大數據及其體系架構與關鍵技術綜述
2017-03-25 03:20:34呂登龍朱詩兵
裝備學院學報 2017年1期
呂登龍, 朱詩兵
(1. 裝備學院 研究生管理大隊, 北京 101416; 2. 裝備學院 信息裝備系, 北京 101416)
大數據及其體系架構與關鍵技術綜述
呂登龍1, 朱詩兵2
(1. 裝備學院 研究生管理大隊, 北京 101416; 2. 裝備學院 信息裝備系, 北京 101416)
介紹了大數據的發展現狀、研究動態和應用前景。針對大數據標準不統一、研究觀點紛雜的問題,以比較辨析的方法從新的視角重新定義了大數據;注重安全性研究,分析總結了大數據的“6V”特征;從大數據標準化入手,深入分析現有研究成果,歸納總結了大數據的體系架構和目前大數據應用的共性技術,分析了各類技術的內涵,使大數據體系架構和關鍵技術有較為系統的展現。
大數據;體系架構;關鍵技術
近年來,隨著移動互聯網、物聯網、云計算、社交網絡、傳感器、數據存儲等技術和服務的迅猛發展,導致網絡數據呈爆炸式增長。據統計[1],中國互聯網的社交媒體用戶達6.59億,超過了美國和歐洲的總和,各種App的應用,使得網絡數據急劇增長。同時,教育、醫療衛生、金融、科學研究等各行業也在源源不斷地產生數據,世界已經進入大數據時代,并正受其影響和推動發展。根據國際數據公司(International Data Corporation,IDC)數字宇宙(Digital Universe)監測顯示[2],全球數據量以大約每2年2倍的速度增長,預計到2020年,全球數據總量將達到44ZB。IDC報告顯示[3],2014—2019年全球大數據技術和服務市場復合年增長率達23.1%,2019年大數據市場總規模將達486億美元;2014年IDC對中國2013—2017年大數據與服務市場的預測[4]顯示,中國將保持38.7%復合年增長率,到2017年大數據的市場規模將增長到8.501億美元;未來幾年,世界企業將進入規模化的數字化轉型階段,此過程將會產生更巨大規模的數據。
大數據已經引起了世界各國和地區的廣泛關注。美國將大數據研究和應用提升到了國家戰略層面,接連出臺了《大數據研究和發展計劃》《支持數據驅動型創新的技術與政策》《大數據:把握機遇,守護價值》等決策性和指導性文件,并在應用領域已經處在世界的領先地位。“棱鏡門”事件曝光了美國對全球的監控計劃,一方面凸顯了美國在全球數據掌控的絕對優勢,另一方面也為世界其他主要國家敲響了數據保衛戰的警鐘。歐盟成立了歐洲網絡與信息安全局(European Network and Information Security Agency ,ENISA),并將數據應用提升到戰略層面,出臺了《數據價值鏈戰略計劃》,英國還專門制定了《英國數據能力發展戰略規劃》。日本、韓國也分別制定了《創建最尖端IT國家宣言》和《大數據中心戰略》。我國也意識到了大數據及應用的重要性,實施了國家大數據戰略,從2015年3月至9月,接連制定了《“互聯網+”行動計劃》《大數據產業“十三五”規劃》,實施“加快推進云計算與大數據標準體系建設”計劃,出臺了《關于積極推進“互聯網+”行動的指導意見》和《促進大數據發展行動綱要》等。隨著信息技術在軍事領域的應用發展,軍事數據也呈現爆炸式增長趨勢,軍事大數據時代也已經到來。未來信息化戰爭更多的是數據驅動下的戰爭,誰掌握更多的數據,誰能在瞬息萬變的戰場態勢下快速進行數據分析處理,誰就能掌握制數據權,就會獲得戰爭的勝利。
研究結果表明:目前大數據的概念、體系架構、關鍵技術等方面還有待標準化,在安全和隱私保護方面還面臨著嚴峻挑戰,從概念提出到技術應用、再到科學研究的“第四范式”,大數據還有很大的研究和發展空間。本文分析了大數據的概念、特點及發展現狀,重點分析、歸納、總結了大數據的體系架構和關鍵技術。
1 大數據基礎研究
1.1 大數據定義及特征分析
對于大數據,目前在研究和應用領域還沒有一個標準的定義,比較流行的定義主要有2類:(1)大數據是從規模巨大、形式多樣的數據中,通過高效捕捉、發現和分析獲取有價值信息的一種新的技術架構,是從“What is big data?”的角度定義,IDC、IBM以及百度百科等持這種觀點[5-7],主要強調的是一種數據處理的技術架構;(2)大數據包括結構化和非結構化數據,它的規模相當龐大以至于用傳統的數據庫和軟件技術很難對其進行處理,是從“How hard to deal with big data!”的角度定義, Mckinsey、Gartner以及維基百科等持這樣的觀點[8-10],主要強調的是處理大數據的困難所在。
2類定義都一定程度反映了大數據的最基本特點:大規模(Volume)、多樣性(Variety)和高速性(Velocity),簡稱大數據的“3V”特性[11]。隨著對大數據研究的深入,研究者對大數據的特點進行了深度挖掘和總結,將大數據的“3V”特性進行了豐富和擴展,又有了“4V”[12]、“5V”[13-14]、“6V”和“7V”[15-16]的特性概括,而比較公認的是“5V”特性。當然,對大數據關注的重點不同,研究者對大數據特性的理解和總結也會有所不同。
