基于主成分分析和支持向量機的企業盈利能力預測
2016-12-20 12:31:55張紅,高帥,張洋
統計與決策 2016年23期
張 紅,高 帥,張 洋
(1.清華大學 建設管理系,北京100084;2.北京林業大學 經濟管理學院,北京100083)
基于主成分分析和支持向量機的企業盈利能力預測
張 紅1,高 帥1,張 洋2
(1.清華大學 建設管理系,北京100084;2.北京林業大學 經濟管理學院,北京100083)
文章針對中國建筑業上市公司樣本規模較小,常規預測方法難以奏效的特點,嘗試將支持向量機應用于其盈利能力預測。首先從不同的角度選擇盈利能力單項指標,以此為基礎構建反映公司盈利能力的集成指標,結合2001—2014年中國A股建筑業上市公司的數據,構建基于支持向量的盈利能力預測模型,對樣本公司的盈利能力進行預測。研究結果顯示,經過訓練的支持向量機模型能較為成功地預測樣本公司的盈利能力,2003—2014年的預測準確率均超過80%;通過與BP神經網絡的對比試驗可以發現,在預測中國建筑業上市公司盈利能力方面,支持向量機表現出了較明顯的優勢。
盈利能力;預測;建筑業上市公司;支持向量機;主成分分析
0 引言
盈利能力預測屬于模式識別范疇。目前常用的模式識別方法包括數據挖掘、人工神經網絡和支持向量機[1]。數據挖掘是從大量數據中自動搜索某種蘊含特殊關系信息的過程,對數據量有較高要求。人工神經網絡是一種應用類似于大腦神經突觸聯接的結構進行信息處理的數學模型,在大樣本條件下能得到較好的識別效果。然而其網絡結構需事先指定,難以保證網絡結構的最優化,易陷入局部最優的困境。支持向量機是基于統計學習理論和結構風險最小原理的模式識別方法,主要針對小樣本,且通過核函數可解決局部最優的問題。中國建筑業上市公司的數量較少(2012年A股建筑業上市公司有52家,占A股上市公司總數的2%),難以滿足數據挖掘和人工神經網絡大樣本的要求。相比而言,支持向量機主要對小樣本進行模式識別,更適用于中國建筑業上市公司盈利能力分析。目前該方法被廣泛用于投資風險評價和企業信用評價等評價領域[2]。本文首次將其應用于企業盈利能力預測,這是對支持向量機應用范圍的拓展,同時也是對盈利能力分析的一種全新嘗試。
