面向大數據應用的多層次混合式并行方法
2016-09-21 08:30:37支小莉鄭圣安上海大學計算機工程與科學學院上海00444上海交通大學計算機科學與工程系上海0040
上海大學學報(自然科學版) 2016年1期
黃 磊,支小莉,鄭圣安(.上海大學計算機工程與科學學院,上海00444;.上海交通大學計算機科學與工程系,上海0040)
面向大數據應用的多層次混合式并行方法
黃磊1,支小莉1,鄭圣安2
(1.上海大學計算機工程與科學學院,上海200444;2.上海交通大學計算機科學與工程系,上海200240)
基于很多大數據應用存在對數據進行多種并行處理的需求,提出兩層混合式并行方法,即執行單元的混合并行和計算模型的混合并行.通過在同一個計算節點上執行單元的混合并行,充分挖掘基礎設施的計算能力,從而提高數據處理性能;采用在同一個執行引擎中集成多個計算模型的并行方法,以適合應用多樣異質處理模式.不同的混合并行方法可以契合不同的數據和計算特點,以滿足不同的并行目標.介紹了混合式并行方法的基本思想,并以前期開發的并行編程模型BSPCloud為基礎,闡述了進程和線程混合并行、BSP和MapReduce混合并行的主要實現機制.
混合并行;編程模型;整體同步并行(bulk synchronous parallel,BSP);MapReduce
在物聯網、電子商務、電信、醫療和金融等諸多應用領域,數據已經從TB級迅速發展到PB級甚至更高的數量級,且仍以指數速度增長,信息數量及復雜程度與日俱增[1-2].通過對數據的分析和處理掌握未來的發展趨勢,使數據創造出更大的價值已經成為一個亟需解決的問題[3-6].
大數據的并行處理需求催生了以Hadoop,Dryad,Pregel,Hama,All Pairs,Oivos,KPNs,Storm和Spark等為代表的并行處理平臺.每一種大數據并行處理平臺適合于特定的數據類型,能高效地處理某一類數據[7],例如Hadoop適合處理易于用鍵值對表示的數據密集型數據,Storm適合于處理流數據,Pregel適合于處理大規模圖數據,Hama適合于處理大規模科學計算.
隨著大數據應用的擴展及其處理要求的變化,計算模型也隨之不斷創新和優化,不斷產生新的各種面向領域的處理技術和處理平臺[8].從橫向上看,針對不同的數據類型,計算模型呈現出不斷擴散的趨勢,基于這些模型的Dryad,Pregel,All Pairs,Orleans平臺均適合于處理某一領域的數據;從縱向上看,處理平臺呈現出不斷演化的趨勢,HadoopDB,Pig Latin,Sawzall,Oivos,KPNs和Spark等平臺皆由MapReduce模型演化而來,Pregel和Hama等平臺則是基于整體同步并行(bulk synchronous parallel,BSP)模型發展而來的.
由于應用領域的多元性、數據類型的復雜性、數據處理方式以及流程等的多樣性,研究混合并行計算方法,以適應大數據應用的處理方式多樣性和異構性,已成為一個迫切需要解決的問題.需要使用不同的技術手段、利用異構的基礎設施和異質的計算特征來獲取性能優勢.
1 研究現狀
已有的關于混合并行計算的研究基本上是在異構多核的硬件架構上的混合并行,例如CPU和GPU的并行執行、多CPU系統中的進程級和線程級的并行[9].這類混合并行方法已在各領域的計算密集型應用中獲得廣泛使用.從本質上說,這種混合計算主要從硬件角度來觀察,將同一個并行計算模型的不同實現方法或實現機制進行混合,或者利用硬件組成部分的異構性來實現異質的并行.例如,基于消息的分布內存的消息傳遞接口(message passing interface,MPI)并行和共享內存的線程級OpenMP的混合并行.文獻[10]認為未來的系統是混合系統,即同構多核處理器+GPU+其他加速器.從程序執行角度看,這種混合并行通常體現為多重硬件所支持的多種或多個執行單元(execution unit)的并行,例如多進程和多線程的并行.
