基于HIS的肝病信息與診斷數據庫系統的開發與應用
2017-03-22 04:05:22,,
中華醫學圖書情報雜志 2017年9期
,,
隨著醫院信息化進程不斷推進,醫院信息系統(HIS)在醫院管理中發揮的作用愈加重要[1]。
新版門診工作站、住院工作站等信息系統的升級應用催生了海量信息的迅速增長。如果能整合、分析、利用這些海量數據,將醫療基礎信息中存在的知識精華進行自動化的提取與存儲、智能化的分析與應用,必然對醫生診療、患者就診、臨床科研及管理層的決策有所助力。
因此,尋找一種可以把虛擬分散的海量數據轉化為現實的、可以提高臨床醫生診斷效率和臨床科研知識的技術,是大數據時代醫療衛生領域亟待解決的問題,有突出的現實意義和實用價值。解放軍第302醫院(以下簡稱“我院”)是全軍最大的傳染病醫院,多年來積累了大量肝病診療資料。本文利用豐富的肝病數據資源,建立肝病診斷數據庫系統,為提高臨床診療效率服務。
1 系統設計
我院現有的HIS已采集到海量的病例數據,本系統設計即是利用這些現有數據形成新的智能診斷數據庫,并在此基礎上實現自動診病和快速治療。
采用Visual Basic 6.0企業版對主體系統編程,采用SQL server建立診斷數據庫。首先通過HIS-Visual Basic-SQL server對病例數據進行智能診病訓練和測試,具體應用時采用逆向SQL server到VB以實現診療過程。
軟件設計方法為以Visual Basic語言編輯軟件代碼并設置SQL server數據庫表單,鏈接醫院HIS網絡數據庫測試并調試軟件功能,最終打包軟件安裝軟件客戶端。
系統設計所采用的3種軟件中,HIS具有數據優勢,VB具有簡易和可視化編程的完善功能,SQL server的優勢在于通用性和性能高效。由此建成的系統投入快速、易于操作,不需要專門培訓就可以很好地融入現有診療系統之中。
2 系統結構
系統采用圖形化用戶界面(GUI),主要有AI訓練模塊、測試模塊和診療模塊3個核心模塊。在培訓模塊中,采用神經網絡方法對HIS數據進行采集以實現自我學習;測試模塊是在現有AI并不完善的情況下,采用人工系統測試和矯正;診療模塊針對最終用戶即醫師,直接應用在診療過程中,并可由醫師反饋改進意見。
2.1 系統網絡運行環境
本系統以醫院HIS網絡為基礎,以SQL server數據庫存儲系統數據,用戶以客戶端讀寫網絡SQL server數據庫并將結果存儲于數據庫內以供其他用戶分享使用(圖1),客戶端軟件也可以訪問HIS數據庫并提取數據,為診斷模塊提供數據來源。