盈利能力預測的前提是選擇合適的反映盈利能力的指標。目前常用的指標包括“資產收益率”、“凈資產收益率”、“資本利潤率”、“每股收益”、“主營業務利潤率”和“銷售利潤率”[3,4]等。上述指標從不同的角度反映了企業的盈利能力。然而不同角度的指標在同一時期內往往呈現不同的趨勢[5],因此很難憑借單個指標對企業的盈利能力進行客觀的評價。為全面、系統地衡量企業盈利能力,本文將采用主成分分析法創建一個量化盈利能力的集成指標,以避免單個指標相互沖突的問題。
由此,本文以中國建筑業上市公司為樣本,首先基于既有研究選擇反映盈利能力的單項指標,并采用主成分分析法創建集成指標;其次,構建盈利能力預測的支持向量機模型;最后,選取部分建筑業上市公司為訓練樣本,采用支持向量機模型對部分樣本進行盈利能力預測訓練,并進一步對其余樣本的盈利能力進行預測判斷。
1 盈利能力指標的分析與構建
1.1 盈利能力單項指標的選擇與分析
在既有研究的基礎上,本文分別從資產利用效率、股東權益、資本利用效率、股票投資回報、主營業務收益能力以及銷售收入獲利水平這6個角度選擇反映上市公司盈利能力的單項指標:資產收益率、凈資產收益率、資本利潤率、每股收益、主營業務利潤率和銷售利潤率。各指標的涵義與計算公式如表1所示。
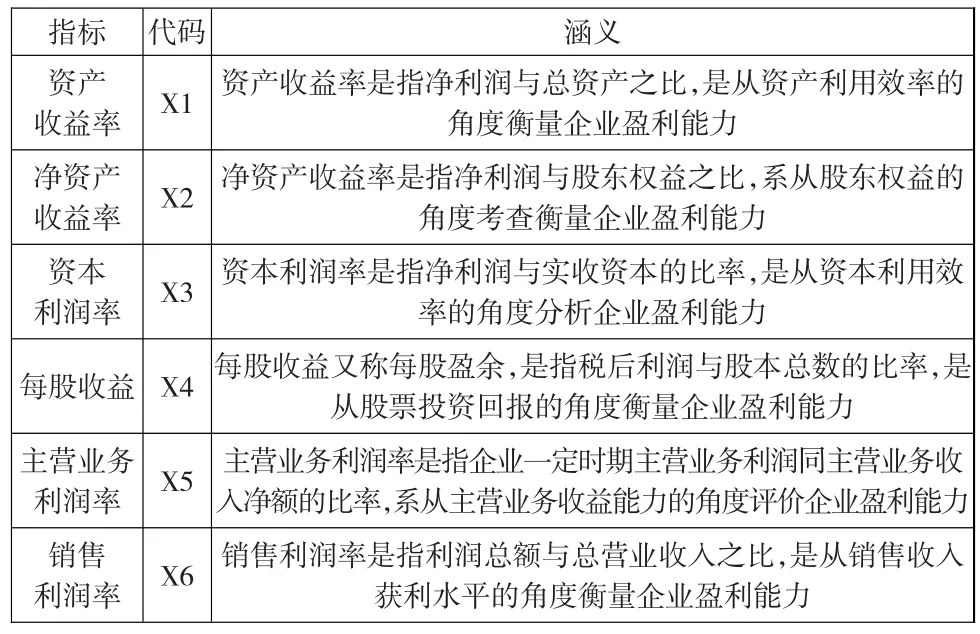
表1 盈利能力單項指標及其涵義
根據中國證監會制定的《上市公司行業分類指引》,本文選擇2001—2014年中國A股的建筑業上市公司為樣本,對其盈利能力單項指標進行統計分析,結果如表2所示。

表2 2001—2014年中國建筑業上市公司盈利能力單項指標均值
分析表2可知,(1)當以資產收益率衡量盈利能力時,2001—2014年樣本公司總體盈利能力變動較小;(2)若以凈資產收益率、主營業務利潤率和銷售利潤率作為盈利能力代表指標,則樣本公司總體盈利能力起伏較大;凈資產收益率均值在2006年跌至谷底(-0.161),在2009年攀升至峰頂(0.686),此后又迅速回落;銷售利潤率均值在2007年到達最低點(-0.094),而2009年出現最大值(0.317);(3)當以資本利潤率和每股收益衡量盈利能力時,14年間樣本公司盈利能力總體呈上升趨勢。
由此可見,當從不同角度考察建筑業上市公司的盈利能力時,不同的單項指標表現出不同的變化趨勢,很難憑借單個指標對盈利能力做出總體判斷。為合理、客觀以及全面地反映中國建筑業上市公司的盈利能力,有必要構建一個集成指標。
1.2 盈利能力集成指標的構建
