面向用戶話題相似性特征的鏈路預測方法
2016-12-23 00:57:48王菲菲楊揚蔣飛許進
西安交通大學學報 2016年8期
王菲菲,楊揚,蔣飛,許進
(1.北京大學光華管理學院,100871,北京;2.北京大學高可信軟件教育部重點實驗室,100871,北京)
?
面向用戶話題相似性特征的鏈路預測方法
王菲菲1,楊揚2,蔣飛2,許進2
(1.北京大學光華管理學院,100871,北京;2.北京大學高可信軟件教育部重點實驗室,100871,北京)
針對線上用戶間的鏈路預測對用戶文本內容特征的挖掘不夠充分的現象,提出了面向用戶興趣話題相似性的二次特征抽取方法。該方法應用主題模型得到任意用戶的主題分布,利用用戶在主題上相異的分布比例提取各自的興趣話題集合,基于興趣話題集合構造了一組話題相似性特征用于鏈路預測。不同于傳統方法中對用戶主題分布的直接利用,該方法對用戶文本內容的相似性特征進行了再次挖掘,使得文本特征具有等同于結構特征的預測能力,并能夠作為結構預測特征的有效補充。實驗結果表明,內容特征的獨立預測效果普遍優于結構特征,并且在聯合預測中將結構特征的預測效果提高了3%。
鏈路預測;用戶內容;主題模型;相似性特征
社交服務提供商為了保持用戶黏性,需培養用戶從事在線社交活動的行為習慣,維持其較高的參與度和存在感,一個重要的方法就是通過鏈路預測來進行推薦,引導用戶關注具有共同愛好的線上朋友或發現尚未建立關注關系的線下好友。社交網絡中好友間可被觀測到的相互關注關系通常被簡稱為鏈路。鏈路預測問題可以概括為:對于目標網絡中每一對未觀測到存在鏈路的節點對,預測它們之間是否真的存在鏈路,或者是否會在將來建立新的鏈路。
鏈路預測中一類重要方法是基于節點相似性假設進行預測,即相似性越強的節點對之間存在鏈路的概率越高。早期研究中對于節點相似性的刻畫,主要體現在提取有效的結構特征來刻畫節點對的相似性,例如以社交行為為背景的共同好友數[1]、局部結構相似性和社團貢獻度[2]等特征。這類研究普遍具有數據采集便捷、特征計算復雜度低、解釋性強和精度良好等優勢,并常在后續工作中作為預測效果的評價基準。在近期研究中,人們開始引入多元和異質的信息來提高原有結構信息的預測精度,即除了原有結構信息外,還引入用戶在同一社交網絡中產生的文本內容信息、地理位置信息或在其他平行社交網絡中產生的結構、文本、地理位置信息等。
在社交網絡所包含的多元異質信息中,文本信息占據著主導地位,其大量形成于網絡中的節點,并時刻借助網絡中的鏈路進行傳播。相比于結構特征對用戶關注關系直接刻畫,文本特征從信息傳播角度間接體現了用戶間潛在的好友關系。對于文本信息的充分挖掘能夠有效改善結構特征的預測效果,并體現在基于文本相似性假設的鏈路預測[3]等研究工作中。
基于文本相似性假設的鏈路預測是隨著文本建模研究的發展而出現的。文本模型經歷了由TF-IDF(text frequency-inverse document frequency)模型到LDA (latent dirichlet allocation)模型[4]的重要發展階段,其中LDA模型是一類非常重要的概率主題模型。它在傳統的空間向量模型和語言模型的基礎上引入了主題空間,將每篇文檔看成是在主題空間上的概率分布,將每個主題看成是在整個詞典空間上的概率分布,從而構建了“文檔-主題-詞典”的多層次概率模型。該模型具有較好的泛化能力和較強的可擴展性,因而被廣泛地應用于包括社交網絡文本內容建模在內的研究工作中。