作者認為:大數據在推動經濟社會創新發展及創造社會效益的同時,本身的安全問題也日益面臨著嚴峻挑戰,大數據及大數據設施極易成為被攻擊的目標,大數據分析和服務也極易泄露個人隱私、企業等機構的敏感信息,甚至是國家機密。
就此來看,大數據還應包含另外一個重要特性:Vulnerable(易受攻擊),構成“6V”特性(Volume, Velocity, Variety, Value, Veracity and Vulnerable)比較合理,這6個“V”共同作用,構成了大數據的特征體系,貫穿于從數據源到數據分析再到數據解釋的整個大數據生命周期,表1對大數據的“6V”特性進行了具體描述。

表1 大數據“6V”特性的具體描述

續表
1.2 大數據與傳統數據對比分析
為了更好地研究大數據,我們將前節所述2類定義進行了融合處理,這樣來定義大數據:大數據規模巨大、形式多樣(包括結構化和非結構化數據),通過傳統的數據庫技術和數據分析技術難以進行處理,只有采用新的技術架構才能高效捕捉、發現和分析,并從中獲取有價值的信息。可以看到大數據在數據結構、體量、處理、存儲等方面與傳統數據有很大的區別,這些區別主要體現在數據分析模式的不同。圖1顯示了大數據分析模式的模型架構。從模型架構上來看,傳統數據來源一般為各種業務系統,數據主要是結構化的,存儲在關系型數據庫中,需要將數據從這些關系數據庫中通過抽取、轉換和加載等一系列操作后,轉移到數據倉庫中再進行數據分析,分析過程主要是線下分析;大數據來源廣泛,除了傳統業務系統的關系型數據庫外,還包括移動終端、傳感器網及社交媒體等來源,數據類型既有結構化的也有非結構和半結構化的,分析過程既有線上分析也有線下分析,分析模式不僅包含了傳統的數據分析,還解決了傳統模式下無法很好對非結構化、半結構化及實時流數據進行分析的問題,同時大數據技術也一定程度緩解了傳統數據處理軟件和硬件無法對海量數據進行分析處理的壓力。
大數據與傳統數據的具體區別,如表2~表4所示。
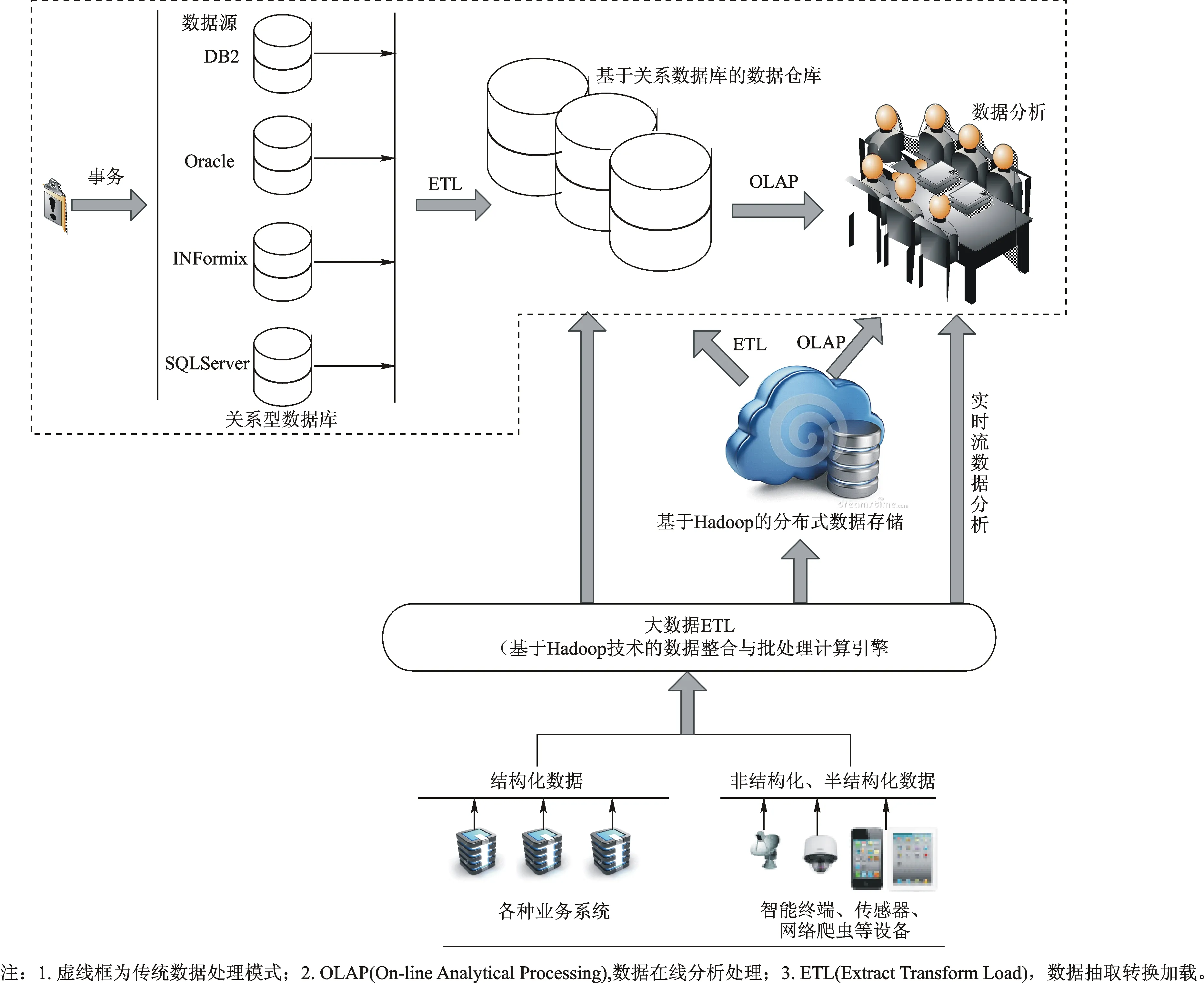
圖1 大數據分析模式的模型架構
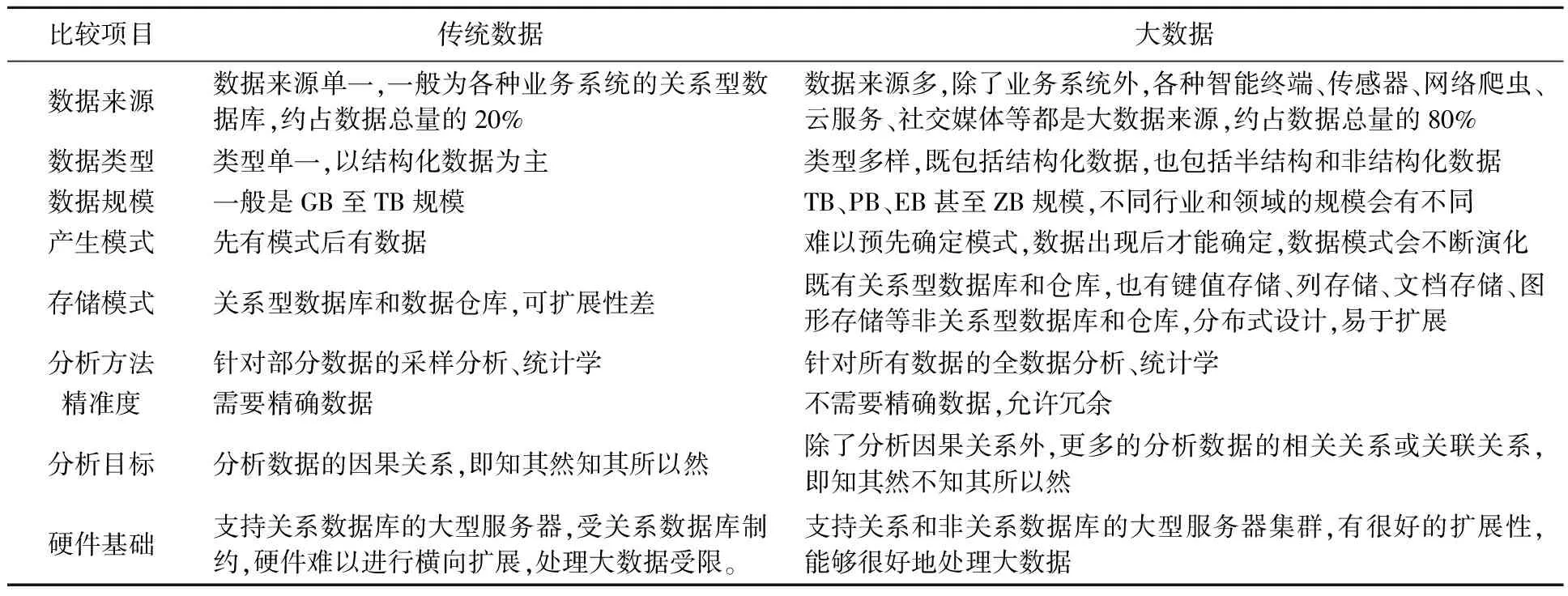
比較項目傳統數據大數據數據來源數據來源單一,一般為各種業務系統的關系型數據庫,約占數據總量的20%數據來源多,除了業務系統外,各種智能終端、傳感器、網絡爬蟲、云服務、社交媒體等都是大數據來源,約占數據總量的80%數據類型類型單一,以結構化數據為主類型多樣,既包括結構化數據,也包括半結構和非結構化數據數據規模一般是GB至TB規模TB、PB、EB甚至ZB規模,不同行業和領域的規模會有不同產生模式先有模式后有數據難以預先確定模式,數據出現后才能確定,數據模式會不斷演化存儲模式關系型數據庫和數據倉庫,可擴展性差既有關系型數據庫和倉庫,也有鍵值存儲、列存儲、文檔存儲、圖形存儲等非關系型數據庫和倉庫,分布式設計,易于擴展分析方法針對部分數據的采樣分析、統計學針對所有數據的全數據分析、統計學精準度需要精確數據不需要精確數據,允許冗余分析目標分析數據的因果關系,即知其然知其所以然除了分析因果關系外,更多的分析數據的相關關系或關聯關系,即知其然不知其所以然硬件基礎支持關系數據庫的大型服務器,受關系數據庫制約,硬件難以進行橫向擴展,處理大數據受限。支持關系和非關系數據庫的大型服務器集群,有很好的擴展性,能夠很好地處理大數據

表3 不同數據類型特點對比
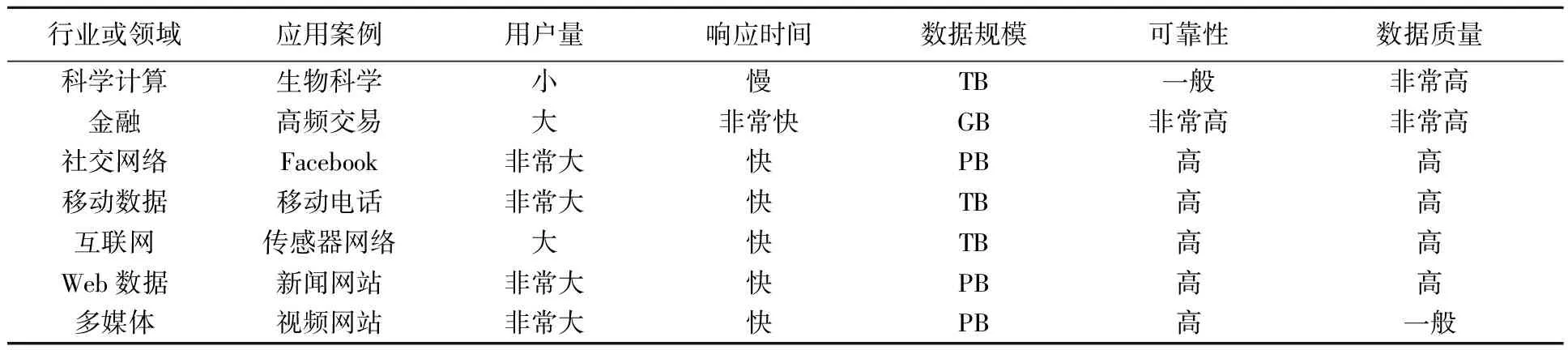
表4 不同行業或領域大數據規模對比[17]
綜上所述,大數據是個系統的概念,是由大數據本身、大數據處理過程、大數據結果及運用組成的體系,缺一不可,如果不考慮大數據處理及結果運用,那么大數據僅僅是規模龐大的普通數據,也就無所謂“大數據”這一新生事物了。
2 大數據體系架構
2.1 大數據體系架構現狀
對比分析Gartner公司公布的2013—2015年新興技術炒作曲線圖[18-20],可以看出大數據從2013年的火熱到2014年開始走向低谷直到2015年在曲線圖上消失,表明大數據技術已趨于成熟并被廣泛應用。而對大數據標準化的研究始于2012年,目前從國內外研究現狀來看尚處于起步階段[21-25],大數據體系并沒有統一標準的應用模型。大數據技術應用早于大數據標準化研究,從應用實際來看,大數據體系更偏向于軟件系統。IEEE軟件工程標準委員會對軟件系統架構進行了定義[26]:軟件系統架構包含各組成要素和各要素之間的相互關系、運行環境以及設計和運行原理描述。大多數研究機構和組織也主要基于軟件系統來研究大數據體系架構。
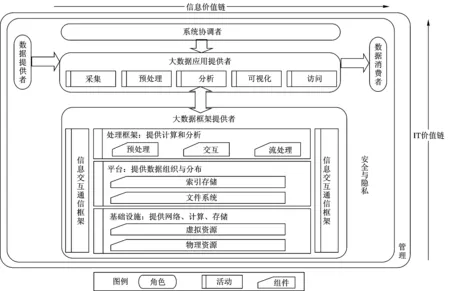
圖2 大數據參考架構