利用主成分分析法構建盈利能力集成指標,首先須對單項指標進行標準化處理,計算因子的特征值及其方差貢獻率;其次,根據方差貢獻率確定主成分因子;然后,根據成分矩陣和特征值計算特征向量,并結合標準化的單項指標數據確定主成分因子;最后,以方差貢獻率為系數對主成分因子進行線性組合,得到集成指標。
本文結合中國A股建筑業上市公司2001—2014年的數據(共593個樣本),利用SPSS統計分析軟件對數據進行標準化處理,利用處理后的數據進行因子分析,得到包含原始指標所有信息的因子Yi(i=1,2,…,6)。各因子的特征值和方差貢獻率,如表3所示。各因子對應的主成分矩陣如表4所示。
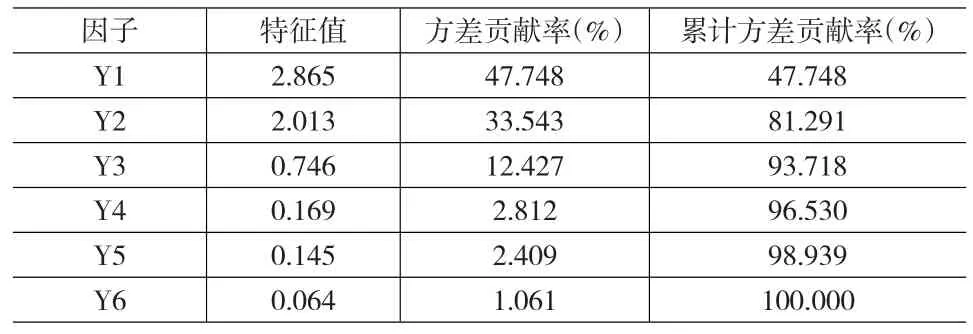
表3 主成分因子的特征值和方差貢獻率
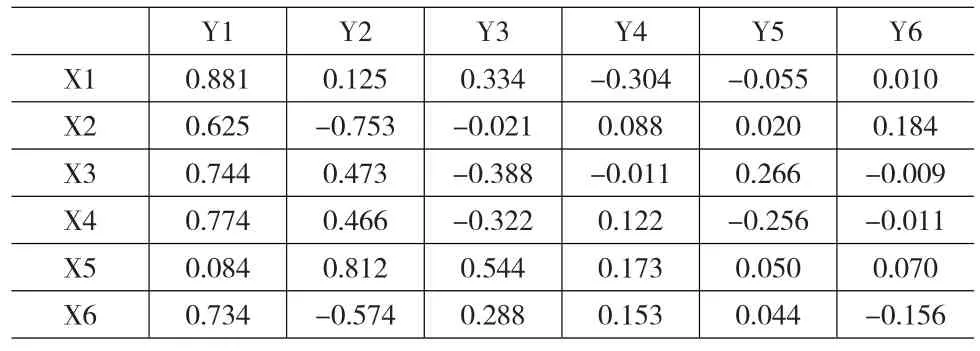
表4 成分矩陣
由表3可知,前3個因子Y1、Y2和Y3的累積方差貢獻率達到93.7%,滿足累積方差貢獻率超過85%的原則,可將其作為主成分因子。結合表4的成分矩陣,選取Y1、Y2和Y3的成分向量,利用以下公式計算主成分特征向量。

按照式(1)可計算出主成分Y1、Y2和Y3的特征向量,如表5所示。
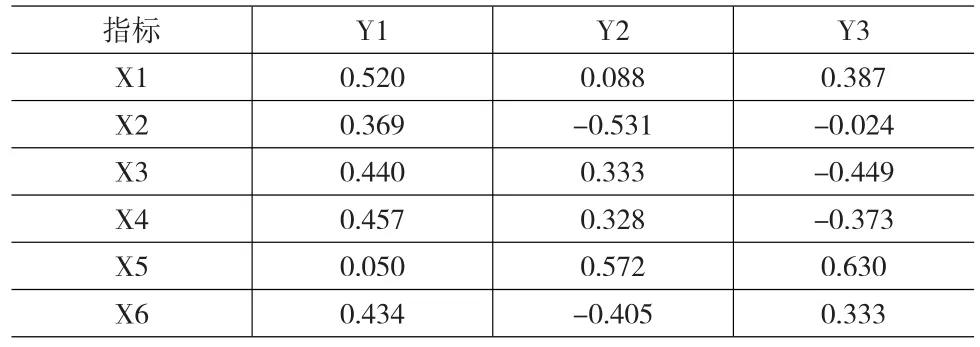
表5 主成分特征向量
根據表5的主成分特征向量,可將每個主成分表達為原指標(標準化后的數據)的線性函數,如式(2)至式(4)所示。

其中,ZX表示經過標準化的單項指標數據。
結合表3的方差貢獻率,可構造出反映盈利能力的集成指標P:
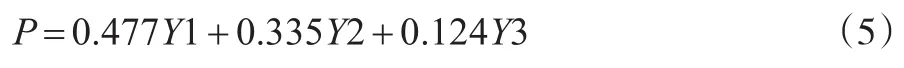
利用樣本公司2001—2014年的數據,可計算出各年度建筑業上市公司綜合盈利能力指標均值,如表6所示。
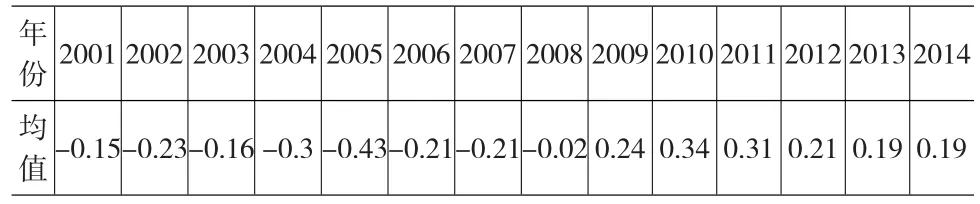
表6 中國建筑業上市公司盈利能力集成指標均值
由表6可知,2001—2008年,中國建筑業上市公司綜合盈利能力指標P的均值小于0,而2009-2012年P均值大于0,這說明2001—2008年樣本公司總體盈利能力較差,而2009—2012年總體盈利能力較好。P均值經歷了2001—2005年的下跌,2005—2010年的上漲,2010—2014年的回落,這說明中國建筑業上市公司總體盈利能力起伏較大。
2 構建支持向量機模型
