基于LDA和SVM的中文文本分類研究
2016-09-24 01:31:29宋鈺婷徐德華同濟大學經濟與管理學院上海200092
現代計算機 2016年5期
宋鈺婷,徐德華(同濟大學經濟與管理學院,上海 200092)
基于LDA和SVM的中文文本分類研究
宋鈺婷,徐德華
(同濟大學經濟與管理學院,上海200092)
0 引言
在龐大的網絡中,大多數信息是以文本形式進行存儲的,文本自動分類作為重要的文本挖掘方法,成為目前機器學習研究的一個重點。文本自動分類的研究主要包括三個基本步驟:文本預處理、特征提取和特征權重計算、分類器構造等[1]。
特征空間的高維度是文本分類的一個重要問題,而特征提取是解決特征維度高和稀疏性的關鍵途徑[2]。因此,本文著重改進特征提取算法。特征提取方法主要有以下四種:文檔頻率(Document Frequency,DF)、互信息(Mutual Information,MI)、信息增益(Information Gain, IG)和卡方統計(CHI)。四種特征提取方法都各有優劣,其中主要在于這幾種方法對于低頻詞過度倚重,忽視了詞與文檔自身的關系[3]。本文選擇卡方統計特征提取方法作為主要研究對象之一。同時,通過LDA(Latent Dirichlet Allocation,LDA)可以解決傳統的文本分類的不足,能夠從語義出發考慮相似性的度量。并且,支持向量機(Support Vector Machine,SVM)能夠處理高維數據,降低稀疏性的影響[4],是較為合適的文本分類器。因此,本文從語義出發,提出LDA和SVM相結合的文本分類算法,將LDA與卡方統計方法相結合,并與其他三種特征提取方法進行對比,以解決低頻詞問題,最后通過SVM進行分類,實驗結果證明該算法能夠提高分類精度和分類效果。
1 文本分類相關研究
1.1特征提取
文本分類是指將文檔自動分組到預定義的類別中。文本通過文本分類的處理后能夠提高的檢索和使用效率。傳統的文本分類直接通過文本數據空間進行表示,但是被抓取的文本通常依賴于高維度的特征空間,這也是文本分類的一個挑戰[6]。特征提取是一種降維的有效方法。特征提取是指從原始數據中提取出有效的特征詞,用提取的特征可以表示分類文本。Rogati 和Yang[7]等人對幾種常見的特征提取方法進行改進,實驗證明改進后的MI、IG和CHI分類效果有一定的提高。以下三種特征提取方法將在本文中進行對比實驗。
(1)互信息
互信息是指用來衡量某個特征和特定類別的相關性,計算出特征詞t和類別C的相關聯的信息量。互信息沒有考慮類間分布和類內出現的頻數等因素,劉海峰等人[8]在此基礎上引入特征項的頻數信息,提高了特征提取的準確率。
(2)信息增益
信息增益是指某個特征詞在整個文本分類系統中存在與否的信息量的差值,即指該特征文本分類系統帶來的信息量。信息增益缺乏對于特征項詞頻的考慮,劉慶和[9]等人綜合考慮頻度、分散度和集中度對IG進行了改進,提高了其分類精度。
(3)卡方統計
卡方統計的特征選擇方法常常用于檢測兩個事件的獨立性,可以用來度量詞項t與類別C之間的相關程度,兩者之間關系類似于具有一維自由度的Z分布。卡方統計忽略了單一文檔中的出現次數,僅僅從統計特征的角度進行特征提取。針對此問題,裴英博等人[10]通過去除特征項與類別負相關的情況,考慮頻度等因素,改進了卡方統計算法,分類效果得到一定程度的提高。
以上三種特征提取方法均僅考慮特征候選詞出現的文檔數,過度倚重低頻詞,其改進方法也是通過結合頻度等因素。Basu等人[11]通過實驗證明了傳統的特征提取方法在處理詞和文檔本身關系上有很大的不足。因此,在此基礎上,本文從語義角度,提出結合LDA對傳統卡方統計算法進行改進。
1.2LDA主題模型
LDA模型是由Blei等人在2003年首次提出,也被稱為三層貝葉斯概率模型,包含詞、主題和文檔結構[12]。
它將一篇文檔看作詞向量的集合,其生成過程如下:首先對于一篇文檔d,文檔與主題滿足一個多項式分布,主題與詞匯表中的詞也滿足一個多項式分布,這兩個多項式分布分別帶有超參數α和B的狄利克雷先驗分布。這樣,對于一篇文檔的構成,可以看成是,首先從文檔主題分布θ中抽取一個主題,然后從抽取到的主題所對應的詞分布?中抽取一個詞,重復上述過程N次,即可以構成一篇含有N個詞的文章。其概率模型公式如公式(1)所示。

