基于設備本底噪聲頻譜特征的手機來源識別
2017-05-03 07:37:39裴安山王讓定嚴迪群
電信科學 2017年1期
關鍵詞:特征
裴安山,王讓定,嚴迪群
(寧波大學,浙江 寧波 315211)
基于設備本底噪聲頻譜特征的手機來源識別
裴安山,王讓定,嚴迪群
(寧波大學,浙江 寧波 315211)
隨著手機錄音設備的普及以及各種功能強大且易于操作的數字媒體編輯軟件的出現,手機來源識別已成為多媒體取證領域的熱點問題。將本底噪聲作為手機的“指紋”,提出了一種基于本底噪聲的手機來源識別方法。該方法先通過靜音段錄音的估計得到本底噪聲;然后計算本底噪聲的頻譜特征在時間軸方向上的均值,將其作為手機來源識別的分類特征;最后采用主成分分析(PCA)法對特征進行降維,并采用支持向量機(SVM)進行分類。實驗部分對 24款主流型號的手機進行了分類,結果表明本文方法的平均識別準確率(accuracy)和平均召回率(recall)達到了99.24%,同時也驗證了相比MFCC,本底噪聲有更加優越的性能。
多媒體取證;手機來源識別;本底噪聲;頻譜特征
1 引言
如今,隨著移動互聯網和微芯片產業的發展,移動終端成為人們生活中不可或缺的部分。越來越多的人開始用智能手機、Pad等便攜設備捕捉和采集他們看到或聽到的情景,而不是用相機、錄音筆、DV等專業設備。大量數字采集設備和采集數據的可用性帶來了新的問題和挑戰——多媒體的安全問題。作為一種檢測多媒體數據獨創性、真實性、完整性的技術,多媒體取證技術是信息安全領域的熱點研究問題[1]。
基于語音的手機來源識別是與多媒體取證最相關的應用之一,用來確定錄制語音文件的手機型號。這一研究方向引起了大量取證研究者的關注,并在近年獲得重大進展[2-5]。Hanilci等人[6]通過提取錄音文件的MFCC(梅爾倒譜系數)特征進行手機品牌和型號的識別。在14個不同型號手機的閉集識別實驗中,識別率達到96.42%。此后,又比較了MFCC、LFCC(線性倒譜系數)、BFCC(Bark頻率倒譜系數)和LPCC(線性預測倒譜系數)[7]在手機來源識別中效果的優劣,實驗得出MFCC特征在手機來源識別中效果最好。在手機的來源識別領域還有很多重要的成果[8-10],Kotropoulos[11]通過對不同手機采集的語音信號頻譜取對數,然后沿時間軸取平均,或者通過對每一幀的特征參數利用高斯混合模型建模得到高維的特征向量,然后映射到低維空間進行降維。在7個品牌21個型號的手機來源識別實驗中,識別率達到94%。王志鋒等人[12]考慮到語音段中的靜音包含了與正常語音一樣的設備信息,并且不受說話人、文本、情感等因素的影響,因此從靜音段中提出表征錄音設備的特征。然后利用設備通用背景模型構建設備模型。最后通過歸一化似然度得分,對輸入的錄音設備的語音樣本特征進行分類判決。實驗結果表明,他們的算法對于9種不同設備的平均識別率為87.42%。鄒領等人[13]提出了一種基于噪聲估計的錄音設備源識別方法,通過錄音設備源識別實驗以及與其他幾種常用的錄音設備源識別特征,包括MFCC均值特征、基于MFCC的GLDS kernel超向量特征以及SSF特征做比較,證明了該方法的有效性。
