基于補全矩陣的多標簽相關性情感分類①
2017-02-20 07:40:20許莉莉高俊波李勝宇
計算機系統應用 2017年1期
許莉莉, 高俊波, 李勝宇
?
基于補全矩陣的多標簽相關性情感分類①
許莉莉, 高俊波, 李勝宇
(上海海事大學信息工程學院, 上海 201306)
目前, 對新聞情感分類問題的研究大部分是從新聞作者的角度進行的, 而對讀者反饋的真實情感分析的較少. 本文從讀者角度入手進行情感分析研究. 提出一種基于補全矩陣的多標簽相關性情感分類模型, 采用LDA提取主題表示新聞文本, 然后通過使用標簽相關性矩陣對原始的標簽矩陣進行補全, 構造了一個增強的補全標簽矩陣模型(CM-LDA). 最后通過和原始矩陣的LDA模型進行比較, 該模型使最終的多標簽分類性能有了明顯的提高, 準確率達到了85.72%.
社會新聞; 情感分析; 標簽相關性; 補全矩陣-LDA(CM-LDA); 多標簽分類
1 引言
目前, 從作者角度分析, 有關新聞文本的情感分類研究已見成熟. 而從讀者角度分析的研究相對較少, 但也逐漸取得了不錯的成果. 臺灣的 Lin, Chen等[1]對于這個領域做了較詳細的研究. 他們利用 Yahoo!Kimo News 的數據, 研究讀者情緒. 研究中選取五種特征: 中文字符二元組, 中文詞, 新聞元數據, 詞綴相似度和情緒詞. 實驗結果表明利用SVM分類器與詞綴相似度和情感詞這兩種特征結合的方法得到了最好的準確率. Blei 和 McAuliffe[2]引入一個response 變量因子, 將文檔的標簽信息加入到構造的統計模型Supervised LDA中. 盧露等[3]從讀者的角度對新聞文本情感進行分類, 以新聞文章作為樣本實例, 以文章后讀者的投票信息作為樣本類別標注的先驗知識, 提出了一種半監督學習的分類模型, 實驗證明采用Bayes方法和EM算法相結合具有較高的分類性能. 國內的包勝華、徐生良等[4]考慮了在LDA的基礎上加上一層“情緒”參數, 將特征詞和讀者的情感關聯起來.
另外, 已有學者研究, 試圖將標簽之間的相關性影響應用到多標簽的分類算法中, 希望來提高分類的性能. 比如, 文獻[5,6]利用了標簽兩兩間的的相關性, 使系統的性能有了明顯地提高. 然而在現實中, 一個標簽可能會與其他標簽都有關系. 文獻[7]考慮了標簽之間所有可能具有的相關性, 即對每個標簽都考慮了其它標簽可能對它的影響. 文獻[8]考慮了標簽集中的隨機子集之間的相關性. 針對不同的領域提出了多種標簽相關性方法的應用, 取得了不同程度的情感分類研究成果. 針對本文的研究領域, 如何將標簽相關性有效地應用到多標簽分類的問題中, 是當前的重要問題.
針對情感分類和多標簽相關性分析的問題, 本文提出了在LDA模型能降維使數據處理耗時少的優勢上, 利用學習到的標簽相關性矩陣, 對多標簽標準化處理后得到的原始標簽矩陣進行補全, 構造了一個增強的補全標簽矩陣模型(CM-LDA), 從而來對讀者的情感進行分類, 以期達到更為準確的分類結果, 同時期望能對社會熱點新聞的輿情預測分析提供幫助.
2 相關工作
實驗采用的數據是從新浪社會熱點新聞網站上抓取的, 收集時間為2014.9-2016.3, 共8583篇, 具體信息包括新聞標題、發布時間、文本內容、讀者投票數據, 其中讀者情緒包括: 感動、震驚、搞笑、難過、新奇、憤怒等6種. 為了確保讀者的投票過程達到穩定的狀態, 在新聞發布一星期后進行采集. 然后進行數據凈化處理, 用中科院的中文分詞系統NLPIR進行分詞, 并通過完善停用詞表消除樣本中的停用詞噪聲, 得到了61,505個不同的詞. 本文是在LDA主題模型降低文本空間維度的基礎上, 提出了一種新的多標簽相關性情感分類模型, 具體工作流程如圖1所示.
