醫學文獻檢索關鍵詞多維分析系統的設計與實現
2017-02-28 07:49:34曾展鵬
中國中醫藥圖書情報 2017年1期
關鍵詞:中醫藥
曾展鵬

摘要:針對臨床醫學文獻關鍵詞包含有證型、病癥、治療等特點,設計出醫學文獻關鍵詞多維分析系統。該系統以醫學文獻檢索關鍵詞分析為核心,包含文獻信息管理、詞頻分析、多維統計分析等功能模塊,能有效解決檢索文獻的批量導入、數據規范化、根據關鍵詞屬性進行多維度統計分析等問題。并以銀屑病的中醫藥治療為例,介紹該系統的使用及多維統計分析應用。該系統實現了在計算機輔助下進行快捷、方便、準確的關鍵詞多維分析,為其他醫學領域數據分析系統的設計和實現提供參考。
關鍵詞:中醫藥;文獻檢索;分析系統
中圖分類號:G254.9 文獻標識碼:A 文章編號:2095-5707(2017)01-0016-04
Abstract: A multidimensional analysis system for the key words of medical literature was designed according to the characters of clinical literature, including syndrome, disease and treatment. The system is based on the analysis on medical literature retrieval key words, including document information management, word frequency analysis, multidimensional statistical analysis and other functional modules, which can effectively solve the problem of batch retrieval of imported documents, data standardization, multi-dimensional statistical analysis according to the keyword attribute. Setting the treatment of psoriasis as an example, the use of the system and multi-dimensional statistical analysis application is introduced. The system provides a quick, convenient and accurate multidimensional analysis of the keywords, which can be used as a reference for the design and implementation of other medical data analysis systems.
Key words: traditional Chinese medicine; literature retrieval; analytic system
隨著計算機互聯網技術的快速發展,在大數據時代背景下,傳統的醫學信息檢索模式已經不能適應快速變化的需求[1]。《2015研究前沿報告》也明確提出了“科學研究的世界呈現出蔓延生長,不斷演化的景象。科研管理者和政策制定者需要掌握科研的進展和動態,以有限的資源來支持和推進科學進步”。“定義一個被稱作研究前沿的專業領域的辦法,源自于科學研究之間存在的某種特定的共性。這種共性可能來自于實驗數據,也可能來自于研究方法,或者概念和假設,并反映在科學家在論文中引用其他科學家的工作這個學術行為之中”[2]。所以對文獻信息的提取和關聯分析至關重要,它能揭示學科的發展,為科研人員指引研究方向。2015年,廣東省中醫院委托我校圖書館提供有關“銀屑病研究前沿與熱點”的情報分析[3]。該項目需要收集大量的期刊文獻,并在此基礎上,逐一分析銀屑病癥狀-證型、癥狀-治療、證型-治療之間的關系以及藥物配伍的關系。如果采用比較傳統的情報分析方法,整個過程將耗費較長時間。為此,我們開發了適用于臨床醫學文獻自動分析的情報分析系統。該系統實現了在計算機輔助下進行快捷、方便、準確的關鍵詞多維分析,并提取相關知識。
