基于電廠工況劃分的模糊C-均值聚類算法研究
2016-12-07 06:14:13王惠杰李鑫鑫許小剛
電力科學與工程 2016年11期
關鍵詞:分析
王惠杰, 李鑫鑫,許小剛,王 品
(1.華北電力大學能源動力與機械工程學院,河北保定071003;2.大連發電有限責任公司,遼寧大連116021)
?
基于電廠工況劃分的模糊C-均值聚類算法研究
王惠杰1, 李鑫鑫1,許小剛1,王 品2
(1.華北電力大學能源動力與機械工程學院,河北保定071003;2.大連發電有限責任公司,遼寧大連116021)
火電機組在運行過程中產生大量的歷史數據,而目前所使用數據分析方法僅僅對這些歷史數據進行簡單的分類和統計,并不能對這些數據所隱含的規律進行挖掘。利用相關性分析對某電廠的實時數據進行研究,從大量的機組運行參數中篩選出對機組能耗影響較大的重要參數:負荷、循環水入口溫度、主蒸汽溫度、再熱蒸汽溫度、主蒸汽壓力、循環水流量。然后,介紹了模糊C-均值聚類算法的相關理論及其應用,利用此方法對以上6個參數進行工況劃分。實際應用結果表明,在對電廠大量實時進行數據聚類和合理工況劃分過程中,模糊C-均值聚類算法起到一定作用,并且對優化運行和機組節能優化有重大的意義。
熱耗率;相關系數;工況劃分;模糊C-均值聚類
0 引言
電廠機組在復雜的運行過程中產生大量的歷史數據,而這些數據背后不僅蘊含著大量豐富的信息和知識,同時還具有維數高、復雜非線性和強耦合性等特點[1-3]。影響機組能耗指標的因素就有幾十個甚至上百個,并且這些影響因素會隨電站機組設備特性、運行邊界和運行狀態的變化而發生改變。相關性分析法可以將這些熱力系統參數之間復雜的非線性關系簡化為線性相關性問題來進行處理;然后根據相關性系數來篩選出與機組能耗關系較大的重要參數[4,5]。