美國國家標準與技術研究院(National Institute of Standards and Technology,NIST)對9種大數據解決方案的體系架構進行了詳細剖析和對比分析,確定了大數據體系架構的共性部分,在此基礎上按照邏輯角色和商業應用的目的給出了大數據參考架構[27-28],中國電子技術標準化研究院對NIST研究成果進行了豐富和完善[29],在原有架構的基礎上細化出活動和組件的概念,明確了角色的行為動作和行為的環境支撐以及相互之間的邏輯關系,使得整個架構更加具體形象,如圖2所示。整個參考架構圍繞2個價值鏈進行構建:橫向為信息價值鏈,通過數據收集、集成、分析、分析結果應用創造價值;縱向為信息技術(IT)價值鏈,通過提供網絡、基礎設施、平臺、應用工具及其他服務創造價值。架構定義了5個邏輯角色:數據提供者、大數據應用提供者、大數據框架提供者、系統協調者和數據消費者,整個架構以大數據應用提供者為中心提供了連通其他4個角色的接口。架構包含了2個服務和功能保障構件:安全隱私和管理,分別對各接口和大數據框架提供者內部進行安全與隱私監管以及對全系統各要素進行統一管理,從而構成大數據應用的完整體系。
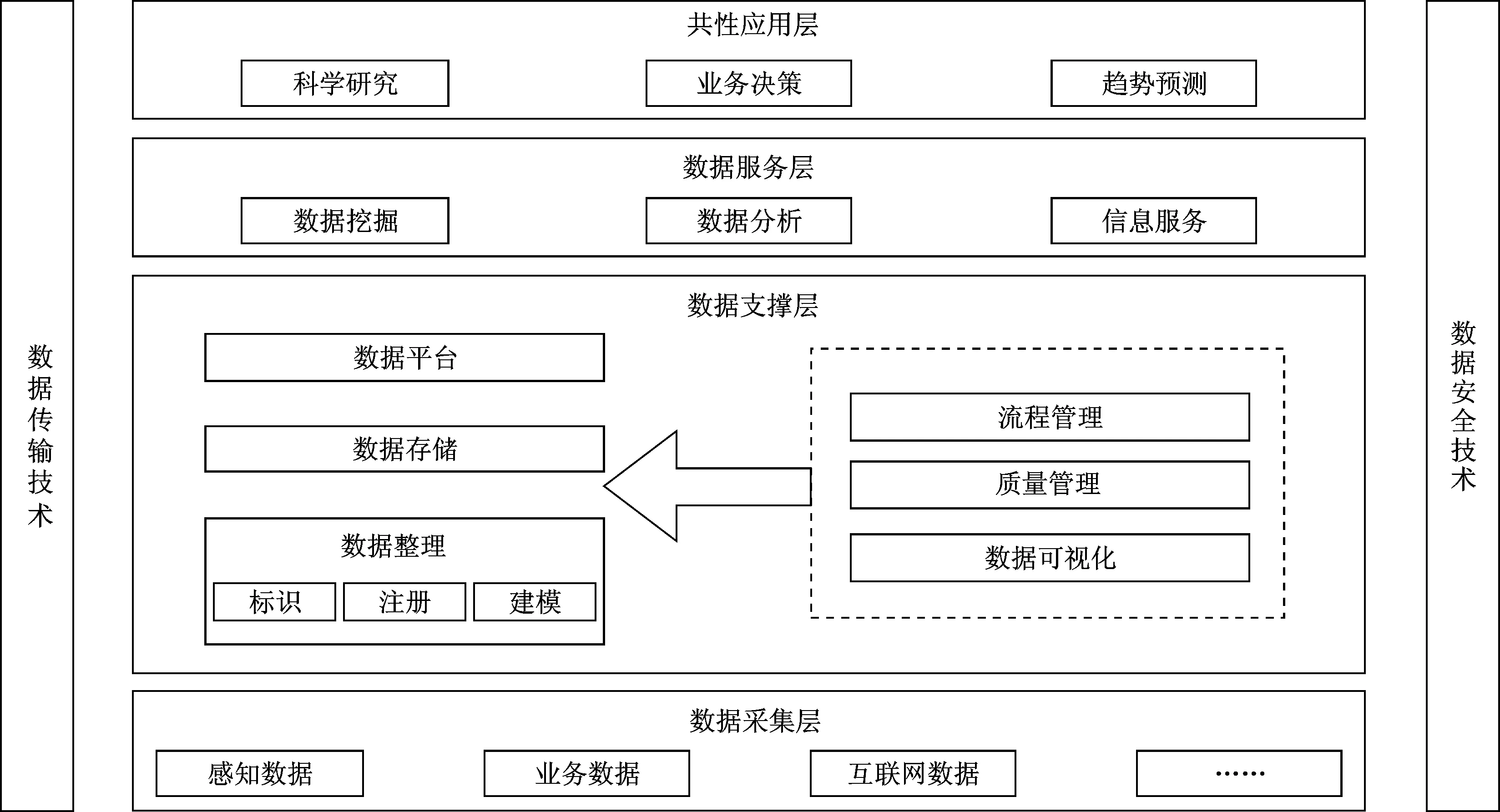
圖3 大數據技術參考架構
文獻[22]借鑒了ISO/IECJTC1/SC32(數據管理和交換分技術委員會)對大數據標準概念模型的研究成果,提出了大數據技術參考架構,如圖3所示。該架構綜合考慮數據的生命周期,采取分層的模型結構,將大數據技術按照生命周期劃分為4個層次、2個技術支撐體系。其中,4個層次包括數據采集層、數據支撐層、數據服務層和共性應用層;2個技術支撐體系包括數據傳輸技術體系和數據安全技術體系。層與層之間形成服務與依賴的關系,下層為上層提供服務,上層依賴于下層服務,2個技術支撐體系分別保證了層間及層內數據通信暢通和可靠的信息安全環境。
雖然不同機構或組織對大數據體系架構的設計有所不同,但從解決問題的實質上來看,不同的體系架構之間又有共性的方面:(1) 工作流程主要圍繞大數據生命周期進行設計;(2) 工作方法主要依靠分布式存儲和分布式并行處理來實現;(3) 基礎設施具有良好的擴展性;(4) 大數據隱私和安全被廣泛重視。
如同其他技術或事物一樣,大數據體系會逐漸趨于一致并最終實現標準化,而具有普遍適用的標準又能更好地為大數據研究和應用提供理論指導和技術參考。
2.2 典型大數據開源架構
目前,比較流行的典型大數據處理開源架構主要有Hadoop、Storm和Spark 3種。
_2.2.1 Hadoop
Hadoop的核心思想是通過大量高效的硬件集群和標準接口構建大規模分布式計算系統,以軟件處理的方式為海量數據提供存儲和計算。Hadoop的核心組件是HDFS(Hadoop Distributed File System)和Hadoop MapReduce,其他組件為核心組件提供配套和補充性服務,其基本體系架構如圖4所示[30-31]。

圖5 HDFS基本體系架構
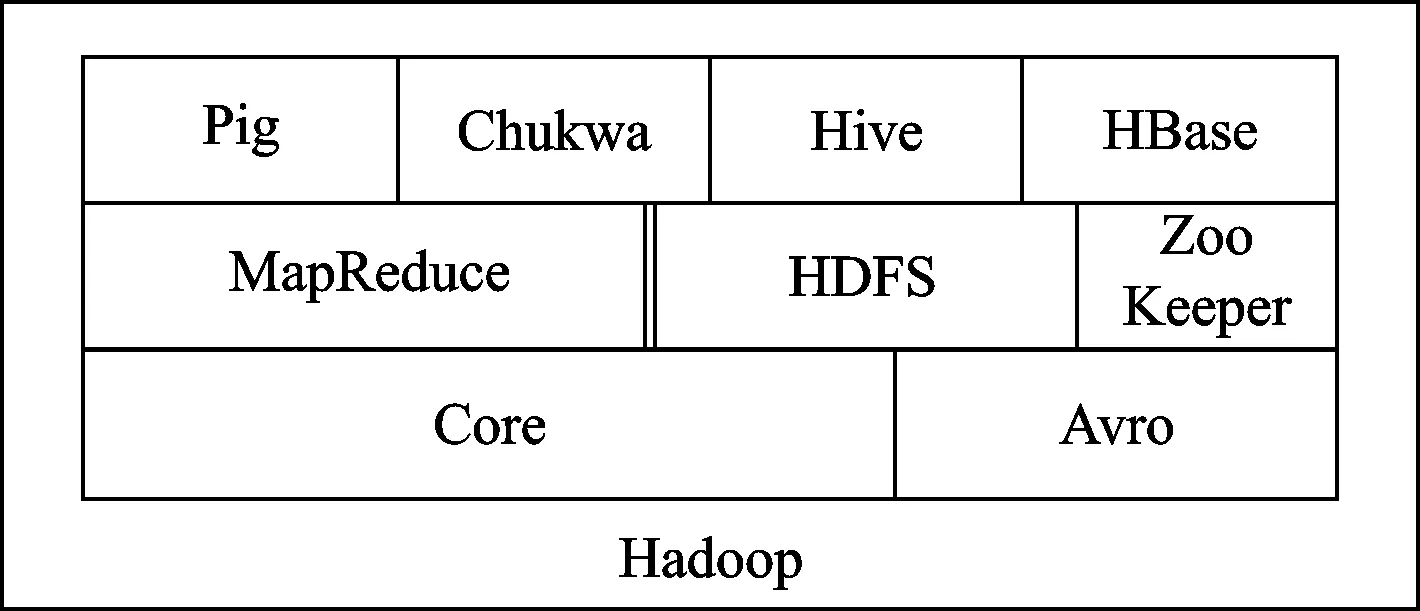
圖4 Hadoop基本體系架構
1) HDFS。其思想來源于Google文件系統(Google File System,GFS),是GFS的開源實現。HDFS特點之一是以流式數據訪問模式實現超大規模數據集存儲。HDFS采取數據集一次寫入、多次讀取方式[32-34],實現了分布式環境下流式訪問數據的能力,保證了數據的大吞吐量。HDFS的基本體系架構如圖5所示,總體上采用了主從式執行模式,主要由Client、NameNode、SecondaryNameNode和DataNode幾個組件構成。
Client是客戶端,主要功能是為用戶提供訪問文件系統的接口,通過NameNode和DataNode交互訪問HDFS中的文件;NameNode是HDFS的主節點,負責協調客戶端對文件系統的訪問,管理文件系統的命名空間、文件目錄樹和元數據信息,并且負責監控和調度DataNode;DataNode是NameNode的從節點,負責數據的實際存儲,同時DataNode以Heartbeat的方式向NameNode報告節點的健康狀況。SecondaryNameNode是監控HDFS運行狀態的輔助節點,在NameNode出現問題時及時進行熱備份來代替NameNode。
2) Hadoop MapReduce。其主要設計目標是為用戶提供抽象的程序模塊,簡化分布式程序設計,將用戶從繁瑣的接口和通信等程序設計中解放出來,只專注應用程序的設計,從而提高程序開發和解決大數據問題的效率。MapReduce也采取master/slave結構模式,基本體系架構如圖6所示,主要由Client、JobTraker、TaskTracker和Task幾個組件構成[34-38]。
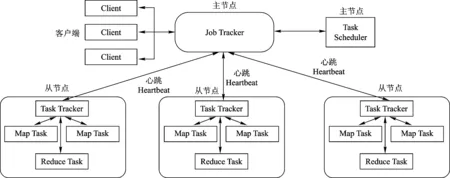
