網絡嵌入視角下達成注意力經濟的實證與仿真分析
2017-01-09 09:29:30唐四慧陳鶴鑫
華南理工大學學報(社會科學版) 2016年6期
唐四慧+陳鶴鑫


摘要:本文首先通過對豆瓣社區用戶的實際建邊行為的追溯,構建了個體獲取知識的異質樹狀網絡,然后從樹狀網絡結構出發模擬了三個個體經濟的網絡模型(DLA、DLCA、BA),用實驗數據統計得出與集體搜索效率相關的網絡屬性指標。結果顯示BA模型是以犧牲“公平性”來獲得小的平均最短路徑,集體經濟背后對應的不是個體的經濟。基于DLCA模型做了三個比對實驗,實驗結果證明在不同的“熟人”推薦策略下得到的網絡可以同時滿足個體經濟和集體經濟。在個體有限注意力條件下,異質樹狀網絡是高效獲取知識的方式,在理論上為社區的建設提供了設計建議同時也將復雜網絡的研究貼近實際,用以指導個人經濟有效的使用注意力。
關鍵詞:個體注意力經濟;集體注意力經濟;網絡優化;異質樹狀網絡
中圖分類號:C931文獻標志碼:A文章編號:1009-055X(2016)06-0035-06
doi:10.19366/j.cnki.1009-055X.2016.06.006
諾貝爾獎獲得者赫伯特·西蒙(HerbertA.Simon)應是注意力經濟概念的最早提出者,在他的書中寫到:“在信息豐富的世界里,意味著某些東西是稀缺的。因為信息是豐富的,那么稀缺的就是信息消費的東西,這種東西就是消費信息時接受者的注意力。因此我們在過載的數據中收集信息時,需要經濟有效的安排我們的注意力。”[1-2]
在互聯網的世界里,簡潔有效的收集信息的方法有兩種:一個是基于自己以往的經驗——朋友推薦的方法,另一個是基于陌生人的經驗——擇優連接。[3]基于朋友推薦的方法就是去關注朋友關心的事務,既然是興趣相似的朋友,那么朋友去關注的東西總是有朋友的道理;擇優連接的理由是關注大家都關注的東西總是沒錯,錯也是大家一起錯。這兩種高效的信息過濾方法聽起來都有各自的道理,那么大家都采用了相同的策略,群體是否會達成注意力經濟;在時間維度上是否會經濟?
本章分為四部分,第一部分,分析兩組獨立的豆瓣用戶的關注行為、參加小組行為數據證實朋友推薦的方法普遍存在。提出個體獲取知識的樹狀網絡模型。第二部分,用DLA模型模擬這種樹狀網絡的生成過程,揭示網絡規模與知識獲取步數呈現非線性關系。進一步用DLCA模型還原多人合作情景。用整體網絡指標比較DLA、DLCA、擇優連接模型的信息獲取效率。第三部分,以DLCA模型生成的網絡結構作為Agent交互的基底,模擬三種知識尋找策略。通過最后的網絡的結構評價這三種策略的經濟性。第四部分,結合實證分析與仿真實驗提出高效的知識獲取方式應是一種多標準下的熟人推薦方式。它不僅可以達到個體搜索效率的最優而且可以達到群體搜索效率的最優。
一、基于豆瓣社區個體注意力經濟的實證分析
(一)熟人推薦方式的存在
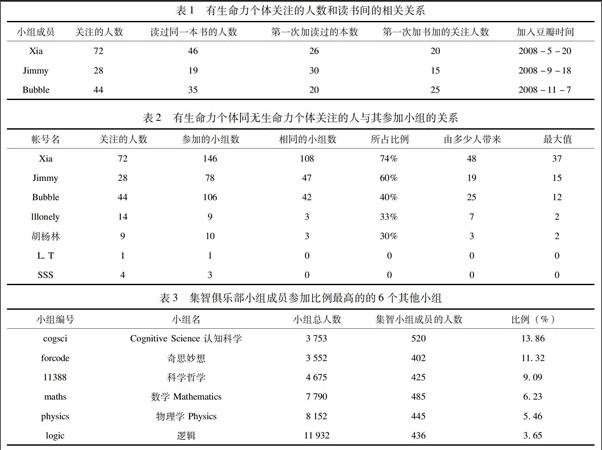
對于個體注意力經濟的實驗過程,包括樣本的確定,實驗過程,實驗平臺,數據分析方法我們在另外的文章中有詳細的論述[4-5],這里只將與本文有關的過程和研究結論做一闡述。2008年10月要求2005級人力資源班學生在豆瓣網上建立小組,共建三個小組分別為:“貪吃蛇”“最愛港產片”和“時光影像”。時隔四年,這三個小組已不具成長性,小組中沒有新的內容,新的成員或新的活動舉辦,但小組中有些成員一直在更新自己的主頁,分享自己的知識與讀書心得。我們取出這些有生命力的成員,對他們的網絡進行分析,為什么要分析有生命力成員的原因在于我們認為這些成員可以經濟地使用自己的注意力,這種經濟性讓這些成員保持了興趣。通過有生命力個體讀過書的時間序列與添加關注用戶的時間序列的相關分析,發現有生命力個體會通過自己讀過的書來找到關注的人。如表1所示。