本研究側重于更高層次的混合并行,即計算模型的混合并行.目前,國內外相關研究主要集中在對單一并行編程模型的創新或改進,對混合計算模型及混合式編程模型的研究比較鮮見.孟丹等[11]提出一種Transformer編程架構,該架構基于兩個簡單的主類型send()和receive()范式建立程序模型,試圖以一種統一的方式來構建不同的并行編程模型.Pace[12]對MapReduce模型和BSP模型進行了分析,指出MapReduce模型本身缺乏堅實的理論基礎,并需要與其他模型(如BSP,PRAM等)建立關系,同時指出用MapReduce來實現BSP是可行的,但沒有考慮MapReduce和BSP混合并行的問題.潘巍等[13]介紹了為分布式大圖算法設計的一個改進的MapReduce并行計算框架,將BSP嵌入到Map或Reduce階段.通過將迭代過程內化到Map或Reduce階段的BSP超級步間,從而減少多輪作業調度的開銷.本研究的編程模型中沒有把BSP限制到MapReduce的內部,而是由應用自行決定BSP和MapReduce這兩種模式的關系.同時本研究還修改了一些BSP和MapReduce對輸入輸出和中間數據的處理方式,使其能靈活選擇內存或文件形式,從而改善編程模型對更多應用的支持能力.Fegaras[14]提出一個新的框架,將數據分析應用的描述性查詢翻譯成MapReduce和BSP的評估計劃,根據運行時的資源決定采用哪個模型.若資源足夠,就采用BSP模型,完全在內存中計算查詢,否則,采用MapReduce模型.這項工作給本研究帶來一定啟示:BSP和MapReduce在內存數據是否能跨越迭代步這一點上,截然不同的做法會對不同特點的應用產生很大的性能影響.
目前的大數據并行編程模型大多是針對特定類型的數據進行某種模式的處理,缺乏有效的混合方案,難以適應大數據應用的異構數據處理的需求.
2 兩層混合式并行方法
由于應用存在復雜多樣的并行計算特征,使得多種并行方式共存成為必需.這些混合并行方式能夠在同一個編程模型中實現,可以更靈活方便地支持應用開發.混合并行主要從以下兩個層次來實現:①執行單元(execution unit)的混合,以挖掘異構多核硬件的計算能力;②計算模型的混合,以適合應用的多樣化數據處理模式.