1 系統設計
1.1 數據庫設計
本系統開發選取了適合大量本地運算的C/S應用模式,開發語言為面向對象的編程語言VISUAL BASIC,采用SqlServer2005數據庫作為數據的組織和存儲對象。主要信息存放在文獻記錄表(WXJL)、關鍵詞表(GJCB)、同義詞表(TYCB)和詞類屬性表(CLSX)。其中WXJL保存導入的文獻記錄;GJCB保存從WXJL提取的關鍵詞信息;TYCB保存關鍵詞的同義詞,比如:高血壓、高血壓病、血壓高、原發性高血壓、一級高血壓、早期高血壓等均用高血壓病表示;CLSX用于類比關鍵詞屬性并對其逐一歸類,比如:血熱型屬于證型,克銀方屬于治療。
1.2 功能設計
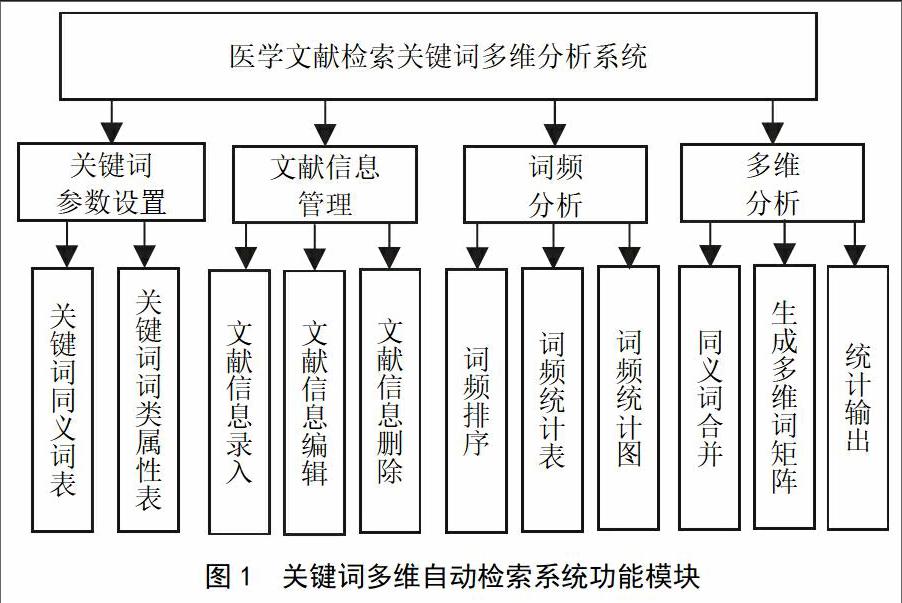
根據用戶目前的需求,系統主要有4個功能模塊。⑴關鍵詞參數設置:主要用于設定關鍵詞的TYCB和CLSX。⑵文獻信息管理:主要是對學術論文基礎數據的管理,它們是數據分析的基礎,主要實現對論文題目、關鍵詞和年份信息的錄入、編輯、刪除等功能。⑶詞頻分析:計算不同關鍵詞在所有選定論文中出現的頻數,對關鍵詞按頻數排序并確定高頻關鍵詞。在此基礎上,生成詞頻統計表和統計圖,便于研究者分析該領域的研究重點和熱點。⑷多維分析:多維分析是本系統的核心功能,主要完成同義詞合并、生成多維詞組矩陣、矩陣詞多維分析、數據轉存等功能。系統的具體功能結構如圖1所示。
1.3 統計分析原理
本系統的核心功能是對關鍵詞作多維統計分析,其原理是根據各種數據分類的度量關系,找出同類性質的統計項之間的聯系,是對數據進行維度化分析后的度量聚集統計。其中維度化是根據數據的特性進行分類,并建立多維矩陣。具體實現方法為:⑴從相關文獻數據庫中提取關鍵詞或主題詞,通過詞頻分析獲取代表某一學科研究主題或研究方向的高頻詞;⑵對高頻詞根據特性進行分類,形成各分類集合,分類集合之間相互組合形成多維矩陣;⑶圍繞該多維矩陣進行分析,統計這些詞組在同一篇文章中同時出現的次數。
多維分析的主要思路:在數據集中,若大量記錄在具有特征屬性A的同時,也頻繁出現了特征屬性B,則稱特征屬性A和B構成頻繁模式[4],表示A和B之間的關聯性,而這些模式可以用關聯規則來觀察和分析。
2 系統的程序開發關鍵技術分析與實現
為了更好地體現關鍵詞多維分析系統的實際應用效果,本文以“銀屑病研究前沿與熱點”為案例,展示系統的使用及原理。文獻來源數據庫為:中國知網(CNKI)、中國生物醫學文獻數據庫(CBM),時間段為2010-2015年。案例以檢索結果為分析對象,列舉多維分析系統在詞頻統計以及同義詞合并的應用,并從“證型-治療”2個維度進行統計。其中CNKI的檢索詞包括:銀屑病、牛皮癬、中醫藥、中成藥、中藥、中草藥、方劑,檢索途徑為“主題”;CBM檢索策略為:"銀屑病"[全字段:智能]OR"牛皮癬"[全字段:智能]OR"銀屑病"[擴展:不加權]AND中醫藥OR中成藥OR中藥OR中草藥OR方劑。
2.1 多數據源導入
根據檢索詞,本案例在CBM共獲得1389條記錄,如圖2所示;在CNKI共獲得1566條記錄,如圖3所示。對獲得數據進行分解,使文獻轉化為計算機能夠處理的結構化數據單元。然后通過對比查重、字段映射合并,使之規范、準確和有序。原始數據查重合并后共獲取記錄1863條。該數據表是數據分析的基本條件,處理后的結果如圖4所示。
2.2 關鍵詞規范化
文獻數據結構化處理后可進一步提取關鍵詞信息,并對其規范化處理。關鍵詞原始數據的不規范,主要表現為多詞一義,也即是同義詞現象。操作中,首先通過文獻記錄提取所有非重復關鍵詞,形成數據列表。然后對比同義詞庫逐一進行歸并。本案例共計提取關鍵詞3987條,通過臨床專家結合醫案認真討論和分析,篩選出銀屑病證型、治療相關的同義詞142條,合并后形成標準關鍵詞30條。如圖5所示。
2.3 關鍵詞屬性歸類