目前,國內電站機組普遍面臨著外界環境溫度和機組負荷大幅度變化等問題,這不僅會造成機組運行工況變化較大,火電機組在不同運行工況下的特性差異也很大,對應的最優值也是不同的。為了使各個工況點都對建模過程的數據起到作用,避免一些典型工況的冗余或一些非典型工況的缺失,而導致算法的結果偏向于典型工況,因此產生了機組的運行工況劃分問題[6,7]。目前對電站機組進行工況劃分的方法通常有等頻率法、等密度法、等寬度法和K-均值聚類算法等[8]。而以上這些傳統的聚類算法往往只是將某個樣本對象生硬地劃分到唯一的某一個類屬中,但對于現實的電站機組運行數值對象,它們的數值之間都存在一定的聯系,因此為避免劃分過硬等問題,本文引入利用了模糊集理論。在電廠機組模糊離散化過程中,模糊C-均值聚類算法(Fuzzy C-Means,FCM)的運用最為成功普遍。1973年,FCM最先是由Dunn提出,隨后由Bezdek改進并發展起來的一種模糊聚類算法。FCM不僅具有重要的基礎理論,而且在實際應用中有一定的實用價值,目前已經成功地用于解決包括特征分析、數據分析和分離器設計在內的很多問題,并同時成功應用在農業工程、圖像分析、醫學診斷、天文學、化學、地質學、形狀分析及目標識別等多種領域。隨著該算法應用的不斷深入發展,模糊聚類算法的研究也得到了不斷的改進。該算法是將各個類的隸屬度從只能取1或0擴展到[0,1],從而來表示樣本數據屬于不同的類,從而解決了數據劃分過硬的問題,為進行軟劃分提供了有力的分析工具[9-11]。