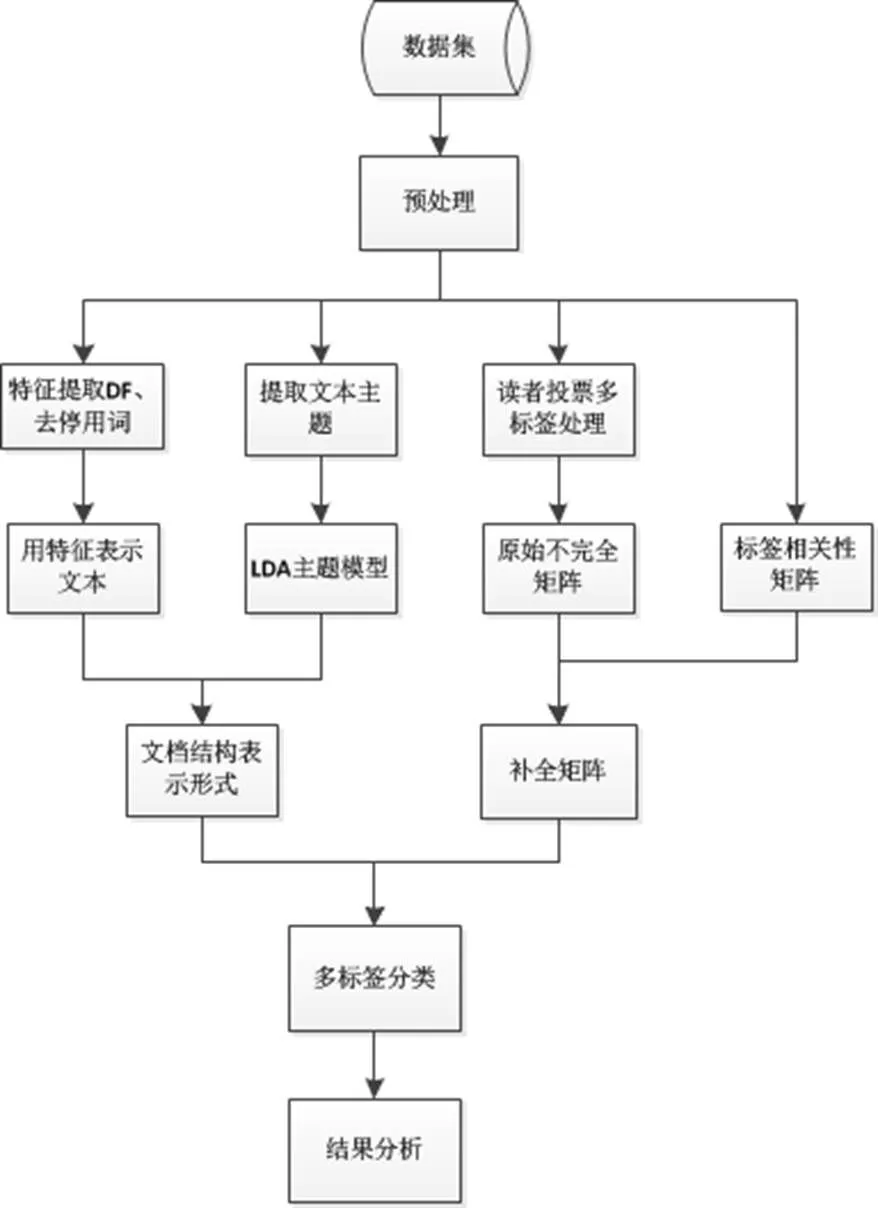
圖1 基于補全矩陣的情感分類模型
2.1 文本預處理
2.1.1 特征詞提取
特征詞選擇的目的是在不損失其他性能的前提下, 有效地選擇出較少的特征表示文本. 常用的特征選擇方法有:2統計量(CHI)、互信息(MI)、文檔頻率(DF)等. 本文選取的方法是DF, 即樣本中包含這個特征的所有文本數. DF是提取出DF值達到一定次數的特征, 低于該值的認為影響力小. 然后對提取特征詞后的文檔按照停用詞表去無用詞、消除噪聲.
2.1.2 LDA主題模型
在文獻[9]的研究中說明了讀者情緒與文本主題具有一定的相關性. 于是, 本文就引入了LDA模型, 其是一種無監督的機器學習技術, 也是一種典型的詞袋模型, 是通過采用Gibbs Sampling進行推導的. 而且LDA模型能有效的將高維的文本轉化到較低的主題維度空間. LDA主題模型是三層模型: 文本-主題-詞.
通過對文本的預處理及LDA主題建模將非結構化的文檔表示為結構化的數據, 處理之后的文檔格式如圖2所示.
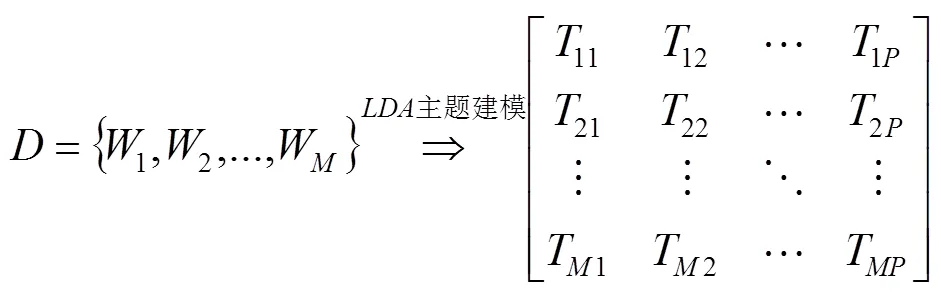
圖2 文檔集主題概率生成形式
2.2 CM-LDA建模步驟
2.2.1 多標簽處理問題
在早期研究文本分類時, 遇到的歧義性問題[10]提到了多標簽學習概念.