基于支持向量機建立建筑業上市公司盈利能力預測模型的基本思路是:
第一階段,選擇適當的核函數和參數構建支持向量機。上文提到,核函數是支持向量機的重要組成部分。常用的核函數有4類:線性核函數、多項式核函數、Sigmoid核函數和徑向基核函數(RBF)。目前大部分學者推薦使用RBF[6]。RBF能有效處理非線性和高維的識別問題。RBF所得的分類器在形式上與神經網絡比較類似,但其網絡結構、分類器中心以及網絡權重由二次優化算法自動確定。RBF模型中包括兩個重要的參數,懲罰參數C和核參數γ。參數選擇不當將會對最終的分類超平面產生嚴重的影響,由于這兩個參數沒有通常的規律,常使用網格與交叉驗證來進行選擇。本文利用LIBSVM軟件包完成支持向量機的參數選擇工作[7]。
第二階段,建立訓練樣本對支持向量機進行預測訓練。以建筑業上市公司第t年和t+1年的數據作為訓練樣本。將樣本公司第t年的6個盈利能力單項指標作為支持向量機模型的輸入量;把樣本公司第t+1年的盈利能力劃分為+1(盈利能力集成指標P大于0)和-1(盈利能力集成指標P小于0)兩類,以+1和-1作為模型的輸出量,形成支持向量機預測模型的基本框架。借助LIBSVM軟件包和MATLAB商用軟件對樣本進行訓練,得到支持向量xi、最優解的拉格朗日乘子α*i和分類閾值b*。
第三階段,利用訓練好的支持向量機進行建筑業上市公司盈利能力預測。將樣本公司第t+1年的6個盈利能力單項指標輸入訓練好的預測模型,根據輸出量對其t+2年的綜合盈利能力進行預測。
3 建筑業上市公司盈利能力預測
這里采用支持向量機模型進行中國建筑業上市公司盈利能力預測。首先根據已有理論與研究建立支持向量機預測模型,這一工作由軟件(LIBSVM+MATLAB)實現;其次利用第t年和t+1年的數據對訓練樣本進行訓練;最后基于訓練完畢的支持向量機模型預測中國建筑業上市公司第t+2年的盈利能力。
3.1 訓練樣本的建立
本文利用相鄰兩年的數據建立訓練樣本對支持向量機進行訓練,以經過訓練的模型預測中國建筑業上市公司下一年度的盈利能力。即2001—2013年的13年間,可建立12個訓練組,利用這些訓練組對模型進行訓練,可依次預測中國建筑業上市公司2003—2014年的盈利能力。這里將以2001年和2002年的數據(訓練組1)為例,詳細說明模型的訓練過程。