圖6 Hadoop MapReduce基本體系架構
Client客戶端,主要負責將用戶編寫的應用程序提交給JobTracker,并為用戶提供查看作業(Job)運行狀態的接口;JobTracker是MapReduce的主節點,主要負責監控子節點TaskTracker和作業的運行狀況,一旦子節點出現問題,JobTracker會將任務轉移到其他子節點執行,同時JobTracker還負責跟蹤任務的執行進度和資源的使用情況,發揮任務調度的作用。TaskTracker是JobTracker的子節點,主要為任務(Task)分配資源和提供執行環境;Task是任務的具體執行單元,主要分Map任務和Reduce任務。Map任務以
_2.2.2 Storm
Storm是一款開源的分布式實時流處理系統,最早由BackType公司的Nathan Marz開發,之后BackType公司被Twitter收購,隨之Storm也由Twitter開源發布,目前Storm已成為Apache軟件基金會的孵化器項目之一。Storm同樣也采取主從式架構,核心組件包括3個部分[39-42]: Nimbus、Supervisor node和ZooKeeper cluster,基本體系架構如圖7所示。
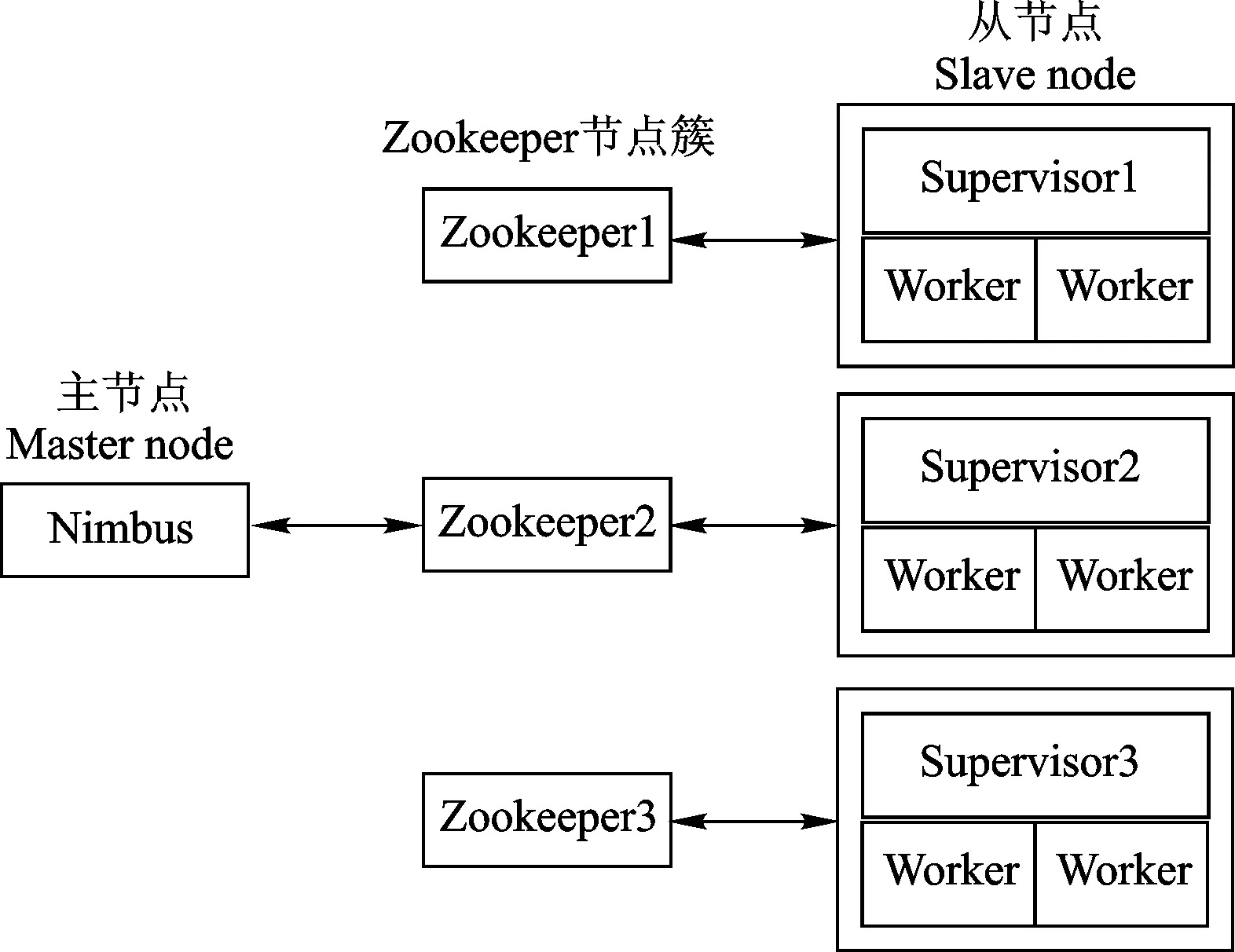
圖7 Storm基本體系架構
Nimbus是Storm集群的主節點,負責向工作節點分發應用代碼和分配任務,同時監控任務的執行狀態和工作節點的健康狀況。Nimbus節點被設計成“快速失敗(fail-fast)”的模式,所有的數據都存儲在Zookeeper上,一旦節點死掉會快速重啟而不會對工作節點造成任何影響[43-44]。Supervisor是Storm集群的從節點,每個節點上運行一個Supervisor,負責創建、啟動、停止工作進程,控制工作進程執行分配的任務。與Nimbus相同,Supervisor也被設計成“快速失敗”的模式,所有的狀態信息也存儲在Zookeeper上,節點一旦死掉會快速重啟而不會丟失任何狀態信息。Zookeeper是整個Storm集群的橋梁,在整個系統中發揮協調作用,存儲著Nimbus的數據和Supervisor的狀態信息,并負責Nimbus和Supervisor的通信。
_2.2.3 Spark
Spark是在MapReduce基礎上實現的高效迭代計算框架,它的最大特點是支持基于內存的分布式數據集計算,從而大大提高了運算速度。Spark最早由美國加州大學伯克利分校于2009年開發,2010年實現開源發布,2013年由Apache軟件基金會接管,并成為其頂級項目。Spark核心理念是通用和速度,集成了流計算框架、圖計算框架、數據查詢引擎、機器學習算法庫、分布式文件系統等功能和組件,其基本體系架構[45-47]如圖8所示。
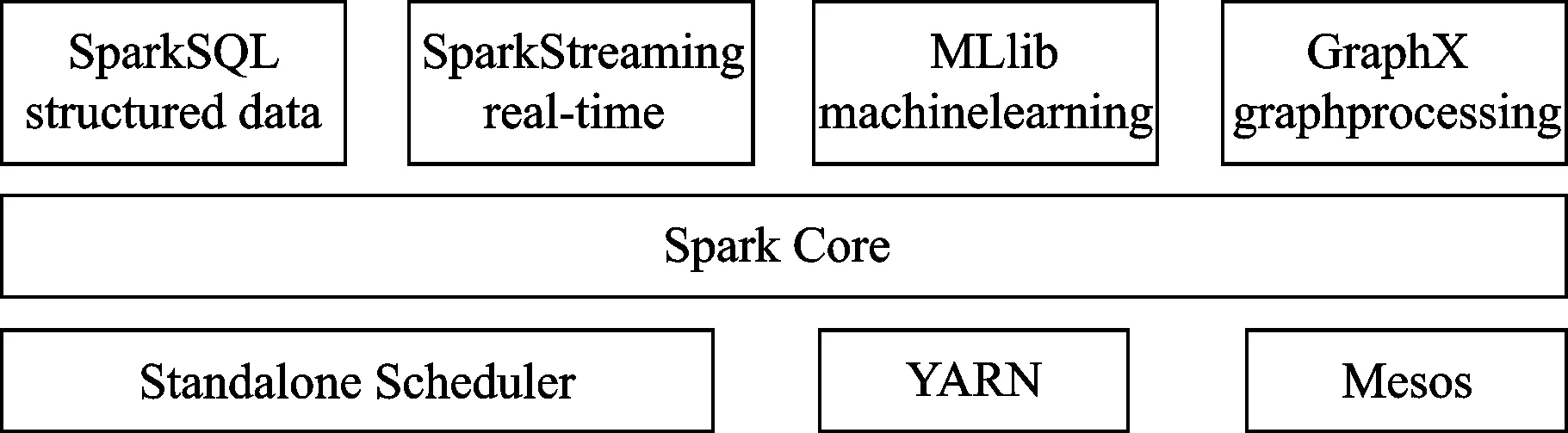
圖8 Spark基本體系架構
Spark Core是Spark體系的核心,實現了Spark的基本功能,包括任務調度、內存管理、錯誤恢復以及和存儲系統的交互,Spark Core定義了一個程序抽象模型——彈性分布式數據集(Resilient Distributed Datasets,RDD),所有的應用程序都被抽象成RDD來完成運算[45,48-49]。Spark SQL是處理結構化數據的工具,通過引入RDD數據抽象,能夠通過SQL語言和集成其他SQL工具實現對結構化數據的高效查詢。Spark Streaming是Spark的實時流數據處理組件,它以時間片對數據進行分割形成RDD,能夠以相對小的時間間隔對流數據進行處理,同時提供良好的應用程序接口(Application Program Interface,API)和容錯機制,能夠與其他組件友好的合作從而高效完成對流數據的處理。MLlib是Spark的機器學習算法庫,可以為處理大數據提供基本的機器學習算法,包括分類、回歸、聚類等算法,同時還支持算法模型評估等。GraphX是Spark對圖操作和處理大規模并行圖計算的功能庫,能夠利用RDD API接口實現對圖數據的統一高效處理。YARN、Mesos等運行于Spark體系的底層[50],負責對集群資源和數據的管理,保證Spark集群節點的擴展和統一高效運行。
_2.2.4 3種架構的比較分析
上述3種開源架構的技術特點各有不同。Hadoop采用一次寫入多次讀取的流式數據訪問方式,更多的是以時間換空間,側重的是數據吞吐量,不適合迭代式的數據處理,在數據處理的實時響應方面也不占優勢,更適合在線下對靜態大數據進行處理和分析。Storm設計理念是對大數據記錄逐條持續進行處理,計算過程非主動結束,同時容錯性較高,更適合對實時流數據的處理。由于集成度相對不高,Storm對其他類型的大數據處理性能還有待完善。Spark的集成程度較高,功能比較強大,能夠對不同數據類型(一般結構化數據,圖數據、流數據等非結構化數據)的大數據進行處理。由于Spark是基于內存計算框架,在數據量低于內存容量時計算性能突出,但當數據量遠大于數據容量時存在穩定性問題[51],更適合進行規模適當迭代式數據處理。
