Health and the Nations Health,1946,36(12):1412-1416.
[9]NEWCOMBE H B,KENNEDY J M,AxFORD S J,et al.Automatic linkage of vital records computers can be used to extract“follow-up”statistics of families from files of routine records[J].Science,1959,130(3381):954-959.
[10]FELLEGI I P,SUNTER A B.A theory for record linkage[J].Journal of the American Statistical Association,1969,64(328):1183-1210.
[11]UKKONEN E.Approximate string-matching with q-grams and maximal matches[J].Theoretical Computer Science,1992,92(1):191-211.
[12]BRODER A Z,CHARIKAR M,F(xiàn)RIEZE A M,et al.Min-wise independent permutations[J].Journal of Computer and System Sciences,2000,60(3):630-659.
[13]MCCALLUM A,NIGAM K,UNGAR L H.Efficient clustering of high-dimensional data sets with application to reference matching[C]//Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.2000:169-178.
Product matching based on Internet and its implementation
GU Qi1,2,ZHU Can1,CAO Jian1
(1.School of Electronic Information and Electrical Engineering,Shanghai Jiao Tong University,Shanghai 200240,China;2.School of Computer Science and Technology,Nantong University,Nantong 226019,Jiangsu,China)
Entity resolution identifies entities from different data sources that refer to the same real-world entity.It is an important prerequisite for data cleaning,data integration and data mining,and is a key in ensuring data quality.With the rapid growth of E-commerce,diversity of products and flexible buying patterns of consumers,product identification and matching becomes a long-standing research topic in the big data era.While the traditional entity resolution approaches focus on structured data,the Internet data are neither standardized nor structured.In order to address this problem,this paper presents a synthesized similarity method to calculate similarity between different products.An agglomerate hierarchical clustering method is used to identify products from different sources.Also,the approach is optimized to improve efficiency of execution in three aspects:global cache,knowledge constraints,and blocking strategies.Finally,a series of experiments are performed on real data sets.The experimental results show that the proposed approach has a better performance compared with others.
entity resolution;big data;unstructured data;product matching
TP 391
A
1007-2861(2016)01-0058-11
10.3969/j.issn.1007-2861.2015.04.016
2015-11-30
國家自然科學基金資助項目(61272438,61472253,61300167);上海市科委資助項目(15411952502,14511107702)
曹健(1972—),男,教授,博士生導師,博士(后),研究方向為服務計算、網(wǎng)絡計算、大數(shù)據(jù)分析.
E-mail:cao-jian@cs.sjtu.edu.cn
