基于圖像嵌入空間集成學習的圖像分類
2016-11-18 07:45:32岳占峰
中國傳媒科技 2016年9期
■文/岳占峰 湯 豐
基于圖像嵌入空間集成學習的圖像分類
■文/岳占峰湯豐
針對物體分類任務中同類物體的類內多樣性,提出了子類的概念。通過構造圖像嵌入空間,學習每一幅圖像中有判別力的局部特征組合,隱式地揭示了不同子類的特性。在AdaBoost框架下,最具代表性的子類特性被組合形成物體分類器。進一步地引入了基于Gist特征的場景分類器,用來考慮物體在圖像中的上下文信息。兩種分類器通過邊緣最大化準則進行融合。在標準數據庫上的實驗證明了本文提出的算法有效性。
圖像分類;圖像嵌入空間
引言
物體分類(Object Categorization)是近年來計算機視覺和多媒體領域的一個研究熱點,其研究對于圖像管理、圖像檢索和圖像內容理解都有著重要的意義。問題主要的困難在于,由于存在視角變化、尺度變化和遮擋等因素的影響,同類的物體間存在較大的類內變化。
基于局部特征聚類形成的視覺詞典(Visual Vocabulary):Zhang[1]提出用視覺單詞的出現頻率直方圖來表示圖像,圖像之間相似度用2χ核或者EMD(Earth Mover’s Distance)核度量,然后使用SVM作為分類器。Grauman[2]引入多分辨率思想,提出了基于層級聚類的金字塔匹配核(Pyramid Match Kernel,PMK),允許兩幅圖像的視覺單詞的出現次數直方圖在不同分辨率下進行多次匹配,并賦予不同的權重。在PMK的基礎上,Lazebnik[3]提出空間金字塔匹配(Spatial Pyramid Match,SPM)在匹配特征點時考慮局部特征在圖像上的絕對位置信息。Ling[5]則改進了Savarese[4]提出的視覺單詞相關圖(Correlogram),考慮局部特征在圖像空間中分布的相對位置關系。
基于視覺單詞的好處是降低數據存儲量,便于局部特征的索引。但由于在聚類過程中引入的量化誤差會在某種程度上降低特征的判別力,一部分研究者直接基于原始特征訓練模型。Liu[6]使用混合高斯模型(Gaussian Mixture Model,GMM)對每幅圖像中的局部特征建模,兩幅圖像之間的相似度就是兩個GMM分布的相似度。Zhang[7]尋找一幅圖像中的點到另外一幅圖像中最相似的點構成的點對,并用所有點對的平均距離度量兩幅圖像的相似度。而Lyu[8]在計算特征點之間相似度時進一步考慮了這兩個點在圖像空間上鄰域的信息。
以上的方法中存在著兩個共同的問題:1)認為每一個特征點的作用是一樣的,沒有考慮不同特征點具有不同的判別力;2)在設計分類器的過程中沒有充分考慮類內的多樣性。