3 大數據關鍵技術
在實際應用中,大數據是一項非常復雜的系統工程,既需要硬件基礎也需要軟件支撐,涉及的技術涵蓋信息通信、計算機科學、信息網絡、數據庫等多個領域。單從大數據的處理流程和生命周期考慮,歸納起來,大數據的關鍵技術主要包括數據感知與獲取技術、數據預處理技術、數據存儲與管理技術、數據分析技術、數據可視化技術以及數據安全與隱私保護技術等6部分。
3.1 數據感知與獲取技術
大數據應用的關鍵,就是從海量的看似無關的數據中,通過分析關聯關系從而獲取有價值的信息,有效獲取目標數據成為大數據應用必須解決的首要問題。大數據類型多樣,來源非常廣泛,涉及人類社會活動的各個領域,其中最主要的來源有3個方面[52-53]:人們在互聯網活動中產生的數據,各類計算機系統產生的數據,各類數字設備記錄的數據。人在互聯網活動中產生的數據為網絡數據,常用到的數據感知與獲取技術有網絡爬蟲或網絡嗅探等;計算機系統產生的數據主要是日志和審計數據,常用日志搜集和監測系統來獲取數據,如Scribe、Flume、Chukwa等;各類數字設備主要包括傳感器、RFID、GPS等,這些設備記錄的數據既有實時的流數據,也有像記錄產品交易信息的非實時數據,常用數據流處理系統、模數轉換器等來感知和獲取數據。
3.2 數據預處理技術
大數據源中既有同構數據也含有大量的異構數據,目標數據常會受到噪聲數據的干擾,影響到數據的準確性、完整性和一致性。為提升大數據質量,需要對原始數據進行數據清理、數據集成、數據規約與數據轉換等預處理工作。
大數據清理是通過設置一些過濾器,對原始數據進行“去噪”和“去臟”處理。常用到的技術有數據一致性檢測技術、臟數據識別技術、數據過濾技術、噪聲識別與平滑處理技術等。
大數據集成是指把來自不同數據源、不同格式的數據通過技術處理,在邏輯上或物理上進行集中,形成統一的數據集或數據庫。常用到的技術包括數據源識別技術、中間件技術、數據倉庫技術等。
大數據規約是在不影響數據準確性的前提下,運用壓縮和分類分層的策略對數據進行集約式處理。常用到的技術有維規約技術、數值規約技術、數據壓縮技術、數據抽樣技術等。
大數據轉換是將數據從一種表示形式轉換成另一種表示形式,目的是使數據形式趨于一致。常用到的技術有基于規則或元數據的轉換技術、基于模型和學習的轉換技術等。
3.3 數據存儲與管理技術
目前,除了傳統關系型數據庫外,大數據存儲和管理形式主要有3類:分布式文件系統、非關系型數據庫和數據倉庫。
分布式文件系統是由物理上不同分布的網絡節點,通過網絡通信和數據傳輸統一提供文件服務與管理的文件系統,它的文件物理上被分散存儲在不同的節點上,邏輯上任然是一個完整的文件。常用的分布式文件系統有Hadoop的HDFS、Google的GFS等。
非關系型數據庫(Not Only SQL,NoSQL)是為解決大規模數據集合多重數據種類存儲難題應運而生的,它的最大特點就是不需要預先定義數據結構,而是在有了數據后根據需要靈活定義。非關系型數據庫一般分為4類:鍵值(Key-Value)存儲數據庫,主要利用哈希表中的特定鍵值對來實現數據存儲,常見的有Redis、Apache Cassandra等;列存儲數據庫,是按行排序以數據列為單位進行存儲,有利于對數據庫進行壓縮,減少數據規模,提高存儲和數據查詢性能,常見的有Sybase IQ、InfiniDB等;文檔型數據庫,是按封包鍵值對的方式進行存儲,每個“文檔”(如XML、HTML、JSON文檔等)代表一個數據記錄,記錄著數據的具體類型和內容,常見的有MongoDB、CouchDB等;圖形數據庫,是利用圖形模型實現數據的存儲,主要存儲事物與事物之間的相關關系,將這些相關關系所呈現負責的網絡關系簡單地稱為圖形數據,常見的有Google Pregel、Neo4J等。
數據倉庫建立在已有大量操作型數據庫的基礎上,通過ETL等技術從已有數據庫中抽取轉換導出目標數據并進行存儲。與操作型數據庫不同,數據倉庫不參與具體業務數據操作,主要目的是對從操作型數據庫中抽取集成的海量數據進行分析處理,并提供高速查詢服務。
3.4 數據分析技術
數據分析是大數據處理流程中最為關鍵的步驟,也是大數據價值生成的核心部分。從對數據信息的獲知度上來看,大數據分析可以分為對已知數據信息的分析和對未知數據信息的分析。對已知數據信息的分析一般運用分布式統計分析技術來實現,對未知數據信息的分析一般通過數據挖掘等技術來實現。
大數據統計分析主要利用分布式計算集群和分布式數據庫,運用統計學相關知識和算法(如聚類分析、判別分析、差異分析等),對獲取的海量已知數據信息進行分析和解釋。目前,比較流行的大數據統計分析工具是基于R語言的分布式計算環境(如RHIPE)。