在社交網絡的鏈路預測中,對于用戶的文本內容的利用主要通過以下兩種方式:
(1)對用戶的內容進行文本建模,并將得到的內容特征應用于預測模型,或對初步得到的內容特征進行進一步抽取,用新得到的用戶內容特征進行預測;
(2)擴展原有的文本模型,對用戶內容和網絡結構進行聯合建模,并通過模型擬合后的相應參數直接或間接推導出鏈路的存在概率。
在第一種方式中,Puniyani等在回歸模型中將每對文檔在每個主題上分布概率之差的平方值作為自變量,研究了每個特定主題與文檔間鏈路的存在性是否顯著相關[5]。相似地,Quercia等則證明了改進的監督型主題模型Labeled-LDA能夠取得與LDA相近的用戶相似性評價效果[3]。
第二種方式中建立的聯合模型是對LDA主題模型的進一步擴展,能夠建模網絡中所有文本與結構信息的生成過程。Erosheva等提出的Link-LDA模型假設一篇文檔中的每一個詞以及該文檔的引用連接服從同一個主題分布,并且由該引用連接的主題歸屬來分配被引文檔的編號[6],從而模擬了文檔間的引用與被引用的關系以及文檔內容的生成過程,然而該模型并不服從文本相似性假設。Ramage等提出了Link-PLSA-LDA模型[7]。該模型對Link-LDA模型進行了擴展,將PLSA(probabilistic latent semantic analysis)模型和LDA模型統一在一個模型框架中,并顯式地刻畫了主引文檔和被引文檔之間的拓撲結構關系,即文檔鏈路關系,進而經過模型推導,給出了主引文檔與被引文檔之間主題相關性的條件概率,并通過該條件概率取值來進行鏈路預測。Chang等提出了相關性主題模型,從而對文檔網絡的內容和鏈路的生成過程進行建模[8]。該模型用一個二元指示變量表示一對文檔之間鏈路的存在性,并且假定該二元變量與其所對應文檔的主題相關性系數具有邏輯回歸關系。
本文屬于第一種方式,研究了基于LDA主題模型提取的用戶內容特征,在社交網絡中進行鏈路預測的效果。本文首先應用LDA主題模型對用戶微博內容進行主題建模,得到了每個用戶內容的主題分布,進而創新性地提出了直接內容特征和間接內容特征兩類相似性指標。其中在直接內容特征中,提出將用戶主題熵之間的差異性與主題分布的相似性進行聯合,來評價不同用戶在話題愛好上的差異性;在間接內容特征中,利用用戶內容在主題分布上的差異性,設定不同閾值篩選出任意一個用戶的話題優先性集合,進而基于不同用戶的話題集合,提出一組相似性指標來評價他們的話題集合相似性。對于以上所有內容特征,首先分別將其與常見結構特征的獨立預測效果進行了對比,證實了直接內容特征和間接內容特征在鏈路預測中的有效性;接著,在不同監督型算法中,對不同特征集合的預測效果進行了比較。實驗結果表明,內容特征集合能夠獨立地取得較高的預測準確率,并且能夠有效提高傳統的基于結構特征的方法的預測效果。
本文的貢獻主要表現在:
(1)對LDA文本建模得到的用戶主題分布進行二次特征抽取,得到了直接內容特征和間接內容特征兩類內容特征;
(2)通過充分的實驗,驗證了間接內容特征在獨立預測中優于結構特征,并能在聯合預測中改善結構特征的預測效果。
1 數據采集和預處理
1.1 數據采集
本文所用的原始數據采集自新浪微博,采集時間段為2014年8月31日8時至2014年8月31日18時,其中包含用戶54 119人,有向鏈接754 149條,以及所有用戶在近一周內原創和轉發的微博文本內容共1 114 693條。
