藏語語音合成系統的關鍵技術研究
2017-01-11 02:30:58劉芳
西藏大學學報(自然科學版) 2016年2期
劉芳
(西藏大學藏文信息技術研究中心 西藏拉薩 850000)
藏語語音合成系統的關鍵技術研究
劉芳
(西藏大學藏文信息技術研究中心 西藏拉薩 850000)
文章根據藏語的語音規律和特點,以統計聲學模型為基礎,對藏語語音合成系統中的語料庫設計與建設、韻律信息及標注、模型設計與訓練及語音合成等關鍵技術進行了分析,對藏語語音合成系統的實現具有一定的參考價值。
藏語;語音合成;統計聲學模型
引言
計算機語音合成是依據語音處理規則,將計算機自身產生或通過外部輸入所形成的文字信息,轉換成相應的語音信號并向外輸出的一種技術,是信息處理領域的重要研究內容之一。藏民族是中華民族大家庭中歷史悠久、文化發達的民族之一,藏語言作為藏文化傳承的工具,對于新思想、新技術的傳播起著巨大的作用。由于藏文特有的拼寫規則,藏語音獨有的發音方式和韻律,藏語語音合成技術研究在國內起步較晚。目前國內很多研究機構都在對藏語語音合成系統中的詞性標注、韻律分析、模型構建等關鍵技術進行了研究,一些藏語語音合成系統的產品也陸續推向了市場。
藏語語音合成系統關鍵技術的研究,將為藏語語音合成產品的實用化提供一定的技術支撐,對藏文化的傳播和促進西藏社會穩定發展具有重要意義。
1 藏語語音合成概述
藏語語音合成系統的最終實現主要靠語音的訓練及合成。在具體的訓練當中,運用HMM對頻譜參數、時長及基頻實施建模操作;在具體的合成當中,分析所輸入的文本內容,將訓練后的模型給與利用,預測參數并生成參數,然后利用語音的參數合成器,來實現對輸出語音的合成工作。

圖1 藏語語音合成流程圖
本文針對藏語語音合成系統,以統計聲學模型為基礎,分別從語料準備、韻律標注、模型訓練及合成等方面進行分析和描述。藏語語音合成系統的具體框架模式見圖1,在設計語音合成系統之前,根據藏語的音節結構和發音規律等特點,開展相應的前期準備,如語料庫的建設、數據的標注和系統模型中相應配置參數的設計和實驗等。
2 語料庫建設
拉薩語藏語語料庫是藏語語音合成系統的基礎內容,語料庫的構建流程如圖2所示。

圖2 語料庫建設流程圖
對于語料庫的建設,語料庫的規模應該是越大越好,設計也應該是動態的,可以不斷擴充。語料選擇的好壞是語料庫優劣的關鍵,對整個系統的性能起著重要的作用。藏語作為一種具有特殊性聲調的語言,在對語料的選擇上,主要考慮語句的持續時間、清濁搭配、音段的音聯現象及聲調的組合等方面,選出能基本覆蓋藏語當中所使用的有調音節[1]。
在海量的文本中,采用greedy算法完成語料的初選,選擇的語料范圍和分類要盡可能平衡,要考慮到不同發音人的年齡、性別、本語言中的句法結構及文本類型的比例,盡量選擇能反映本語言的發音特征、韻律結構、語調信息和發音變化的句子。再將選中的句子使用16 kHz的采樣頻率進行錄音,用.wav的格式存儲[2],最后再進行人工校對,去除錯誤的語音文件。
3 韻律信息描述與標注
設計出優質的語料庫之后,還需要對藏語特殊的音節結構及發音現象進行分析,下面分別從藏語的發音信息和韻律信息兩方面,對系統的語境信息標注進行描述。
3.1 發音信息的表示及標注分析
藏語語音分為輔音和元音兩種。氣流在口腔或咽頭受阻而形成的音為輔音;氣流震動聲帶,在口腔和咽頭不受阻而形成的音為元音。依據發音方法對藏語語音進行分類,可以分為塞擦音、鼻音及塞音等;依據發音部位的不同,又可劃分為喉音、舌根音及雙唇音等。發音信息的表示和標注,主要包括當前音素所具有音節當中的后音節的聲調信息、前音節的聲調信息等,還有當前音素當中所存在的發音特點[3]。
3.2 韻律信息相應表示和標注
對于藏語語音合成系統來說,語音韻律信息的標注須具備32個韻律特征,描述韻律單元的有句子(utterance)、韻律短語(phrase)、韻律詞(word)及音素(segment)等。分析韻律特征標注的信息,存在多個韻律層級單元所具有的位置信息,其中后向位置(Bw)、前向位置(Fw)為其主要內容。
3.3 標注信息的表示
語料上下文語境信息當中相應標注的部分信息描述和語境信息的符號表示,見表1。