接著分析有生命力個體與無生命力個體關注的人的時間序列與參加小組間的相關分析,發現有生命力的個體有通過關注的人去參加新小組的現象,而無生命力個體則相對較少用關系。如表2所示。
同時,為去除樣本對于分析結果的影響,我們采用整體抽樣的方法,抽取一個有生命力的小組——集智俱樂部小組,查看其用戶參加其他小組的信息,并分析小組組員參加小組時是否會用到以往連邊。如表3所示。
在前六個小組里,有五個小組是集智俱樂部的友情小組,只有最后一個邏輯小組不列在友情小組的集合中。從以上的數據分析中我們可以看到,在有生命力組員和小組中都有較大的比例是通過熟人推薦的方式進行知識的搜索。
(二)個體知識獲取的樹狀網絡結構
在對用戶行為分析后,發現在一個時點上看到的都是該用戶看了什么書、想看什么書、關注了什么人、參加了哪些小組,按傳統的網絡分析方法,這些均為該節點的度,計算指標只有一個。但從時間序列連邊行為進行觀察后發現,這些關系之間是有先后順序的,一些邊是來自于用戶原有一些邊的推薦,如果沒有時間序列數據的支撐,這些先后的順序就被隱藏了,我們分析時將這些形成過程按先后順序進行恢復,用來顯示“度”以外的一些特性。用戶理性成邊的過程還原如圖1。
圖1中,在原有的網絡分析中只看到一個平面的一度的網絡結構(圖中虛線部分表示的連線)。依據成邊的先后將該網絡層次化,成員A及成員B都看過書A,這樣通過讀過同一本書的關系形成的連邊1,成員A關注了成員B后,看到成員B讀過的書B,這時產生連邊2(通過推薦形成的邊,在圖中用虛線表示),表示自己也想讀這本書;同時成員A看到成員B參加了小組A,產生連邊3;成員A參加了小組A后發現小組A的友情小組B不錯,產生連邊4,成員A參加了小組B;接著成員A看到小組B收藏有書C,并對書C產生了興趣,產生連邊5。整個圖給出成員A形成自己網絡的先后順序,所有這些成邊由有生命力的用戶的時間序列相關性分析可以得出,這體現了成員A理性的一面。[5]
二、注意力經濟達成的仿真建模
(一)樹狀網絡仿真模型
本文用有限擴散凝聚(Diffusion-limitedaggregation)網絡模型來模擬樹狀過濾信息網絡的生成過程。[6]DLA最早來自于物理學的分形體研究,在這里將之映射為Agent搜索知識的過程,個體通過累積結成自己搜尋知識的樹狀網絡,如圖2所示。整個知識的搜索過程被分為兩個階段,首先是從圖2中黑色區域到達樹狀網絡,然后樹狀網絡中的邊緣知識由熟人推薦進入中心點。在(200*200)的平面中心處置入種子,種子最早進入網絡,實驗中可理解為信息接收者,接著隨機放置另一個粒子(選擇范圍是4萬),可理解為接收者不知道的知識,粒子隨機游走(也可理解為擴散,因為它不知道種子節點的具體位置),當它運動到種子旁邊時,停止行走,與種子建立連邊,這里演示的是粒子在找種子。因為運動是相對的,也可理解為種子在找這個粒子。接著第二個粒子被釋放出來,也是隨機游走,當它靠近種子或第一個粒子時,也停住不動,與它相鄰的那個粒子(種子或第一個粒子)建立連邊……如此反復,得到一個樹形結構的網絡,圖2中A圖為粒子數為3000的樹形結構的凝聚體,B圖顯示出新加入加點找尋到樹狀網絡所需要的步數,紅線為總搜索的平均步數。因為樹狀網絡達到3000個粒子時,其半徑只有113,相對于黑色區域的找尋步驟要小很多。
在模型模擬的情境為假如個體對一件事一無所知時,在沒有這種樹狀的信息獲取網絡時,尋找知識需要的步數是6個數量級,而有了樹狀信息獲取網絡后,這一尋找過程只要3個數量級的步數。B圖中,我們可以看出隨著樹狀結構的不斷增大,搜索的平均步數逐漸下降(紅線部分)。A圖中,藍色節點為后1500個節點,這些節點可理解為新的知識,這些知識通常是先被樹最外面的分枝俘獲,只有極小數的藍色節點進入樹狀結構的內部,實驗中共產生粒子3016個,其中由粉色粒子捕獲的藍色粒子有290個,種子節點捕獲的藍色粒子數為0個,藍色節點捕獲的藍色粒子數為1226個,這一過程在物理學中被稱為屏蔽效應,我們可以理解為,中心節點在獲得新的知識時,更多的來自于自己網絡中的其他節點,只有非常非常少的新知識(藍色節點)是自己直接俘獲的;同時也可理解為中心節點會屏蔽隨機進入的藍色節點,網絡規模越大被屏蔽的可能性越大,過濾信息的效果越好。