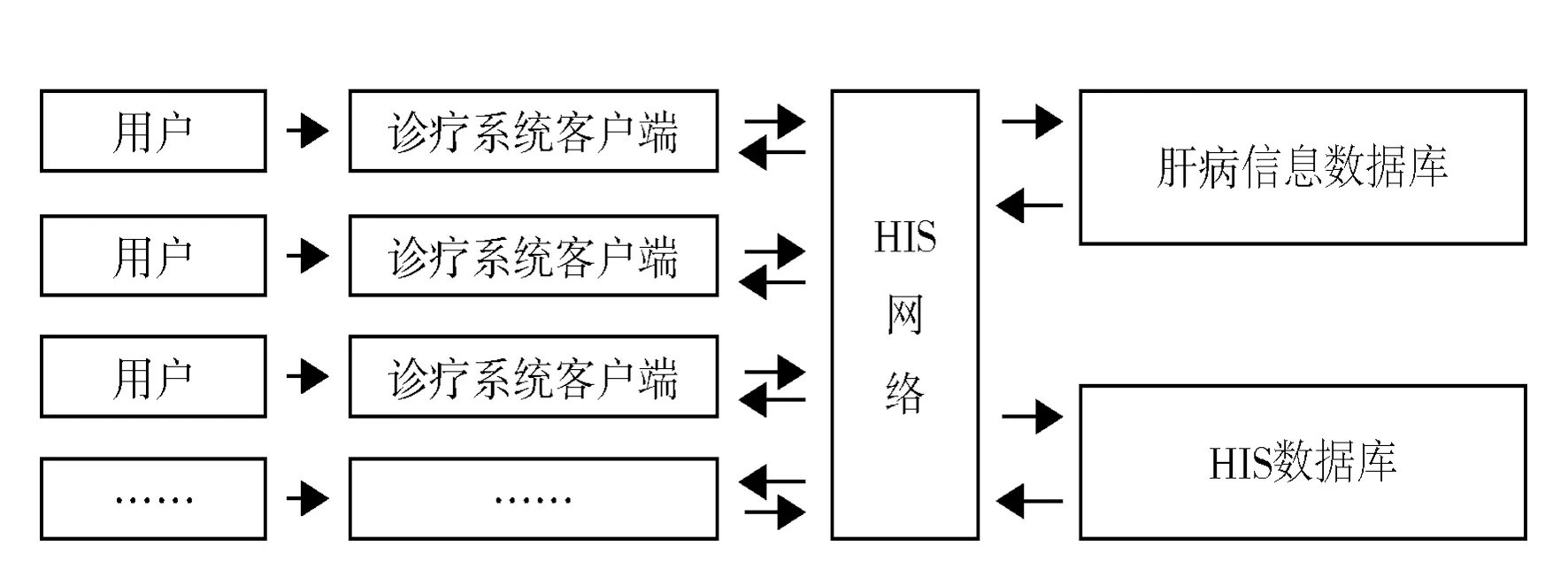
圖1系統運行結構
2.2 客戶端結構
根據系統功能需求將客戶端分成肝病知識模塊、肝病數據庫模塊、肝病診斷模塊、肝病專家庫模塊和軟件設置模塊5部分。各模塊分別為用戶提供肝病知識信息,為已知檢測指標提供智能診斷、肝病典型數據信息、肝病專家信息,以及軟件維護和設置功能。客戶端以智能診斷功能為核心,其余模塊為智能診斷模塊提供數據和知識信息支持。用戶通過人機對話過程即可快速完成知識庫錄入和查詢、病例診斷數據的查詢與統計、疾病智能診斷等過程。
3 實現技術
3.1 神經網絡方法
神經網絡(NN)也稱為人工神經網絡(ANN),是一種基于大腦結構形成程序功能的計算模型,在大數據集中,它具有很好的成本效益和靈活性,在推理準確度方面具有不可替代的優勢。在神經網絡中,神經元可以以各種方式排列,權重(神經元之間的連接)可具有不同的模式,可以實現如前饋、反饋、聯網計算和AI自我競爭等功能,這是本系統的實現基礎和優勢。神經網絡技術原理公式如下:
3.2 智能診斷模塊
系統核心功能是為用戶提供肝病智能診斷功能,智能診斷模塊采用k-NN(k-nearest neighbor)算法建模,將肝病數據庫內診斷病例的疾病按照種類進行二進制命名,訓練器通過對主要診斷指標(通過統計計算后出現概率最高的診斷項目)進行加權,以類中心法離線方式進行數據訓練,以在線方式計算用戶設定所需個數的待分類疾病距離,從而獲得概率最高的疾病列表,并以概率順序羅列。
該模塊根據用戶輸入的患者臨床診斷或輔助診斷指標等信息,通過讀取樣本數據、計算各類中心、比較待檢樣本與K-NN算法計算出的各類中心距離,輸出最近距離的3類疾病和概率數值,以供用戶對診斷進一步甄別(圖2)。
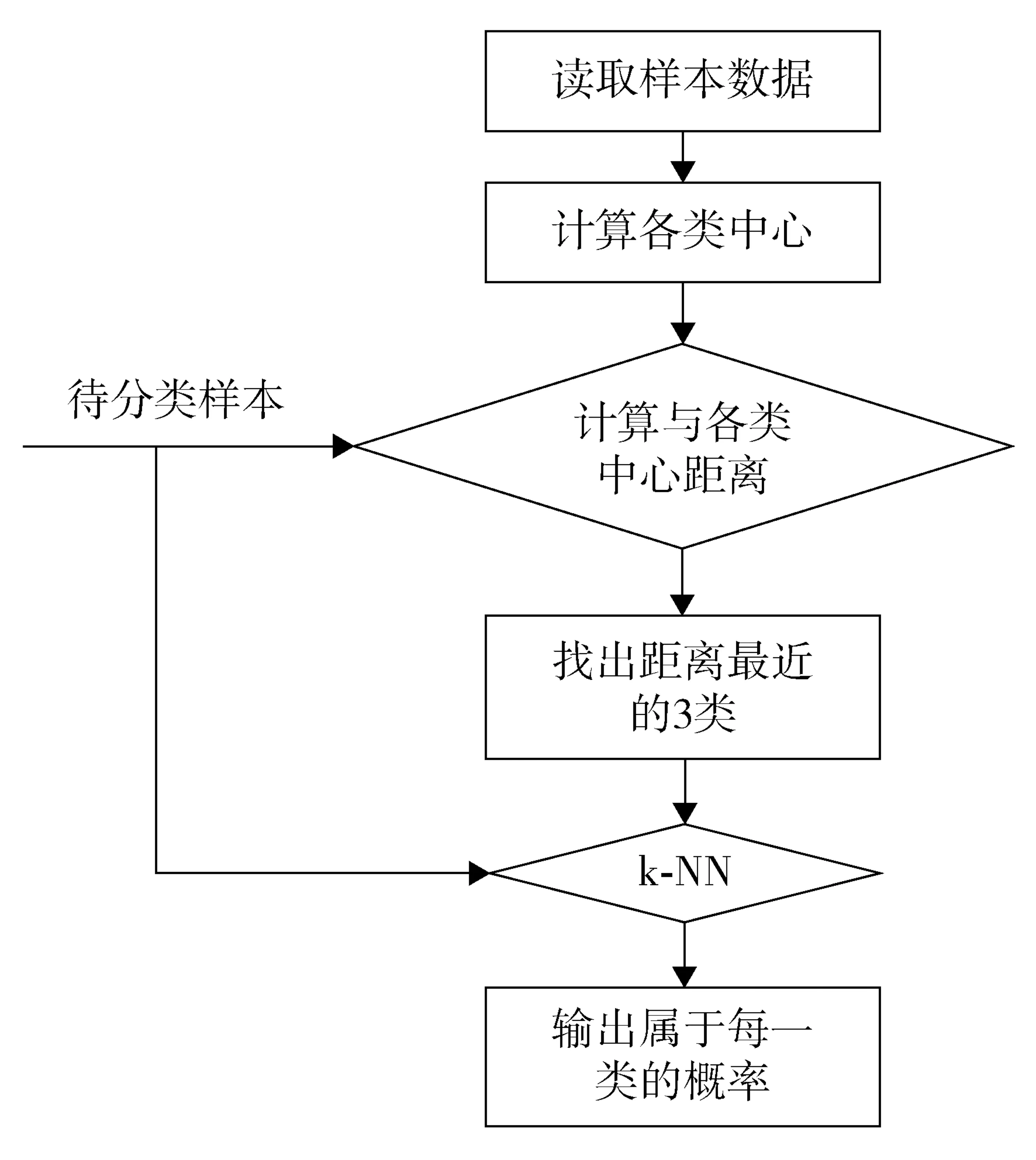
圖2 算法流程
4 功能與應用
功能方面包括AI訓練模塊、測試模塊和診病模塊。AI訓練的目的是通過改變病例間的權重實現預期輸出,共使用了3種訓練方式:一是監督訓練,在此過程中,可以為系統提供一系列標準樣本輸入,并將結果輸出與預期結果比較;二是無監督訓練,完成監督訓練后輸入隨機的病例,進行AI自我學習,盲訓和進化神經網絡;三是加固訓練,此過程用于加強預期結果的正確性。為保證達到預期結果,系統將HIS數據庫等分為兩份,使用第一部分進行AI訓練,使用第二部分進行正確性測試。測試模塊是本系統實現預期響應的最重要模塊,由人工全程監督測試,用以確定訓練模塊的正確性。只有當測試結果達到或超出預期時,才可認為完成了系統的自我學習過程。
