LDA模型在專利文本分類中的應用
2017-04-07 16:18:47廖列法勒孚剛朱亞蘭
現(xiàn)代情報 2017年3期
廖列法+勒孚剛+朱亞蘭


〔摘要〕對傳統(tǒng)專利文本自動分類方法中,使用向量空間模型文本表示方法存在的問題,提出一種基于LDA模型專利文本分類方法。該方法利用LDA主題模型對專利文本語料庫建模,提取專利文本的文檔-主題和主題-特征詞矩陣,達到降維目的和提取文檔間的語義聯(lián)系,引入類的類-主題矩陣,為類進行主題語義拓展,使用主題相似度構(gòu)造層次分類,小類采用KNN分類方法。實驗結(jié)果:與基于向量空間文本表示模型的KNN專利文本分類方法對比,此方法能夠獲得更高的分類評估指數(shù)。
〔關鍵詞〕LDA;主題模型;專利文本分類;主題相似度
DOI:10.3969/j.issn.1008-0821.2017.03.007
〔中圖分類號〕G25553;G2541〔文獻標識碼〕A〔文章編號〕1008-0821(2017)03-0035-05
〔Abstract〕A new text classification method based on LDA model is proposed to solve the problem of traditional VSM text categorization.The LDA topic model was used to model the patent text corpus,and the document-topic and topic-feature word matrix of the patent text was extracted to achieve the purpose of dimension reduction and to extract semantic links between documents.The class-topic matrix was introduced,Topic semantic extension,hierarchical classification using theme similarity,and KNN classification by subclass.Experimental results:Compared with the KNN patent text classification method based on vector space text representation model,this method can obtain higher classification evaluation index.
〔Key words〕LDA;topic model;patent text classification;topic similarity
根據(jù)2016年世界知識產(chǎn)權組織(WIPO)在日內(nèi)瓦總部發(fā)布的《世界知識產(chǎn)權指標》年度報告顯示,2015年中國國家知識產(chǎn)權局受理的專利申請數(shù)量超過110萬件,相當于美國、日本和韓國的專利申請數(shù)量總和。從全球排名來看,中國位居首位;美國居于第二,數(shù)量為589萬件;日本第三,數(shù)量為318萬件。我們國家實施創(chuàng)新驅(qū)動發(fā)展戰(zhàn)略,對于科研人員的科技成果轉(zhuǎn)化方面的激勵和科技創(chuàng)新企業(yè)的納稅政策優(yōu)惠等都有效地推動了專利申請數(shù)量的提升。面對如此海量的專利文獻數(shù)據(jù),僅僅依靠工作人員采用傳統(tǒng)的手工分類不僅效率低下,而且人力和物力資源耗費量巨大。因此,專利文獻的自動分類方法研究顯得極為重要和迫不及待,它已成為科研人員現(xiàn)階段一個研究熱點和重點[1]。與一般的文本相對,專利文本具有結(jié)構(gòu)特殊、專業(yè)性強、領域詞匯較多等特點,因此相對傳統(tǒng)的文本分類而言,專利文本需要采用更加針對的分類方法[2]。