本文基于電站機組大量的歷史運行數據,基于這種相互聯系特點,應用相關性分析方法得出熱耗率與各參數間的相關系數,根據相關系數的判定,從大量的電廠機組運行參數中確定對機組能耗影響較大的重要參數。然后,介紹了模糊C-均值聚類算法的基本理論及應用,利用此方法對已篩選好的重要參數實時數據劃分成相似的工況簇,以同一工況簇為基礎,利于建模以后的分析和進行運行參數最優目標值的研究。
1 機組能耗指標的相關性分析
相關性分析是用來分析兩個變量(或變量組)之間相互依存關系的一種統計學方法,可以通過相關性系數這一指標來衡量兩變量之間的關系[12]。對于兩個參數x,y之間的相關性系數的計算公式,如式(1)所示:
(1)
判斷兩變量之間相關關系的方向和密切程度的強弱,可以利用相關性系數數值的符號和大小。若r>0,即為正相關,表示相關參數的變化方向是相同的;r<0,即為負相關,表示相關參數的變化方向是相反的。而r=0,表示不相關;r=+1,表示完全正相關;r=-1,表示完全負相關。
當|r|越趨近于1時,其相關程度越高;當|r|越趨近于0時,其相關程度越低。當|r|≥0.8時,可視為兩個變量高度相關;當0.5≤|r|<0.8時,可視為中度相關;當0.3≤|r|<0.5時,可視為低度相關;當|r|<0.3時,可視為兩個變量之間的相關程度極弱[13]。通常認為r≥0.5的變量有分析的必要,即兩個變量之間的相關程度為高度相關或中度相關。
2 模糊C-均值聚類的基本原理