在關鍵詞庫數據集的基礎上,利用頻次分析,把頻次較高的關鍵詞組成高頻詞庫。通過下拉框從癥狀、證型和治療等方面選取相應的特征屬性。對新增的特征屬性,點擊添加按鈕增加并保存該分類詞庫。案例中30條標準關鍵詞按證型和治療2個特征屬性,得到12條證型記錄,18條治療記錄。如圖6所示。
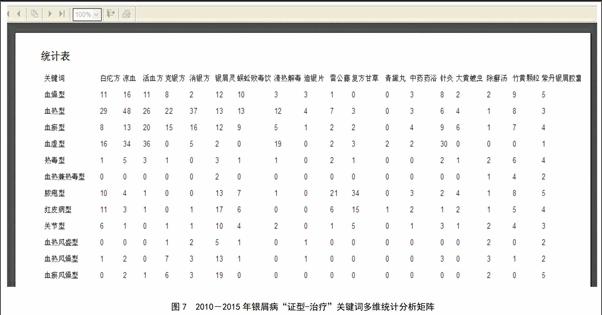
2.4 多維統計分析
通過12條證型記錄和18條治療記錄2個維度,交互組成12×18的二維矩陣,如圖7所示。統計分析后,得到共同出現頻率最高的2個關鍵詞為“血熱型”與“涼血方”,共計出現48次。其次為“血熱型”與“消銀方”共計出現37次。
統計結果符合臨床診斷和用藥規律,同樣統計方法適用于“癥狀-證型”“癥狀-治療”等其他維度分析。此外,通過查閱我校附院名中醫治療銀屑病的醫案發現,銀屑病目前尚無固定分型,但血瘀、血熱、血虛等證型是銀屑病最為常見的證型,其中,血熱型是廣東地區患病頻率最高的證型。以生地黃、元參、杭芍、茅根、牛蒡子、知母、荊芥、防風、升麻、甘草等為主的“涼血方”是治療本地區血熱型銀屑病最常用、最有效的中醫處方。所以,銀屑病的純中醫治療也與本系統的統計結果相吻合,從某種程度上來說增加了本系統的可信度。
對醫學關鍵詞進行多維度分析,可以幫助我們了解醫學領域的研究熱點,并推斷其未來研究的發展方向。對獲得的統計結果還可導出轉存為Excel、文本文件等格式,以便于利用SPSS等其他統計分析軟件做進一步分析處理。
3 小結
隨著醫學大數據的不斷發展,用戶對醫學情報服務的要求也越來越高,關鍵詞多維自動檢索系統的設計為圖書館情報服務的開展提供了更多、更便捷的服務支持。該系統已在圖書館參考咨詢部門應用于相關的文獻統計分析。實踐應用表明,使用該系統后,統計分析效率明顯提高,符合用戶檢索統計要求。同時,通過用戶對該系統的體驗和建議,將不斷對該系統進行完善及優化,提供更人性化、更精確、更快捷的文獻檢索統計服務。
本系統在功能和使用上還存在一些不足,需要不斷改進和完善。⑴系統中合并同義詞功能是依靠人工判斷方式進行的,可考慮增加系統自動提示的輔助建議功能,以更快速度完成合并同義詞工作。⑵如何實現從詞頻統計自動獲取高頻關鍵詞并歸類屬性,以減少人工錄入信息的工作量。⑶關鍵詞分析擴展成從全文自動獲取相關的關鍵詞,結合病案或醫案實現自動分析功能[5],從而可以更加全面地考察醫學的發展變化。
參考文獻
[1] 涂新莉,劉波,林偉偉.大數據研究綜述[J],計算機應用研究,2014, 31(6):1612-1616,1623.
[2] 今日報告網.湯森路透&中國科學院:2015前沿研究[R/OL].[2016-08-28].http://www.imxdata.com/archives/12707.
[3] 盧傳堅,曾召,謝秀麗,等.1979-2010年尋常型銀屑病文獻證候分布情況分析[J].中醫雜志,2012,53(11):959-961.
[4] Han J, Kamber M.數據挖掘:概念與技術[M].2版.范明,孟小峰,譯.北京:機械工業出版社.2007:146-155.
[5] 袁鋒.基于數據挖掘的中醫醫案分析系統的設計與實現[D].濟南:山東師范大學,2006.
(收稿日期:2016-10-28)
(修回日期:2016-11-04;編輯:魏民)
猜你喜歡
——中醫藥科研創新成果豐碩(一)
中國現代中藥(2022年10期)2022-11-27 03:26:18
中國現代中藥(2021年7期)2021-09-06 03:44:36
現代臨床醫學(2021年3期)2021-07-16 07:36:44
中國民間療法(2021年5期)2021-06-09 09:21:42
實用中醫藥雜志(2021年2期)2021-04-01 03:05:20
公民與法治(2020年15期)2020-09-25 02:57:56
家庭醫學(下半月)(2020年6期)2020-08-24 07:46:14
安徽醫學(2020年6期)2020-07-17 12:16:44
知識經濟·中國直銷(2017年7期)2017-07-24 14:12:41
中國衛生(2016年11期)2016-11-12 13:29:24