1.2 數據預處理
由于本文關注的是無向網絡中的鏈路預測問題,因此需要把有向鏈路轉換成無向鏈路,并去除在此過程中產生的重邊。最終得到的網絡具有無向鏈路621 875條,其中用戶節點的最大度數為3 219,最小度數為4。
本文所用到的文本內容數據包括用戶原創和轉發的微博,每條長度不超過140個中文漢字。在采集到的數據中,絕大多數用戶發表的微博數都在20到60條之間,占總人數的78.3%。為了取得更好的主題建模效果,將屬于同一個用戶的所有微博內容進行拼接,以避免在主題建模的過程中由于文本稀疏性而引發的詞頻共現性較差等問題,因而最終得到了對應于每個用戶的54 119條長度不同的文本內容。
對于每條長文本,首先去掉微博內容中的標點符號、特殊字符以及外文字符,進而去除停用詞并進行中文分詞。本文所使用的分詞工具是北京理工大學發布的NLPIR中文文本分詞系統[9]。
2 預測特征
本節中分別給出本文在進行鏈路預測時用到的9個基準結構預測特征、2個由用戶主題分布直接計算得到的內容相似性特征以及6個由對主題分布進行進一步挖掘得到的用戶內容特征。
2.1 結構預測特征
結構預測特征是基于網絡結構數據計算得到的用于表示社交網絡中節點對的結構相似性。本文用做基準的結構特征包括CN、LHN、Salton、Sonrensen、Jaccard、Adamic-Adar(AA)、PA、HPI和HDI指標[10],分別設為S1、S2、S3、S4、S5、S6、S7、S8和S9。
2.2 直接內容特征
文本內容特征的提出是建立在相鄰用戶具有更高內容相似性的假設之上的。對于數據預處理之后得到的中文文本分詞結果,應用LDA主題模型進行文本建模,得到每一個用戶的主題分布,主題個數為100。
基于得到的用戶主題分布,本文給出2個直接計算得到的相似性度量指標:
(1)主題相關性系數Rxy。相關性系數能夠度量兩個變量之間線性相關關系的密切程度,因此本文通過計算不同用戶的微博文本內容在主題分布上的相關性系數,來度量用戶之間的主題相似程度。已知用戶x和用戶y的文本內容在n個主題上的分布θx和θy,則相關性系數的計算方法為
(1)

(2)主題熵Hx。在本文中,熵被用于度量用戶主題分布的無序性,對于用戶x的內容在n個主題上的分布,其主題熵的計算公式為
(2)
當用戶內容在主題上不是服從均勻分布,而是集中分布在一個或少數幾個主題上時,用戶的主題熵較小,這反映了用戶愛好比較集中的現象;相反,當用戶的主題分布較為均勻,沒有明顯的傾向性時,用戶的主題熵較大,這說明了用戶的愛好比較廣泛。為了評價任意一對用戶x和y在興趣愛好的集中程度上的差異性,本文采用主題熵之差的絕對值作為度量指標,其計算公式為
(3)
如果該指標的取值較小,則說明用戶x和y的興趣愛好的集中程度比較接近,反之則說明集中程度的差異性較大。
2.3 間接內容特征

(1)共同興趣主題數設為F1。對于用戶x和y,該特征是他們主題集合Tx和Ty的交集,反映了兩人興趣主題集合的重疊數目。具有越多共同話題的用戶之間的共同興趣主題數越高。
(2)共同興趣主題占比設為F2。對于用戶x和y,該特征是他們興趣話題集合Tx和Ty的交集與并集之比,反映了共同興趣主題占兩人所有愛好主題的比例。若兩人具有較多的共同興趣主題數和較少的總愛好主題,則該特征取值較高。該特征刻畫了兩人興趣主題集合的重疊程度。