FCM應用于工況劃分的基本計算思路是:(1)首先要選取對樣本X進行劃分的聚類個數c和初始化各聚類中心數值,以及樣本屬于不同類別的初始隸屬度矩陣和權重系數;(2)然后根據距離最小原則將各樣本劃分到c類中的某一類,經過不斷地迭代計算聚類中心和隸屬度矩陣,從而調整各樣本所屬類別;(3)最終使類內距離平方和達到最小時停止循環,從而來確定樣本所屬的類。最終達到對樣本數據進行分類的目的[14-16]。
令目標數據集X={x1,x2,…xn}∈Rm表示給定的已知樣本集合,m是樣本空間的維數,n是樣本個數,c(c>1)是對X進行劃分的聚類個數。FCM算法可以描述如下:
(2)
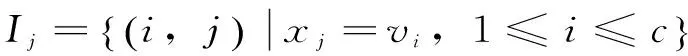
(3)
(4)
(5)
(6)
式中:m>1是模糊系數;U=uij是一個c×m的模糊劃分矩陣,uij是第j個樣本xj屬于第i類的隸屬度值;V=[v1,v2,…vn]是由c個聚類中心向量構成的n×c的矩陣;dij=‖xj-vi‖表示從樣本點xj到中心vi的距離。
FCM算法先選取初始化類中心(或者隸屬度矩陣),然后利用式(5)和式(6)進行迭代直至滿足設定的終止條件。FCM算法的具體步驟如下:
(1)設定聚類個數c(2≤c≤n)和模糊指數m(1≤m≤+∞);初始化矩陣U(0),初始化各類中心V(0);設置收斂的精度ε>0;設置循環次數s=0。
(2)用式(6)計算U(s+1)。
(3)用式(5)計算V(k+1),令k=k+1。
重復步驟(1)和(2),直到滿足如下的終止條件:
(7)
3 實例分析