然而,現有大多數手機來源識別的研究是基于MFCC特征或MFCC的統計分類特征的。雖然相關特征在手機來源識別中取得了令人滿意的效果,但是梅爾頻帶近似人類聽覺系統的響應,分類效果可能受到許多不確定條件的干擾,如說話人的性別、情感、語音內容等。為了有效捕獲手機的內在“指紋”,將本底噪聲作為相同型號手機特有的身份特征。本底噪聲是設備自身產生的信號,它的特性主要受電路設計和電子元器件的影響。因為不同型號的手機電路設計和電子元器件的使用不一致性,所以不同型號的手機沒有完全相同的本底噪聲。本文提出了一種基于本底噪聲頻譜分布特征的手機來源識別方法。實驗結果表明,本底噪聲的頻譜分布特征能夠對數據庫中的手機進行識別分類,平均識別準確率和平均召回率可以達到99.24%。
2 本底噪聲
2.1 本底噪聲的定義
手機的本底噪聲是手機本身產生的噪聲,是一種在沒有輸入信號的情況下也能產生的噪聲。在電子學中,所有組件的溫度在絕對零度以上時,都將產生自己的噪聲。而錄音在采集過程中可能會受到錄音軟件和系統操作版本的影響,另外,部分手機可能包含語音壓縮等信號處理過程,因此本文研究的本底噪聲是廣義上的本底噪聲。在研究中默認使用系統自帶的錄音軟件,對手機電子元器件和電路設計對本底噪聲的影響進行整體研究,針對系統版本對本底噪聲的影響挑選幾款典型的手機進行對比研究[13-15]。圖1為數字語音錄音系統的簡化示意,可以看出,背景噪聲和本底噪聲是獨立的,本底噪聲主要由與麥克風相關的電子元件及編碼傳輸失真產生的噪聲組成。
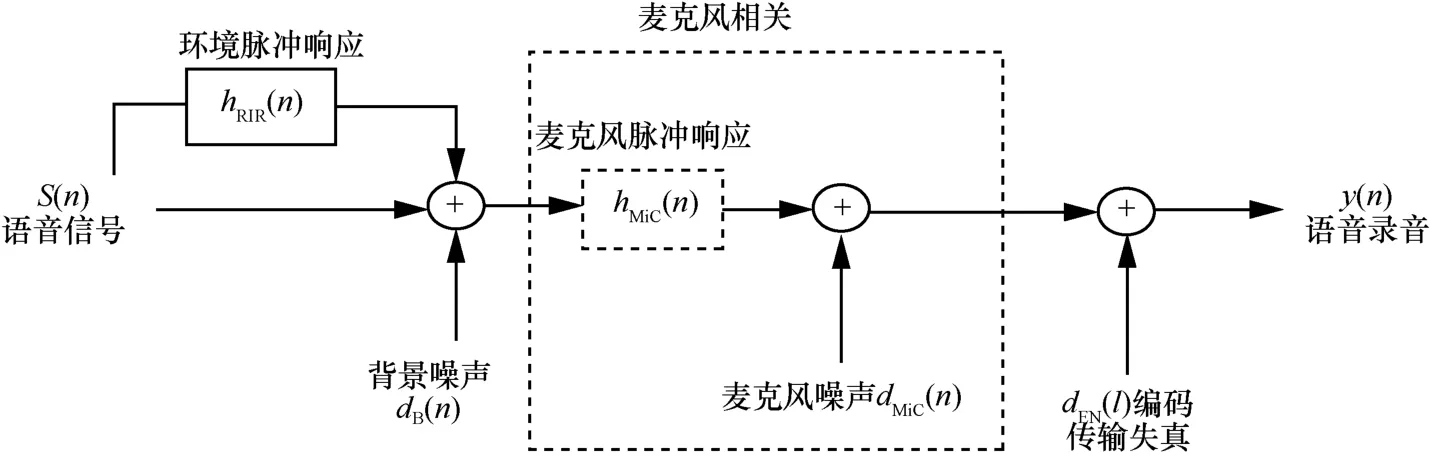
圖1 數字語音錄音系統簡化示意

表1 實驗中手機的品牌和型號以及類名
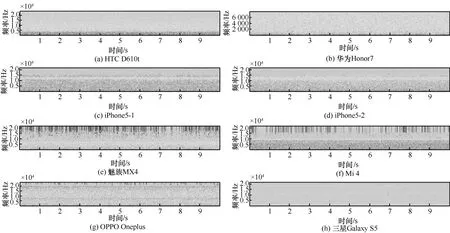
圖2 不同手機品牌的本底噪聲語譜
本底噪聲的定義表明,本底噪聲的特性與手機的電路設計和電子元器件的使用密切相關。由于不同型號的手機在電路設計和電子元器件的使用上存在部分差異。所以,本底噪聲可以作為手機的“指紋”進行手機的來源識別。
2.2 本底噪聲的性質
為了研究本底噪聲的特性,對現下流行的7個品牌24個型號的25臺設備 (其中有兩臺iPhone 5)進行了研究,具體手機型號見表1。實際本底噪聲樣本是在無回聲的錄音棚的靜音環境下錄制的。為了避免其他電氣設備噪聲對實驗的干擾,當手機在錄音時,關閉了整個錄音棚的電源開關。
語譜是語音信號的頻譜隨時間變化的直觀展示。為了研究本底噪聲的頻譜特性,圖2給出了其中8個手機的本底噪聲語譜。通過觀察圖2可以看出,不同品牌手機的本底噪聲語譜存在很大差異。例如,魅族MX4本底噪聲語譜的振幅曲線是隨頻率呈波動變化趨勢的,HTC D610t的本底噪聲語譜在頻率為4 000 Hz附近有大幅下降,三星Galaxy S5本底噪聲的能量在所有的頻點間隔(0~16 kHz)是最弱的,而相同型號的手機(如iPhone 5)的語譜比較相似。
圖3以iPhone手機為例,給出了相同品牌不同型號手機的語譜。通過圖3可以看出,同一品牌手機的本底噪聲語譜在一定程度上是相似的,不同型號手機間的語譜區別較小,但是在低頻部分的噪聲強度上仍有一定區別,需要構建特征并選用合適的分類算法進行區分。基于圖2和圖3的分析可得,顯示語譜內在變化的頻譜分布特征可以作為手機設備來源識別的特征。

圖3 蘋果品牌手機的語譜