定義. 設一個樣本的特征向量=(1,2,...,x), 其中; 候選標簽集合=(1,2,...,l), 文本所對應的標簽集合=(1,2,...,l),, 即; 則包含個樣本的多標記數據集合表示如下:
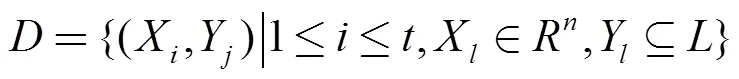
式(1)中X表示一個樣本向量,Y表示該樣本所對應的標簽集. 多標簽分類算法認為樣本中的標簽是獨立的, 沒有考慮它們之間的相關性. 本文提出, 首先利用多組實驗統計得到穩定的相關性矩陣, 然后用相關性矩陣對原始不完全的標簽矩陣進行補全, 最后采用分類算法RAkEL進行分類. 不需要像王霄等[11]對訓練集進行擴展, 而是利用多標簽標準化算法對語料的讀者投票數據處理, 使每個樣本的讀者情感標簽不超過三個, 為滿足該條件本文取閾值為0.45. 多標簽標準化算法如下:

1 讀入N篇新聞文本的讀者投票數據2 data = originalData(:,1:6);3 mean_row = mean(data,2);4 std_row = std(data,0,2);5 [row,col] = size(data);6 for i = 1:row7 data(i,:) = (data(i,:)-repmat(mean_row(i),1,col))/std_row(i);8 end9 threshold = 0.45; 10 index_1 = find(data > threshold);11 data(:,:) = 0;12 data(index_1) = 1;13 sum_row = sum(data,2); % sum_row: 每個樣本中1的個數, 用于檢測是否在1和3之間14 若返回兩個空矩陣說明每個樣本中‘1’的個數都不少于1個且不多于3個!否則, 則不滿足條件, 需要對閾值進行調節!15 輸出文件.xls, 確定新聞文本的類別標簽
2.2.2 補全矩陣的LDA建模過程
以上2.1.2 LDA模型分類的研究中, 完全沒有考慮標簽之間的相關性. 現實中, 標簽之間的關系并不是相互獨立的, 而是在一定程度上是有聯系的. 本文采用文獻[12]介紹的多標簽相關性的二階策略, 考慮標簽兩兩之間的關聯關系. 那么, 通過數學統計分析得到了穩定性相關性矩陣, 如何將這種相關性矩陣應用到分類模型中, 能否使分類結果更準確呢?
為了解決這個問題, 本文考慮利用該相關性對初始標簽矩陣進行補全, 從而來得到包含更多標簽信息的補全標簽矩陣, 最后通過對得到的補全標簽矩陣建立模型以期達到更好的分類結果. 考慮到不同標簽間的共現性和依賴關系, 我們假設補全標簽矩陣的構建是由原始得到的不完全標簽矩陣和通過數組實驗準確學習的標簽相關性矩陣決定的. 具體如何構造, 是受標簽依賴傳播思想[13]的啟發, 即對不完全標簽矩陣和標簽相關矩陣直接進行矩陣相乘來補全增強(如圖6所示):, 其中補全矩陣中的每個元素代表第個樣本x標識為第個標簽的置信度, 而且該置信度會被原始矩陣中第個樣本x擁有的其他標簽的先驗條件所影響, 具體如下:
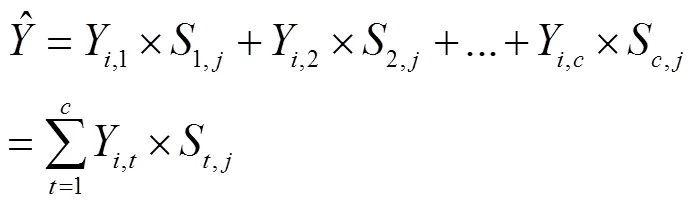
3 實驗與分析
3.1 多標簽分類算法及評估標準
本文多標簽分類算法選擇RAkEL分類器, RAkEL是構造了Label PowerSet(LP)[14]分類器的一個集成. LP算法是將全部標簽的每個子集看作是獨立的, 這樣可以將多標簽分類問題轉化. 但是, 測試樣本以及所有的子集個數決定了LP算法的計算復雜度. 隨著標簽數變多, 標簽的子集的數目呈指數級增長, 這樣LP算法的計算復雜度將會很大. RAkEL算法解決了這一缺陷, 僅僅利用了一部分子集作為標簽.