本文認為一個物體類可以看成由多個子類構成。針對這種情況,從特征構造出發,提出了圖像嵌入空間,用來學習得到一幅圖像中有判別力的局部特征的組合模式,這種組合模式可以認為隱式的對應某一個子類。在AdaBoost框架下,代表不同子類的有判別力的組合模式被挑選出來構成最終的物體分類器,可以有效提升圖像分類的精度。
1.基于圖像嵌入空間的分類模型
基于局部特征,物體類類內的多樣性表現為:對同一個物體類中的圖像很難找到一組公共的有判別力的局部特征。這種多樣性的產生既源于物體類自身的特性,也與圖像的拍攝視角、尺度等外部因素有關。為了應對這種多樣性,本文引入了子類的概念對物體類進行細分,并認為每一個子類中的圖像都共有一組有判別力的局部特征。
在具體的算法實現中,我們沒有顯示的把圖像集劃分成不同的子類。事實上,從另外一個角度考慮,因為每一幅圖像都屬于某一個子類,所以一幅圖像中有判別力的特征組合模式也反映了其所在子類的特點。基于這樣的思想,本節首先提出了圖像嵌入空間的表示方法,然后學習每幅圖像有判別力的特征組合,最后,AdaBoost用來挑選有代表性的特征組合模式(子類)通過集成學習構成強分類器。
1.1圖像嵌入空間
定義圖像集合為I,對每一幅圖像提取局部特征,不考慮特征點的空間位置信息,圖像i被表示為一個特征點集合xi:xi={fi,j|j=1,2,…,ni}
其中fi,j是圖像i中的第j個局部特征,ni為特征點的個數。
以圖像~i中的每一個局部特征為基,構造一個n~i維的圖像嵌入空間R~i,文獻[9]中提出的最可能因素(Most-Likely-Cause)估計子被用來定義圖像i到嵌入空間R~i的映射關系,如下式:
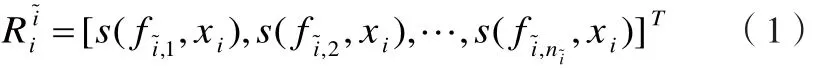
1.2線性加權支持向量機
如圖1所示,通過正負樣本在嵌入空間中的分布可以學習一幅圖像中有判別力的局部特征組合模式,這種學習在本文中是通過線性加權支持向量機來實現的。相比其他學習方法,線性支持向量機訓練速度較快,且對噪聲有較好的魯棒性。假定共有N個訓練樣本,包括N+個正樣本和N-個負樣本。因為只關心正樣本中有判別力的特征模式,所以僅僅對正樣本構造嵌入空間并學習,其形式化如(2):
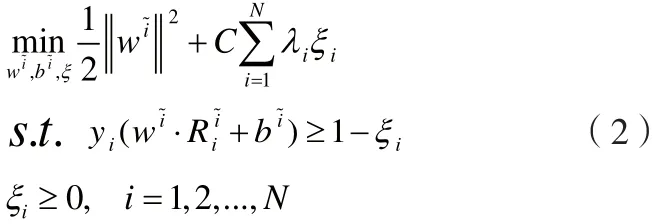
其中w~i表示是在基于圖像~i的嵌入空間中學習的分類面,λi為樣本i的權重,權重越大的樣本被錯分后的懲罰越大,樣本的權重將通過AdaBoost算法中動態調整。
1.3基于嵌入空間的分類器
因為每一個嵌入空間中的分類器可以認為對應著某一個子類,在AdaBoost的框架下,這些分類器被作為弱分類器組合成最終的物體分類器。基于每個嵌入空間~i的若分類器h~i為:
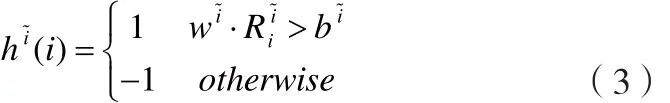
AdaBoost每一輪從N+個嵌入空間中選擇一個判別力最強的弱分類器,一共選擇T個組成物體分類器:

其中αt為弱分類器權重, k(t)為第t輪被選中的嵌入空間,k(t)∈{1,2,…,N+}。