以HTC D610t、iPhone 5和Mi 4為例,對3臺手機的操作系統版本進行了升級,以驗證系統版本對本底噪聲的影響。圖4是升級后3臺手機本底噪聲的語譜,由圖4和圖2中3臺手機的語譜對比可得,HTC D610t和iPhone 5系統升級前后本底噪聲語譜沒有明顯變化,Mi 4手機操作系統升級前后本底噪聲語譜變化較兩者略大,主要是高頻部分本底噪聲的能量有些許差別。
3 基于本底噪聲的特征提取和來源識別
3.1 本底噪聲的估計
本文將本底噪聲作為手機來源識別的基本特征。因為本底噪聲不等同于語音的噪聲,所以本底噪聲的估計是一項具有挑戰性的工作。因此,本文提出兩步實現本底噪聲估計的方法。
(1)靜音段提取
靜音段提取原因是:語音的靜音段主要由本底噪聲和背景噪聲構成,不會被語音部分的綜合噪聲中占主導地位的聲電響應不一致噪聲所污染[16]。本文采用自適應端點檢測算法進行靜音段估計[17]。如圖5(a)和圖5(b)所示,該方法可以很好地識別靜音段。從圖5(c)可以看出,經過自適應端點檢測算法得到的靜音段還含有少量語音信息。為了進一步消除不必要的語音信息,使用函數ns(·)對靜音段進行了后處理,如式(1)所示:
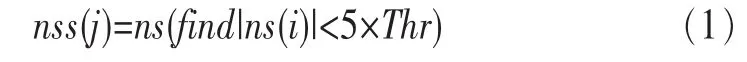
式(1)中Thr是ns(i)升序排列后前40%樣本的均值,find(·)的功能是當ns(i)的絕對值小于5倍的Thr時,定位和輸出ns(i)的位置。
經步驟1處理后,得到一個語音樣本的幾段靜音段,將它們拼接起來得到一個靜音段信號。
(2)背景噪聲抑制
為了從靜音段得到實際的本底噪聲,要盡可能地抑制背景噪聲。首先,采用算法1(改進的頻譜減法)的偽代碼抑制背景噪聲。然后根據式(2)計算5 760個語音樣本(24個手機,每個手機240個樣本)的通用背景噪聲模型。

其中,i是手機型號的索引,BNi是背景噪聲的語譜,BNi(k,n)是第k(1≤k≤K)個頻率點、第n(1≤n≤N)幀在短時傅里葉變換(short-time Fourier transform,STFT)域的頻譜特征,K表示語音樣本頻率點的個數,N表示語音樣本的總幀數。注意,本文語音樣本STFT的點數為4 096個,由于STFT輸出的對稱性,所以K的值為2 049(4 096/2+1)個,N隨著語音長度的變化而變化。k、n、K和N的定義也適用于其他式子。

圖4 操作系統升級后手機的語譜
算法1 背景噪聲計算
輸入 靜音段語譜|NS(k,n)|,本底噪聲的頻譜|SNmean(k)|
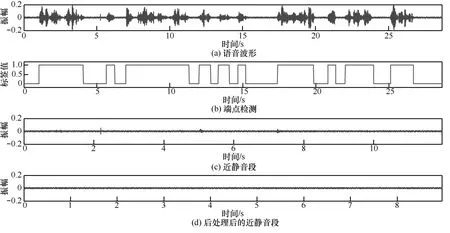
圖5 基于端點檢測的靜音段估計
輸出 背景噪聲語譜|BN(k,n)|
參數:比例因子α1=3,增益補償因子β1=0.1
if|NS(k,n)|>α1×|SNmean(k)|
|BN(k,n)|=|NS(k,n)|-α1×|SNmean(k)|;
else|BN(k,n)|=β1×|NS(k,n)|;
end
因此,未知來源手機的本底噪聲可以通過靜音段信號減去通用背景噪聲得到。為了使估計的本底噪聲不含殘余的背景噪聲,設計了一個濾波方案。本底噪聲估計的完整過程的偽代碼如算法2所示。
算法2 本底噪聲估計
輸入 靜音段語譜圖|NS(k,n)|,背景噪聲的頻譜|BNmean(k)|