2001年中國A股共有23家建筑業上市公司,2002年在此基礎上增加了一家公司。為保證樣本的匹配,以2001年的23家公司為訓練樣本,將其按照A1-A23編號。利用2001年的6個單項盈利能力指標作為輸入向量,擬合2002年的綜合盈利能力狀況,輸出值為+1和-1,分別對應2002年綜合盈利能力指標P大于0和小于0的情況。訓練樣本的原始數據和訓練結果如表7所示。
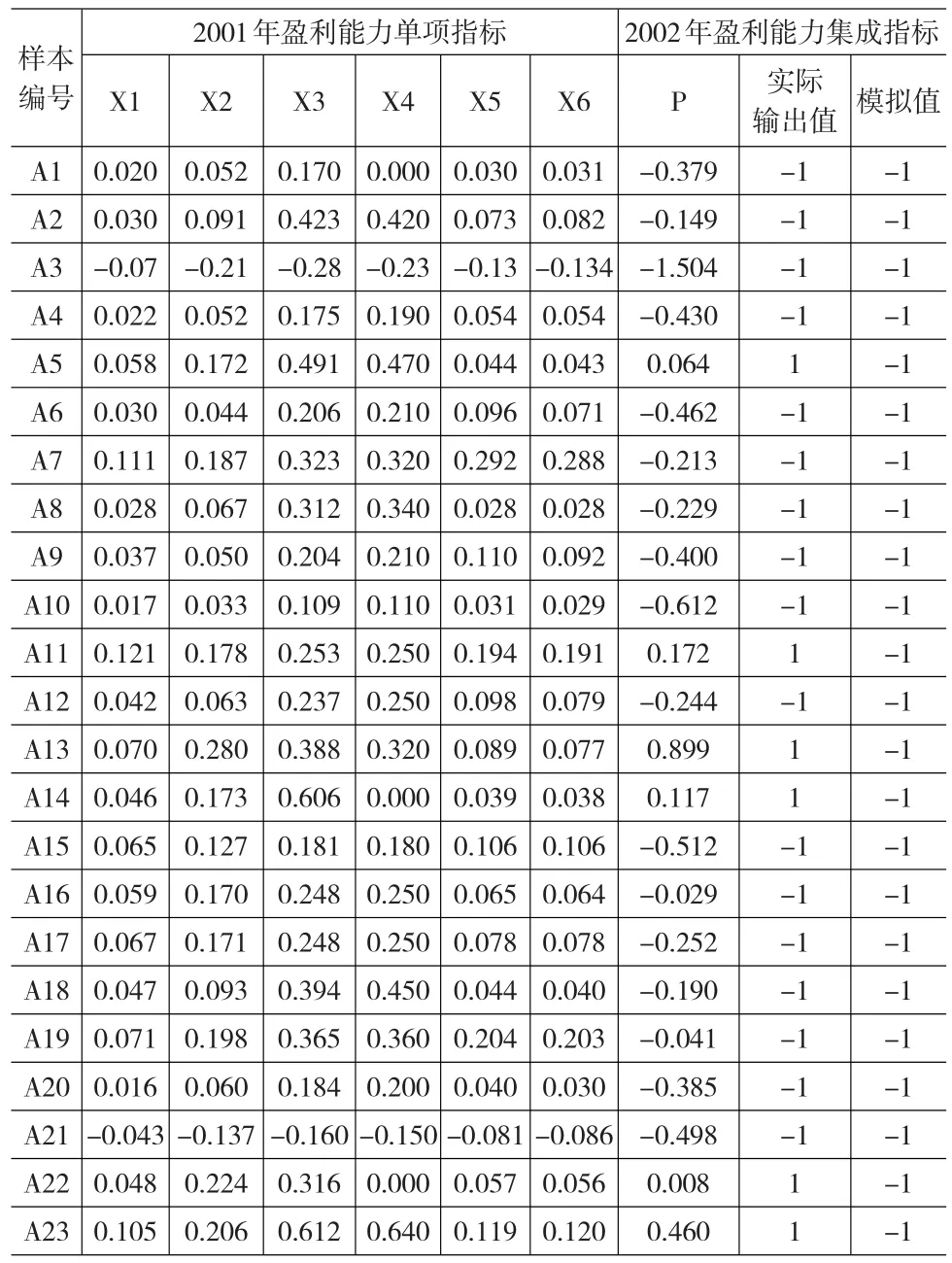
表7 訓練樣本的原始數據和訓練結果
由表7可知,在2002年23個訓練樣本中,盈利能力良好(集成指標P大于0)的公司有6家,而盈利能力較差(集成指標P大于0)的公司有17家;從訓練的結果來看,23個樣本的模擬結果均為-1,即模型正確地判斷出了17家公司的盈利能力,說明支持向量機能對73.9%的訓練樣本進行正確分類。
以上是第一組訓練樣本。類似地,結合2002年和2003年的數據可構建第2組訓練樣本,2001年到2011年總共可建立10組訓練樣本。利用訓練樣本即可進行公司下一年盈利能力的預測。
3.2 盈利能力預測
本文采用訓練好的支持向量機模型對2003—2014年中國建筑業上市公司盈利能力進行預測。這里沿用2001年和2002年的訓練結果,具體闡述預測方法。上文提到,根據第t年和t+1年的數據得到的訓練結果,可預測公司t+ 2年的盈利能力。即利用2001年和2002年的數據,可預測23家樣本公司2003年的盈利能力。具體做法是將樣本公司2002年的6個單項盈利能力指標作為輸入向量,利用訓練好的模型預測2003年的綜合盈利能力。輸入的原始數據和預測結果如表8所示。
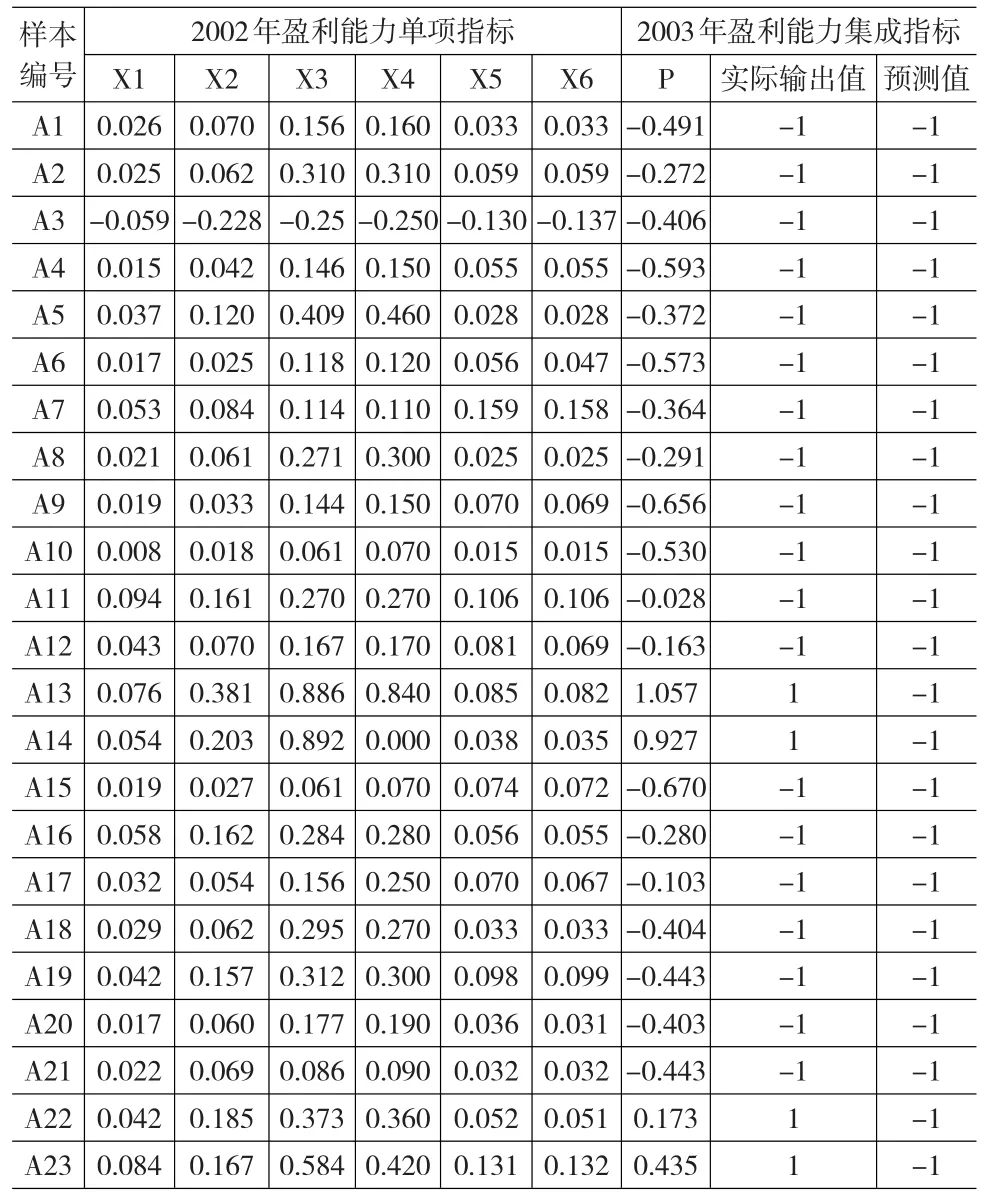
表8 預測樣本的原始數據和預測結果
由表8可以看出,根據綜合盈利能力指標P判斷,在2003年23個訓練樣本中,盈利能力良好的公司有4家,而盈利能力較差的公司有19家;從預測結果來看,支持向量機模型預測23家公司2003年的盈利能力均較差,說明模型預測的準確率為82.6%。
類似地,可以逐年預測2004—2014年建筑業上市公司的盈利能力。為考察支持向量機在企業盈利能力預測方面是否具備優勢,本文建立了BP神經網絡模型進行對比試驗。在設計BP神經網絡時,采用3層神經網絡結構:第一層是輸入層,包括6個輸入節點;第二層是隱層,包含20個節點;第三層為輸出層,包含2個輸出節點。神經網絡的輸出內容同樣為+1或-1。支持向量機與神經網絡對比試驗的結果如表9所示。