2.1執行單元層次的混合并行
一個并行任務,可以實現為進程或線程等形式在處理器上執行.執行單元的混合并行主要體現為多進程和多線程的混合執行.通過充分利用多核異構硬件的計算資源,合理安排節點內和節點外的數據使用策略,能夠顯著加快數據處理速度.特別是目前多核處理器在集群中的普遍使用,使得這種對計算密集型應用效果明顯的混合并行成為必然的趨勢.
集群是大數據應用通常采用的基礎設施,集群中的節點可以是普通物理機,或者是云(虛擬)主機.集群一般具有如圖1所示的邏輯結構.每個節點機本身可以是一個異構系統,可能具有多個同質的CPU核和若干異質核(如GPU,DSP等)(見圖2).
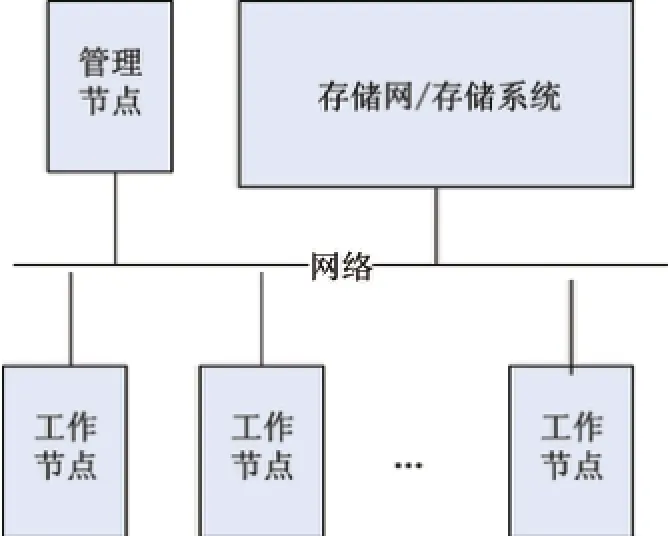
圖1 集群的邏輯結構Fig.1 Logical structure of the cluster
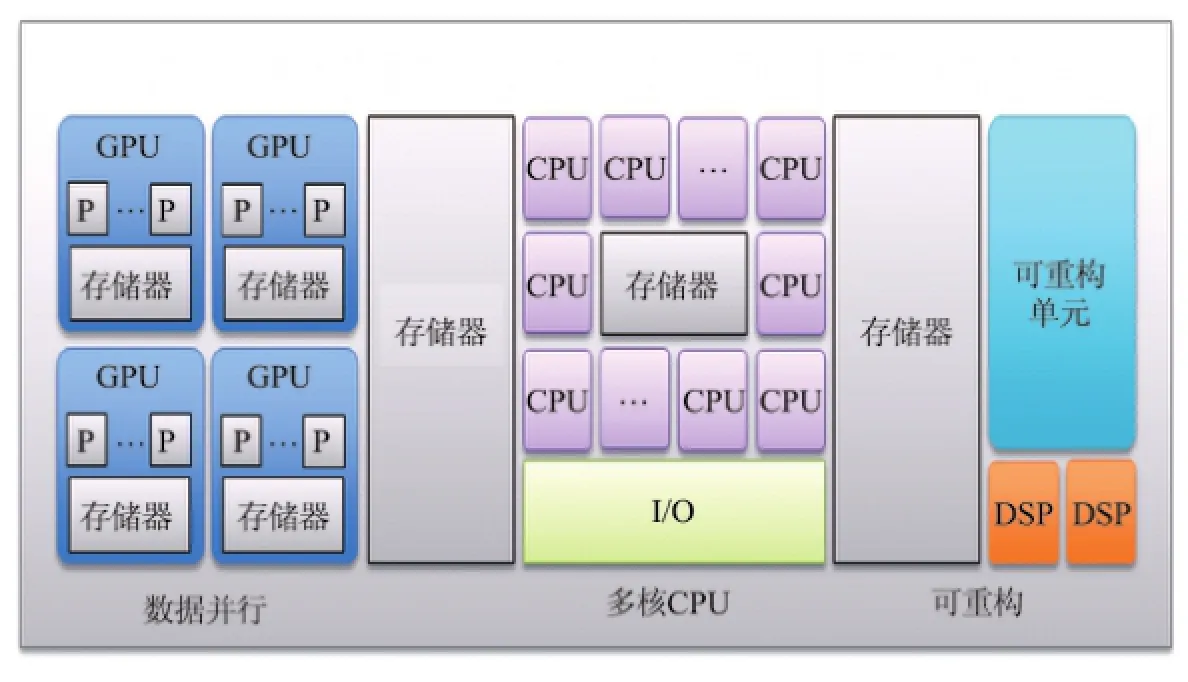
圖2 節點機的異構多核架構Fig.2 Heterogeneous and reconfigurable computer architecture
多核硬件的存在使單個節點內可以存在多層次的線程級并行任務.圖3(a)是適用于同質處理器核的兩級并行.圖3(b)是異質處理器核CPU+GPU的兩級并行,CPU線程可以等待GPU線程執行完畢,也可以與之同時執行.基于此,集群很方便就能實現至少兩級的混合并行:進程級的并行和線程級的并行(見圖4).這兩級并行實質上是分布內存級的并行和共享共存級的并行.在共享共存級的并行中,并行任務(線程)共享一個全局地址空間,數據交換接近零代價;在分布內存級的并行中,并行任務(進程)行為獨立,需要顯式通信.
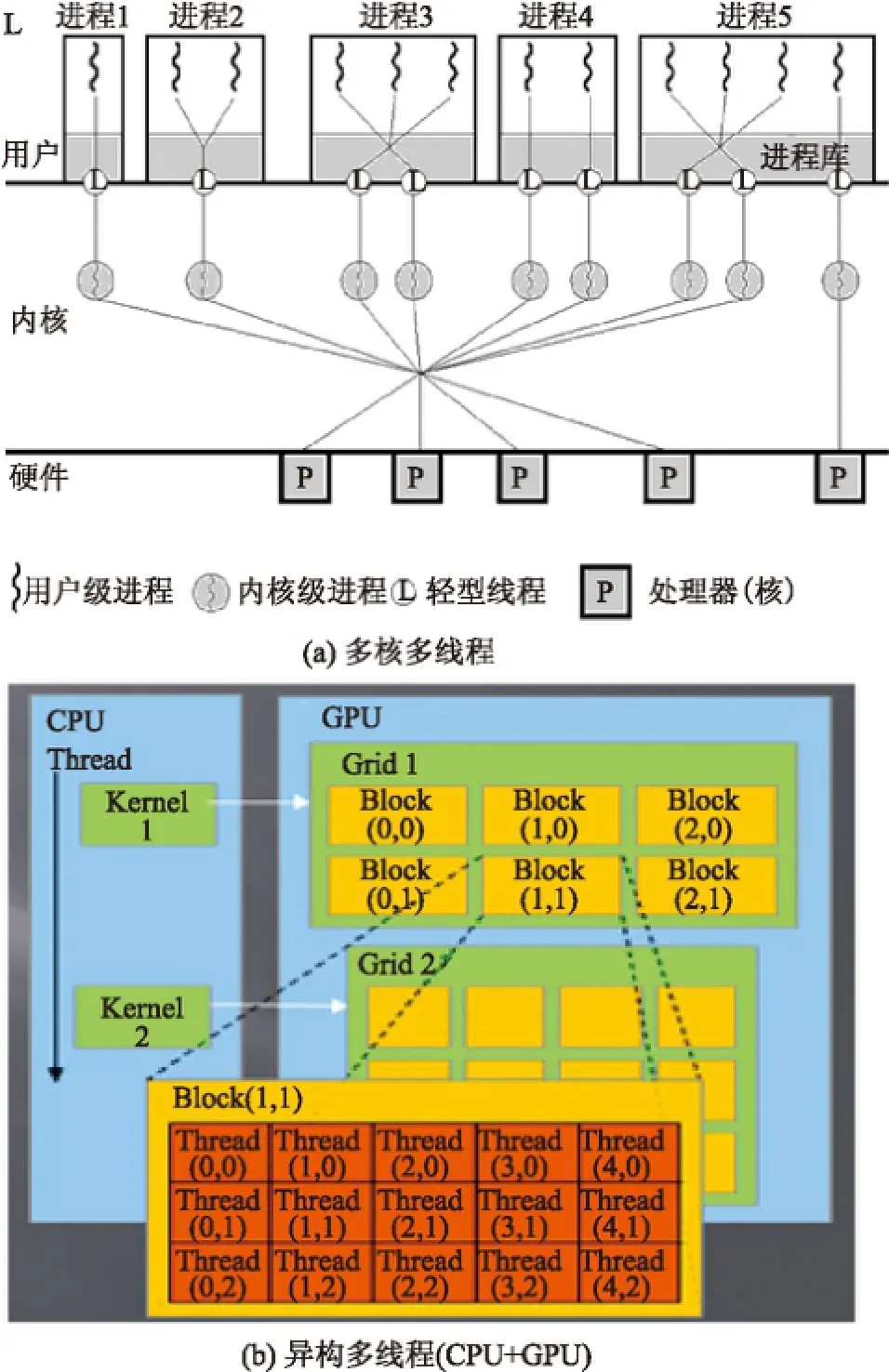
圖3 多線程并行Fig.3 Multi-threaded parallel
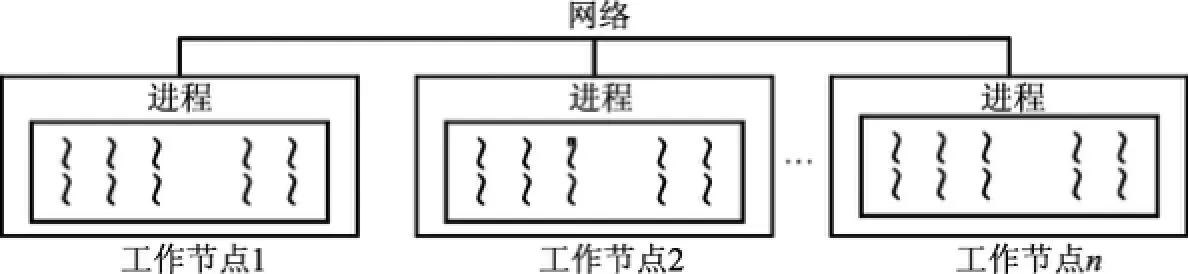