在文本分類中,文本的表示直接影響到特征值的選取,好的特征值選取方法可以有效提高分類方法的效率,目前的專利文本分類方法的文本表示都是基于向量空間模型(Vector Space Model,VSM)算法[3],并沒有涉及概率主題模型。例如:李程雄、丁月華和文貴華[4]提出并分析結(jié)合SVM算法和KNN算法的組合改進算法SVM-KNN,當樣本和SVM最優(yōu)超平面的距離大于給定的闕值,即樣本離分界面較遠,則用SVM分類,反之用KNN算法對測試樣本分類,比單一的算法取得了更優(yōu)的分類效果。蔣健安、陸介平、倪巍偉等[5]設計的層次分類算法先采用Rocchio算法進行專利大類的區(qū)分,再對各個大類之間的文本采用KNN方法進行小類的細分,由于大類之間的區(qū)分度較大,故可以使用Rocchio算法,而相同大類之間的小類分別較小,采用KNN算法更能區(qū)分。郭煒強、戴天、文貴華[6]根據(jù)改進的詞語權重計算方法構(gòu)造給定文本的特征向量,從分類表IPC中直接提取類別的概念向量和待分類專利文本的特征向量,然后采用向量空間模型實現(xiàn)專利的自動分類。
結(jié)合計算機語言學,概率空間模型在文本表示上具有更加優(yōu)異的效果,能夠提取變現(xiàn)力更強的特征詞匯,能使文本的分類效果更好。則概率空間模型代替詞向量模型運用在文本表示中是一種趨勢,故本文提出一種基于LDA(Latent Dirichlet Allocation)模型[7]的專利文本分類方法,LDA模型是符合文本生成規(guī)律的全概率生成模型,具有好的文本表示能力,提取具有語義信息的主題,運用在專利文本分類中,能夠有效提升分類效率。
31向量空間模型用于專利文本分類的不足分析[8]
在對專利文本進行分類時,文本表示一般采用向量空間模型算法,該算法把對文本內(nèi)容處理簡化為向量空間中的向量運算。在向量空間模型中,文檔被映射成由向量組成的多維向量空間,其中每個詞表示1個維度。假設向量的空間維數(shù)為n,則每篇文檔d映射為由二元組組成的特征向量V(d)=(t1,w1(d);…tn,wn(d)),其中ti(i=1,2,…,n)為一列互不相同的特征詞,wi(d)為特征詞ti在文檔d中的權重。傳統(tǒng)的特征詞權重計算普遍采用TF-IDF算法[9],TF-IDF算法考慮了特征詞的詞頻、逆文本頻、歸一化等因素,這些都是文本權重計算中很重要的概念。
但是,在專利文本自動分類中,該算法在處理專利數(shù)據(jù)時有二個明顯的不足:
1)向量空間模型是依據(jù)語料庫中的特征詞,使用TF-IDF算法計算它們的權重,構(gòu)造文檔-特征詞向量,并將整個文檔集構(gòu)造為一個高維、稀疏的特征值-文檔矩陣。其中模型的對向量的維數(shù)難以控制,語料庫特征詞越多則矩陣維數(shù)越高、越稀疏,矩陣的高維稀疏使得實際用來計算的數(shù)值很少,大部分數(shù)值都為0,增加了算法的計算開銷,降低了算法的效率。維數(shù)過大對于算法的產(chǎn)生巨大的計算量,時間和空間復雜度會提高。
2)對于專利的分類,不僅要考慮專利詞匯上的相似性,還要考慮專利的語義內(nèi)容上的相似性。由于專利文本中使用的詞匯都比較專業(yè)化,因此產(chǎn)生的詞匯集相對比較狹窄,產(chǎn)生的專利文本在詞集上會有很多的相似,而VSM模型是根據(jù)詞的頻率及逆文本頻來計算特征詞的權重,并不能很好的對文本進行區(qū)分,所以基于VSM模型的專利文本分類方法的效果很差。應該考慮特征詞間的語義聯(lián)系,及特征詞與類的關聯(lián),從專利文本所表達的語義層面上去理解文本,在語義層面上對專利文本進行分類,這樣才能取得更好的分類效果。
基于上面的兩種問題,傳統(tǒng)的基于VSM模型的專利文本分類方法已經(jīng)不能很好地應用在專利文本分類中了。
2LDA主題模型
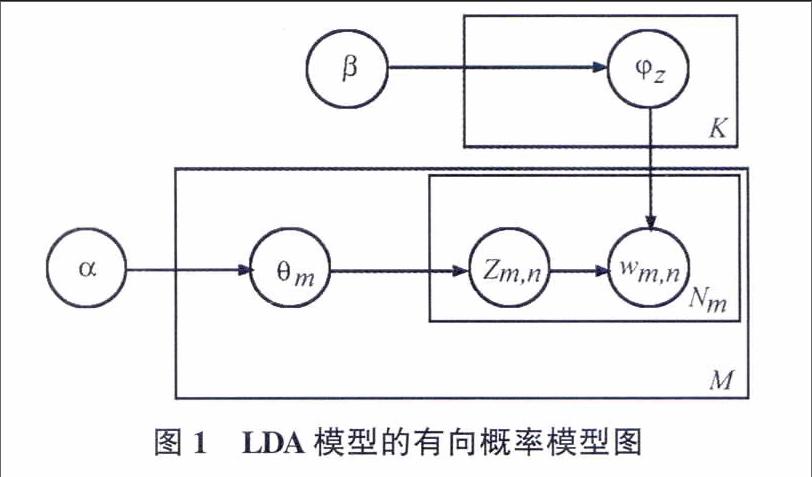