(3)以主題分布概率賦權的共同興趣主題數和共同興趣主題占比分別設為F3和F4。
3 實驗對象和算法
本文所采用的數據集為2014年8月31日當天采集得到的靜態數據,通過按相同比例隨機抽取該數據集中存在鏈接與不存在鏈接的節點對,構造出無重復的訓練數據與測試數據。
由于實驗是判斷給定的靜態網絡中任意兩點之間的鏈路是否存在,因此用1表示鏈路存在,用0表示鏈路不存在,可以將該問題轉化為二分類問題。在此基礎上,在監督學習框架下對結構特征、直接內容特征和間接內容特征的預測能力進行評價。首先通過每個特征的獨立預測效果對結構特征和內容特征的預測能力進行比較,進而在多個分類器中對這些特征的整體預測效果進行評價。

表1 內容特征
4 實驗評價
本節在監督學習框架下對提出的預測特征進行評價,以驗證本文所提內容特征在鏈路預測應用中的有效性。
4.1 獨立特征評價
分別應用9個基準結構特征、2個直接內容特征和6個間接內容特征在新浪微博數據集上進行鏈路預測,并采用基于抽樣方法實現的近似AUC得分進行效果評價[11]。
對于每個特征,在新浪微博數據中進行30次隨機抽樣,每次抽取100 000組樣本,并計算其AUC得分,其中結構特征和直接內容特征如圖1所示,間接內容特征分別在p值為0.2、0.4、0.6和0.8時進行計算,結果如圖2所示。

圖1 結構特征和直接內容特征的AUC得分

圖2 間接內容特征的AUC得分
由圖1、圖2可以看出,在獨立特征預測中,PA指標取得了結構特征中的最高得分。這說明該數據集中的鏈路通常存在于兩個度數較高的節點之間,即新浪微博用戶表現出較強的擇優連接特性。相應地,其他與PA指數存在負相關的指標預測效果相對較差。在直接內容特征中,主題相關性系數Rxy取得了最好的預測效果,而間接內容特征中的F5測度取得了更好的預測效果。
從整體上來看,內容特征取得了與結構特征相近的獨立預測效果,并且大多數內容特征的單獨預測能力都優于結構特征。間接內容特征在p值較小(p=0.2)時能夠取得最好的預測結果,而隨著p值增大,間接內容特征的預測效果隨之下降。直接內容特征中的主題熵差絕對值Dxy取得了最差的預測效果,幾乎與隨機預測器效果相同。
4.2 監督預測評價
本節在監督學習的框架下,給出了一個同時基于內容特征和結構特征的鏈路預測模型,以評價所提出特征的預測效果。首先利用邏輯回歸(LR)分類模型,對各個內容特征與鏈接存在與否的相關關系進行了檢驗;然后通過支撐向量機(SVM)、隨機森林(RF)、決策樹(DT)和樸素貝葉斯(NB)4種常用分類器進一步驗證同時基于內容特征和結構特征的鏈路預測模型的有效性。
邏輯回歸分類器的優勢在于不但能夠完成分類工作,還能夠在建模后檢驗自變量是否與因變量顯著相關,并且自變量對應的回歸系數可以顯示自變量與因變量的相關關系是正相關還是負相關。本文用邏輯回歸分類器判斷基于內容特征的各項指標是否具有較強的鏈路預測能力。
由于分類問題可看成是二分類問題,因此在邏輯回歸模型中,將節點對之間的鏈路是否存在作為因變量Y(取值為0或1);將結構特征、直接內容特征和間接內容特征作為自變量,分別用X1,X2,…,X17表示。設在n個自變量作用下鏈路存在的條件概率為P=P(Y=1|X1,X2,…,Xn),則可將LR模型表示為
z1=a-1+a1Xi1+a2Xi2+…+a17Xi17+εi
Pi=1/(1+ezi)