常用的多標簽分類評估準則為Hamming Loss(HL)、One-Error(OE)、Ranking Loss(RL)、Coverage(COV)、Average Precision(AVP). 前四個評估值越小越好, 但最后的AVP值越大則分類的準確精度就越高.
3.2 標簽相關性統計結果分析
通過上文提到的多標簽標準化算法, 對8583篇新聞的讀者情緒投票數據進行0或1標簽標識之后, 根據不同標簽數進行統計的結果如表1所示.
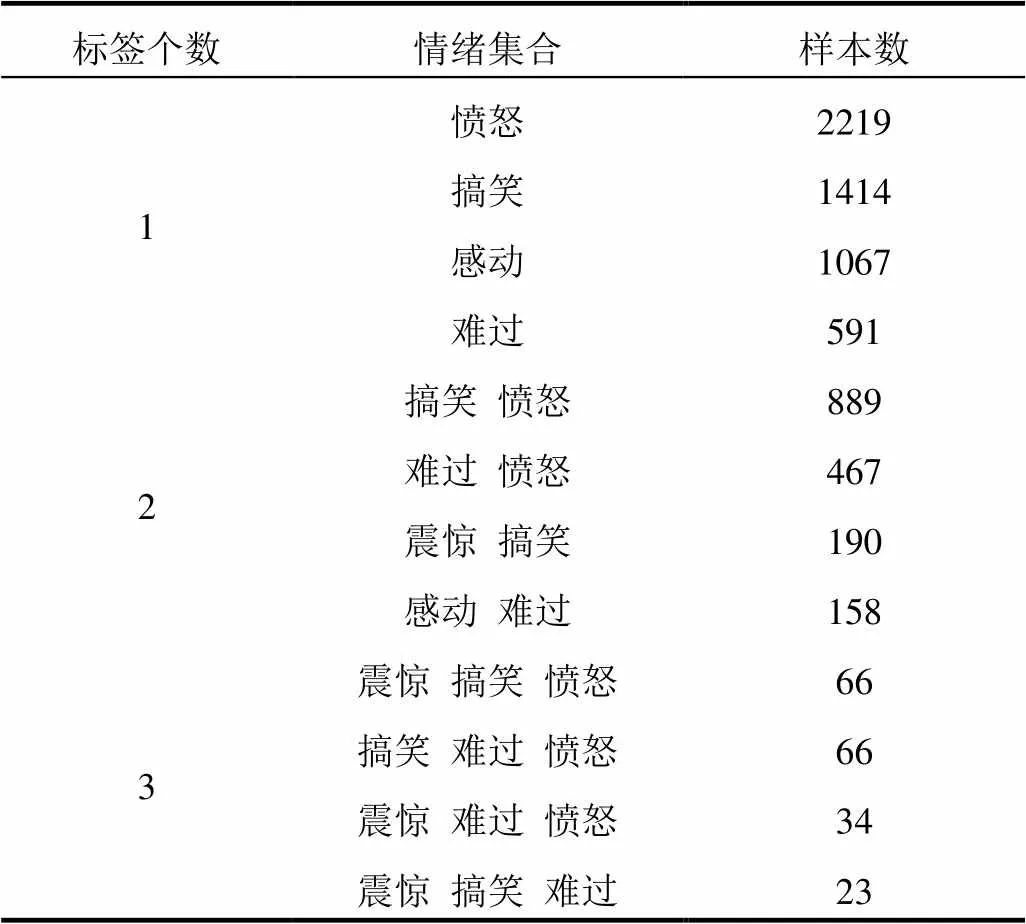
表1 讀者情緒標簽組合及對應樣本數
從表1中統計發現, 搞笑情緒和憤怒情緒組合出現的次數最多, 難過情緒和憤怒情緒次之. 在三個標簽的組合中, 震驚情緒、搞笑情緒和憤怒情緒組合也常出現, 對數據的處理也有一定的影響. 可見, 分析標簽相關性對情感分類的影響, 對原始標簽進行補全方法是可行的.
于是, 對3188篇、5235篇及8583篇新聞投票數據分別進行多標簽標準化算法處理, 通過多組實驗驗證, 統計相同標簽下不同文本數、哪些標簽共同出現在同一篇新聞的文本數, 來學習得到相關性矩陣. 橫坐標為讀者情感, 縱坐標為共現情緒在包含該情緒的總票數中所占比率, 結果如圖4、圖5、圖6所示.
從3個圖中發現, 讀者投票數據歸一化處理后, 兩兩標簽間的關系是一個穩定的狀態, 也就是說從數據中準確地學習的標簽相關性矩陣具有一般性, 即標簽之間的相關性大小趨于穩定, 如表2. 每行之和為1, 除對角線外其他行列對應的值為該列情感占該行情感的共現比率.