4.1 核心功能與應用
本系統智能診斷功能采用神經網絡模型設計。以我院HIS數據庫10余萬條肝病典型肝病病例數據為訓練樣本,涵蓋了感染性和非感染性等全部肝病種類,篩選了肝病病例的家族史、感染史、用藥史、臨床癥狀、檢驗結果、影像資料等具有代表性的各類診斷以及輔助診斷等50種指標信息(表1),并可擴展或縮減指標數量,用戶將預測樣本(患者檢測或臨床指癥等指標)輸入系統即可開始模擬診斷。系統根據用戶提供的數據,對用戶輸入的樣本數據與系統數據庫內疾病病例數據進行計算和比對,以概率高低順序輸出與預測樣本最接近的3種肝病種類名稱,以供用戶進一步甄別診斷。本系統的應用過程中實測訓練誤差為5.23%,測試誤差4.20%,可以滿足疾病預測要求和目標。

表1 系統采用的肝病診斷及輔助診斷指標
4.2 擴展功能與應用
系統以智能診斷技術為核心,擴展了多個系統輔助功能供用戶使用。肝病知識庫模塊存儲了肝臟基礎知識和臨床所有已知肝病知識信息,并分為感染和非感染性將肝病兩類,每一類別又詳細劃分成若干肝病子類,且每種肝病又分為疾病簡介、典型癥狀、發病原因、實驗室檢測、鑒別診斷、預防、治療、護理、并發癥、飲食保健等多個部分,為用戶提供知識信息快速查詢功能。
肝病數據庫模塊包含了我院HIS數據庫各類肝病病例的診斷指標數據,為智能診斷模提供模擬訓練數據源,同時也為臨床醫護人員提供病例樣本和診斷指標的統計和瀏覽功能。用戶可以通過客戶端錄入和編輯疾病各類的診斷指標、篩選HIS數據庫的病例等,以豐富肝病數據庫病例數據。
肝病專家模塊包含肝病方面的權威專家信息(包括專家簡介、研究領域、聯系方式、工作單位等),為疾病診斷、專家會診等提供信息幫助。系統的設置模塊可輔助用戶設置軟件各類參數(用戶管理、數據庫維護、軟件界面調整、功能編輯等),以豐富和優化軟件功能,確保軟件運行安全。
5 討論
作為智能診斷技術的分支,神經網絡模型技術[2-4]已經廣泛應用于各行業的數據挖掘與前瞻性結論預測[5-6]。當前醫療領域疾病智能診斷技術開發與應用成果很多,但受限于學科方向不同,尤其是不同學科的疾病臨床癥狀千差萬別,一種智能診斷技術不能涵蓋多個學科領域;加上數據來源的權威性、代表性的差異以及數據模型針對性的不同,各醫療學科目前還需要量體裁衣地設計和制作適合自身的智能診斷系統。肝病智能診斷方面目前尚無成熟技術可以應用。我院屬于大型肝病專科醫院,HIS數據庫存儲了幾十萬條病例數據信息,涵蓋了肝病領域的各類典型病例,大量病例數據資源未能充分挖掘使用,無疑是醫療資源的浪費。