第一步的輸出:估計本底噪聲的語譜|SNestimated(k)|
第二步輸出:估計的本底噪聲濾波輸出|SNfilter(k)|
參數:比例因子α2=3,φ=3,ω=1,增益補償因子β2=0.9
功能:median(·)計算每一個頻率區間沿時間軸的中值
ifft(·)逆快速傅里葉變換重構時域信號
第一步:if|NS(k,n)|>α2×|BNmean(k)|
|SNestimated(k,n)|=|NS(k,n)|-α2×|BNmean(k)|;
else|SNestimated(k,n)|=β2×|NS(k,n)|;
end
第二步:SNmedian(k)=median(|SNestimated(k,n)|);
if|NS(k,n)|≥φ×|SNmedian(k)|
|SNfilter(k,n)|=ω×SNmedian(k);
else|SNfilter(k,n)|=|SNestimated(k,n)|;
end
|SNfilter(n)|=ifft(|SNestimated(k,n)|)
圖6展示了iPhone 6的實際本底噪聲語譜和它的估計本底噪聲的語譜。對比圖3(c)和圖6(b)可以看出,iPhone 6估計的本底噪聲語譜與實際的本底噪聲語譜是最相似的,圖6(c)也表明了估計本底噪聲與實際本底噪聲的頻譜是很相似的。因此,本文所提出的兩步實現對未知來源手機語音的本底噪聲估計的方法是可行的。

圖6 估計本底噪聲和實際本底噪聲的對比
3.2 特征提取和識別過程
為了實現手機的來源識別,需要選擇不同型號的手機之間具有差異性的本底噪聲特征。本文選取本底噪聲的頻譜分布特征作為分類特征,如式(3)所示:

特征的構建過程表述如下:首先求出本底噪聲的頻譜特征SNi(k,n),然后對頻譜特征SNi(k,n)取對數,最后沿時間軸按幀取平均,作為一個樣本的特征。
正如第3.1節提到的每幀的特征維度是2 049,由于特征維數太大,可能導致特征不能完全獨立不相關。冗余的特征不僅不能提升識別的準確率,甚至會影響特征向量的識別效果。而PCA(principal component analysis,主成分分析)是一種常用的數據分析方法[18,19],通過線性變換將原始數據變換為一組各維度線性無關的數據,可用于提取數據的主要特征分量,常用于高維數據的降維。因此利用PCA進行降維,形成最優的頻譜分布特征空間。識別采用PCA降維和MATLAB自帶的SVM(support vector machine,支持向量機)函數訓練分類,SVM是一種二類分類模型,其基本模型定義為特征空間上的間隔最大的線性分類器,其學習策略是間隔最大化,最終可轉化為凸二次規劃問題的求解。本文所采用的 SVM函數使用的是 RBF(radial basis function,徑向基函數核函數)。實驗中,對兩個關鍵參數懲罰系數(C)和Gamma函數(γ)進行尋優處理。識別過程的步驟為:先將第4.1節所述的測試語音庫中一半樣本用于模型訓練,另一半用于測試。訓練集和測試集樣本按第3.1節所述進行本底噪聲估計,然后進行頻譜分布特征提取,將各自所得的頻譜分布特征分別構造特征空間。再利用PCA對訓練特征空間進行降維,將降維后的特征空間歸一化處理,測試集的特征空間根據訓練集特征空間降維所采用的映射矩陣進行降維,對降維后的測試特征空間進行歸一化處理。最后對降維后訓練特征空間進行模型訓練,對測試特征空間逐行進行SVM分類判別。