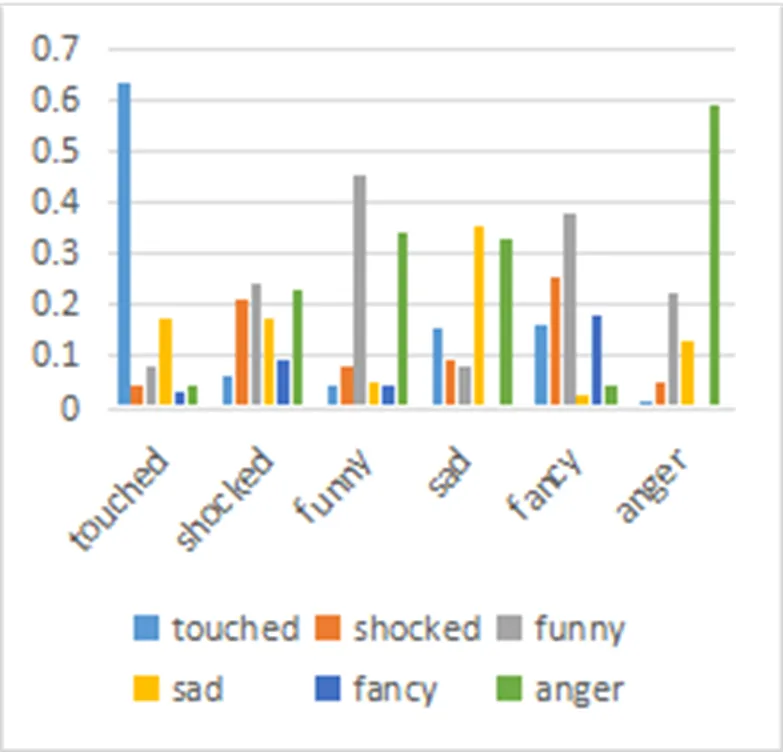
圖4 3188篇新聞讀者情感投票共現統計結果
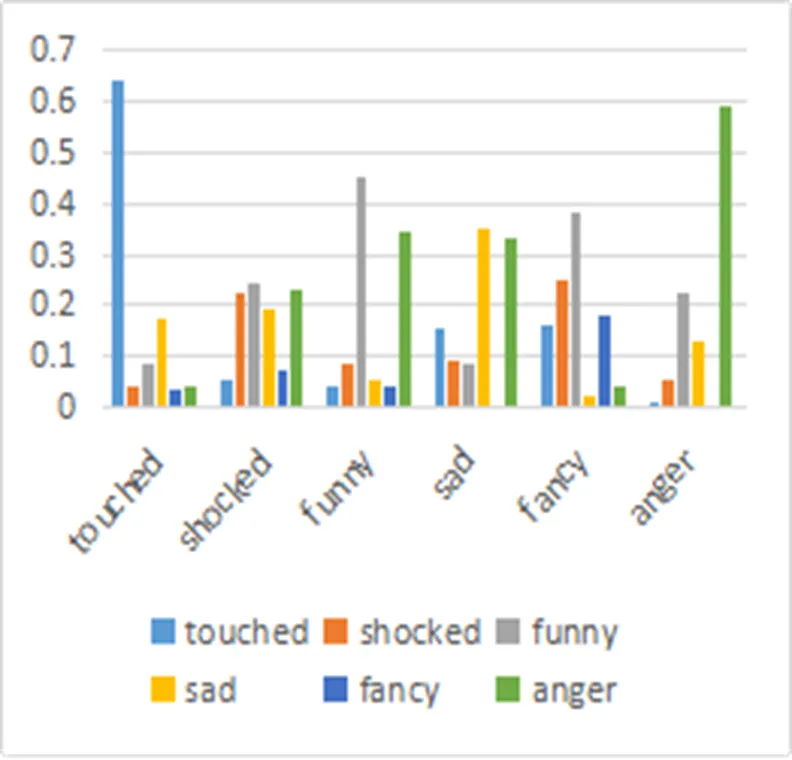
圖5 5235篇新聞讀者情感投票共現統計結果
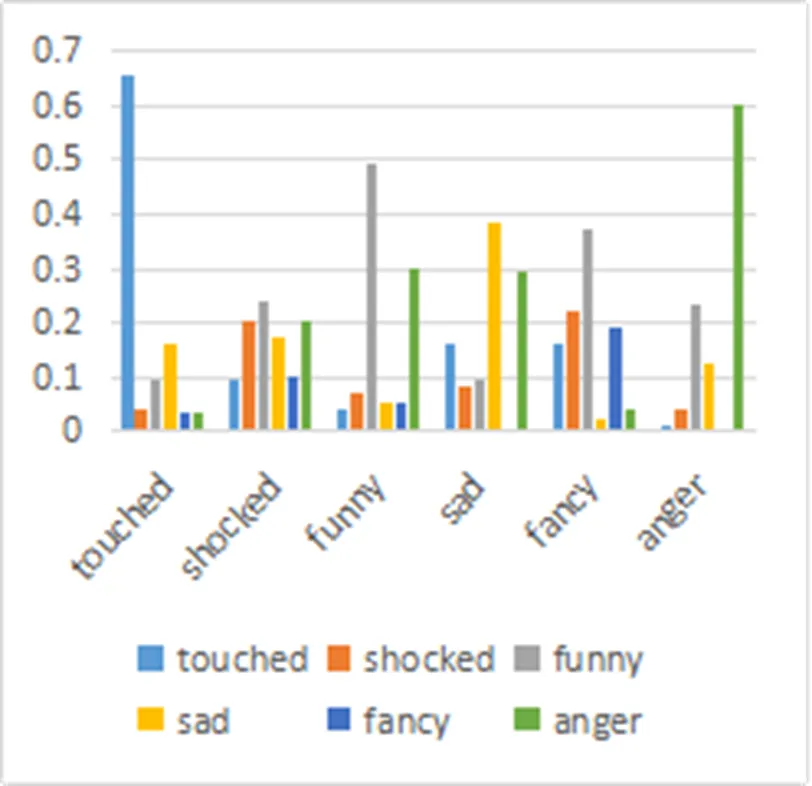
圖6 8583篇新聞讀者情感投票共現統計結果
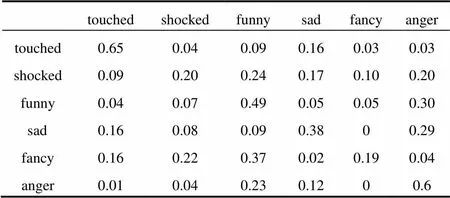
表2 讀者投票共現統計的相關矩陣
從上述表2中發現, 有些標簽兩兩之間確實存在著聯系. 對于包含震驚情緒的新聞總數中, 僅包含震驚情緒的新聞占總數的20%, 搞笑情緒竟占24%, 而憤怒情緒也占了20%. 可見, 在一篇新聞被確定為震驚標簽的時候會受到搞笑情緒和憤怒情緒的影響. 憤怒情緒和新奇情緒的共現率就很小, 幾乎互不影響. 因此, 標簽之間的共現模式一定體現了它們之間所蘊含的某種語義相關性.
3.3 實驗結果分析