表9 支持向量機與神經網絡的預測結果對比
由表9可以看出,利用支持向量機和BP神經網絡分別對中國建筑業上市公司盈利能力進行預測,前者的預測準確率明顯高于后者。這說明在小樣本的分類實驗中,支持向量機可能比神經網絡更具優勢。
4 結論
針對中國建筑業上市公司樣本規模較小的特點,本文創造性地將支持向量機應用于其盈利能力預測。首先從不同的角度選擇盈利能力單項指標,以此為基礎構建反映公司盈利能力的集成指標,結合2001—2014年中國A股建筑業上市公司的數據,構建基于支持向量的盈利能力預測模型,對樣本公司的盈利能力進行預測。研究結果顯示,經過訓練的支持向量機模型能較為成功地預測樣本公司的盈利能力,2003—2014年的預測準確率均超過80%;通過與BP神經網絡的對比試驗可以發現,在預測中國建筑業上市公司盈利能力方面,支持向量機表現出了較明顯的優勢。
本文嘗試建立基于支持向量機的中國建筑業上市公司盈利能力預測模型。研究結果證明,支持向量機憑借堅實的統計學習理論基礎,具有較強的逼近能力和泛化能力。支持向量機不僅具有與神經網絡類似的不斷學習、不斷訓練的功能,而且解決了神經網絡難以避免的大樣本、網絡結構優化以及局部最優等問題。其對樣本公司盈利能力較為準確的預測,也說明了該方法比較適用于建筑業上市公司盈利能力預測。
[1]Peng X.TPMSVM:A Novel Twin Parametric-Margin Support Vector Machine for Pattern Recognition[J].Pattern Recognition,2011,44(10).
[2]Chen J,Jiang F,Huang Z,et al.Performance Evaluation for GEM List?ed Companies Based on Support Vector Machine[J].International Journal of Applied Mathematics and Statistics,2013,45(15).
[3]Hoque Z.Measuring Divisional Performance in the Short-Run[J]. Handbook of Cost&Management Accounting,2012.