LDA模型是一種對文本數(shù)據(jù)進行有效降維和發(fā)掘潛藏主題信息的方法[10]。它是一個三層貝葉斯概率生成模型,把文檔表示成隱含主題的概率分布,主題表示成詞匯的概率分布,其中主題是對文檔內(nèi)容的匯集,因此模型可以很好地模擬大規(guī)模語料的語義信息。模型的把文檔由主題構(gòu)成,而主題的數(shù)量是一定的,對文檔具有良好的降維能力。LDA的概率模型圖如圖1所示:
LDA模型的生成過程較好地模擬了在生成實際文本的大體思維過程,其具體的數(shù)學化描述如下:
1)對每一篇文檔dm,根據(jù)N~Poisson(ξ)生成文檔dm中詞的數(shù)目Nm;
2)對于每一篇文檔dm,根據(jù)θm~Dir(α)生成文檔dm關于主題多項式分布的參數(shù)θm;
3)對于每一個主題z,根據(jù)φz~Dir(β)生成主題z關于語料庫中詞多項式分布的參數(shù)φz;
4)對于文檔dm的第n個詞wm,n:
a)根據(jù)多項式分布zm,n~Multi(θd),抽樣得到詞wm,n所屬的主題zm,n;
b)根據(jù)多項式分布wm,n~Multi(φz),抽樣得到具體的詞wm,n。
參數(shù)估計是LDA模型的關鍵步驟,假如要直接計算LDA模型的參數(shù)是不能實現(xiàn)的,需要使用間接推理算法來估算模型的參數(shù)值,LDA模型常用的算法有Gibbs抽樣、EM算法、Expectation-Propagation方法、變分推理算法等。其中因為Gibbs抽樣算法具有快速、高效等優(yōu)點,故常被用于LDA模型的參數(shù)估算。
Gibbs抽樣算法詳述如下:
1)初始化。zi被初始化為1到K之間的某個隨機整數(shù)。i從1循環(huán)到N,N是語料庫中所有出現(xiàn)于文本中的詞匯記號個數(shù)。
2)迭代。i從1循環(huán)到N,根據(jù)公式(1)將詞匯分配給主題,獲取Markov鏈的下一個狀態(tài)。
3)估算φ和θ的值。迭代第(2)步足夠次數(shù)以后,認為Markov鏈已經(jīng)接近目標分布,遂取zi(i從1循環(huán)到N)的當前值作為樣本記錄下來。為了保證自相關較小,每迭代一定次數(shù),記錄其他的樣本。舍棄詞匯記號,以w表示惟一性詞,對于每一個單一樣本,可以按下式估算φ和θ:
3基于LDA模型的專利文本分類算法
31確定語義主題數(shù)
LDA模型要進行Gibbs抽樣就要先確認所有的參數(shù),但是主題參數(shù)事先無法確定的,而主題數(shù)的多少對模型的影響非常大,主題數(shù)目過多,將會產(chǎn)生很多不具有明顯語義信息的主題,反之數(shù)目過少將會出現(xiàn)一個主題包含多層語義信息的狀況,兩種狀況都很糟糕,所以科學的確定主題的個數(shù)非常重要。本文采用LDA標準的評價函數(shù)Perplexity(困惑度)來確定最優(yōu)主題數(shù)。
困惑度衡量主題模型對于未觀測數(shù)據(jù)的預測能力,困惑度越小,模型預測能力越強,模型的推廣性越高。其中:Dtest為測試集;wd為文檔d中的可觀測單詞序列;Nd為文檔d的單詞數(shù)目。困惑度公式如下:
32文檔的主題向量提取
對于專利文本數(shù)據(jù),有意義的文本內(nèi)容是標題、摘要、主權項,而標題中出現(xiàn)的特征詞往往更具有代表性,其次是摘要。在不同位置的特征詞對文檔的貢獻程度是不同的,假如直接利用LDA模型對語料庫建模,不考慮特診詞匯在文檔中的位置信息對該文本的區(qū)分度影響,將嚴重影響文本的分類效果。故結(jié)合專利文本數(shù)據(jù)的結(jié)構(gòu)特殊性,體現(xiàn)特征詞匯的位置信息因素,使用一種位置加權來計算文本的主題向量。將標題、摘要和主權項分為3篇文檔,即一篇專利文獻包含3個子文檔,定義為一個三元組D=D(P1,P2,P3),其中P1表示標題,P2表示摘要,P3表示主權項,將3篇子文檔中的主題向量按位置權重計算,從而得到該專利文檔的主題向量,其中θP1表示標題文檔的主題向量,θP2表示摘要文檔的主題向量,θP3表示主權項的主題向量,計算公式如下:
33類-主題矩陣
LDA模型將文檔表示成三層模型,即文檔層、主題層和詞匯層,文檔由主題向量構(gòu)成,主題由詞匯向量構(gòu)成,從而對文檔進行降維表示。根據(jù)已有的LDA模型討論:文檔集是由各種類別的文檔組成,文檔集和類別之間存在一對多映射關系,類別和文檔之間也存在一對多映射關系,可理解為類別就是一個子文檔集,由主題和文檔的關系,用主題向量對子文檔集降維,即類和隱含主題之間存在著一定的概率分布,向標準的LDA模型中添加一層即文檔類別層。類的隱含主題信息拓撲結(jié)構(gòu)如圖2所示:
從帶類別標簽訓練文檔的文檔-主題矩陣中提取類-主題矩陣。把帶相同類別標簽的文檔建立成一個文檔-主題矩陣,計算這個矩陣每列的平均值,得到該類的類-主題向量,所有的類-主題向量構(gòu)成類-主題矩陣。其中γci表示類別c關于主題i的概率,M表示關于類別c的文檔數(shù),θmi是類別c中第m篇文檔關于主題i的概率,計算公式如下:
在上面的公式中,若主題i在c類文檔中出現(xiàn)的概率高,則表示這一隱含主題對于類別i具有強表現(xiàn)性,在類間具有較強的類別區(qū)分能力,概率較小的主題,則表示與該類具有弱變現(xiàn)性,與該類的關聯(lián)程度較低。
34基于LDA模型的專利文本分類算法
專利分類擁有一套國際專利分類體系(簡稱IPC分類),它是我國常用的分類體系,IPC分類[11]號包括了與發(fā)明創(chuàng)造有關的全部知識領域。IPC分類號采用層級的形式,將技術內(nèi)容注明:部-分部-大類-小類-大組-小組,逐級形成完整的類別體系。故需要對專利文本進行層次分類,部屬于專利分類的最高級,屬于不同學科領域,較好分類,大類屬于同一學科里的不同方面,類別區(qū)分難度一般,故部和大類的分類都采用類間相似度構(gòu)造分類器進行分類;而小類屬于同一技術的不同研究方向,較難區(qū)分,故采用普遍認為具有高分類性能的KNN方法。
具體的算法步驟描述如下:
輸入:帶類別標記的訓練文本集,測試文本
輸出:測試文本的所屬類別
步驟1:獲取專利文本數(shù)據(jù),并將文本分為訓練文本集和測試文本集。
步驟2:對訓練文本和測試文本進行預處理,包括:分詞、去停頓詞,及使用TF-IDF算法對詞匯過濾,將權重小于01的詞除去,建立訓練文本的語料庫。
步驟3:利用LDA模型對語料庫建模,提取語料庫的文檔-主題和主題-詞匯矩陣。
步驟4:根據(jù)帶標簽的文檔-主題矩陣提取部-主題矩陣和大類-主題矩陣。計算每一篇待測試專利文本的主題與各個部和類別主題間的相似度,相似度度量采用余弦相似度算法來計算。其中Cz為類別的主題向量,θz為測試文檔的主題向量。計算公式如下:
步驟5:部。將待分類文檔與各部的部-主題向量計算相似度,相似度最大的為文本所屬部號。
步驟6:大類。將具有部號的待分類文本與本部的各大類計算主題相似度,其中相似度值最大的為文本所屬大類。
步驟7:小類。對確定大類的文本與屬于該大類的訓練文本計算主題相似度,KNN分類方法確定該專利所屬小類。
步驟8:實驗結(jié)果評價。
具體專利文本分類算法基本框架如圖3所示:
4實驗及結(jié)果分析
41實驗數(shù)據(jù)集
為驗證此方法的有效性,本文利用從專利局獲取的稀土專利數(shù)據(jù)進行實驗。實驗數(shù)據(jù)集包含2007-2015年共31 000篇稀土專利文本,每個部選取大類和小類數(shù)量較均勻的1 000篇專利文檔進行訓練和測試,實驗將數(shù)據(jù)集的80%用來訓練模型,20%用來驗證分類算法性能。數(shù)據(jù)具體分布情況見表2。
42評估指標
文本分類性能結(jié)果的評估指標采用F值。F度量值是信息檢索中的一種組合P(準-確率)和R(召回率)指標的平衡指標。計算公式如下:
F的值越與1靠近說明P和R的平衡性越好。相反F的值與0越靠近,則兩個參數(shù)的平衡性越差。
43參數(shù)設定