數據挖掘是從海量的數據中通過算法計算,提取隱藏在其中的有用信息的數據分析過程,是統計分析、情報檢索、模式識別、機器學習等數據分析方法的綜合運用。在大數據領域中,常見數據挖掘方法主要包括聚類分析、分類分析、預測估計、相關分析等。
3.5 數據可視化技術
大數據可視化技術的工作原理,是運用計算機圖形學和圖像處理技術將數據以圖形或圖像的方式展示出來,實現對大數據分析結果的形象解釋,并能夠實現對數據的人機交互處理。大數據可視化關鍵技術包括:符號表達技術、數據渲染技術、數據交互技術、數據表達模型技術等。
大數據可視化技術與傳統數據可視化技術不同。傳統數據可視化技術通常是從關系數據庫或數據倉庫中提取數據(數據類型較為單一)并進行可視化處理,一般不支持實時數據的可視化和交互式的可視化分析。而大數據可視化技術則是從多個數據源提取多種類型數據進行可視化處理,并且支持實時數據的可視化和交互式的可視化分析。常見的可視化處理和管理工具有Tableau Desktop、QlikView、Datawatch、Platfora等。
3.6 數據安全與隱私保護技術
大數據應用在商業、政府決策、軍事等領域創造了巨大價值,同時也正是受利益驅使,大數據的安全和隱私保護也正面臨著愈來愈嚴重的威脅。從大數據的關鍵技術來看,大數據處理的每個階段幾乎都面臨著各種各樣的安全威脅[29,54],傳統的信息安全技術措施很難對大數據進行有效的安全防護[55]。越來越多的人開始重視大數據的安全和隱私保護,并開始著重研究應對安全隱患和保護隱私的技術措施。
保護大數據安全,主要是保證大數據的可用性、完整性、機密性[56]。大數據來源廣泛、模態復雜,大量數據來自于不可信的數據源,同時收集到的大數據常常會有字段缺失或數據錯誤的情況,導致大數據不可用或弱可用以及完整性缺失。解決大數據可用性問題一般通過數據冗余設置,而大數據的完整性問題一般通過數據校驗技術和審計策略來解決。對于大數據的機密性,由于數據規模大,傳統的數據加密技術會極大地增加開銷,因此一般利用訪問控制和安全審計技術來保證大數據的安全。
由于監管和法律條款的缺失,大數據在收集和發布等過程中常常會涉及個人或數據擁有者的隱私,導致隱私信息被泄露。目前,除了加強監管和完善立法外,在技術層面研究人員也在不斷地探索和突破。文獻[57]從密碼學的角度綜述了大數據隱私保護技術,包括安全審計技術、大數據加密搜索技術、完全同態加密技術。針對大數據背景下個人隱私數據的保護,文獻[58]設計了一套個人數據溯源機制,一定程度起到了對個人隱私的保護。文獻[59]以云計算為背景,深入研究了基于不經意隨機訪問存儲器的隱私保護、基于對稱加密的隱私保護、基于公鑰體制的隱私保護、可搜索加密等技術和方法,一定程度反映了大數據的隱私保護研究現狀。
4 結 束 語
大數據很“熱”,其在當下的價值貢獻和未來的應用前景已經引起了各個領域的高度重視并開始付諸實踐,但其中也不乏炒作的因素。大數據需要變“冷”,需要人們用平常心冷靜地看待、研究和應用;大數據還沒有統一的標準,在體系架構和核心技術上需要進一步完善和創新,特別是大數據的安全和隱私保護機制更需要在立法、監管、安全保護、響應處理等方面進行系統化、標準化。大數據被稱為科學研究的“第四范式”,是一場新的技術革命。大數據催生了智能時代,促進了機器智能的發展;大數據也勢必催生新的戰爭模式,加速推進武器裝備的信息化、智能化。未來戰爭將是數據驅動型的戰爭,誰掌握制數據權誰將取得戰爭的勝利。扎實推進我軍的大數據應用與創新,將會使我國的國防實力產生質的飛躍。
References)
[1]2015中國互聯網、社交和移動數據報告[EB/OL].(2015-09-21)[2016-04-05].http://tech.163.com/15/0921/10/B41EHHAG00094P40.html.
[2]EMC Digital Universe.The digital universe of opportunities:rich data and the increasing value of the internet of things(executive summary)[EB/OL].(2014-04-05)[2016-04-05].http://www.emc.com/ leadership/digital-universe/ 2014iview/executive-summary.htm.
[3]IDC.New IDC forecast sees worldwide big data technology and services market growing to MYM48.6 billion in 2019,driven by wide adoption across industries[EB/OL].(2015-11-09)[2016-04-05].http://www.idc.com/getdoc.jsp?containerId=prUS40560115.
