基于加權(quán)相對距離的自由文本擊鍵特征認(rèn)證識別方法
2016-09-23 07:19:27宋夢玲胡曉勤
現(xiàn)代計(jì)算機(jī) 2016年4期
宋夢玲,胡曉勤
(四川大學(xué)計(jì)算機(jī)學(xué)院,成都 610065)
基于加權(quán)相對距離的自由文本擊鍵特征認(rèn)證識別方法
宋夢玲,胡曉勤
(四川大學(xué)計(jì)算機(jī)學(xué)院,成都610065)
加權(quán)相對距離;自由文本;擊鍵;特征識別;認(rèn)證
0 引言
本文描述的擊鍵特性的分析是根據(jù)擊鍵序列的檢測屬于異常入侵檢測范疇。收集不同用戶在QQ聊天中生成的擊鍵樣本,通過分析建立正常用戶的擊鍵序列模板,將訓(xùn)練樣本與測試樣本進(jìn)行匹配以檢測入侵是否發(fā)生。
本文在分析、比較擊鍵特性識別算法的基礎(chǔ)上,收集了大量的數(shù)據(jù)并進(jìn)行實(shí)驗(yàn)與分析。本文的實(shí)驗(yàn)是以雙鍵為基本鍵對進(jìn)行實(shí)驗(yàn)的[1-2]。在基于相對距離的算法上,為每對雙鍵的相對距離賦予不同權(quán)值,計(jì)算訓(xùn)練樣本與測試樣本的加權(quán)相對距離和。通常,同一個用戶的測試樣本與訓(xùn)練樣本的相似度越大,其加權(quán)相對距離和越小。反之,不同用戶的測試樣本與訓(xùn)練樣本的相似度越小,加權(quán)相對距離和越大,由此可以判斷該訓(xùn)練樣本是否屬于該用戶。
1 擊鍵動力學(xué)
擊鍵動力學(xué)識別分為靜態(tài)和動態(tài)擊鍵識別兩種。靜態(tài)擊鍵識別:Bergadano[3-4]所做的實(shí)驗(yàn)中,要求自愿者根據(jù)他們所提供的固定文本來擊鍵產(chǎn)生樣本來構(gòu)建用戶的模型,其樣本與被識別的輸入樣本是相同的文本[5]。
動態(tài)擊鍵識別:用戶按著自己的習(xí)慣、方式擊鍵產(chǎn)生的非固定樣本構(gòu)建模型就是動態(tài)擊鍵識別[6-7]。本文所提出的擊鍵特識別方法就是基于自由文本的動態(tài)擊鍵識別。
2 擊鍵時間
擊鍵可以分為單鍵、雙鍵、三鍵、四鍵,以及N鍵。研究證明,使用雙鍵作為擊鍵特征的區(qū)分度最好,特征最明顯。如圖1 所示:

圖1 雙鍵時間示意圖P:press R:release(visio繪制)
PR為按下一個鍵到釋放該鍵的時間間隔;PP為按下一個鍵到按下下一個鍵的時間間隔;RP為釋放一個鍵到按下下一個鍵的時間間隔;RR為釋放一個鍵到釋放下一個鍵的時間間隔。雙鍵組合的持續(xù)時間可以擴(kuò)展為N鍵組合。在本文中,我們將采用雙鍵的時間。
3 傳統(tǒng)的R方法[8]
文獻(xiàn)[3]和文獻(xiàn)[4]提出并完善了基于相對距離的擊鍵識別(即R方法)。與之相對的是采用絕對距離(擊鍵時間)衡量擊鍵樣本間的相似度與差異性。R方法的支持者認(rèn)為,擊鍵是一個持續(xù)的過程,擊鍵時間是一個絕對值。在這個過程中,用戶可能會受到外界或自身影響,將擊鍵時間的絕對值作為擊鍵特征存在不穩(wěn)定、偶然性等特征,難以衡量擊鍵樣本之間的真實(shí)差異性。實(shí)驗(yàn)證明,不同雙鍵按照時間長短排序的位置存在著某種穩(wěn)定關(guān)系[8],受外部因素影響較小,適于作為擊鍵特征,由此提出了R方法。
對于給定的兩數(shù)組V={a1,a2,…,ak},V'={a1',a2',…,ak'},維度均為K。定義亂序度為V和V相同元素位置的距離絕對值之和。例如,數(shù)組V={2,5,1,4,3},V’= {1,2,3,4,5},則V和V'的無序度為:|0-1|+|1-4|+|2-0|+| 3-3|+|4-2|=1+3+2+0+2=8。可知,當(dāng)數(shù)組V與V'排序完全相同時,無序度最小為0;反之,排序完全相反時,無序度最大,無序度的值如下:

因此,對于給定K個元素的數(shù)組來說,我們可以對其進(jìn)行歸一化,即歸一化的無序度=當(dāng)前無序度/最大無序度,顯然,歸一化無序度的取值范圍為[0,1]。
設(shè)有擊鍵樣本S1=classification和S2=authentication。它們共有的雙鍵有ic,ca,at,ti,,io,on這6對。其中 :S1={265,150,280,230,260,240},S2={320,220,200,150,190,210},將它們的值從小到大升序排列,如表1所示:
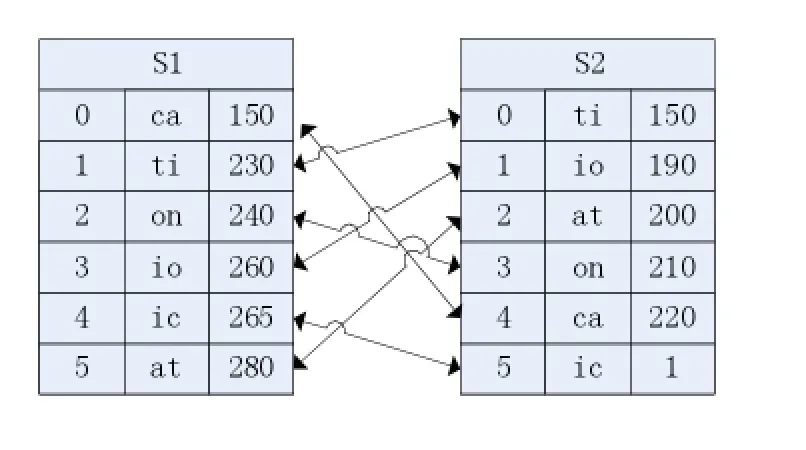
表1 樣本S1和S2雙鍵時間排列(排序后)
最大距離為二者間的最大無序度,即maxDistance(S1,S2)=62/2=18,則R距離(相對距離)=當(dāng)前距離/最大距離,即R(S1,S2)=d(S1,S2)/maxDistance(S1,S2)= 12/18=0.6666。
4 基于加權(quán)相對距離的特征識別方法
本方在R方法的基礎(chǔ)上對不同鍵對的相對距離進(jìn)行加權(quán),盡可能地縮同一用戶間的差異性,同時擴(kuò)大不同用戶間的差異。維護(hù)了樣本的穩(wěn)定性,并且具有更高的準(zhǔn)確識別度。
設(shè)有N個擊鍵時間值的有序擊鍵序列:測試數(shù)組S1={a1,a2,…,ai,…,an},訓(xùn)練數(shù)組S2={b1,b2,…,bi,…,bn}。S1和S2都被分為M組,每組雙鍵個數(shù)為N/M,每組賦予不同權(quán)值,為k1,k2,…,km。由于每對雙鍵的相對距離都賦予了權(quán)值,為與傳統(tǒng)的R方法進(jìn)行比較,將權(quán)值作歸一化處理。即:

本方法是比較位置索引值,因此它是關(guān)于符號序列之間的變化程度。改進(jìn)方法和示例如下:以擊鍵序列arithmetic為雙鍵樣本S1和S2,有9個雙鍵:ar,ri,it,th,hm,me,et,ti,ic。 S1={185,160,230,310,280,245,260,220,250},S2={210,195,230,190,290,235,270,220,255},單位均為ms。按擊鍵時間從小到大升序排列后,如表2所示。
R方法計(jì)算S1和S2之間的距離有:d(S1,S2)=|0-1|+|1-2|+|2-3|+|3-4|+|4-5|+|5-6|+|6-7|+|7-8|+|8-0|=1+ 1+1+1+1+1+1+1+8=16。
最大距離maxDistance(S1,S2)=(92-1)/2=40,則相對距離=距離/最大距離R(S1,S2)=d(S1,S2)/ maxDistance(S1,S2)=16/40=0.40。上例中,只有雙鍵th位置改變,導(dǎo)致其他雙鍵的相對位置改變,最終得到的相對距離和累加了所有雙鍵的位置差異,擴(kuò)大擊鍵樣本間的差異性,使得認(rèn)證效果變差。實(shí)際上,這兩個樣本間的差異性很小。