通過LDA,即可以獲得詞在主題上的概率分布(公式2),以及文章在主題上的概率分布(公式3),其中K表示主題數,Cwk表示詞w被賦予主題k的次數,Cdk表示文檔d被賦予主題k的次數。


1.3文本表示方法
在提取特征詞后,需要將文檔用所提取的特征詞來表示。向量空間模型(VSM)是使用較多且效果較好的表示方法之一。在該模型中,文檔空間被看作是由一組正交向量組成的向量空間。若該空間的維數為n,則每個文檔d可被表示為一個實例特征向量d?={w1,w2,…,wn}。wn指第n個詞在文檔d中的權重。
本文利用TF-IDF公式來計算詞的權重。見公式(4)。

其中tfji指的是第i個詞在文檔j中出現的頻數,dfi指的是包含第i個詞的文檔數,N指所有文檔總數。
1.4文本分類器
隨著文本檢索和分類的需求迅速增長,文本自動化分類的研究成果發展迅速。如今,已經有相當多的數據分類方法和機器學習技術被應用到文本分類當中,其中包括支持向量機 (SVM)、貝葉斯算法、K最近鄰(KNN)、決策樹等分類算法[13]。
支持向量機[14]是由Joachims首先運用到文本分類中,和其他分類算法相比,SVM具有較好的穩定性和分類效果[15]。本文采用SVM構建分類器。
2 基于LDA和SVM的文本分類
結合LDA和SVM的中文文本分類流程如下,如圖1所示:

圖1 文本分類流程圖
2.1文本預處理
本分詞作為中文文本分類的文本預處理重要的步驟,相比英文文本,中文文本分類需要對沒有空格進行區分的中文文本進行分詞處理。本文選擇的是由張華平博士帶領團隊研制的ICTCLAS漢語分詞系統。
首先將文本分為訓練集和測試集。然后對文本進行分詞、去停止詞等操作,并將處理好的數據按照一定格式進行存儲。
2.2結合LDA主題模型的特征提取
卡方統計、信息增益和互信息都沒有從語義的角度考慮,僅僅從統計的角度來提取特征詞,本文將以卡方統計為例,詳細描述如何通過結合主題模型,從語義的角度提取特征詞。
然后選擇形容詞和名詞作為特征詞的候選詞語,利用卡方公式,對某一類別下,例如財經類,計算出該類別下所有候選特征詞的卡方值,例如“股票”在財經類別下的卡方值。其計算公式見公式(5):
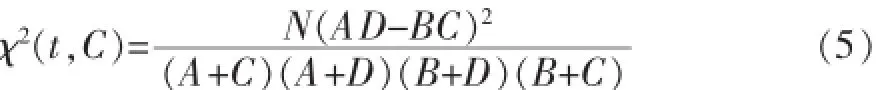
式中,A表示包含詞項t又屬于分類C的文檔數目,B表示包含詞項t不屬于分類C的文檔數目,C表示不包含詞項t但屬于分類C的文檔數目,D表示既不包含詞項t又不屬于分類C的文檔數目。N代表所有文檔總數。
接著,選擇該類下包含該詞次數最多的文檔,例如在財經類下,包含“股票”一詞最多的文檔為Di,采用公式(6)計算“股票”與該文檔Di在主題分布下的關聯度。某一詞語和某文本的主題關聯度,即該詞能在主題上代表該文本的程度。如果出現多個包含該詞最大數目相同的文本,則選擇該詞與文本關聯度最大的值,作為該詞與該文本的關聯度。
接著,把所有包含詞Ti的文檔聚為該類下的一個子類,稱為詞子類C?,其他不包含該詞的文檔稱為非Ti詞子類。對于詞的關系,可以用剛剛算出的詞與包含該詞次數最多文檔的關聯度近似表示。