本文將抓取的新浪社會新聞語料的7000篇作為訓練集, 剩余的作為測試語料. 實驗中, 取20到100, 得到9個不同主題數下的9種文檔表示, 然后使用RAkEL來多標簽分類. 將補全矩陣模型CM-LDA和原始矩陣的LDA模型在不同主題數下, 進行分類性能的比較, 加粗表示在該主題數下應用的分類模型性能最好, 實驗結果如表3所示.
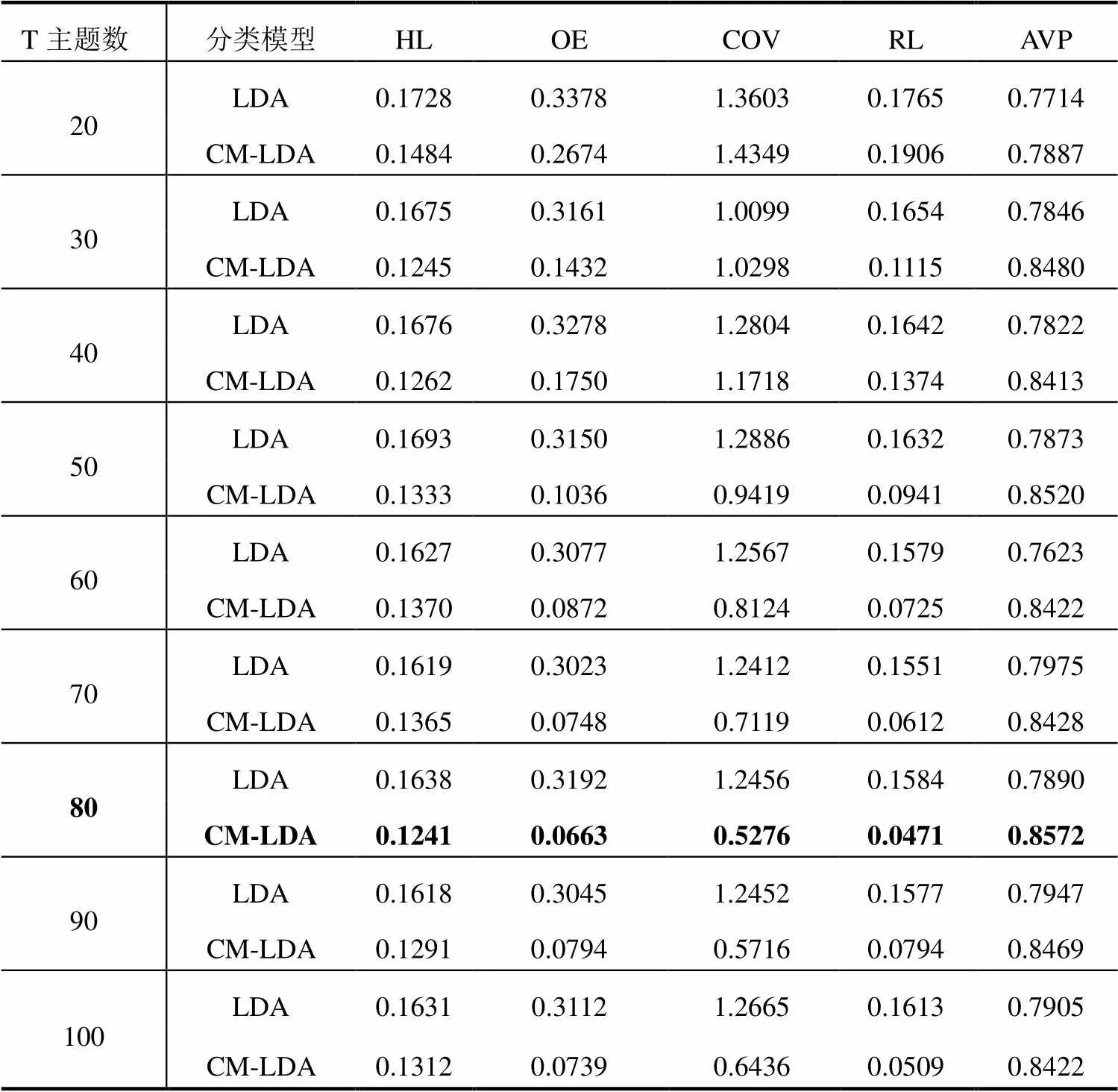
表3 RAkEL在不同主題數的CM-LDA和LDA模型下的分類性能比較
通過上表3可見, 補全矩陣模型CM-LDA比原始矩陣的LDA模型分類結果準確率高. 尤其是在主題數為80, 其他參數設置=0.5,=0.1時, HL、OE、COV、RL這四個評估標準均較低, 準確率也達到了85.72%, 可知該模型CM-LDA的綜合性能最優. 這說明, 在傳統的LDA主題模型上, 利用標簽相關性對原始不完全的標簽矩陣進行補全增強, 獲得的CM-LDA模型能夠改善多標簽分類的性能.