表2 樣本S1和S2雙鍵時間排列(排序后)
而加權(quán)相對距離的特征識別算法是將S1和S2適當(dāng)?shù)姆纸M,并賦予每組不同的權(quán)值。在本文實(shí)驗(yàn)中,提取的源數(shù)據(jù)是根據(jù)雙鍵頻率由大到小排列的,因此出現(xiàn)頻率高的雙鍵的權(quán)值大于出現(xiàn)頻率低的雙鍵的權(quán)值。經(jīng)過反復(fù)實(shí)驗(yàn),將S1和S2分為3組,每組3個雙鍵,每組的權(quán)值分別為3,2.5,1.25時,所得到的認(rèn)證效果最佳,對權(quán)值作歸一化處理:k=(k1*3+k2*3+k3*3)/ 9=2.25。d(S1,S2)w=3*|0-1|+3*|1-2|+3*|2-3|+2.5*|3-4|+ 2.5*|4-5|+2.5*|5-6|+1.25*|6-7|+1.25*|7-8|+1.25*|8-0|= 3+3+3+2.5+2.5+2.5+1.25+1.25+10=29;d(S1,S2)w'=d(S1,S2)w/k=29/2.25=12.9。
最大距離maxDistance(S1,S2)=(92-1)/2=40,則加權(quán)相對距離=距離/最大距離,即Rw(S1,S2)=d(S1,S2)w'/ maxDistance(S1,S2)=12.9/40=0.32<R(S1,S2)=0.40。可見加權(quán)相對距離算法優(yōu)于傳統(tǒng)R方法。
再看雙鍵僅發(fā)生微弱變化時的情況,設(shè)有雙鍵樣本S3和S4,有9個雙鍵值:ar,ri,it,th,hm,me,et,ti,ic。其中,S3={185,160,230,310,280,245,260,220,250},S4={195,190,220,290,270,235,255,210,230},單位均為ms。如表3所示。
可以看出,樣本S3和S4的順序大致相同,僅雙鍵ic和et的位置發(fā)生了交換。
按傳統(tǒng)的R方法計(jì)算S1和S2之間的距離,有:d(S1,S2)=|0-0|+|1-1|+|2-2|+|3-3|+|4-4|+|5-6|+|6-5|+|7-7|+|8-8|=0+0+0+0+0+1+1+0+0=2。

表3 樣本S3和S4雙鍵時間排列(排列后)
最大距離maxDistance(S1,S2)=(92-1)/2=40,則相對距離=距離/最大距離,即R(S1,S2)=d(S1,S2)/max Distance(S1,S2)=2/40=0.05。這里只有me和ic的位置發(fā)生交換,其余雙鍵的位置沒有改變,最終相對距離只累計(jì)了me和ic的位置差異。
同樣,將升序排列后的擊鍵樣本S3作為測試數(shù)組分為3組,由此可得:d(S1,S2)w=3*0+3*0+3*0+2.5*0+2.5*0+ 2.5*1+1.25*1+1.25*0+1.25*0=0+0+0+0+0+2.5+1.25+0+0= 3.75;d(S1,S2)w'=d(S1,S2)w/k=3.75/2.25=1.67<2。
可見,無論雙鍵的擊鍵時間位置發(fā)生較大改變還是微弱改變,本方法得到的歸一化距離比傳統(tǒng)的R方法小。即絕對擊鍵時間的變化不會較大的影響本方法對擊鍵樣本間相似度的計(jì)算,該方法能夠得到較小的歸一化距離。
假設(shè)存在一個新的自稱屬于用戶Uk的擊鍵樣本X,認(rèn)證的目的是判定樣本X是屬于用戶Uk還是樣本集里其他用戶的,也或者都不屬于樣本集里任一用戶的。分別計(jì)算樣本X與Uk之間的相對距離d(S1,S2)w'。
5 實(shí)驗(yàn)及結(jié)論
5.1實(shí)驗(yàn)數(shù)據(jù)
本文實(shí)驗(yàn)所采用的數(shù)據(jù)全是源于QQ聊天過程中產(chǎn)生的。歷時半年,我們選取10位志愿者參加作為合法用戶,另外15個志愿者作為攻擊者。經(jīng)過預(yù)處理,選取了頻率較高的30對雙鍵,并截取了每位合法用戶的20組雙鍵數(shù)據(jù),最終得到10×20=200個認(rèn)證次數(shù)。而對于攻擊數(shù)據(jù),10個合法用戶的每組數(shù)據(jù)都將會作為攻擊數(shù)據(jù)去攻擊除自己以外的所有數(shù)據(jù),攻擊次數(shù)為200×9×20=36000次。15個攻擊者都有一組攻擊數(shù)據(jù),攻擊10個合法用戶,攻擊次數(shù)為15×10×20=3000次。最終的攻擊次數(shù)為36000+3000=39000次。如表4所示:

表4 實(shí)驗(yàn)數(shù)據(jù)
5.2實(shí)驗(yàn)數(shù)據(jù)預(yù)處理
本實(shí)驗(yàn)所做的預(yù)處理是針對于擊鍵時間的篩選、鍵對的選取、數(shù)據(jù)的最終截取這三部分組成。
實(shí)驗(yàn)所取擊鍵時間值得范圍是0<PP<500ms。統(tǒng)計(jì)分析所有志愿者的雙鍵次數(shù)和,降序排列。實(shí)驗(yàn)最終選取了次數(shù)總和最多的前30對雙鍵。為了確保選取的擊鍵時間值的個異性(即不單純的重復(fù)時間值來構(gòu)造擊鍵序列),我們將所有用戶中出現(xiàn)次數(shù)最少那組雙鍵作為基準(zhǔn),超過該基準(zhǔn)的所有擊鍵時間值被舍棄,實(shí)驗(yàn)中以雙鍵次數(shù)最小值20作為最終數(shù)據(jù)組數(shù)。而本文提出的權(quán)值k1>k2>k3,是根據(jù)實(shí)驗(yàn)截取的雙鍵序列是根據(jù)雙鍵出現(xiàn)的頻率由高到低排列的,經(jīng)過大量的實(shí)驗(yàn)分析,我們選取了權(quán)值組合{3,2.5,1.25},所得到的實(shí)驗(yàn)結(jié)果最優(yōu)。
5.3實(shí)驗(yàn)結(jié)果
實(shí)驗(yàn)得到了不同的認(rèn)證結(jié)果,并且在給定相同數(shù)量的雙鍵的情況下,基于加權(quán)相對距離的特征識別優(yōu)于R方法。FRR和FAR的實(shí)驗(yàn)結(jié)果如表5所示:

表5 本方法與R方法實(shí)驗(yàn)結(jié)果對比
由圖可得:本方法的FRR和FAR分別提高了14.29%和7.42%。此外,我們還基于本方法和R方法研究了實(shí)驗(yàn)中用戶的數(shù)量、擊鍵序列組數(shù)以及每組擊鍵序列中雙鍵的數(shù)量對分類錯誤率的影響,對比關(guān)系如圖2 、3、4所示