那么,詞Ti與類C的主題關聯性即可表示為公式(7)。
最后,將語義特征與統計特征(如互信息、信息增益、卡方統計等)相結合,例如結合X2值以及基于潛在語義主題的sim值,得出最終X2,如公式(8)所示。
最后根據這個結果,找出排名在前即特征值較高的詞,作為某一分類下的特征詞。
2.3特征權重計算及分類模型
對于特征權重計算,本文仍然是采用傳統的TFIDF值來表示特征詞的權重,從而將文檔表示為一組特征向量。
在選出特征詞,并計算出權重之后,本文采用LIBSVM算法進行文本分類。本文采用的是SVM分類器模型,并將文檔的輸入形式表示為:類別C特征詞1編號:特征詞1權重特征詞2編號:特征詞2權重…其核函數選取的是徑向基內核(RBF)。其中特征詞序號來自于選出的所有特征詞的集合,特征值為TF-IDF計算得到的值。LIBSVM讀取訓練數據得到訓練模型,并對測試集進行分類預測,最終得到分類準確率。
3 實驗結果及分析
為了進一步考察改進后方法的效果及效率,本文進行了如下實驗。
3.1實驗收據
本實驗使用的是搜狗實驗室中文新聞語料庫,總共有8個分類,每個分類下有1990篇文檔,其中1590篇用作訓練集,400篇用作測試集。如表1所示。

表1 實驗數據訓練集測試集及類別分布情況
3.2評價指標
文本分類中普遍使用的性能評估指標有:查全率R(Recall)和查準率P(Precision),其中查全率為類別C下正確分類文檔數與C類測試文檔總數之比,查準率為正確分類文檔數與被分類器識別為C類的文檔數之比。
F-measure,用來衡量的是查全率和查準率的綜合,以及對它們的偏向程度。
3.3實驗結果分析
本實驗將LDA分別與卡方統計、互信息和信息增益進行結合,利用改進后的特征提取方法提取特征詞并將卡方統計與其他兩種特征提取方法的分類效果進行比較。
(1)LDA主題數K的比較
在訓練LDA主題模型時,由于需要先給出主題K的值,因此實驗分別選擇了主題數為20,30,40,60,80,100,120等進行比較,計算出不同方法與LDA結合時的分類性能,圖中橫坐標為不同的主題數目,縱坐標為F值,選取的特征詞個數為8000,如圖2所示。

圖2 特征詞個數為8000,不同主題數的分類結果

圖3 主題數為60,不同特征值維數的分類結果
從圖2中可以看出隨著主題數目的增長,分類性能雖然越來越好,但效果變化并不大。而隨著主題數目的增長,訓練LDA模型所需要的時間卻越來越長,即消耗很大的代價,卻只得到了一點提高。因此綜合考慮,本文選取60作為主題數目。
(2)特征詞數目的比較
為了考察選取的特征詞數目對文本分類效果的影響,本文選取了 400,1600,3200,4000,6400,8000,9600,11200,128000,16000個特征詞進行比較,分別采用chi、chi+lda、ig、ig+lda、mi、mi+lda得出文本分類的性能,見圖4.圖中橫坐標為特征詞個數,縱坐標為F值,選取的LDA主題數為60。
從上圖3可以看出,本文提出的結合LDA的特征提取算法均比原來的方法分類效果好;另外隨著特征詞個數的增多,每一種方法的分類性能也有提高,但是當特征詞個數過多時,除了會導致維度災難,也可能會因為過多無用的詞或分類特征不明顯的詞被當作特征詞,從而導致分類性能下降。所以在分析比較三種方法分別與LDA結合后的性能時,選取8000作為特征詞的數目。
(3)三種方法與LDA結合的比較
本實驗選擇主題數K為60,特征詞數為8000,分別計算出chi、chi+lda、ig、ig+lda、mi、mi+lda在不同分類下的查準率、查全率以及F值,實驗結果如下表2、3、4所示。