本文基于為肝病臨床診療與科研提供前沿、實用、高效的智能輔助信息支持的目的,開發了基于HIS數據庫的肝病信息與診療數據庫系統。該系統以我院HIS數據庫數據為依托,在查閱各類專業資料[7-16]和專家充分論證的基礎上,精選了50余個最有價值的臨床指標作為肝病診療參數,通過人工篩選LIS典型病例數據方式建立數據庫和神經網絡模型,以期達到疾病預測和智能判斷的目的,為臨床提供快速的智能診療途徑,也為統計和搜集科研數據提供便捷通道。系統的知識庫模塊包含了所有肝病診療、護理、預防和保健知識的信息,并可隨時更新和豐富,為臨床工作提供了強大的專業知識保障。專家模塊包含各類肝病領域的權威專家信息,為臨床進一步診療提供信息幫助和支持。
系統的神經網絡模型采用k-NN算法技術[17-21]。該算法的優點是數據選擇簡單有效,編程實現簡單,是一種懶惰學習算法,分類器不需要使用訓練集訓練,訓練復雜度為0,將部分工作量離線進行,可減少在線計算量。缺點是在線計算量較大,不適合過多預測樣本的計算,不過可以在系統管理模塊中合理設置樣本預測數量,以減少過多數據處理負擔。實際應用過程中,單機10余萬條數據的數據庫采用3個預測樣本參數,系統響應時間為2-3秒,單種類肝病及常見多因素肝病預測準確率高于95%,可以滿足臨床診斷要求。由于部分患者個體因素復雜以及肝病與其他多疾病同時存在會對該預測模型造成影響,目前該系統僅屬于臨床輔助診療工具。下一步還應在當前模型基礎上建立多因素狀態肝病患者數據,并對多因素種類分類和積累數據量,以期達到提高多疾病疊加和多因素影響下預測準確性的目的。隨著信息技術的發展,數據開發成為各新興行業發展的立足點[22],醫療智能診療系統也將迎來更大發展空間,醫院在開發各類輔助醫療應用的同時應該加強診療數據的挖掘和使用,以提高診療水平和診療質量。
猜你喜歡
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
財經(2017年2期)2017-03-10 14:35:35
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
財經(2016年15期)2016-06-03 07:38:02
商用汽車(2016年4期)2016-05-09 01:23:12
財經(2016年3期)2016-03-07 07:44:46