[4]IDC.中國大數據技術與服務市場2013—2017年預測與分析[EB/OL].(2014-03-05)[2016-04-05].http://www.idc.com.cn/prodserv/detail.jsp?id=NTc3.
[5]LUDLOFF M.IDG IDC’s latest digital data study:a deep dive[EB/OL].(2011-07-08)[2016-04-05].http://blog.Patternbuilders.com/2011/07/08/idcs-latest-digital-data-study-deep-dive.
[6]TechAmerica Foundation’s Federal Big Data Commission.Demystifying big data[R/OL].(2012-10-10)[2016-04-06].http://www.kdnuggets.com/2012/10/techamerica-demystifying-big-data-report.html.
[7]Big data[EB/OL].[2016-04-06].http://baike.baidu.com/link?url=b5lUEoIdzxfvAAzFnhZcO8jFkUyUIIycCg SS1KFH5dsJ vemrma75706H5i3kgUbqhY_uXLxO1Wbh DITM9AKzLEWzhhrt9FEfeHDN0W4qVSm.
[8]ADRIAN M.It’s going mainstream, and it’s your next opportunity [EB/OL].(2011-11-01)[2016-04-06].http://www.teradatamagazine.com/v11n01/Features/Big-Data/.
[9]Big data[EB/OL].[2016-04-06].http://www.gartner.com/it-glossary/big-data.
[10]Big data[EB/OL].[2016-04-06].http://en.wikipedia.org/wiki/Big_data.
[11]VENNILA.S, PRIYADARSHINI J.Scalable privacy preservation in big data a survey[J].Procedia Computer Science,2015,50:369-373.
[12]KSHETRI N.Big data's impact on privacy,security and consumer welfare[J].Telecommunications Policy,2014,38:1134-1145.
[13]DEMCHENKO Y,NGO C, DE LAAT C,et al.Big security for big data:addressing security challenges for the big data infrastructure[C]//Secure Data Management.10thVLDB Workshop,SDM .Cham, Switzerland:Springer International Publishing,2013:76-91.
[14]JIN X L, WAHA B W,CHENG X Q, et al.Significance and challenges of big data research[J].Big Data Research,2015,2(2):59-64.
[15]BEDI P, JINDAL V, GAUTAM A.Beginning with big data simplified[C]//2014 International Conference on Data Mining and Intelligent Computing(ICDMIC).New Jersey:Institute of Electrical and Electronics Engineers Inc,2014:1-7.
[16]ALI-UD-DIN KHAN M, UDDIN M F, GUPTA N.Seven V’s of big data understanding big data to extract value[C]//2014 Zone 1 Conference of the American Society for Engineering Education(ASEE Zone 1).New Jersey:Institute of Electrical and Electronics Engineers Inc,2014:1-4.