表2 CHI和LDA結合分類結果

表3 IG和LDA結合分類結果

表4 MI和LDA結合分類結果
從上面三個表中可以看出,三種特征提取方法在與LDA主題模型結合后的分類效果都有一定程度的提高,在不同分類下均能有3%到6%的提高。特別是與CHI結合時分類效果較明顯。因為CHI在選取特征詞時傾向于選取那些詞頻相對較低的詞語,而這些詞在某些分類中并不能很好的代表該類下的特征詞,在與LDA結合后,由于LDA從語義的角度計算詞的權重,一定程度上能夠很好地改善CHI低頻詞的選取,從而提高分類的性能。
4 結語
文本分類涉及到文本表示、相似度計算和算法決策等多種復雜的技術,特征選擇在文本分類中具有重要作用。本文研究并改進了傳統的特征選擇方法,結合LDA主題模型計算出詞和文檔的語義關系,避免了低頻詞的夸大處理,實驗結果表明提出的方法對分類效果提高是有效的,卡方統計、信息增益、互信息等結合LDA后分類效果都有明顯提高。其中卡方統計的分類準確率提高較為明顯。下一步的研究方向是針對不同的特征提取方法分別設計出不同的與LDA結合的算法,以更好地利用LDA進行文本分類;同時在進行特征值計算時,也可以結合LDA主題信息計算。
[1]Dash M,Liu H.Feature Selection for Classification[J].Intelligent Data Analysis,1997,1(1):131-156.
[2]Yang Y,Pedersen J O.A Comparative Study on Feature Selection in Text Categorization[C].ICML.1997,97:412-420.
[3]代六玲,黃河燕,陳肇雄.中文文本分類中特征抽取方法的比較研究[J].中文信息學報,2004,18(1):26-32.
[4]李志清.基于LDA主題特征的微博轉發預測[J].情報雜志,2015,34(9):158-162.
[5]李鋒剛,梁鈺.基于LDA-WSVM模型的文本分類研究[J].計算機應用研究,2015,32(1):21-25.
[6]Wang Z,Qian X.Text Categorization Based on LDA and SVM[C].Computer Science and Software Engineering,2008 International Conference on.IEEE,2008,1:674-677.
[7]Rogati M,Yang Y.High-Performing Feature Selection for Text Classification[C].Proceedings of the Eleventh International Conference on Information and Knowledge Management.ACM,2002:659-661.
[8]劉海峰,姚澤清,蘇展.基于詞頻的優化互信息文本特征選擇方法[J].計算機工程,2014,40(7):179-182.
[9]劉慶河,梁正友.一種基于信息增益的特征優化選擇方法[J].計算機工程與應用,2011,47(12):130-134.
[10]裴英博,劉曉霞.文本分類中改進型 CHI特征選擇方法的研究[J].計算機工程與應用,2011,47(4).
[11]Basu T,Murthy C A.Effective Text Classification by a Supervised Feature Selection Approach[C].Data Mining Workshops(ICDMW),2012 IEEE 12th International Conference on.IEEE,2012:918-925.
[12]Blei D M,Ng A Y,Jordan M I.Latent Dirichlet Allocation[J].the Journal of Machine Learning Research,2003,3:993-1022.
[13]Sebastiani F.Machine learning in Automated Text Categorization[J].ACM Computing Surveys(CSUR),2002,34(1):1-47.
[14]Chang C C,Lin C J.LIBSVM:A Library for Support Vector Machines[J].ACM Transactions on Intelligent Systems and Technology(TIST),2011,2(3):27.
[15]Joachims T.A Support Vector Method for Multivariate Performance Measures[C].Proceedings of the 22nd International Conference onMachine learning.ACM,2005:377-384.
LDA;CHI;Text Classification;SVM
Research on Chinese Text Classification Based on LDA and SVM
SONG Yu-ting,XU De-hua
(School of Economics and Management,Tongji University,Shanghai 200092)
1007-1423(2016)05-0018-06
10.3969/j.issn.1007-1423.2016.05.004
宋鈺婷(1991-),女,江蘇泰州人,碩士研究生,研究方向為信息管理與信息系統
2016-01-07
2016-02-18
針對中文文本分類中特征提取的語義缺失和低頻詞問題,提出一種基于LDA和SVM的中文文本分類算法,首先將LDA與卡方統計特征提取算法結合,根據計算結果得到Top k個指定數目的詞項作為特征詞,使用SVM進行分類,并與互信息、信息增益進行對比,結果分析顯示與主題模型相結合的卡方統計特征提取方法有更高的分類精度。
LDA;卡方統計;文本分類;SVM
徐德華,男,副教授,碩士生導師,研究方位為管理信息系統、電子商務
Against the Chinese text classification feature extraction of semantic loss and low frequency words,proposes a text classification algorithm based on LDA and SVM,which describes CHI feature extraction method combining LDA,according to the results obtained Top k items of specified number of lexical items as feature words,uses SVM classification to realize text classification,compares respectively with mutual information and information gain.The results of the analysis proves that combining CHI feature extraction methods with the topic model have higher classification accuracy.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