[4]Yasser Q R.Corporate Governance and Performance(A Case Study for Pakistani Communication Sector)[J].International Journal of Trade, Economics and Finance,2011,2(3).
[5]張紅,林蔭,劉平.基于主成分分析的房地產上市公司盈利能力分析與預測[J].清華大學學報(自然科學版),2010,(3).
[6]Hsu C W,Chang C C,Lin C J.A Practical Guide to Support Vector Classification[EB/OL].http://www.csie.ntu.edu.tw/~cjlin.
[7]Chang C C,Lin C J.LIBSVM:A Library for Support Vector Machines [EB/OL].http://www.csie.ntu.edu.tw/~cjlin/libsvm.
(責任編輯/劉柳青)
F830.2
A
1002-6487(2016)23-0174-04
國家自然科學基金資助項目(71073096)
張 紅(1970—),女,河北大名人,教授,博士生導師,研究方向:房地產經濟與金融。
(通訊作者)高 帥(1980—),男,陜西榆林人,博士,研究方向:房地產金融。
張 洋(1983—),男,安徽靈璧人,博士,講師,研究方向:房地產經濟學。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
發明與創新(2022年30期)2022-10-03 08:40:56
動漫星空(興趣百科)(2020年12期)2020-12-12 05:31:40
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
人大建設(2018年6期)2018-08-16 07:23:10
文理導航·科普童話(2017年5期)2018-02-10 19:42:14
無人機(2017年10期)2017-07-06 03:04:36
光學精密工程(2016年6期)2016-11-07 09:07:19
小星星·閱讀100分(低年級)(2015年10期)2015-10-22 08:30:04