式中:a-1和aj分別表示回歸常數和第j個自變量的回歸系數;εi為隨機誤差項。本文對數據集中可觀測到的鏈路和未觀測到的鏈路進行了10組隨機抽樣,每組的抽樣規模為100 000,并保證正負樣本的比例相同。將其中的任意一組數據用于進行邏輯回歸分類器的訓練,就能夠得到與每個自變量一一對應的回歸系數及其顯著性指標,下面根據實驗數據進行詳細說明。
表2中列出了其中一組邏輯回歸分類器的訓練結果。標準誤差可用于評價回歸系數是否顯著不為0;z值是由回歸系數與標準誤差之比得到的,與p一起用于檢驗回歸系數為0的零假設。一般來說,取顯著性水平α為0.05,當p小于α時,說明回歸系數顯著不為0,即自變量與因變量顯著相關。由表2可以看出,只有Dxy的p大于顯著性水平α(α<0.166),因此除了直接預測特征中的主題熵之外,其他預測特征對鏈路存在與否均具有顯著影響。
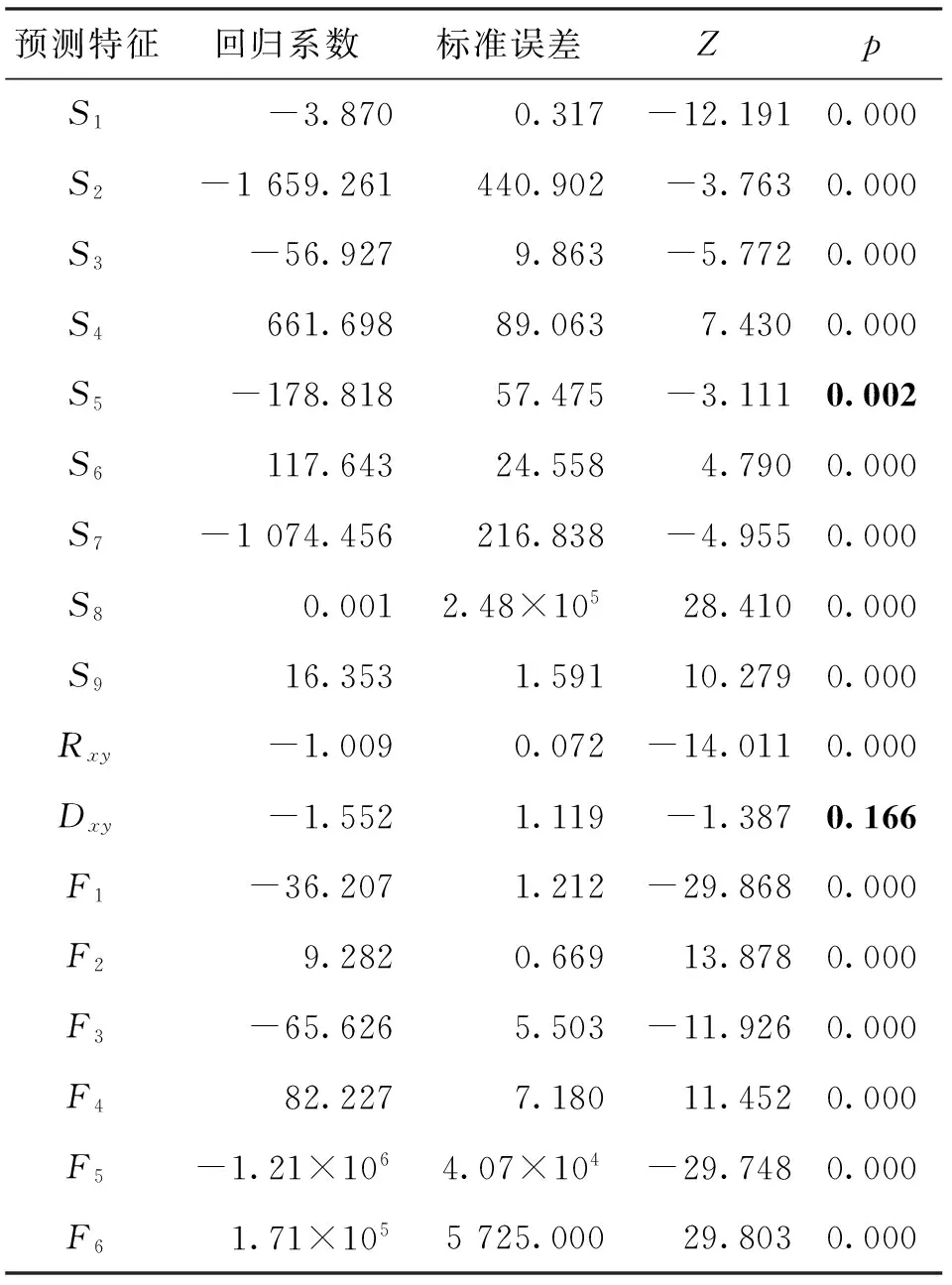
表2 邏輯回歸結果
在所有10組實驗中,結構相似性指標一致地表現出顯著性特征,其中F5在少數幾次實驗中不具有顯著性;直接內容特征中,主題相關性系數Rxy均表現出顯著性,而主題熵之差的絕對值Dxy均不具有顯著性;在間接內容特征中,所有自變量均一致地表現出顯著性。實驗結果表明,在邏輯回歸分類器中,除主題熵特征外,其余文本內容特征均能夠有效地影響鏈路預測結果。
接下來,在支撐向量機(SVM)、隨機森林(RF)、決策樹(DT)和樸素貝葉斯(NB)4個分類器中對模型的預測效果進行進一步測試。實驗中訓練數據與測試數據的規模和抽樣方法與邏輯回歸分類器相同。在每個分類器中分別對結構特征、內容特征以及全部特征進行了測試,內容特征包括直接內容特征與間接內容特征,其中間接內容特征分別在p為0.2、0.4、0.6和0.8時進行抽取。所有的參數取值都是對10次重復實驗結果求得的平均值。模型的分類效果如圖3、圖4和表3所示。

圖3 全部特征的分類效果

圖4 內容特征的分類效果
對比各個分類器的F-測度可以看出,SVM分類器在3組特征下都取得了最好的預測效果,其次分別為隨機森林分類器、決策樹分類器和樸素貝葉斯分類器。對比內容特征和結構特征各自的預測結果,可以看出內容特征具有接近結構特征的預測能力,其中對于SVM分類器、隨機森林分類器和決策樹分類器,內容特征的預測效果稍差于內容特征,而對于樸素貝葉斯分類器,應用內容特征分類的召回率和F-測度明顯高于結構特征的相應值。對比全部特征和結構特征的預測效果,可以看出內容特征分別將傳統的結構特征預測效果(F-測度)提高了1.2%至3%,是對結構預測特征的有效補充。

表3 結構特征的分類效果
實驗中,內容特征和全部特征的預測效果均隨著p的增大而保持穩定或表現出不明顯的下降規律,但在p為0.2時均取得了最好的預測效果,這說明當主題占比p較小時,通過用戶的興趣主題集合得到的內容特征能夠更加有效地區分存在鏈路與不存在鏈路的用戶組合。
以上實驗結果表明,在監督學習框架下,內容特征取得了與傳統結構特征相近的預測效果,并且將兩者結合在一起能夠取得更好的鏈路預測效果。
5 結 論
在鏈路預測研究中,本文基于在線社交網絡中的節點具有豐富的內容信息這一特點,提出了利用文本內容進行鏈路預測的研究思路。對于用戶的文本內容,本文首先采用LDA主題模型進行文本建模,得到了所有用戶內容在各個不同主題上的分布,進而提取出主題相關性系數和主題熵兩個直接內容特征和其他間接內容特征。接著,通過獨立特征預測,將兩類內容特征與常用結構特征的預測效果進行了對比,發現除結構特征中的PA指標外,內容特征的獨立預測能力普遍高于結構特征。最后,結合結構特征、直接和間接內容特征給出了一個監督學習框架下的鏈路預測模型。實驗結果顯示,通過準確率、召回率和測度值進行評價,內容特征具有接近結構特征的預測能力,并且將兩者進行結合能夠取得更好的預測效果。