圖4 多進程與多線程并行Fig.4 Multi-process and multi-threaded parallel
進程級和線程級的混合并行在傳統高性能計算中應用較多,例如MPI/OpenMP混合編程模型,雖然在大數據應用中易被忽視,但這種混合并行對大數據應用也具有普遍的提升處理速度的效果.
2.2計算模型層次的混合并行
并行計算模型通常代表某類典型的數據處理模式.計算模型的混合能滿足同一個應用的處理模式的多樣化需求,使應用開發更自然流暢.每個并行編程模型中都蘊涵了某種計算模型,最普遍的是MapReduce,BSP和有向無環圖DAG等.下面首先研究BSP和MapReduce混合的可能性和實現機制,然后再考慮其他計算模型如有向圖或數據流模型的混合.
MapReduce是目前使用最廣泛的大數據計算模型[15-16],其優點在于借用函數式語言的Map和Reduce原語,使得底層復雜的并行處理細節被屏蔽,應用開發者只需關注Map和Reduce的處理邏輯本身,其余復雜的并行事務交由系統來完成,因此系統的可拓展性較好,并且可在廉價的集群上高效運行.但MapReduce采用單輸入單輸出、基于鍵值對的計算模式,對應用存在較強的限制性,不適合需要迭代、重復的控制流程的應用.MapReduce的另一個主要缺點是不在內存中保存跨越連續的MR任務數據,這在復雜MR工作流中會引起不能容忍的高開銷.
BSP模型是由Valiant[17]提出的一種并行計算模型,該模型由很多被稱為超步的計算過程組成,一個超步由計算階段、全局通信階段和路障同步階段組成,其優點在于模型簡單易編程、性能可預測、能避免死鎖等.由于BSP在內存中保留了中間數據,且超步內各任務可以進行通信,故BSP可用于具有復雜迭代過程的圖、矩陣等計算.除了用于傳統的高性能并行計算,BSP還可用于面向大數據應用的并行計算,例如Google的Pregel[18],Apache HAMA[19]和Yahoo Giraph[20].
BSP和MapReduce各具優勢,可以根據數據處理特點結合使用(combined use),發揮各自所長(見圖5).