3.1 進行相關性分析
本文對某電廠提取的從2015年8~11月的歷史運行數據進行分析,經數據選擇與數據檢驗得到穩定運行工況數據。對影響機組能耗的歷史運行參數進行相關性分析。
根據經驗常識,本課題選取負荷、主蒸汽溫度、主蒸汽壓力、再熱蒸汽溫度、汽包壓力、給水溫度、給水流量、循環水入口溫度、循環水流量等來分析與機組熱耗之間的相關性,計算得出各參數與機組熱耗的相關性系數如表1所示。
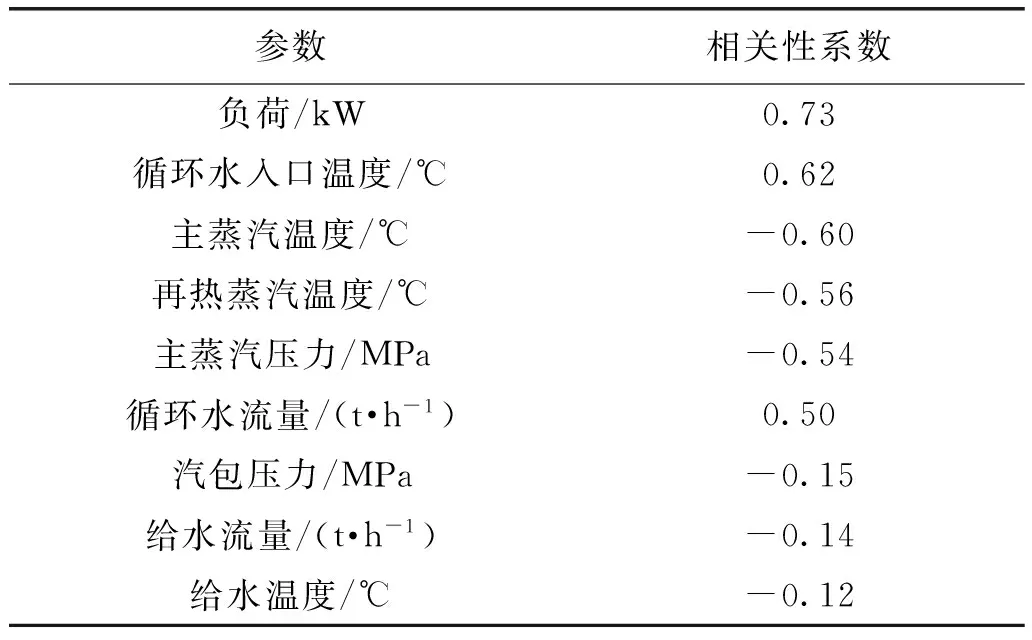
表1 相關性系數計算結果
根據表1可以得出。相關性系數為正時,意味著機組熱耗隨運行參數的增大而增大;相反,相關性系數為負時,意味著機組熱耗隨參數的增大而減小。根據表1中相關性系數大小排序,可以分析得出對熱耗影響較大的前6個因素是負荷、循環水入口溫度、主蒸汽溫度、再熱蒸汽溫度、主蒸汽壓力、循環水流量。
3.2 對各參數進行工況劃分
利用模糊C-均值聚類算法對各參數進行工況劃分時,對于C值的選擇,可能會嚴重影響工況劃分的結果,如組數太多會導致數據離散化太強,每組之間的前后關聯性降低;如果組數太少又會導致代表性數據模糊,都會對以后的建模結果造成影響。因此組數的選取是一個重要的過程,鑒于上述原因,本文選擇將每個參數劃分為10組,這樣就對6個參數劃分出106個區間。通過上文的相關性分析結果,本文選擇與機組能耗相關性強的6個參數進行工況劃分。根據模糊C-均值聚類算法將各參數進行聚類劃分,其結果如圖1~6所示。
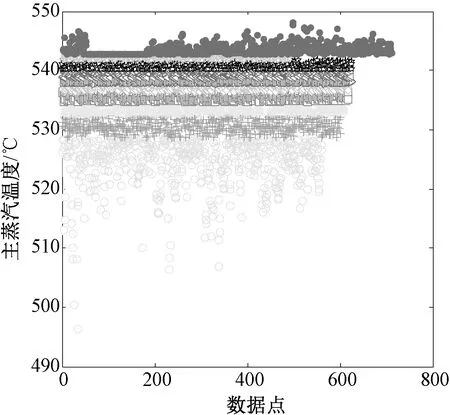