4 實驗分析
4.1 實驗設置
在實驗中,建立了一個語音數據庫來有效評估提出方法的有效性。該數據庫由表1所示的24個型號的手機所采集的語音組成。邀請了12人(6男6女)參與語音采集。每個人需要錄制兩段語音,一段為用正常的語速朗讀固定的內容,另一段為問答和主題演講,時長均保證5 min以上。錄音環境是一間相對安靜的辦公室,25個手機由工作人員同時打開和關閉錄音機,保證錄制較好的同步性。每個手機采集了24段語音,對每段語音取中間固定的長度進行分割,將每段語音分割成5 s的語音片段,每個手機得到1 200個語音樣本,作為原始語音庫。對原始語音進行靜音段估計提取,得到靜音段數據庫。由于靜音段語音長度不一致。為了保證在構建特征空間時特征矩陣長度保持一致,選取每個型號手機240個語音幀數大于40幀的靜音段語音,組成求取本底噪聲頻譜分布特征的測試語音庫。對測試語音庫中所有語音進行通用背景噪聲模型訓練,然后采用改進的譜減法得到估計本底噪聲的語音庫。構造特征空間時,取每段語音的前40幀本底噪聲頻譜分布特征的平均值。此處幀長為64 ms,幀移為32 ms。按照第3.2節所述,進行基于本底噪聲的頻譜分布特征的手機設備來源識別實驗。
4.2 實驗結果與分析
引入平均識別準確率Accuracy和召回率Recal作為客觀指標評價分類特征的識別性能,如式(4)、式(5)所示:
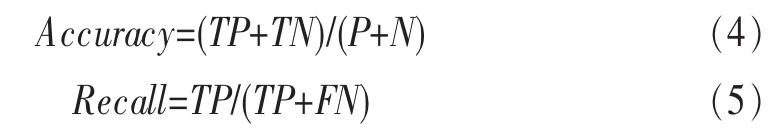
其中,TP為正樣本預測為正樣本的個數,TN為負樣本預測為負樣本的數目,FN為正樣本預測為負樣本的數目,P為正樣本實際數,N為負樣本實際數,P=TP+FN,式(5)可表示為Recall=TP/P。在實驗中,24類手機來源識別的平均召回率為((TP1+TP2+,…,+TP24)/P)/24=(TP1+TP2+,…,+TP24)/ 24P,由于(TP1+TP2+,…,+TP24)=TP+TN,24P=P+N,則平均召回率即平均識別準確率。
表2給出了降維后特征為28維、參數C和γ分別為30和0.001時,24個手機的識別結果,從中可算得平均識別準確率為99.24%,算法可以較好地完成24個手機的分類識別,iPhone 6識別率為91.67%,其主要誤判來自品牌類內區分,將之誤判為iPhone 4s和iPhone 5s。除iPhone 6以外,其他手機都有較高的識別準確率,其中有18個手機的識別率達到100%,三星、OPPO、魅族等品牌可以做到無差錯分類。
4.3 系統升級后實驗結果與分析
對3臺操作系統升級后的手機按第 4.1節的實驗設置進行語音錄制和語音處理,每個手機得到1 200個語音樣本,將其作為原始語音。對原始語音按照試驗設置進行后續操作,每個設備取100個幀長大于40幀的估計本底噪聲的語音片段構成測試語音庫,對該測試語音庫中的語音樣本進行頻譜分布特征提取,然后以升級后的測試樣本代替升級前3臺手機的測試樣本,以每個設備100個測試樣本在系統升級前的24臺設備的訓練模型上進行檢測。
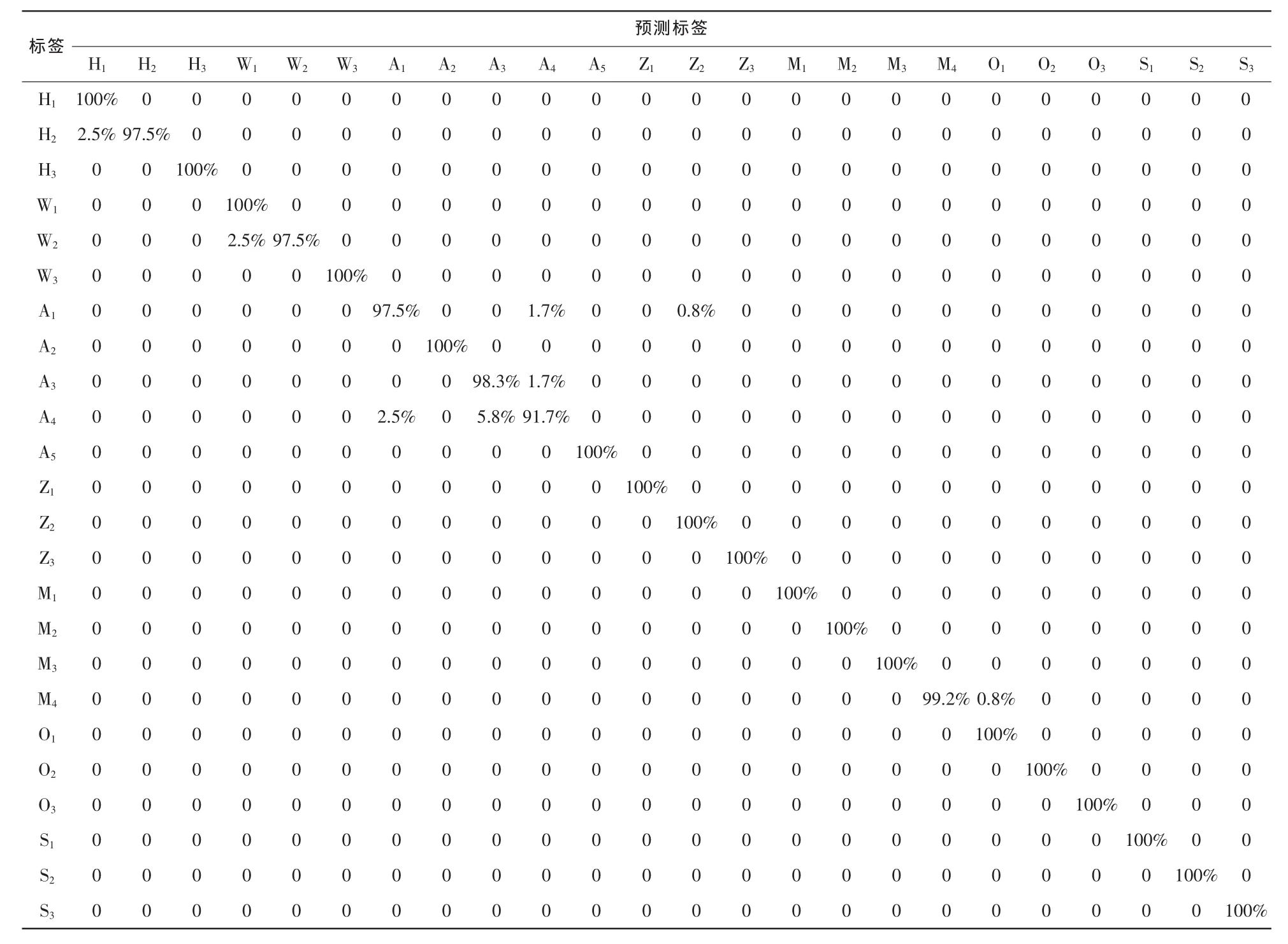