圖2 用戶數(shù)量與認(rèn)證結(jié)果的關(guān)系對比圖

圖3 擊鍵序列組數(shù)與認(rèn)證結(jié)果的關(guān)系對比圖

圖4 雙鍵個數(shù)與認(rèn)證結(jié)果的關(guān)系對比圖
5.4實(shí)驗(yàn)結(jié)果分析
從表5中可知,對于本方法,通過對排序后的擊鍵序列賦予不同的權(quán)值,得到的認(rèn)證結(jié)果FRR和FAR皆優(yōu)于R方法。由圖2 、圖3 、圖4 可知,本方法較R方法對擊鍵序列的認(rèn)證效果更理想。總體而言,隨著擊鍵個數(shù)的增加,F(xiàn)RR越來越低。FAR都隨著用戶數(shù)量、擊鍵序列組數(shù)、擊鍵個數(shù)的增加而減小。從圖2 、圖3 可以看出,當(dāng)用戶數(shù)量、擊鍵序列組數(shù)到達(dá)一定數(shù)量后,F(xiàn)AR趨于0。由圖4 可知,當(dāng)擊鍵個數(shù)足夠大時,F(xiàn)RR和FAR都趨于0。
因此,我們可以得出結(jié)論:本方法的認(rèn)證結(jié)果比R方法更高、識別準(zhǔn)確度更好。
6 結(jié)語
本文提出了一種基于加權(quán)相對距離的擊鍵特征識別方法。與R方法相比,擊鍵時間值的驟變或微變,本方法的歸一化距離都小于R方法的,因此本方法縮小了R方法由于某一擊鍵時間值驟變引起的相對距離的累加問題,更好地反映了用戶擊鍵特性的差異。實(shí)驗(yàn)證明,本方法的正確率和識別度均高于R方法,并研究了用戶數(shù)量、擊鍵序列組數(shù)和雙鍵數(shù)量對本方法FRR和 FAR的影響。
由于實(shí)驗(yàn)條件和時間所限,本文忽略了外部條件的影響。未來的實(shí)驗(yàn)中,可以針對三鍵、四鍵…N鍵等多種組合,甚至是環(huán)境、鍵盤燈外在因素對擊鍵特征識別的影響作更深入的研究。
[1]Daniele Gunetti,Claudia Picardi,Giancarlo Ruffo.Keystroke Analysis of Different Languages:A Case Study[C].The 6th International Symposium on Intelligent Data Analysis,Madrid,Spain,September 8-10,2005:133-144.
[2]Daniele Gunetti,Claudia Picardi,Giancarlo Ruffo.Dealing with Different Languages and Old Profiles in Keystroke Analysis of Free Text[C].The 9th Congress of the Italian Association for Artificial Intelligence,Milan,Italy,September 21-23,2005.3673:347-358
[3]Francesco Bergadano,Daniele Gunetti,Claudia Picardi.User Authentication through Keystroke Dynamics1.ACM Transactions on Information and System Security,Vol.5,No.4,November 2002:367-397.
[4]Francesco Bergadano,Daniele Gunetti,Claudia Picardi.Identity Verification through Dynamic Keystroke Analysis.Intelligent Data Analysis.Vol.7,No.5,January 2003:469-496.
[5]Mariusz Rybnik,Piotr Panasiuk,Khalid Saeed,User Authentication with Keystroke Dynamics using Fixed Text.International Conference on Biometrics and Kansei Engineering,DOI 10.1109.2009:70-79
[6]Giot,Romain;Dorizzi,Bernadette;Rosenberger,Christophe.Analysis of Template Update Strategies for Keystroke Dynamics.IEEE Symposium Series on Computational Intelligence(SSCI 2011),2011:21-28
[7]M.Rybnik,M.Tabedzki,K.Saeed.A Keystroke Dynamics Based System for User Identification.Computer Information Systems and Industrial Management Applications-CISIM 2008,2008:225-230.
[8]Daniele Gunetti,Claudia Picardi.Keystroke Analysis of Free Text[J].ACM Transactions on Information and System Security,Vol.8, No.3,August 2005:312-347
According to the keystroke characteristics authentication and recognition method of free text based on a relative distance,which named method R,proposes a keystroke characteristics authentication and recognition method of free text based on the weighted relative Distance. Through collecting keystrokes of free text when users used QQ chat,analyses the keystroke characteristics of each user,extracts the information of double key,calculate weighted distance,normalized processing and authentication judgment.And then calculates the data to get FRR and FAR.Experiments prove that FRR and FAR of this method is less than that of method R,and get a higher recognition accuracy. Keywords:
Weighted Relative Distance;Free Text;Keystroke;Characteristics Recognition;Authentication
Keystroke Characteristics Authentication and Recognition Method of Free Text Based on the Weighted Relative Distance
SONG Meng-ling,HU-Xiao-qin
(College of Computer Science,Sichuan University,Chengdu 610065)
2015-12-11
2016-01-18
基于相對距離的自由文本擊鍵特征認(rèn)證識別方法(即R方法),提出一種基于加權(quán)相對距離的自由文本擊鍵特征認(rèn)證識別方法。通過收集用戶在QQ聊天過程中產(chǎn)生的擊鍵自由文本數(shù)據(jù),對用戶的擊鍵特性進(jìn)行分析,提取其中的雙鍵數(shù)據(jù)信息,計(jì)算加權(quán)距離、歸一化處理及認(rèn)證判斷。分別計(jì)算FRR和FAR。實(shí)驗(yàn)證明文中所用方法的FRR和FAR都低于R方法,識別準(zhǔn)確度更好。
宋夢玲(1990-),四川眉山人,碩士研究生,研究方向?yàn)橛?jì)算機(jī)網(wǎng)絡(luò)與安全
胡曉勤(1977-),男,四川內(nèi)江人,博士,講師,研究方向?yàn)樾畔踩?/p>
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
商用汽車(2016年11期)2016-12-19 01:20:16
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