圖7表示在不同主題數下, 多標簽分類算法RAkEL在原始矩陣的LDA和補全矩陣模型CM-LDA分類準確率比較, 更清晰地將實驗結果展現在了曲線圖上. 很明顯地看到, 基于CM-LDA模型的分類準確率高于原始矩陣的LDA模型. 因此, 從整體的分類結果來看, 基于CM-LDA模型的讀者情感分類方法是可行的, 補全矩陣的應用能提高多標簽的分類性能, 同時也為接下來新聞讀者情感預測的深入研究做了鋪墊.
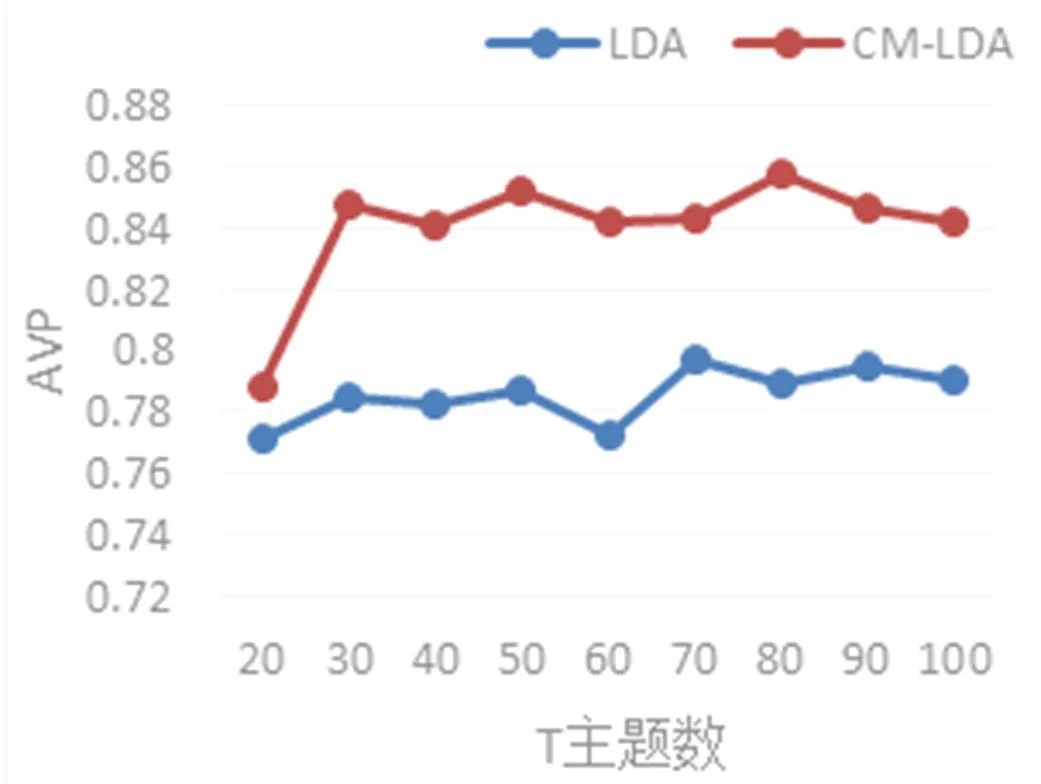
圖7 LDA和CM-LDA模型下的RAkEL算法分類準確率對比
4 結語
通過在真實多標簽數據集(即新浪社會新聞語料)上的實驗中, 學習到相關性矩陣, 然后對原始不完全矩陣進行補全獲得的補全矩陣, 不僅驗證了標簽間相關關系的語義合理性, 而且也證明了利用本文提出的CM-LDA模型進行多標簽分類的正確性和實用性, 這對熱點問題或突發事件做好社會輿情預測的研究是很有價值的. 而如何學習主題與標簽之間的聯系以及進一步獲得更高的讀者情感預測的準確率, 則是將來需要進一步研究的方面.