表2 本底噪聲頻譜分布特征的識別率
表3是HTC D610t、iPhone 5和Mi 4操作系統升級后的識別結果(實驗中特征為28維、參數C和γ分別為 30和0.001),平均識別率為98.04%。從表3中可以看出, HTC D610t、iPhone 5和Mi 4這3臺設備的識別準確率依次是97%、97%和99%。因此可以得出,手機操作系統版本的升級對手機本底噪聲的影響較小,實驗結果也驗證了第 2.2節中圖 2和圖 4對應 HTC D610t、iPhone 5和Mi 4手機系統升級前后本底噪聲語譜沒有明顯變化的結論。
4.4 Hanilci[6]實驗結果與分析
為了綜合評價所提出的方法,對參考文獻[6]中提出的基于MFCC特征的手機來源識別算法在原始語音數據庫上進行了測試。訓練和測試樣本數目與實驗所用數目一致。在該工作中將 12維的 MFCC特征和基于幀間的MFCC一階差分系數36維作為區分特征。對特征沿時間軸做平均,每個樣本得到48維的特征。表4為實驗結果,SVM中的參數C和γ分別為7和0.004。
從表4可知,與本文所提特征相比,部分手機的識別準確率嚴重下降,如HTC D820t、iPhone 4s、魅族Meilan Note、紅米Note 2、OPPO find 7、三星Galaxy Note 2等,尤其是HTC D610t識別率已經降到50%。不過24臺設備中有15臺的識別正確率超過90%,平均識別率為88.23%。本文所提方法的平均識別率優于Hanilci所提算法,其原因是本文所提取的本底噪聲是手機本身的特征,而Hanilci所提特征是基于語音信號的,所含的說話人信息可能對分類產生干擾。
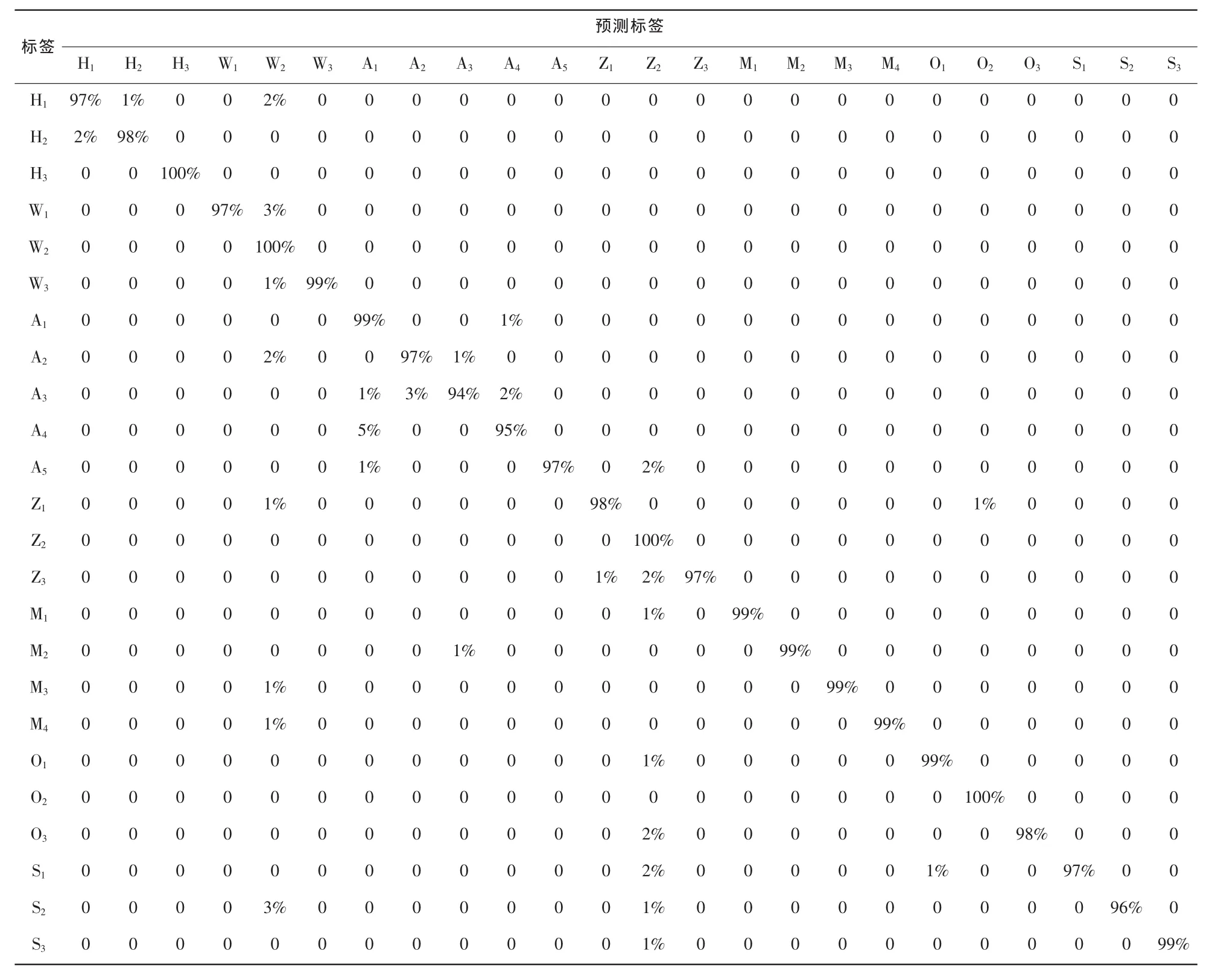
表3 操作系統版本升級后本底噪聲頻譜分布特征識別率
從上述實驗結果分析,手機的本底噪聲可以作為手機的“指紋”很好地進行手機來源識別。在手機來源識別的語音取證領域,手機的本底噪聲特征是一個具有區分性的特征。
5 結束語
本文提出了一種新的手機來源識別方法,將本底噪聲作為手機的“指紋”進行手機來源識別。由于本底噪聲主要取決于手機本身的電路設計和電子元器件的不同,因此以本底噪聲作為手機來源識別的區分特征是可行的。實驗結果驗證了所提出的本底噪聲可以作為手機來源識別的特征。而且,較MFCC特征,基于本底噪聲頻譜分布特征的分類識別效果更好。
然而,本文的方法是應用本底噪聲做手機來源識別的初步研究,仍有許多局限性。如估計本底噪聲的步驟是:先通過錄音自適應端點檢測處理得到靜音段,然后利用改進的譜減法減去背景噪聲得到的。所以,能否準確地估計本底噪聲,背景噪聲很關鍵。在實際情況中,不同錄音環境的背景噪聲是不同的,會影響本底噪聲估計的準確性。因此,本底噪聲的估計是一項具有挑戰性的工作。而綜合基準數據庫的建立是一項費力的工作,將之作為長遠目標堅定地研究下去。
[1]楊銳,駱偉祺,黃繼武.多媒體取證[J].中國科學:信息科學, 2013,43(12):1654-1672. YANG R,LUO W Q,HUANG J W.Multimedia forensics[J]. Science China:Information Science,2013,43(12):1654-1672.