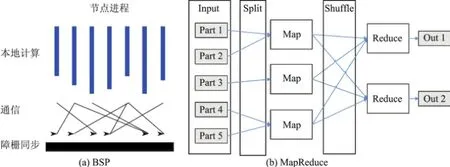
圖5 BSP和MapReduce的執行模型Fig.5 Execution models of BSP and MapReduce
3 HyBSPCloud的實現機制
目前已出現很多大數據并行編程模型,但支持混合式并行的模型較少.雖然HAMA可以支持BSP引擎和MapReduce引擎,但這兩個引擎是獨立的,基本上沒有關注BSP和MapReduce的有機結合的相關研究.本研究在前期開發的并行編程模型BSPCloud[21]的基礎上,探索混合式并行方法的實現機制,并改善編程模型對大數據的支持.
與已有的編程模型相比,BSPCloud具有以下優點:
(1)性能可預測,開發人員在編寫應用時,有一個可依賴的性能消耗模型,可以預先對應用程序的時間復雜度等進行分析;
(2)不僅適合計算密集型計算,也適合數據密集型計算;
(3)應用的執行進度可動態顯示,可以對總執行時間和剩余時間進行預測.
BSPCloud包含能實現管理、計算、通信、進度等功能的22個類的源代碼.本研究在BSPCloud的基礎上,將之改進成為HyBSPCloud,使其增加了以下優點:①支持兩個層次上的混合并行;②改善處理大數據的能力.
3.1進程級和線程級混合并行
HyBSPCloud采用如圖6所示的分布式內存和共享內存混合并行模型(即進程級和線程級的混合并行).實現結構如圖7所示.
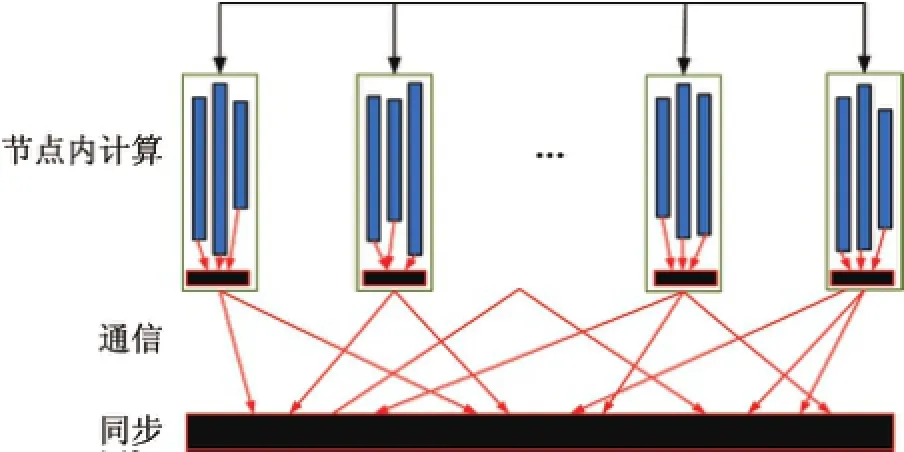
圖6 HyBSPCloud的進程級和線程級混合并行模型Fig.6 Mixture parallel model of process-level and thread-level in HyBSPCloud
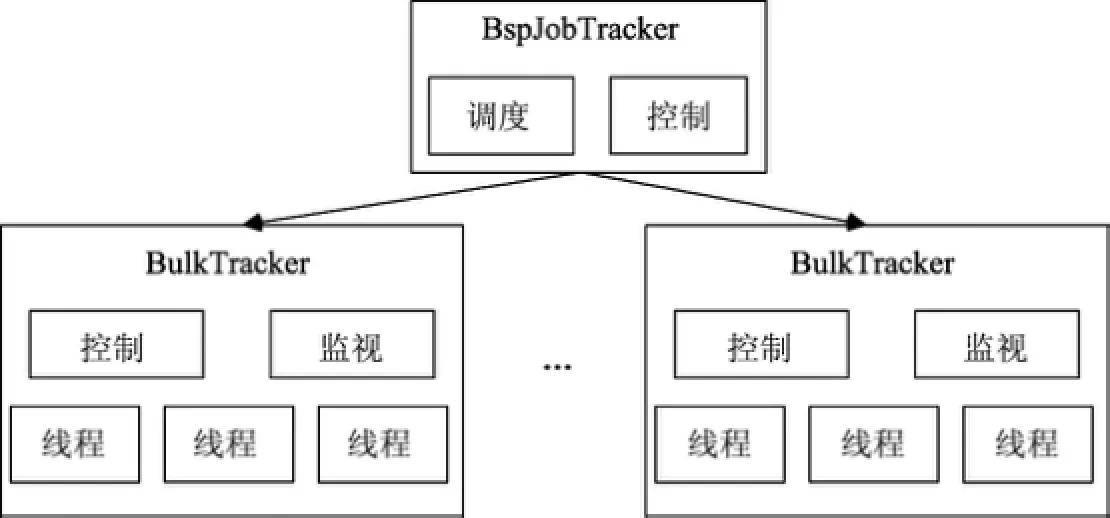
圖7 HyBSPCloud中進程級和線程級混合并行的實現Fig.7 Hybrid parallel implementation of process-level and thread-level in HyBSPCloud
圖7中的BspJobTracker負責作業的調度和控制作業的運行,當用戶提交一個作業到云平臺后,由調度器Schedule模塊負責調度作業運行.當調度器取出一個作業后,BspJobTracker將作業劃分成若干子任務,并將這些子任務分配到節點機(虛擬機或物理機),由BulkTracker負責調度運行.