(二)多人合作網絡的仿真模型
在現實生活中,找尋知識的動作不是單個個體獨自進行的,而是很多個節點同時進行,那么如果把DLA模型中的中心點放寬為多個,DLA模型就轉變為有限擴散集團凝聚(DLCA)模型,在這個模型中中心粒子是多個。[6]與DLA不同的是DLCA模型中初始狀態是許多的單體粒子被放置在二維網絡中,所有粒子都處于隨機游走的狀態。當相鄰的格點被隨機行走的粒子占據后,相鄰粒子形成一個聯合體,然后該聯合體作為一個單體再隨機運動,這樣不斷地繼續下去,直到形成一個聯合體。如圖3所示。
網絡中Agent數為3000,粒子形成終態凝聚體只需1200多步少于DLA模型的3000步。這是一種與現實比較接近的多人搜尋知識過程,這個凝聚體比DLA模型的凝聚體要開放和松散些。
(三)擇優連接仿真模型
新發表的文章更傾向于引用已被廣泛引用的重要文獻,新的網頁上的超文本鏈接更可能指向新浪、雅虎等著名的站點。在找尋知識的過程中,最省力的方式就是關注熱點,這些熱點通過吸引了很多人的注意力后再去獲得更多的關注。這種現象被稱為“富者更富(richgetricher)”或“馬太效應(Matrheweffect)”,從信息接收者的角度來看這也是較省力的過濾信息的方式。為解釋這一現象,Barabási和Albert提出了BA模型,BA模型的兩個重要特性[7]:
(1)增長(growth):指網絡的規模是不斷擴大的,主要是指節點數量不斷擴大。例如,每個月都會有大量的新的科研文章發表,而WWW上則每天都有大量新的網頁產生。
(2)擇優連接(preferentialattachment):指新增節點更傾向于與那些具有較高連接度的“大”節點相連。通過這兩個建邊規則構建了一個BA網絡,網絡中的節點數為2397個,與DLCA模型相似擇優連接也是基于多個個體的選擇進行結網的過程,不過個體的判斷是基于他人的行為來連入網絡,DLCA模型則基于自己的積累,如果與自己相連的人找到了粒子自己也就算找到了。如圖4所示。
(四)三個網絡與集體注意力經濟相關的網絡統計數據
在BA、DLA及DLCA模型中,討論了個體搜尋信息的方式,以及單個個體和多個個體行動形成的網絡,經過一段時間后,對這些行為形成的網絡進行整體性能的分析,用以發現這些網絡是否能達成集體注意力經濟。具體如表4所示。
表4中,在網絡中如果我們采用隨機游走的方式去找尋知識,那么搜索效率與網絡的平均路徑長度正相關的[8],從這一結論可以看出BA模型具有優勢,因為該模型的平均路徑長度只有7.5,DLA模型其次,DLCA模型最弱。再來看網絡的這種搜索特性是如何達成的,BA模型中節點度的差異性最大,節點度之間差了三個數量級,標準差為3.6,而DLA模型節點間的度數差別不大,最大的也只有5,最小的為1,標準差為0.79。與DLA模型相比BA模型犧牲了3個數量級的節點差異性換回了1個數量級的平均路徑長度,因此從經濟的角度來看DLA模型要有優勢。從個體的角度來看,在BA模型中介數中心性最大的和接近中心性最小的點都是度最大的點1。而在DLA和DLCA模型中,介數中心性最大和接近中心性最小的點不是度數最大的,這兩個點的度數均為3,在DLA模型中也不是種子節點。從這里我們可以看到在網絡DLA和DLCA模型中,個體通過較少的關注達到了好的效果(介數中心性最大和接近中心性最小),這就是我們要實現的個體注意力經濟。