1 Lin KHY, Yang C, Chen HH. Emotion classification of online news articles from the reader’s perspective. Proc. 2008 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT ’08). 2008. 220–226.
2 Blei DM, Mcauliffe JD. Supervised topic models. Advances in Neural Information Processing Systems, 2010, 3: 327–332.
3 盧露,魏登月.基于讀者視角的文本情感分類.微電子學與計算機,2014,(10):122–125.
4 Bao S, Xu S, Zhang L, et al. Mining social emotions from affective text. IEEE Trans. on Knowledge & Data Engineering, 2011, 24(99): 1658–1670.
5 Zhang ML, Zhou ZH. Multilabel neural networks with applications to functional genomics and text categorization. IEEE Trans. on Knowledge & Data Engineering, 2006, 18(10): 1338–1351.
6 Fürnkranz J, Hüllermeier E, Mencía EL, et al. Multilabel classification via calibrated label ranking. Machine Learning, 2008, 73(2): 133–153.
7 Read J, Pfahringer B, Holmes G, et al. Classifier chains for multi-label classification. Machine Learning, 2011, 85(3): 254–269.
8 Tsoumakas G, Katakis I, Vlahavas I. Random k-labelsets for multilabel classification. IEEE Trans. on Knowledge & Data Engineering, 2010, 23(7): 1079–1089.
9 葉璐.新聞文本的讀者情緒自動分類方法研究[碩士學位論文].哈爾濱:哈爾濱工業大學,2012.
10 Schapire RE, Singer Y. BoosTexter: A boosting-based system for text categorization. Machine Learning, 2000, 39(2-3): 135–168.
11 王霄,周李威,陳耿,等.一種基于標簽相關性的多標簽分類算法.計算機應用研究,2014,31(9):2609–2612.
12 胡春安,范麗文,毛伊敏.HPDBSCAN:高效的不確定數據處理算法.計算機工程與設計,2013,34(3):1044–1049.
13 Pizzuti C. A multi-objective genetic algorithm for community detection in networks. 21st International Conference on Tools with Artificial Intelligence(ICTAI ’09). IEEE. 2009. 379–386.
14 Tsoumakas G, Katakis I. Multi-label classification: An overview. International Journal of Data Warehousing & Mining, 2009, 3(3): 1–13.
Emotion Classification of Multi-Label Correlation Based on Completion Matrix
XU Li-Li, GAO Jun-Bo, LI Sheng-Yu
(College of Information Engineering, Shanghai Maritime University, Shanghai 201306, China)
At present, most of the researches of sentiment classification are carried out from the writer’s perspective with quite few analyses from readers. This paper is to study the sentiment analysis from the news readers. A model of multi-label correlation sentiment classification based on completion matrix and LDA is proposed to extract the topic. The original news text is represented with the generated text-subject features, which are taken as the input to a subsequent classifier. Furthermore, the paper constructs a model of enhanced completion label matrix (CM-LDA) by appending the label correlation matrix to the original label matrix. Results show that the accuracy of this approach achieves 85.72% in the multi-label classification task, which outperforms the traditional LDA methods significantly.
social news; sentiment analysis; label correlation; completion matrix-LDA(CM-LDA); multi-label classification
2016-04-13;收到修改稿時間:2016-05-08
[10.15888/j.cnki.csa.005496]
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
風流一代·青春(2018年2期)2018-02-26 15:27:06
風流一代·青春(2017年6期)2018-02-14 19:28:55
風流一代·青春(2017年5期)2018-02-14 09:32:37
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學教學參考(2015年20期)2016-01-15 08:44:38