BulkTracker啟動若干個線程,由這些線程完成細粒度任務計算.異構處理器(如GPU)的線程由BulkTracker啟動的線程來管理.各個節點上的Control負責實現節點間的同步、負載均衡、容錯等功能.Monitor負責向BspJobTracker報告節點內的運行狀態.
BulkTracker之間是進程級并行.如圖8所示,進程間通信(inter process communication,IPC)可以采用消息傳遞、同步、共享內存和遠程過程調用等技術.HyBSPCloud使用socket實現節點間并行任務的通信,對節點內的并行進程也支持共享內存的通信方式.BulkThread之間是線程級并行.HyBSPCloud使用全局變量、消息傳遞、參數傳遞和線程同步這4種方式實現線程間通信(inter thread communication,ITC),從而實現線程級并行管理.對于應用開發者,一般采用全局變量方式就可達到線程間交換數據的目的.
3.2BSP和MapReduce的混合并行
HyBSPCloud在原來的BSP基礎上,增加了MapReduce的實現.BSP和消息傳遞功能不嵌入在Map和Reduce(縮寫為MR)內部,MR也不嵌入在BSP的超步中實現.而是由應用開發者決定BSP和MapReduce這兩種模型在執行時的關系:BSP可以嵌入在MR內,MR也可以嵌入到BSP的bulk中.圖9為BSP和MR運行時3種關系的示例:①將MR嵌入在BSP超步中的計算階段(算法見表1);②將BSP嵌入在Map階段(算法見表2),此方法與文獻[13]類似;③先執行MR,再執行BSP.
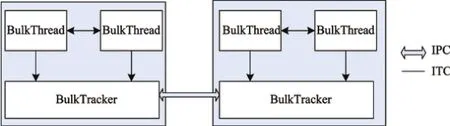
圖8 HyBSPCloud的并行任務間的通信Fig.8 Communication between parallel tasks in HyBSPCloud
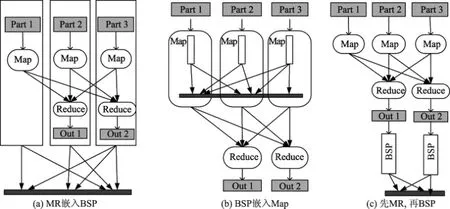
圖9 BSP和MapReduce運行時的三種關系Fig.9 Three relationships of BSP and MapReduce when running

表1 MR嵌入在BSP超步中的計算階段Table 1 Embed MR into calculation stage of BSP

表2 BSP嵌入在Map階段Table 2 Embed BSP into Map stage
另外,HyBSPCloud的BSP的中間結果不局限于內存,其輸入輸出和中間數據均可使用分布式文件系統.同時,為了更好地支持復雜計算并行應用,提供MR的變形版本,即MR的中間結果可以“粘”在內存中,而不是必須導出來持久化到分布式文件系統中.
3.3HyBSPCloud對大數據的支持
本研究采用3種方案來改善HyBSPCloud對大數據的支持.
(1)利用開源分布式文件系統來存放輸入數據、輸出數據,允許計算的中間數據自動持久化到文件中,這是目前支持大數據處理最通用的方法.若待處理數據不用分布式文件系統支持,完全加載于分布式內存,會導致無法滿足海量數據的實際應用需求.開源分布式文件系統及其特點如表3所示.從開放性和成熟性來看,首選HDFS作為HyBSPCloud的文件系統.為支持大量并發訪問的應用,HyBSPCloud也支持PVFS作為數據存儲系統.

表3 開源分布式文件系統及其特點Table 3 Open source distributed file systems with their characteristics
(2)虛擬內存數據結構(vmstruct).HyBSPCloud提供應用運行時對vmstruct的源碼解釋支持.應用將vmstruct作為一般的全局數組來使用,但不同的是,vmstruct將大部分數據存放在外存,而只占用小部分內存堆空間,根據需要再進行新舊數據的替換.這種結構在一次性順序地操作少量數據的應用中,可以解決由于內存限制導致大數據應用不能執行的問題.
(3)網絡數據流(netdataflow).HyBSPCloud支持應用運行時訪問netdataflow對象,將其作為一個不斷流出或流入新數據的通道.數據的另一端點可以設置為持久化的文件、網絡信道.