三、個體與集體注意力經濟達成的仿真實驗
通過實證分析,我們知道個體在進行選擇的時候會通過熟人推薦的方式,或者是擇優連接的方式,我們把這兩種目前來看經濟的方式加載到模擬現實網絡的DLCA模型上,讓個體通過這兩種方式去搜尋知識,然后再比較經過一段時間的累積后這兩種方式在集體注意力經濟的表現上是否有差異。實驗參數的設定是依據DLA模型中個體嘗試的次數,我們在DLA模型上做了100次模擬,計算出初始種子的連邊(出度)平均數為4。在DLCA模型上讓每個Agent做均值為2的嘗試,這樣的嘗試按熟人推薦的方式和擇優的方式去連邊,然后再比較整體網絡與搜索相關的指標。實驗中DLCA_1模型是隨機選擇前向鏈接的鄰居的前向鄰居進行連邊;DLCA_2模型是如果沒有前向鏈接的鄰居的鄰居時,則隨機選擇一個節點進行連邊;DLCA_3模型是如果沒有前向鏈接的鄰居的鄰居時,則擇優連邊。如表5所示。
實驗后,我們看到僅通過熟人推薦的方式并不能使得網絡的直徑變小,它與DLCA模型還是在同一個數量級,網絡的特性還是與DLCA模型的特性一樣。但有了隨機連邊后,則網絡的結構發生了很大的變化,網絡的直徑只有9.2,其他特性與DLCA相似,網絡三種指標中的介數中心性改為另一個點2459,它的度數僅為5。加了擇優機制后,網絡的集聚系數雖然很大,但網絡還是回歸到擇優模型的那種網絡結構,具有中心性的節點也是度數最大的節點,節點與節點度數的差異更大了,網絡中心勢比前兩個網絡高3個數量級,但它的網絡直徑與DLCA_2模型的卻是在同一個數量級。
四、結論
人與人之間的關系起到的主要作用就是過濾信息,在豐富信息的世界里這是一種高效率獲取信息的方式,因此個體可以把多次注意力作用在同一個對象或相關對象后沉淀、固化為關系,通過這些關系去經濟有效地找尋自己需要的信息,是否通過個體經濟的方式就能達成集體的經濟,在網絡優化的過程中仍需要研究。在BA的擇優模型中,通過擇優度最大的點占據了網絡的介數中心性和接近中心性,該點也為此付出了比一般節點高3至4個數量級的連邊代價,而在WS的小世界模型中個體的連邊數是均勻分布的,但這個網絡的網絡直徑卻與BA模型是同一數量級,Watts在文章中給出的解釋是熟人推薦與隨機連接的方式共存造成了這一經濟現象[9,10],但如果個體習慣了熟人推薦方式然后還會有隨機連邊方式就不太符合人類行為一致性的解釋。在本文中,我們通過實證研究得出個體有通過熟人推薦的方式進行過濾信息的行為,在解釋模型中的隨機連邊方式時,我們采用另一維度的解釋來描述這一現象,如人們會通過書來找人,通過人來找小組,通過小組來找書,擴充了“熟人”的定義。本文中將人、書及小組看成不同的維度,在某一維度下某一行為是隨機的,但在另一維度下卻是“熟人”推薦。通過不同維度的熟人推薦方式的仿真實驗,看到無論在個體還是在群體上過濾信息都可以達到經濟的效果。通過多維度下的熟人推薦實現了個體經濟性與集體經濟的一致達成,這是以往的網絡研究中沒有發現的。在實際應用的設計時,可以設計多個關注點比如豆瓣社區中的書籍、音樂等,或者是將用戶分成不同的興趣小組,這樣在做熟人推薦方式時可以達到集體經濟。從復雜網絡研究的角度來看,改變了原來仿真過程通過調整參數的實驗范式,而是先從實際出發,依據實際個體中的行為方式來進行實驗的設計進而回歸到實際系統設計的建議,在論證環節上要更完善、更合理。本文的仿真實驗中的規則還可以做的更細致些,比如在隨機連邊時的概率、方式都可以再精確些,這是以后研究的方向。
參考文獻:
[1]SIMONHA.DesigningOrganizationsforanInformation-RichWorld[M].Maryland:JohnsHopkinsUniversityPress,1991.