圖2 主蒸汽溫度的聚類劃分結果
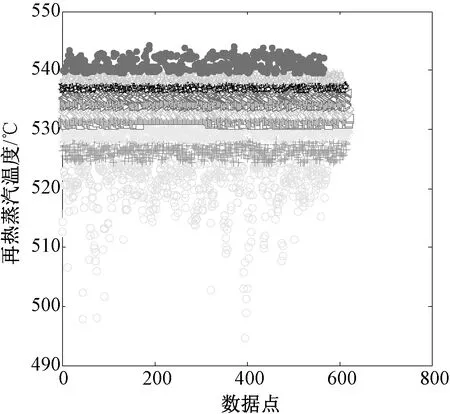
圖3 再熱蒸汽溫度的聚類劃分結果
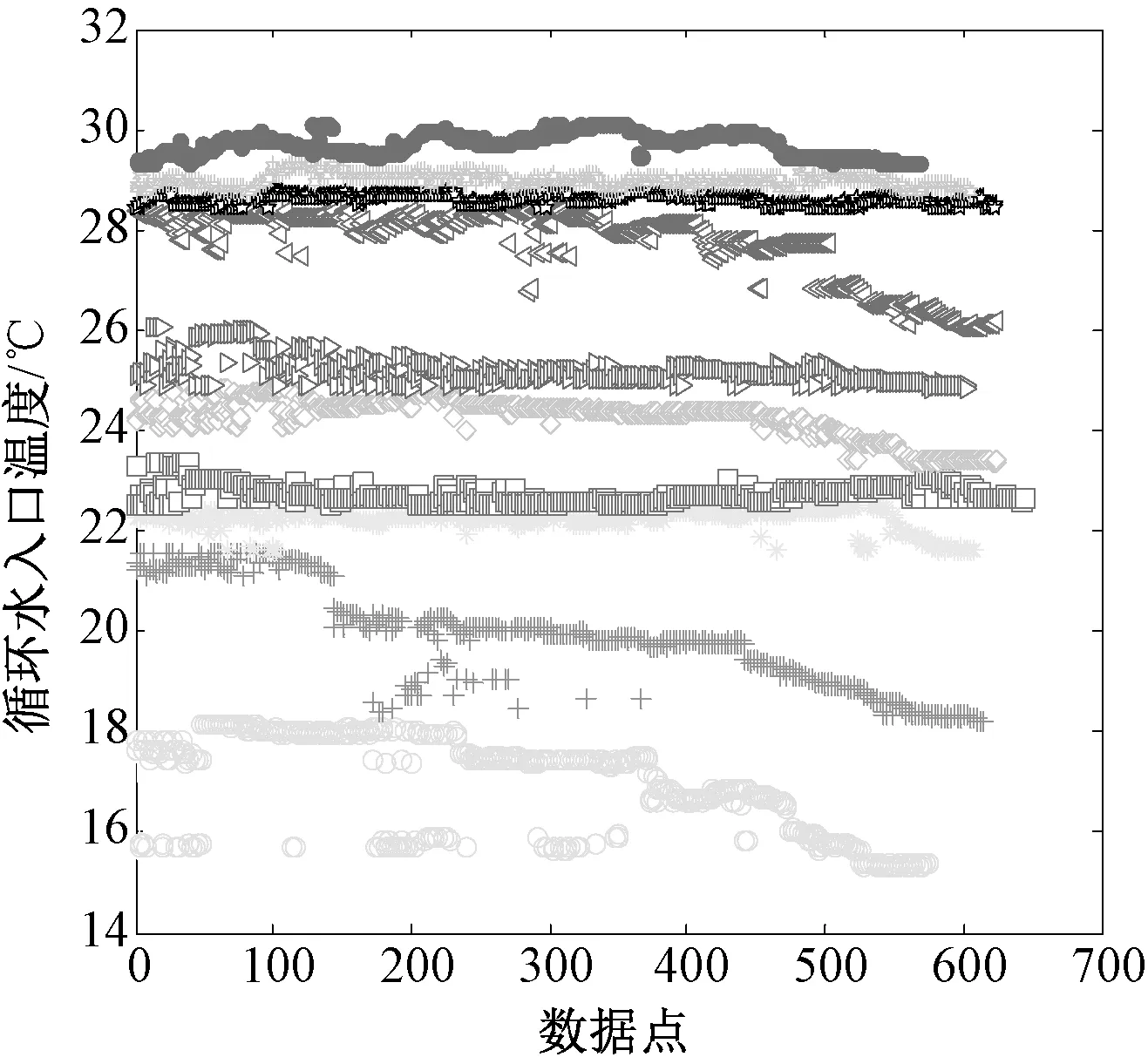
圖4 循環水入口溫度的聚類劃分結果
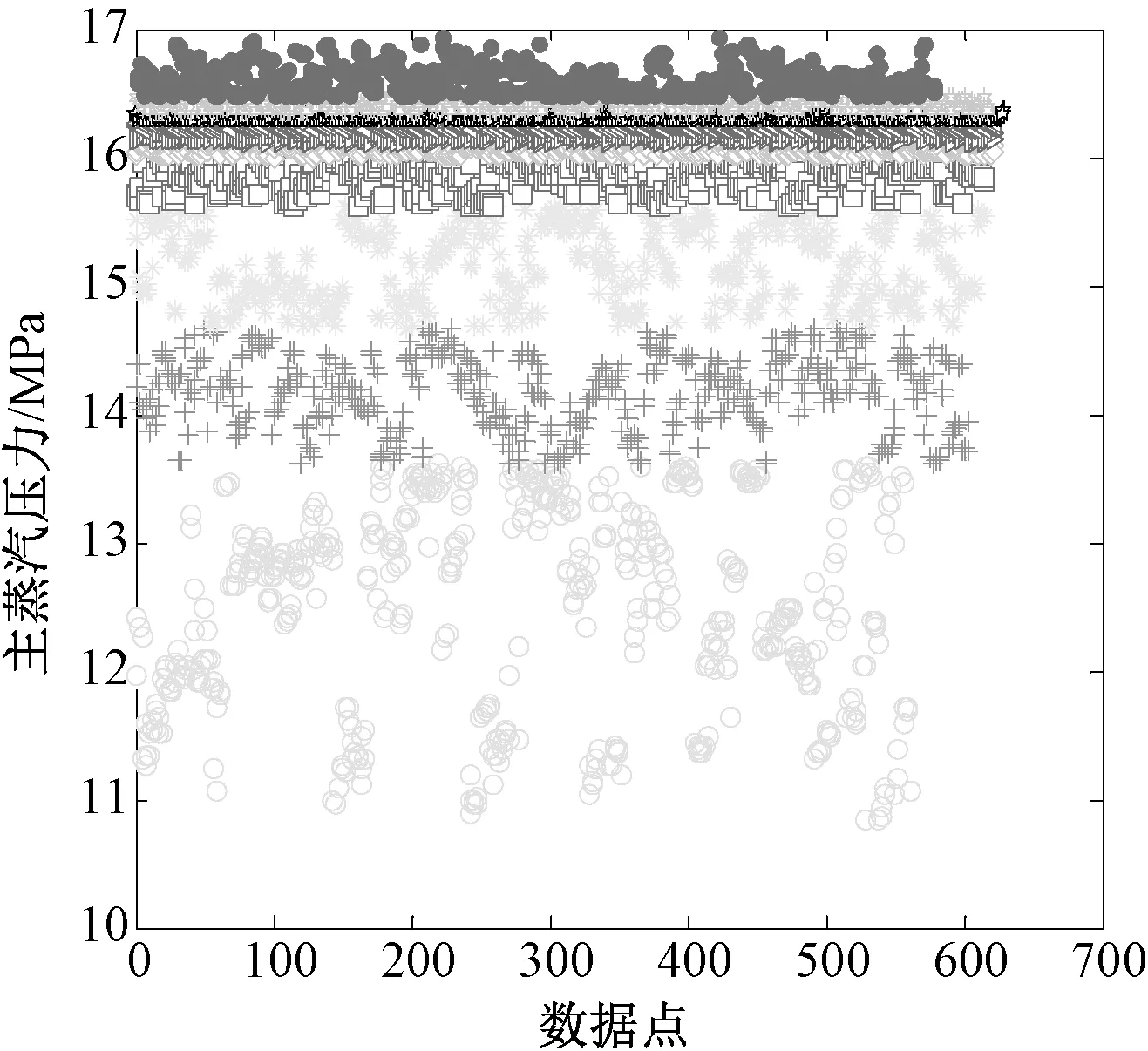
圖5 主蒸汽壓力的聚類劃分結果
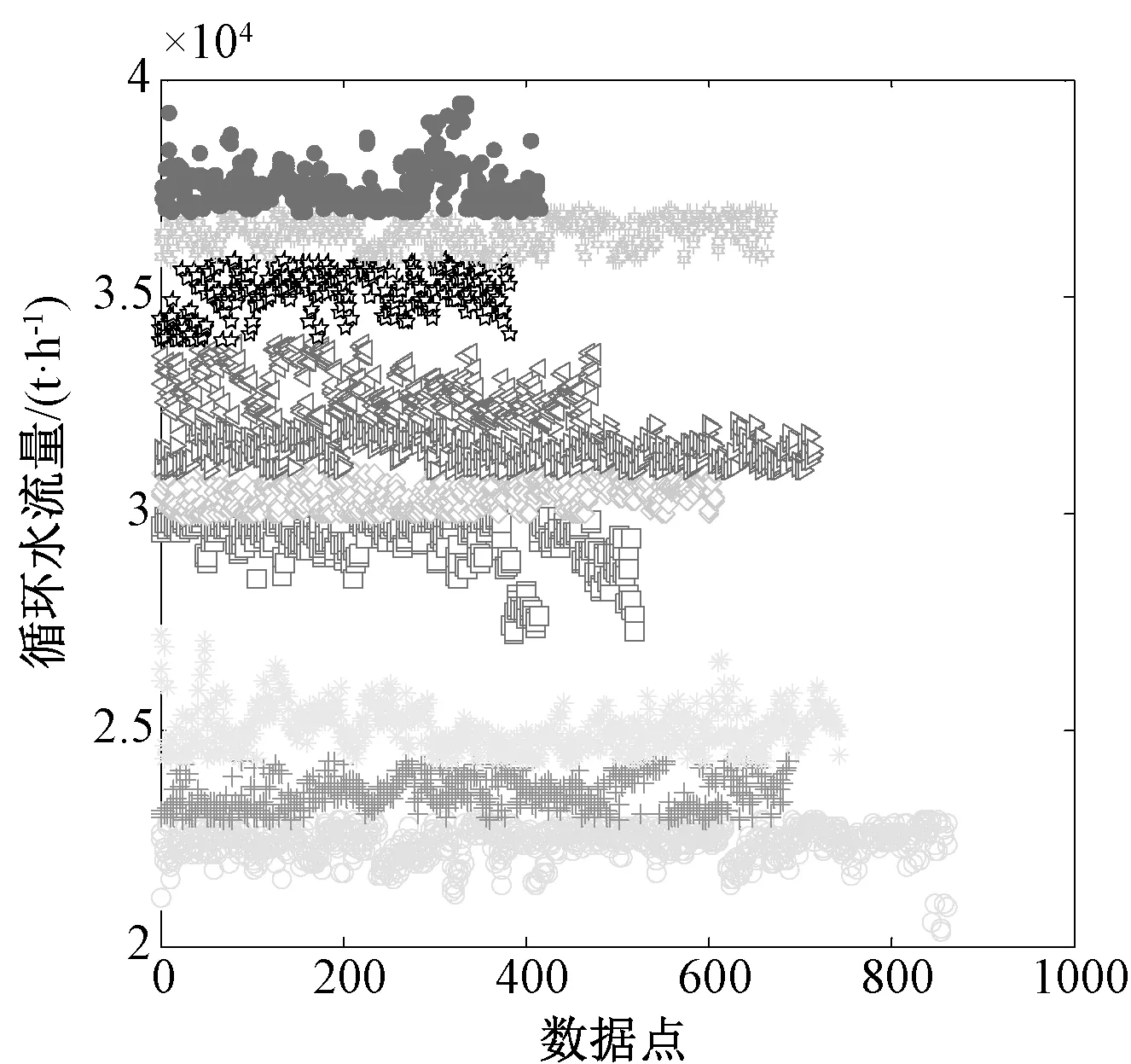
圖6 循環水流量的聚類劃分結果
根據圖1~6的工況劃分結果,經過聚類后得到的各參數區間,呈現出一定的聚類特性。由各圖聚類后得到的10個類,區間所包含的個數是不均勻的,如機組在低負荷和高負荷運行的負荷點較少,而在穩定運行時較多。將每個參數分為10組,則可將所有參數分為106種不同工況, 這樣分組結果也許某些組中會有幾百條甚至更多的數據,其他的數據忽略,這樣就能有效防止數據冗余。經過工況劃分后的數據不一定將所有工況全部填滿,并且可能有些工況的數據量過少,避免影響計算結果刪除不具有代表性的數據。隨著機組運行參數的不斷積累,工況劃分各工況中的數據不斷完善。模糊C-均值聚類算法不僅具有快速簡潔,并且避免劃分過硬等問題。
綜上所述,本文使用模糊C-均值聚類算法在進行電廠生產過程的工況劃分,對每個參數進行劃分成相似的工況簇,該方法克服了傳統聚類算法的硬劃分和不穩定等缺點,具有更好的劃分效果。機組運行工況劃分對以后的電站數據挖掘優化目標值和機組運行參數優化等生產實踐有一定參考價值。同時為挖掘電站設備的節能潛力以及耗差分析、指導運行和維修提供依據和有利的前提條件。