[17]孟小峰,慈祥.大數據管理:概念、技術與挑戰[J].計算機研究與發展, 2013, 50(1):146-169.
[18]Gartner.Gartner’s 2013 hype cycle for emerging technologies maps out evolving relationship between humans and machines[EB/OL].(2013-08-19)[2016-04-10].http://www.gartner.com/newsroom/id/2575515.
[19]Gartner.Gartner’s 2014 hype cycle for emerging technologies maps the journey to digital business[EB/OL].(2014-08-11)[2016-04-10].http://www.gartner.com/newsroom/id/2819918.
[20]Gartner.Gartner’s 2015 hype cycle for emerging technologies identifies the computing innovations that organizations should monitor[EB/OL].(2015-08-18)[2016-04-10].http://www.gartner.com/newsroom/id/3114217.
[21]《大數據發展研究報告》編寫組.綜合分析 冷靜看待 大數據標準化漸行漸近(上)[J].信息技術與標準化,2013(9):12-14.
[22]《大數據發展研究報告》編寫組.綜合分析 冷靜看待 大數據標準化漸行漸近(下)[J].信息技術與標準化,2013(10):17-20.
[23]張群.大數據標準化現狀及標準研制[J].信息技術與標準化,2015(7):23-26.
[24]韓晶,王健全.大數據標準化現狀及展望[J].信息通信技術,2014(6):38-42.
[25]NIST Big Data Public Working Group (NBD-PWG).NIST big data interoperability framework V1.0[EB/OL].(2015-08-25)[2016-04-10].http://www.nist.gov/itl/bigdata/bigdatainfo.cfm.
[26]ISO/IEC .Systems and software engineering-recommended practice for architectural description of software-intensive systems:IEEE Std 1471-2000 [S].New York:Institute of Electrical and Electronics Engineers, Inc ,2000:1-11.
[27]NIST Big Data Public Working Group (NBD-PWG).NIST big data interoperability framework:volume 5,architectures white paper survey[R/OL].(2015-08-25)[2016-04-10].http://dx.doi.org/10.6028/NIST.SP.1500-5.
[28]NIST Big Data Public Working Group (NBD-PWG).NIST big data interoperability framework:volume 6,reference architecture[R/OL].(2015-08-25)[2016-04-10].http://dx.doi.org/10.6028/NIST.SP.1500-6.
[29]全國信息技術標準化技術委員會大數據標準工作組.大數據標準化白皮書(2016版)[R].北京:中國電子技術標準化研究院,2016:1-97.
[30]WHITE T.Hadoop權威指南 [M].曾大聃,周傲英,譯.北京:清華大學出版社,2010:13-14.
[31]董西成.Hadoop技術內幕:深入解析MapReduce架構設計與實現原理[M].北京:機械工業出版社,2013:33-37.
[32]費仕憶.Hadoop大數據平臺與傳統數據倉庫的協作研究[D].上海:東華大學,2014:4-8.
[33]高薊超.Hadoop平臺存儲策略的研究與優化[D].北京:北京交通大學,2012:2-13.
[34]曹風兵.基于Hadoop的云計算模型研究與應用[D].重慶:重慶大學,2011:15-28.
[35]李韌.基于Hadoop的大規模語義Web本體數據查詢與推理關鍵技術研究[D].重慶:重慶大學,2013:14-17.
[36]楊宸鑄.基于HADOOP的數據挖掘研究[D].重慶:重慶大學,2010:5-19.
[37]潘陽.基于Hadoop技術在分布式數據存儲中的應用研究[D].大連:大連海事大學,2014:8-27.
[38]李嬌龍.基于Hadoop 的云計算應用研究[D].成都:電子科技大學,2014:13-26.
[39]JAIN A,NALYA A.Learning storm[M].Birmingham:Packt Publishing,2014:19-24.
[40]ESKANDARI L, HUANG Z Y, EYERS D.P-scheduler:adaptive hierarchical scheduling in apache storm [C]//Australasian Computer Science Week(ACSW) ’16 Multiconference.Canberra,Australia:ACM,2016:1-3.
[41]陳敏敏,王新春,黃奉線.Storm技術內幕與大數據實踐[M].北京:人民郵電出版社,2015:2-95.
[42]龍少杭.基于Storm的實時大數據分析系統的研究與實現[D].上海:上海交通大學,2015:18-22.
[43]鄧立龍,徐海水.Storm 實現的應用模型研究[J].廣東工業大學學報,2014,31(3):114-115.
[44]李川,鄂海紅,宋美娜.基于Storm 的實時計算框架的研究與應用[J].軟件,2014,35(10):17-18.
[45]KARAU H, KONWINSKI A, WENDELL P, et al.Learning spark[M].Sebastopol:O’Reilly Media,2015:1-7.
[46]李文棟.基于Spark的大數據挖掘技術的研究與實現[D].濟南:山東大學,2015:8-12.
[47]孫科.基于Spark的機器學習應用框架研究與實現[D].上海:上海交通大學,2015:20-22.
[48]胡俊,胡賢德,程家興.基于Spark 的大數據混合計算模型[J].計算機系統應用,2015,24(4):214-217.
[49]胡于響.基于Spark的推薦系統的設計與實現[D].杭州:浙江大學,2015:6-9.
[50]邱榮財.基于Spark平臺的CURE算法并行化設計與應用[D].廣州:華南理工大學,2014:7-14.
[51]方艾,徐雄,梁冰,等.主流大數據處理開源架構的分析及對比評測[J].電信科學,2015,(7):2-5.
[52]LI G J,CHENG X Q.Research status and scientific thinking of big data[J].Bulletin of Chinese Academy of Sciences,2012,27(6):647-657.
[53]MAYER-SCHONBERGER V, CUKIER K.大數據時代[M].盛揚燕,周濤,譯.杭州:浙江人民出版社,2013:193-232.
[54]TeraData.The threat beneath the surface:big data ana-lytics,big security and real-time cyber threat response for federal agencies[R].California:TeraData,2012:1-35.
[55]孟小峰,張嘯劍.大數據隱私管理[J].計算機研究與發展,2015,52(2):265-281.
[56]何小東,陳偉宏,彭智朝.網絡安全概論[M].北京:清華大學出版社,2014:272-278.
[57]黃劉生,田苗苗,黃河.大數據隱私保護密碼技術研究綜述[J].軟件學報,2015, 26(4):945-953.
[58]王忠,殷建立.大數據環境下個人數據隱私泄露溯源機制設計[J].中國流通經濟,2014(8):117-120.
[59]肖人毅.云計算中數據隱私保護研究進展[J].通信學報,2014,35(12):168-174.
(編輯:李江濤)
Big Data and Its Architecture and Key Technologies
LYU Denglong1, ZHU Shibing2
(1. Department of Graduate Management, Equipment Academy, Beijing 101416, China;2. Department of Information Equipment, Equipment Academy, Beijing 101416, China)
This paper introduces the status, research activities and application perspectives of big data. In order to solve the problems like inconsistent standards for big data and different views among researchers, the paper redefines the big data in a new aspect by comparative analysis; especially in the respect of security, the paper analyzes and summarizes the "6V" feature of the big data; starting from the standardization of big data, this paper further analyzes existing research results, concludes the architecture of big data and generic technology in application, analyzes the connotation of various technologies and presents the architecture and key technologies of big data systematically.
big data; architecture; key technologies
2016-09-20
呂登龍(1983—),男,講師,博士研究生,主要研究方向為信息網絡與安全。 朱詩兵,男,教授,博士生導師。
TP311
2095-3828(2017)01-0086-11
A DOI 10.3783/j.issn.2095-3828.2017.01.017