表1 標注信息表
4 模型訓練
基于統計聲學模型的藏語語音合成系統,在前期運行環境的配置及數據準備操作完成之后,便開展模型的訓練。訓練階段主要包括預處理和模型訓練兩大部分。
4.1 預處理
在預處理階段,通過對語料庫中的語音數據進行分析,提取出相應的基頻和譜參數。在研究過程中,采用連續概率分布HMM對譜參數部分進行建模,而基頻部分則采用多空間概率分布HMM進行建模。根據先驗知識選擇一些對譜、基頻和時長等聲學參數有一定影響的上下文相關模型聚類[4]。
4.2 模型訓練
模型訓練過程主要包括模型的初始化、聲韻母的HMM訓練、擴展上下文相關模型的訓練、聚類后模型的訓練以及時長模型的訓練。
在開展語音合成訓練前,需要做與藏語相對應的模型參數的配置工作,即設置聲學參數,運用Mel倒譜系數(MFCC)來表征語音的音段特征,采用基頻(F0)表示語音信號特征,再加入相應的二階、一級差分,共78維;建模單元方面,需綜合考慮藏語音節結構和其所在位置。在基于統計聲學模型的藏語語音合成技術中,以聲母和韻母為合成基元,對聲母和韻母分別進行聲學模型訓練以確定最佳參數[5]。
通過計算相鄰幀間的一階與二階差分,得到各幀完整的觀測特征向量然后以訓練數據對應模型的似然值函數P(| Oλ)最大為準則,訓練一組上下文相關音素的HMM模型λ。這里表示觀測特征序列,(·)T表示矩陣轉置,N表示序列的長度。通過訓練之后,時長的頻譜及基頻便可得出,為下文合成環節打下基礎。
5 語音合成
通過對語料庫進行分析,得到經過處理的輸入信息。根據文本的環境信息和上下文相關基元序列,對基元進行搜索,從中得出狀態時長和頻譜的HMM及基頻周期。依據統計聲學模型,可以獲取到基元相應各個狀態的持續時間,并求出MFCC參數和基音周期,再將所獲得的數據,在合成器當中輸入,最終得到所需要的合成語音。總體來說,可將語音的合成部分劃分為參數生成和語音合成兩大模塊[6]。
5.1 參數生成
所謂參數生成,就是將相關數據開展相應的文本分析及深入處理操作,然后對輸入文本狀態序列進行深入的設置。此外,將已經設置好且訓練完成后的HMM模型,進行深入的合并操作和合并計算,最后計算出生成語音的logF0和MFCC參數。該過程的開展及實現,實質上是具體訓練過程中的部分逆推環節。由于清音部分對基頻參數的獲取和計算會產生一定的影響,需要先清除清音段,然后將各個清音段進行相應的拼接,并將其相應鄰接位置上的濁音序列在具體的一、二階進行置零處理,以便更好地進行相應動態特征的展現。當計算完濁音部分的logF0,再將清音部分的logF0在相關的序列當中進行插入操作,將其再按照最初狀態進行最后的輸出操作。
5.2 語音合成
本次研究所使用的MLSA濾波器,能夠與語音信號MFCC參數進行結合使用,并通過相應公式得到結果,最終實現指數函數形式。公式為:

統計聲學模型當中采用HMM系統,在系統當中通過對MLSA合成器進行綜合運用,最終便可生成所需要的語音,合成器示意圖見圖3。
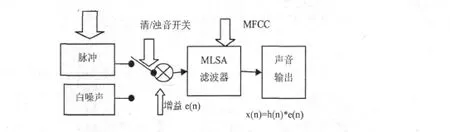
圖3 M LSA濾波器示意圖
在基于統計聲學模型的藏語語音合成系統中,使用MLSA濾波器作為合成器對聲道進行相應的模擬。本文研究所使用的模型系統,就是利用此濾波器過對聲道進行相應的模擬。對于聲門濁音部分運用了沖擊序列作為源;對于清音部分運用了白噪聲作為源。在語音合成時,通過分析輸入的文本,在系統參數生成模塊中獲得了激勵源基頻參數、聲道及增益參數,然后再將聲門波輸送到相應的濾波器當中,最后,得到具有很好韻律表現的合成語音。
6 結語
本文以統計聲學模型為基礎,分別從數據準備、韻律信息描述與標注、模型訓練和語音合成四方面,對藏語語音合成系統的相應框架及關鍵技術進行了剖析,并對其中一些參數的獲取給出了具體的實現公式,對藏語語音合成系統的實現有一定的參考意義。
[1]凌震華,王仁華.基于統計聲學模型的單元挑選語音合成算法[J].模式識別與人工智能,2008,21(3):280-284.
[2]陶建華,康永國.基于多元激勵的高質量語音合成聲學模型[J].中文信息學報,2004,18(03):73-80.
[3]陳國平.基于HMM的語音合成中聲學建模和模型訓練的研究[D].北京:中國科學院聲學研究所,2006.
[4]徐世鵬,楊鴻武,王海燕.面向藏語語音合成的語音基元自動標注方法[J].計算機工程與應用,2015,51(6):199-203.
[5]徐世鵬,楊鴻武,王海燕.面向藏語語音合成的語音基元自動標注方法[J].計算機工程與應用,2015,(6):199-203.
[6]胡郁,凌震華,王仁華,等.基于聲學統計建模的語音合成技術研究[J].中文信息學報,2011,25(6):127-136.
Research on the key technologiesof Tibetan speech synthesissystem
Liu Fang
(Research Center for Tibetan Information Technology,TibetUniversity,Lhasa 850000,Tibet)
According to the phonetic rules and characteristics of the Tibetan language,the key technologies including corpus design and construction,prosodic information and annotation,model design and training,and speech synthesis in the Tibetan speech synthesis system were analyzed based on the statisticalacousticmodel.It has certain reference value for realization of Tibetan speech synthesissystem.
Tibetan;speech Synthesis;statisticalacousticmodel
10.16249/j.cnki.54-1034/c.2016.02.014
TN912.33
A
1005-5738(2016)01-087-005
[責任編輯:張建偉]
2016-06-28
2015年度西藏自治區自然科學基金項目“基于統計聲學建模的藏語語音合成技術研究”階段性成果,項目號:2015ZR-14-12
劉芳,女,漢族,四川南充人,西藏大學藏文信息技術研究中心講師,主要研究方向為藏文信息處理技術。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