4 結論
(1)對各參數進行相關性分析,根據相關性系數的判定,最終篩選出與機組能耗具有較強關聯性的6組參數:負荷、循環水入口溫度、主蒸汽溫度、再熱蒸汽溫度、主蒸汽壓力、循環水流量。
(2)利用模糊C-均值算法對與機組能耗具有較強關聯性的6個參數進行工況劃分,將每個參數劃分為10組,最終得出106個不同工況。最后將分組后的數據重新組合,得到了能全面反映設備特性和運行特性的工況,為后續建模及參數優化提供了有代表性的數據。
(3)計算結果表明,模糊C-均值聚類方法在機組工況劃分中取得較好的效果。另外對以后的數據挖掘電站優化目標值和機組運行參數優化等具有一定實踐價值。該方法不僅有效地解決了數據劃分過硬的問題,而且使得機組運行工況的構建可行性更強。
[1]李正哲,馬燕峰,婁雅融,等.基于電力節能減排雙目標調度優化模型及方法的研究[J].電力科學與工程,2012,28(6):44-50.
[2]王寧玲.基于數據挖掘的大型燃煤發電機組節能診斷優化理論與方法研究[D].北京:華北電力大學, 2011.
[3]王惠杰, 張春發, 宋之平.火電機組運行參數能耗敏感性分析[J].中國電機工程學報, 2008, 28(29):6-10.
[4]宋小敏, 張國防, 邢淑蘭,等.基于數據挖掘的課程相關性分析方法[J].山西財經大學學報, 2012,34(3):240-241.
[5]馬瑞, 康仁, 羅斌,等.基于改進主成分分析法的火電機組能耗特征識別方法[J].電網技術,2013, 37(5):1196-1201.