在實際應用中,常需要對用戶間鏈路的存在概率進行估計,而非簡單判斷鏈路是否存在,尤其是進行保守預測時。這時,可利用能夠給出概率估值的分類器或排序算法,例如本文所用的邏輯回歸分類器能夠給出樣本點的概率估值,Ranking SVM[13]算法能夠對樣本進行排序。在得到概率估值或樣本排序后,概率值更大或序數更小的樣本(未觀測到存在鏈路的用戶組合)更可能被預測為存在鏈路。
本文的工作可以在模型參數優化和內容特征挖掘等方面進行改進。例如:通過優化主題模型在短文本上的建模效果,可獲得更好的主題含義,進而得到解釋性更強的用戶內容特征;挖掘用戶微博的時序性和頻次性等信息,從而可提取更為豐富且合理的內容相似性特征等。
[1] 呂琳媛. 復雜網絡鏈路預測 [J]. 電子科技大學學報, 2010, 39(5): 651-661. Lü Lin-yuan. Link prediction on complex networks [J]. Journal of University of Electronic Science and Technology of China, 2010, 39(5): 651-661.
[2] 伍杰華. 基于劃分社區和差分共鄰節點貢獻的鏈路預測 [J]. 計算機應用研究, 2013, 30(10): 2954-2957. WU Jiehua. Link prediction based on partitioning community and differentiating role of common neighbors [J]. Application Research of Computers, 2013, 30(10): 2954-2957.
[3] QUERCIA D, ASKHAM H, CROWCROFT J. TweetLDA: supervised topic classification and link prediction in Twitter [C]∥Proceedings of the 4th Annual ACM Web Science Conference. New York, USA: ACM, 2012: 247-250.
[4] BLEI D M, NG A Y, JORDAN M I. Latent Dirichlet allocation [J]. Journal of Machine Learning Research, 2003, 3: 993-1022.
[5] PUNIYANI K, EISENSTEIN J, COHEN S, et al. Social links from latent topics in Microblogs [C]∥Proceedings of the NAACL HLT 2010 Workshop on Computational Linguistics in a World of Social Media. New York, USA: ACM, 2010: 19-20.