在LDA建模過程中,確定最優(yōu)主題數(shù)采用Perplexity函數(shù),參數(shù)估計采用MCMC方法中的Gibbs抽樣算法,在LDA建模過程中,根據(jù)經(jīng)驗設置α=50/K、β=001,Gibbs抽樣的迭代次數(shù)參數(shù)Iteration為2000,保存迭代參數(shù)Save Step為1000。其中主題數(shù)K的取值依次為5、10、25、50、100直到200,利用不同的主題數(shù)進行Perplexity函數(shù)分析,獲得最小困惑度得到最優(yōu)主題數(shù)K。
從圖4看出,隨著主題數(shù)目的增加,模型的困惑度值慢慢收斂到一個較小較穩(wěn)定的值,在圖中可以發(fā)現(xiàn)當主題數(shù)K=100時模型的困惑度值開始最小且平穩(wěn),則此時模型的性能最好,所以本實驗的主題數(shù)目取值為100。
44實驗結(jié)果分析
實驗分兩組進行,第一組采用基于向量空間模型的專利文本分類方法,首先采用向量空間模型表示文本,然后運用TF-IDF計算特征值的權重,最后采用KNN方法分類;第二組采用本文提出的基于LDA模型的專利文本分類方法,首先運用LDA方法對語料庫建模,提取各文檔、部和類的主題分布,然后部和大類的分類采用相似度構(gòu)造分類器,計算主題相似度,最后小類的分類采用KNN分類方法。實驗分詞采用的是基于R軟件Rwordseg包segmentCN分詞方法。實驗結(jié)果見表3、表4和圖5。
由實驗結(jié)果可以得知,基于LDA模型的分類方法在正確率、召回率和F值方面均優(yōu)于基于VSM模型的分類方法,故基于LDA模型的專利文本分類方法是有效的,大大提高了專利文本的分類效率。
5結(jié)語
本文主要從文本表示方向?qū)@谋痉诸愡M行改善。
將LDA主題模型應用到專利文本分類中,使得文檔和類由低維具有語義匯集的主題向量表示,達到了較好的降維效果,并引入類-主題矩陣用于文本分類,有效提高分類準確性,使模型的分類性能更加優(yōu)越。本文運用LDA模型專利文本分類時,存在專利文本的標題文本過短的問題,本文并沒有考慮到,下一步工作將結(jié)合短文本的特性設計更優(yōu)的分類方法,進一步提高專利文本分類效率和分類精度。
參考文獻
[1]屈鵬,王惠臨.專利文本分類的基礎問題研究[J].現(xiàn)代圖書情報技術,2013,(3):38-44.
[2]劉紅光,馬雙剛,劉桂鋒.基于機器學習的專利文本分類算法研究綜述[J].圖書情報技術,2016,(3):79-86.
[3]龐劍鋒,卜東波.基于向量空間模型的文本自動分類系統(tǒng)的研究與實現(xiàn)[J].計算機應用研究,2001,18(9):23-26.
[4]李程雄,丁月華,文貴華.SVM-KNN組合改進算法在專利文本分類中的應用[J].計算機工程與應用,2006,42(20):193-195.
[5]蔣健安,陸介平,倪巍偉,等.一種面向?qū)@墨I數(shù)據(jù)的文本自動分類方法[J].計算機應用,2008,28(1):159-161.
[6]郭煒強,戴天,文貴華.基于領域知識的專利自動分類[J].計算機工程,2005,31(23):52-54.
[7]Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].Journal of machine Learning research,2003,3(1):993-1022.
[8]胡冰,張建立.基于統(tǒng)計分布的中文專利自動分類方法研究[J].現(xiàn)代圖書情報技術,2013,(Z1):101-106.
[9]施聰鶯,徐朝軍,楊曉江.TFIDF算法研究綜述[J].計算機應用,2009,29(s1):167-170.
[10]姚全珠,宋志理,彭程.基于LDA模型的文本分類研究[J].計算機工程與應用,2011,47(13):150-153.
[11]繆建明,賈廣威,張運良.基于摘要文本的專利快速自動分類方法[J].情報理論與實踐,2016,(8):103-105.
(本文責任編輯:孫國雷)