[2]GUPTA S,CHO S,KUO C,et al.Current developments and future trends in audio authentication [J].IEEE Multimedia, 2012,19(1):50-59.
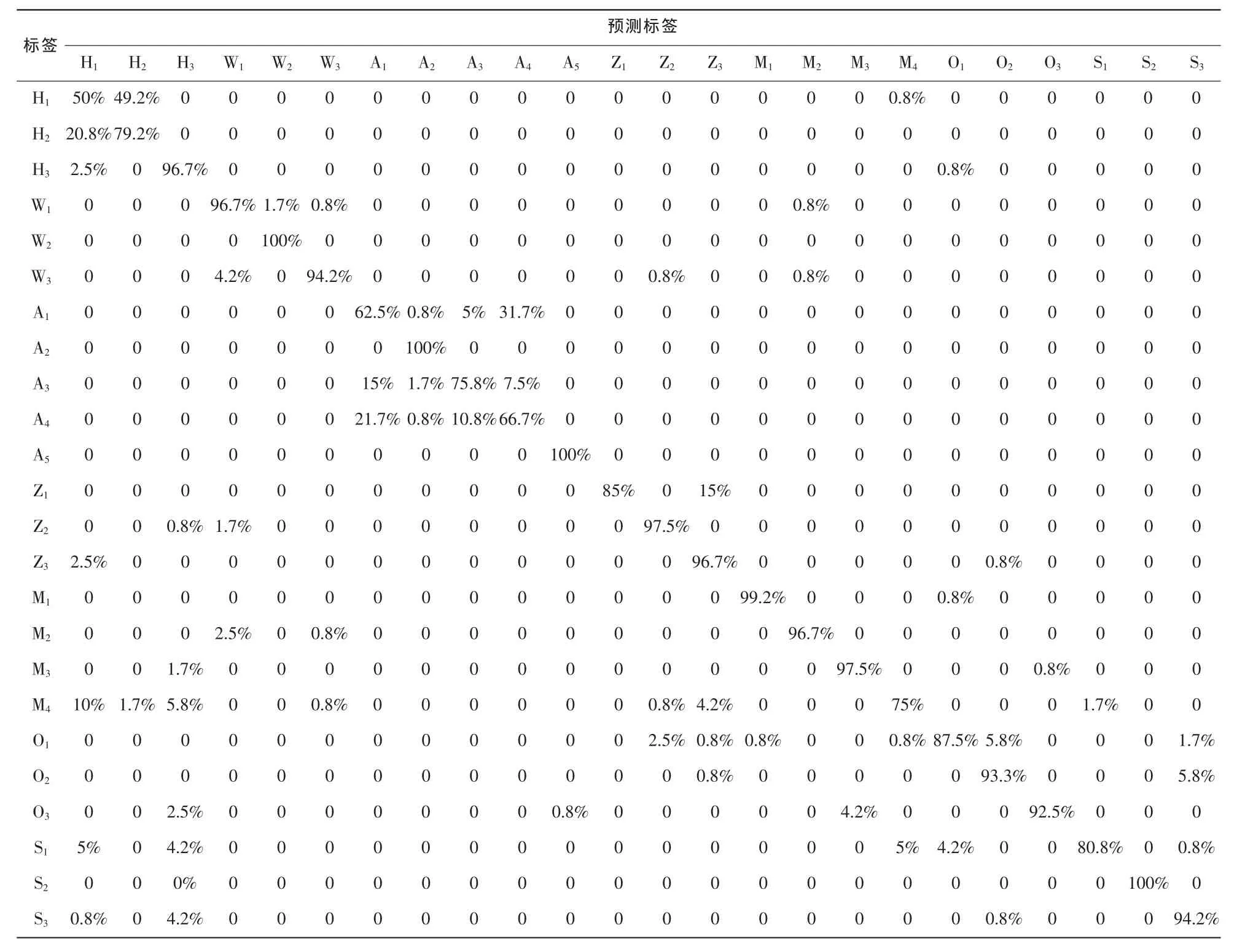
表4 Hanilci特征的識別率
[3]BAO Y,LIANG R.Research progress on key technologies of audio forensics[J].Journal of Data Acquisition&Processing, 2016,31(2):252-259.
[4]王昌海,張建忠,徐敬東,等.基于 HMM的動作識別結果可信度計算方法[J].通信學報,2016,37(5):143-151. WANG C H,ZHANG J Z,XU J D,et al.Identifying the confidence level of activity recognition via HMM[J].Journal on Communications,2016,37(5):143-151.
[5]賀前華,王志鋒,RUDNICKYA I,等.基于改進PNCC特征和兩步區分性訓練的錄音設備識別方法 [J].電子學報,2014, 42(1):191-198. HE Q H,WANG Z F,RUDNICKYA I,et al.A recording device identification algorithm based on improved PNCC feature and two-step discriminative training[J].Acta Electronica Sinica, 2014,42(1):191-198.
[6]HANILCI C,ERTAS F,ERTAS T,et al.Recognition of brand and models of cell-phones from recorded speech signals[J]. IEEE Transactions on Information Forensics&Security,2012,7(2): 625-634.
[7]HANILCI C,CEMAL I,ERTAS F.Optimizing acoustic features for source cell-phone recognition using speech signals[C]//ACM Workshop on Information Hiding and Multimedia Security,June 20-22,2013,Montpellier,France.New York:ACM Press,2013: 141-148.