在現有的集群環境下,增加硬件存儲容量并部署高性能的文件系統是解決并行大數據處理的基本方式.由于這種方式依靠文件系統的操作來訪問數據,因此時間開銷較大.若關于新型非易失存儲介質、大容量新型混合內存體系結構等的內存計算技術能取得關鍵性進展,則大數據的并行處理技術也會得到突破.
3.4實驗測試
為了檢驗所提出的兩層混合并行的可行性,本研究設計了一個混合并行的綜合實驗.假設兩個矩陣相乘C=A×B,且B的值已知,A的值需要通過分類統計數據集X得到.本例的一個應用解釋如下:某地區有若干個工廠,每個工廠生產一種以上產品;每個工廠生產每種產品的月產量的信息存放在數據集X中,通過X可以得到該工廠生產每種產品的年產量A;每種產品的單價和單位利潤存放在矩陣B中;求各工廠的總收入和總利潤,即C.
為實驗方便,假設A和B是浮點方陣,X中的值也默認為浮點數,X和B中的值都由隨機函數生成.實驗使用了如表4所示的硬件資源,程序采用HyBSPCloud并行編程庫來開發.

表4 硬件參數Table 4 Hardware parameters
所有物理機運行版本為ubuntu 12.04的64位操作系統,虛擬化軟件采用Xen hypervisor 4.1.2,客戶操作系統采用ubuntu 10.04.4的32位操作系統.
從Host1上申請2個虛擬機(virtual machine,VM),Host2和Host3分別申請一個VM,每個虛擬機的vCPU為4個.為了更好地反映硬件資源的利用情況,實驗中特別指定從特定物理機申請的虛擬機數量.
對于C=A×B的計算,有兩種BSP程序版本:①用4個VM,每個VM上用1個thread來計算,即進程級并行;②用4個VM,每個VM上用4個thread來計算,即進程和線程混合并行.
版本①和②代碼的不同點僅在于前者在每個VM上用直接法(單線程處理)計算子陣At×Bt(At,Bt分別是矩陣A和B的子陣),而后者在每個VM上把子陣At和Bt再分塊后用4個線程并行計算.版本②使用了表5中的函數來管理多線程.

表5 共享內存模型主要函數Table 5 Main operational functions of shared memory model
用上述兩種計算矩陣乘的BSP版本,分別進行規模2000×2000和4000×4000的實驗,運行時間如圖10所示.

圖1 0進程和線程混合并行的運行時間Fig.10 Running time of processes and hybrid parallel threads
上述計算A×B的BSP程序是完整計算C=A×B過程的一部分,該過程有以下3種版本.
(1)用MapReduce計算矩陣A的元素值,再用BSP計算A×B.
(2)調用BSP分塊計算A×B,在BSP超步中,當用到每個A子塊時,用MapReduce計算A子塊的元素值.
(3)調用MapReduce計算A′(A′為A的部分值),在每個Map步后,調用BSP計算C′= A′×B,再對C′進行加操作的Reduce,最終得到C.
通過對上述3種版本產生的矩陣C進行比較,最終結果是一致的.由實驗結果可以得出,兩層混合并行是可行的、方便易用的.混合并行的性能分析和比較將是下一步的研究內容.
4 結束語
本研究針對同一個大數據應用的異質并行計算問題,提出兩個層次上的混合并行方法.在執行單元層次的混合并行,即進程和線程的混合并行時,可以充分利用多核同構/異構硬件的計算資源,顯著加快數據處理速度,這種混合并行對于具有密集計算的應用效果明顯.計算模型層次的混合并行能適合應用的多樣異構處理模式,使開發和部署運行過程更自然簡潔.BSP 和MapReduce這兩種計算模型在同一個編程框架HyBSPCloud上的實現,表明在充分考慮模型之間并行計算的流程連續和動態數據傳遞的前提下,計算模型混合并行是可行的.
另外,本研究還提出了3種方案以改善HyBSPCloud對大數據應用的支持,包括用分布式文件系統來存放中間輸入/輸出數據、采用虛擬內存數據結構來解決內存限制、通過網絡數據流(netdataflow)來封裝流動的數據通道.目前,本研究主要關注BSP和MapReduce這兩種典型的大數據計算模型混合并行的可行性,下一步將進行這種混合方法的性能分析和性能優化技術研究,還將對其他計算模型的混合并行甚至統一并行模型的可能性進行探索.
[1]LYNCH C.Big data:how do your data grow?[J].Nature,2008,455(4):28-29.
[2]GOLDSTON D.Big data:data wrangling[J].Nature,2008,455(4):15.
[3]WANG S,WANG H J,QIN X P,et al.Architecting big data:challenges,studies and forecasts[J].Chinese Journal of Computers,2011,34(10):1741-1752.