[6]楊婷婷, 曾德良, 劉吉臻,等.基于工況劃分的火電機組運行優化規則提取[J].華北電力大學學報(自然科學版), 2009, 36(6):64-68.
[7]翟少磊, 黃孝彬, 劉吉臻.基于工況劃分的電廠經濟性指標挖掘[J].中國電力, 2009, 42(7):68-71.
[8]王秋平, 陳志強, 魏浩.基于數據挖掘的電站運行參數目標值優化[J].電力科學與工程, 2015,31(7):19-24.
[9]LI J Q, NIU C L, LIU J Z.Application of data mining technique in optimizing the operation of power plants[J].Journal of Power Engineering, 2006, 26(6):830-835.
[10]HAN J, KAMBEER M, KAMBER M.Data mining: Concepts and techniques [J].Morgan Kaufmann Publishers, 2006, 5(4):394-395.
[11]石琴, 仇多洋, 吳靖.基于主成分分析和FCM聚類的行駛工況研究[J].環境科學研究, 2012, 25(1):70-76.
[12]張建鼎.電站輔機運行參數劣化分析的研究[D].北京:華北電力大學, 2011.
[13]王開明, 束洪春, 曹立平,等.基于相關性分析的OLTC運行狀態評價方法研究[J].電力系統保護與控制,2015,43(19):54-59.
[14]劉寶玲, 何鈞.基于數據挖掘及SIS的工況劃分方法研究[J].南昌工程學院學報, 2009, 28(6):36-39.
[15]王寧玲, 楊勇平, 楊志平.多變邊界條件下火電機組能耗基準狀態診斷[J].中國電機工程學報, 2013,33(26):1-7.
[16]孫曉霞, 劉曉霞, 謝倩茹.模糊C-均值(FCM)聚類算法的實現[J].計算機應用與軟件, 2008, 25(3):48-50.
Research on Fuzzy C-mean Clustering Algorithm Based on Power Plant Operating Conditions
WANG Huijie1, LI Xinxin1, XU Xiaogang1, WANG Pin2
(1.School of Energy and Power Engineering, North China Electric Power University, Baoding 071003,China;2.Dalian Power Generation Co., Ltd.,Dalian 116021, China)
Thermal power unit produces a large number of historical data during the operation process, and the currently used methods for data analysis classify these historical data and carry out statistics in a rather simple way, which cannot reveal the hidden rules beneath these data.The correlation analysis is applied for the study of real-time data for a power plant.Some parameters, such as the load, circulating water entrance temperature, main steam temperature, reheat steam temperature, steam pressure, and circulating water flow, are selected and considered as important ones who have great influence on the energy consumption of the unit.Then, the related theory of fuzzy C- mean clustering algorithm and its application are introduced, and by using this method, six parameters mentioned above are divided according to the working condition.The results obtained during practical application show that during the reasonable working condition division and data clustering process, fuzzy C- means clustering algorithm works and is of great significance to the optimization of the operation and energy saving of the group.
heat consumption rate; correlation coefficient; working condition classification; fuzzy C- means clustering
2016-07-19。
中央高校基本科研業務費專項基金資助項目(12NQ40)。
王惠杰(1979-),男,副教授,主要從事能源利用節能技術、熱力發電廠系統、設備及運行節能在線監測等工作,E-mail:ncepuwhj@163.com。
TK01+8
A
10.3969/j.issn.1672-0792.2016.11.010
猜你喜歡
現代畜牧科技(2021年9期)2021-10-13 06:39:14
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
當代經濟研究(2016年5期)2016-12-01 03:12:05
現代農業(2016年5期)2016-02-28 18:42:46
出版與印刷(2016年3期)2016-02-02 01:20:11
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
華北水利水電大學學報(社會科學版)(2014年3期)2014-04-16 04:38:31
終身教育研究(2014年5期)2014-02-28 01:23:06