[2]SimonHA.TheSciencesoftheArtificial[M].3rded.Cambridge,MA:TheMITPress,1996.
[3]LANHAMR.TheEconomicsofAttention:StyleandSubstanceintheAgeofInformation[M].Chicago:UniversityofChicagoPress,2006.
[4]唐四慧,楊建梅.兩種交互式信息傳播網絡的傳播模型比較研究[J].科學學研究,2008,26(3):476-479.
[5]唐四慧.異質復雜信息網絡上的搜索路徑研究[J].華南理工大學學報(社科版),2011,13(4):8-13.
[6]費孝通.鄉土中國[M].北京:人民出版社,2008.
[7]張濟忠.分形[M].北京:清華大學出版社,1995.
[8]BARABSIAL,ALBERTR.Emergenceofscalinginrandomnetworks[J].Science.1999,286:509-512.
[9]REAGANSR,MCEVILYB.Networkstructureandknowledgetransfer:theeffectsofcohesionandrange[J].Administrativesciencequarterly,2003,48:240-267.
[10]DODDSPS.ROBYM,WATTSDJ.Anexperimentalstudyofsearchinglobalsocialnetworks[J].Science,2003,301:827-829.
[11]WATTSDJ,DODDSPS,NEWMANMEJ.Identityandsearchinsocialnetworks[J].Science,2002,296:1302-1305.
[12]NEWMANMEJ.Thestructureandfunctionofcomplexnetworks[J].SIAMReview,2003,42(2):167-256.
[13]羅家德.社會網分析講義[M].2版.北京:社會科學文獻出版社,2010.
Abstract:Thispapershowsthat,basedontheretrospectoftheactualmakeedgebehaviorofDoubanusers,aheterogeneoustreenetworkofindividualsacquiringknowledgeisconstructed,andthenthreeindividualeconomicnetworkmodels(DLA,DLCA,BA)aremade.TheresultsindicatethattheBAmodelsacrificesfairnesstogetasmallaverageshortestpath.ThreecomparisonexperimentsbasedonDLCAwereconducted,andtheresultsprovethatthenetworkofdifferentacquaintancesrecommendedcanreachboththeindividualeconomyandcollectiveeconomy.Underconditionsoflimitedindividualattention,theheterogeneoustreenetworkisefficienttoobtainknowledge.
KeyWords:individualattentioneconomic;collectiveattentioneconomy;networkoptimization;heterogeneoustreenetwork
(責任編輯:潘江曼鄧澤輝)