整個算法流程如算法1所示,在第1步中,AdaBoost中樣本的權重被用于訓練加權SVM,這樣可以使弱分類器關注被錯分的樣本,整合新的子類特性,并加快算法的收斂速度。
算法1 Adaboost算法
輸入:圖像集在嵌入空間的投影Ri~i,如式(1)初始化:正負訓練樣本的權重分別為: λ1i=1/2N+,1/2N-
For t=1,2,…,T
1:在每一個嵌入空間根據當前的樣本權重訓練一個線性加權支持向量機,最優化(2)。
2:根據加權分類錯誤率εt最小的準則,選擇一個判別力最強的嵌入空間和其對應的弱分類器,如公式(3)。
3:由分類誤差確定弱分類器的權重:
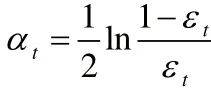
4:更新樣本權重并歸一化:
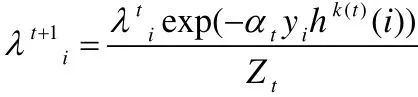
End
輸出:最終的物體分類器,如公式(4)。
2. 實驗
實驗所用數據庫是Pascal VOC 2007[12],其中共有9963幅圖像,包含20類物體,分別是:飛機、自行車、鳥、船、瓶子、公共汽車、小汽車、貓、椅子、牛、餐桌、狗、馬、摩托車、人、盆栽、羊、沙發、火車和顯示屏。依照數據庫提供的劃分,1/4的數據作為訓練集,1/4的數據作為驗證集,其余1/2數據為測試集。在訓練分類器時采用了一對多(one-vs-all)的策略,測試結果用平均精度(Average Precision)來評價,它的直觀解釋是精度-召回率曲線和坐標軸所圍的面積。 實驗結果
本文實現中使用Koen[13]提供的程序提取Harris-Laplace感興趣點,并用SIFT描述。在每一幅圖像中隨機選擇大約300個特征點構造圖像嵌入空間。算法Opelt[10]和Gist[11]實現用于實驗比較。
從表1中可以看出,本文的算法分類準確率提高了16.3%,顯示了學習圖像中有判別力的特征組合比學習單個有判別力的特征點更加重要,證明了算法的有效性。
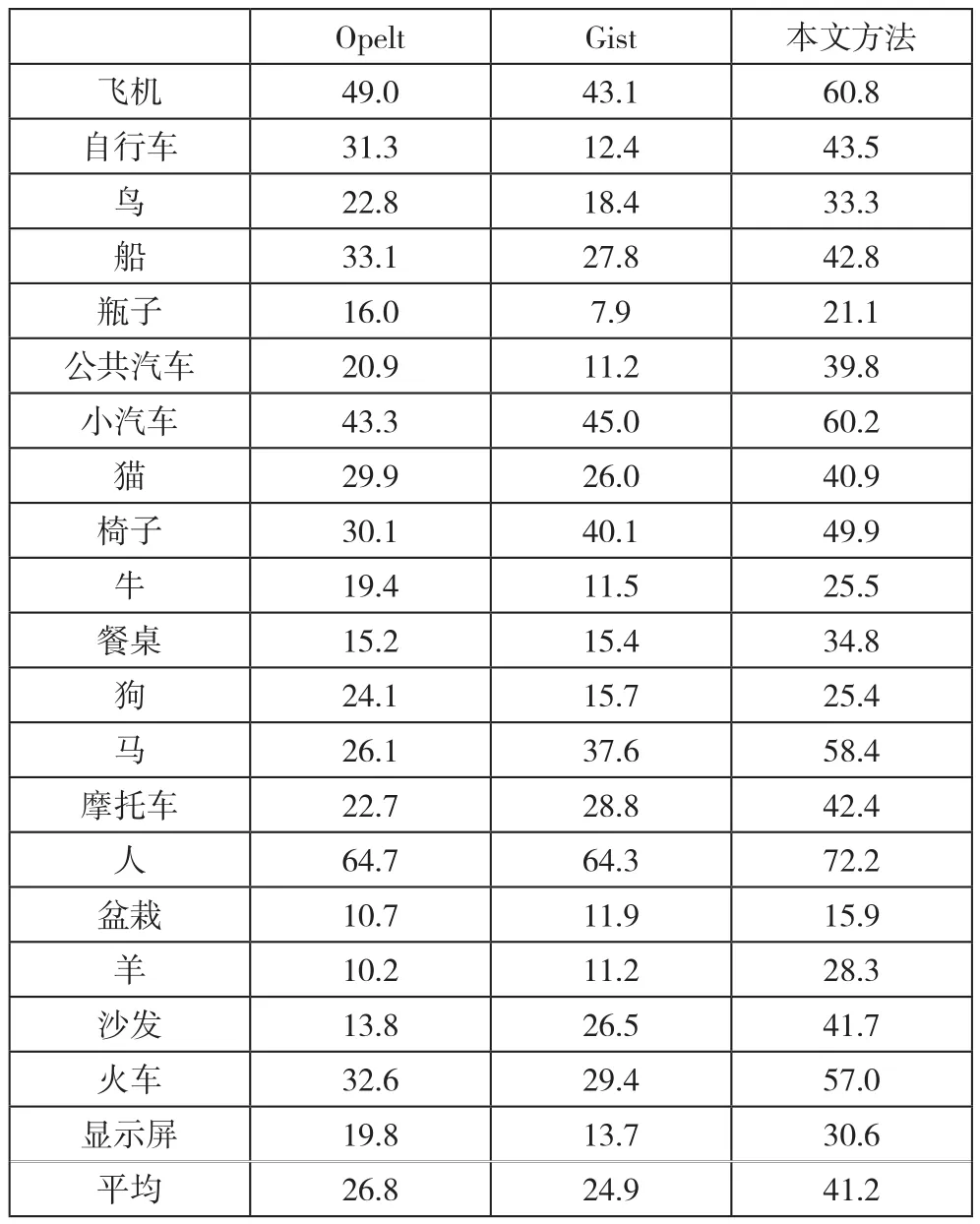
表1 實驗結果
3.結論
為了學習同一個物體類的不同圖像中有判別力的局部特征組合模式,提出了圖像嵌入空間的表示方法。這些組合模式反映了不同子類的特點,而通過AdaBoost可以隱式地組合有代表性的子類,形成最終的物體分類器。實驗結果表明物體分類精度得到顯著提高。
(作者單位:北京版銀科技有限責任公司)
TP3
A
1671-0134(2016)09-035-02
10.19483/j.cnki.11-4653/n.2016.09.010
本文由國家科技支撐計劃支持,課題名稱“數字版權資源管理系統研發與應用”,課題編號2014BAH19F01
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