[6] EROSHEVA E, FIENBERG S, LAFFERTY J. Mixed-membership models of scientific publications [J]. Proceedings of the National Academy of Sciences, 2004, 101(S1): 5220-5227.
[7] RAMAGE D, HALL D, NALLAPATI R, et al. Labeled LDA: a supervised topic model for credit attribution in multi-labeled corpora [C]∥Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing. New York, USA: ACM, 2009: 248-256.
[8] CHANG J, BLEI D M. Relational topic models for document networks [J]. Journal of Machine Learning Research, 2009, 9: 81-88.
[9] ZHANG Huaping, YU Hongkui, XIONG Deyi, et al. HHMM-based Chinese lexical analyzer ICTCLAS [C]∥Proceedings of the Second SIGHAN Workshop on Chinese Language Processing. New York, USA: ACM, 2003: 184-187.
[10]DONG Yuxiao, KE Qing, WANG Bai, et al. Link prediction based on local information [C]∥Proceedings of the 2012 IEEE International Conference on Advances in Social Networks Analysis and Mining. Piscataway, NJ, USA: IEEE Computer Society, 2011: 382-386.
[11]呂琳媛, 周濤. 鏈路預測 [M]. 北京: 高等教育出版社, 2013: 82-87.
[12]KOSSINETS G. Effects of missing data in social networks [J]. Social Networks, 2006, 28(3): 247-268.
[13]JOACHIMS T. Optimizing search engines using click through data [C]∥Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA: ACM, 2002: 133-142.
[本刊相關文獻鏈接]
劉兆麗,秦濤,管曉宏,等.采用用戶名相似度傳播模型的線上用戶身份屬性關聯方法.2016,50(4):1-6.[doi:10.7652/xjtuxb201604001]
孟憲佳,馬建峰,王一川,等.面向社交網絡中多背景的信任評估模型.2015,49(4):73-77.[doi:10.7652/xjtuxb201504 012]
葉娜,趙銀亮,邊根慶,等.模式無關的社交網絡用戶識別算法.2013,47(12):19-25.[doi:10.7652/xjtuxb201312004]
張賽,徐恪,李海濤,等.微博類社交網絡中信息傳播的測量與分析.2013,47(2):124-130.[doi:10.7652/xjtuxb201302 021]
孫艷,周學廣,付偉.無監督的主題情感混合模型研究.2013,47(1):120-125.[doi:10.7652/xjtuxb201301023]
莫同,褚偉杰,李偉平,等.采用超圖的微博群落感知方法.2012,46(11):120-126.[doi:10.7652/xjtuxb201211022]
(編輯 武紅江)
A Link Prediction Method Based on Similarity of User’s Topics
WANG Feifei1,YANG Yang2,JIANG Fei2,XU Jin2
(1. Guanghua School of Management, Peking University, Beijing 100871, China; 2. Key Lab of High Confidence Software Technologies, Peking University, Beijing 100871, China)
A new topical feature extraction method based on similarities of user’s topics is proposed to solve the insufficiency of topical feature mining of link predictions in social networks. The topic distributions of social network users are firstly obtained using a topic model and then topic groups of interests for each user are extracted for further similarity-based feature extractions. The proposed topical features exhibit comparable performance of structural features and is efficiently combined with structural features to achieve better results in link predictions. Experimental results based on the dataset collected from Sina Microblog show that independent prediction of topical features is better than that of structural features and the F-measure of structural features is improved by up to 3% with joint predictions.
link prediction; user generated content; topic model; feature similarity
10.7652/xjtuxb201608017
2016-03-12。 作者簡介:王菲菲(1988—),女,博士生;許進(通信作者),男,教授,博士生導師。 基金項目:國家重點基礎研究發展計劃資助項目(2013cb329600);國家自然科學基金資助項目(61372191,61572492,61472433)。
時間:2016-06-27
http:∥www.cnki.net/kcms/detail/61.1069.T.20160627.1231.008.html
TP391.9
A
0253-987X(2016)08-0103-07
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
臺聲(2016年2期)2016-09-16 01:06:53
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
河南科技(2014年23期)2014-02-27 14:19:15