[8]JAHANIRAD M,WAHAB A W A,ANUAR N B,et al.Blind source mobile device identification based on recorded call[J].Engineering Applications of Artificial Intelligence,2014(36):320-331.
[9]PANAGAKISY,KOTROPOULOSC.Automatictelephone handsetidentification by sparse representation ofrandom spectral features[C]//MM&Sec’12,September 6-7,2012,Coventry, UK.New York:ACM Press,2012:91-96.
[10]PANAGAKIS Y,KOTROPOULOS C.Telephone handset identification by feature selection and sparserepresentations[C]// IEEE International Workshop on Information Forensics and Security,December 2-5,2012,Costa,CA,USA.New Jersey: IEEE Press,2012:73-78.
[11]KOTROPOULOS C L.Source phone identification using sketches of features[J].Biometrics IET,2014,3(2):75-83.
[12]王志鋒,賀前華,李艷雄.錄音設備的建模和識別算法[J].信號處理,2013(4):419-428. WANG Z F,H Q H,LI Y X.A modeling and identification algorithm of recording devices[J].Journal of Signal Processing, 2013(4):419-428.
[13]鄒領,賀前華,鄺細超,等.基于設備噪聲估計的錄音設備源識別[J].吉林大學學報(工學版),2016:1-8. ZOU L,HE Q H,KUANG X C,et al.Source recording device recognition based on device noise estimation[J].Journal of Jilin University(Engineering and Technology Edition),2016:1-8.
[14]AGGARWAL R,SINGH S,ROUL A K,et al.Cellphone identification using noise estimates from recorded audio[C]// IEEE International Conference on Communications and Signal Processing (ICCSP),April 3-5,2013,Melmaruvathur,India. New Jersey:IEEE Press,2014:1218-1222.
[15]ZHAO H,MALIK H.Audio recording location identification using acoustic environment signature[J].IEEE Transactions on Information Forensics&Security,2013,8(11):1746-1759.
[16]LUKAS J,FRIDRICH J,GOLJAN M.Digitalcamera identification from sensor pattern noise[J].IEEE Transactions on Information Forensics&Security,2006,1(2):205-214.
[17]KINNUNEN T,RAJAN P.A practical,self-adaptive voice activity detector for speaker verification with noisy telephone and microphone data [C]//IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP),May 26-30, 2013,Vancouver,BC,Canada.New Jersey:IEEE Press,2013: 7229-7233.
[18]MALHI A,GAO R X.PCA-based feature selection scheme for machine defect classification [J].IEEE Transactions on Instrumentation and Measurement,2004,53(6):1517-1525.
[19]LU Y,COHEN I,ZHOU X S,et al.Feature selection using principal feature analysis [C]//The 15th ACM International Conference on Multimedia,September 27-29,2007,Baltimore, MD,USA.New York:ACM Press,2007:301-304.
Cell-phone origin identification based on spectral features of device self-noise
PEI Anshan,WANG Rangding,YAN Diqun
Ningbo University,Ningbo 315211,China
With the widespread availability of cell-phone recording devices and the availability of various powerful and easy-to-use digital media editing software,source cell-phone identification has become a hot topic in multimedia forensics.A novel cell-phone identification method was proposed based on the recorded speech.Firstly,device self-noise(DSN)was considered as the fingerprint of the cell-phone and estimated from the silent segments of the speech.Then,the mean of the noise’s spectrum was extracted as the identification.Principal components analysis (PCA)was applied to reduce the feature dimension.Support vector machine(SVM)was adopted as the classifier to determine the source of the detecting speech.Twenty-four popular models of the cell-phones were evaluated in the experiment.The experimental results show that the average identification accuracy and recall of the method can reach up to 99.24%and demonstrate that the self-noise feature has more superior performance than the MFCC feature.
multimedia forensics,cell-phone origin identification,self-noise,spectral feature
TP391
A
10.11959/j.issn.1000-0801.2017019

裴安山(1992-),男,寧波大學信息科學與工程學院碩士生,主要研究方向為多媒體通信、信息安全、移動終端來源檢測等。

王讓定(1962-),男,博士,寧波大學高等技術研究院教授,主要研究方向為多媒體通信與取證、信息隱藏與隱寫分析、智能抄表及傳感網絡技術等。

嚴迪群(1979-),男,博士,寧波大學信息科學與工程學院副教授,主要研究方向為多媒體通信、信息安全、基于深度學習的數字語音取證等。
2016-12-11;
2017-01-10
王讓定,wangrangding@nbu.edu.cn
國家自然科學基金資助項目(No.61672302,No.61300055);浙江省自然科學基金資助項目(No.LZ15F020002,No.LY17F020010);寧波大學科研基金資助項目(No.XKXL1405,No.XKXL1420,No.XKXL1509,No.XKXL1503);寧波大學科研創新基金資助項目(No.G16079);寧波大學王寬誠幸福基金資助項目
Foundation Items:The National Natural Science Foundation of China (No.61672302,No.61300055),Natural Science Foundation of Zhejiang Province of China (No.LZ15F020002,No.LY17F020010),Scientific Research Foundation of Ningbo University(No.XKXL1405,No.XKXL1420, No.XKXL1509,No.XKXL1503),Scientific Research Foundation of Graduate School of Ningbo University(No.G16079),K.C.Wong Magna Fund in Ningbo University
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