[4]QIN X P,WANG H J,LI F R,et al.New landscape of data management technologies[J].Journal of Software,2013,24(2):175-197.
[5]ZHANG Y S,JIAO M,WANG Z W,et al.One-size-fits-all OLAP technique for big data analysis[J].Chinese Journal of Computers,2011,34(10):1936-1946.
[6]GONG X Q,JIN C Q,WANG X L,et al.Data-intensive science and engineering:requirements and challenges[J].Chinese Journal of Computers,2012,35(8):1563-1578.
[7]MA K,YANG B.Log-based change data capture from schema-free document stores using Map-Reduce[C]//2015InternationalConferenceonCloudTechnologiesandApplications (CloudTech).2015:1-6.
[8]JUNG G,GNANASAMBANDAM N,MUKHERjEE T.Synchronous parallel processing of bigdata[C]//2012 IEEE fifth International Conference on Cloud Computing.2012:811-818.
[9]LIU X,GAO W,HU Z Y.Hybrid parallel bundle adjustment for 3D scene reconstruction with massive points[J].Journal of Computer Science and Technology,2012,27(6):1269-1280.
[10]FEINBUBE F,SOBANIA J A,TR¨OGER P,et al.Light-weight programming of hybrid systems[J]. Parallel&Cloud Computing,2012,1(2):34-44.
[11]WANG P,MENG D,HAN J Z,et al.Transformer:a new paradigm for building data-parallel programming models[J].Micro IEEE,2010,30(4):55-64.
[12]PACE M F.BSP vs.MapReduce[J].Procedia Computer Science,2012,9:246-255.
[13]潘巍,李戰懷,伍賽,等.基于消息傳遞機制的MapReduce圖算法研究[J].計算機學報,2011,34(10):1768-1784.
[14]FEGARAS L.Supporting bulk synchronous parallelism in Map-Reduce queries[C]//High Performance Computing,Networking,Storage and Analysis(SCC).2012:1068-1077.
[15]QIN X P,WANG H J,DU X Y,et al.Big data analysis-competition and symbiosis of RDBMS and MapReduce[J].Journal of Software,2012,23(1):32-45.
[16]DING L L,XIN J C,WANG G R,et al.Efficient skyline query processing of massive data based on MapReduce[J].Chinese Journal of Computers,2011,34(10):1785-1796.
[17]VALIANT L G.A bridging model for parallel computation[J].Communication of the ACM,1990,33(8):103-111.
[18]MALEWICZ G,AUSTERN M H,BIK A J C,et al.Pregel:a system for large-scale graph processing[C]//Proceedings of the 2010 International Conference on Management of Data.2010:135-145.
[19]HAMA-a general BSP framework on top of Hadoop[EB/OL].[2015-10-20].http://hama. apache.org.
[20]AVERY C.Giraph:large-scale graph processing infrastructure on Hadoop[C]//Proceedings of the Hadoop Summit.2011:1-8.
[21]LIU X D,TONG W Q,FU Z R,et al.BSPCloud:a hybrid distributed-memory and sharedmemory programming model[J].International Journal of Grid and Distributed Computing,2013,6(1):87-98.
Multilevel hybrid parallel method for big data applications
HUANG Lei1,ZHI Xiaoli1,ZHENG Shengan2
(1.School of Computer Engineering and Science,Shanghai University,Shanghai 200444,China;2.Department of Computer Science and Engineering,Shanghai Jiao Tong University,Shanghai 200240,China)
Many large data applications require a variety of parallel data processing.This paper presents a two-layer hybrid parallel method,i.e.,hybrid parallel of execution units and hybrid parallel of computing model.By hybrid parallel of execution units on the same computing node.The computing power of infrastructure can be fully taped,and thus data processing performance can be improved.By integrating several calculation models into the same execution engine in a parallel way,diverse heterogeneous processing modes may be applied.Different hybrid parallel ways can meet different data and calculation characteristics,and meet different parallel objectives as well.This paper introduces the basic ideas of hybrid parallel methods,and describes main implementation mechanisms of hybrid parallelism.
hybrid parallelism;programming model;bulk synchronous parallel(BSP);MapReduce
TP 391
A
1007-2861(2016)01-0069-12
10.3969/j.issn.1007-2861.2015.04.017
2015-11-19
上海市科委科研計劃資助項目(15DZ1100305)
支小莉(1974—),女,副研究員,博士,研究方向為并行計算、軟件定義網絡. E-mail:xlzhi@mail.shu.edu.cn
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國外匯(2019年20期)2019-11-25 09:54:58
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
教育與職業(2014年7期)2014-01-21 02:35:04
計算機與網絡(2013年1期)2013-06-05 05:31:50
中華女子學院學報(2012年6期)2012-03-25 13:52:27
俄羅斯問題研究(2012年1期)2012-03-25 09:54:45
