基于擴充詞匯鏈改進的關鍵詞提取算法
2017-05-15 00:38:00王小林邰偉鵬
蘇州科技大學學報(自然科學版) 2017年2期
關鍵詞:提取
王小林,朱 磊,邰偉鵬
(安徽工業大學 計算機科學與技術學院,安徽 馬鞍山 243002)
基于擴充詞匯鏈改進的關鍵詞提取算法
王小林,朱 磊,邰偉鵬
(安徽工業大學 計算機科學與技術學院,安徽 馬鞍山 243002)
的準確提取在文本分類、文本聚類、信息檢索等方面起著重要作用。現有的基于詞匯鏈的關鍵詞提取方法在計算詞語相似度時,賦予第一類獨立義原系數的值最大并且通過第一類獨立義原相似度約束其他三類義原相似度;通過區域特征和詞頻提取關鍵詞時,詞語的權重依賴詞匯鏈的長度,不能充分利用區域特征等問題。為了提高關鍵詞的提取準確率,計算詞語相似度時,用對比的兩個詞語每類義原個數的和與四類義原個數總和的比值大小排序后動態的獲取系數取代固定系數,并且去除每類義原受到前面所有義原類的約束;提取關鍵詞時,用詞匯鏈的有效權重替代詞匯鏈的長度。實驗結果表明:改進后的算法較傳統的算法提高了準確率。
關鍵詞提取;區域特征;詞語相似度;有效權重;詞匯鏈;義原
信息時代不斷的發展,信息內容呈現的方式成多樣化,但是以文本呈現信息內容的方式依舊不可取代。隨著網絡上文本數據的不斷增長,如果還靠人工去獲取所需文本信息,那么將會耗費太多的時間和精力,如何提高文本信息的獲取效率變得尤為突出。在對海量的文本數據進行處理時,研究人員從文本分類、文本聚類、信息檢索等方面進行了大量的研究,發現了一個非常關鍵的問題,就是如何從文本中獲取能簡約概括文本信息的關鍵詞。關鍵詞能夠具體的概括出文本所要表達的信息,使讀者不必查看文本就能知道該文本是不是自己所需要的。而且,通過計算文本關鍵詞的相關性度量[1],就能很快的對文本進行分類、聚類,因此,可以提高文本分類、聚類的效率。在信息檢索方面,關鍵詞的作用顯得尤為突出,用戶在搜索引擎中輸入關鍵詞,搜索引擎會向用戶給出那些包含關鍵詞的文章。國外對關鍵詞研究的比較早,已經建立了一些實用和試驗系統。Witten[2]采用樸素貝葉斯技術對短語離散的特征值進行訓練,獲取模型的權值,以完成下一步從文檔中抽取關鍵短語的任務。Turney[3]設計的GenEx系統將遺傳算法和C4.5決策樹機器學習方法用于關鍵短語的抽取。
由于漢語本身沒有詞語邊界這一特點,給關鍵詞提取增加了一些難度。文獻[4]提出了最大熵模型,當前關鍵詞候選集合中的每一項都在一定程度上反映了文章的內容,因此,要計算每一候選項反應主題內容的程度大小,最大熵模型就是計算這個程度大小以獲取關鍵詞的基礎,但是由于特征選取以及特征參數的估計不夠準確,因此,在關鍵詞自動標引中并不是太理想。文獻[5]的關鍵詞提取方法中,關鍵詞的權重依賴于插值系數,由于插值系數受訓練集影響太大,因此,結果不太理想。文獻[6]提出的關鍵詞算法,通過計算語義距離,不僅計算量大而且計算復雜,最后還要自定義一個閾值去提取關鍵詞,閾值的高與低影響著提取的準確率,因此,局限性很大。文獻[7]的關鍵詞提取算法中所用到的詞語相似度算法,給予第一獨立義原最大系數,并且讓第一獨立義原約束其他義原,但是第一獨立義原對詞語只是一個大概的描述,起不到區分詞語的作用,且由于原有的算法過于依賴詞頻,造成部分詞頻不是很高的,卻是非常關鍵的詞語,未能被標引出來。
文中正是針對文獻[7]方法中出現不足提出的基于擴充詞匯鏈[8]改進的關鍵詞提取方法,該方法在計算詞語相似度時,用對比的兩個詞語每類義原個數的和與四類義原個數的總和的比值取代固定系數,去除第一類義原約束,提取關鍵詞時,用詞匯鏈的有效權重替代詞匯鏈的長度。通過實驗該方法在準確率和召回率上有所提高。
1 詞語相似度算法及改進算法
1.1 詞語相似度算法[9]
《知網》是一個以漢語和英語的詞語所代表的概念為描述對象,以揭示概念與概念之間以及概念所具有的屬性之間的關系為基本內容的常識知識庫。《知網》中含有豐富的詞匯語義知識和世界知識。在《知網》中有兩個主要的概念:“概念”與“義原”。“概念”是對詞匯語義的一種描述,每一個詞可以表達為幾個概念。“概念”是用一種“知識表示語言”來描述的,這種“知識表示語言”所用的詞匯叫做“義原”。“義原”是用于描述一個“概念”的最小意義單位。每個義原類別都是一個樹狀結構。文獻[7]計算詞語相似度的方法:對于兩個漢語詞語W1和W2,如果W1有n個義項(概念)S11,S12,…,S1n,W2有m個義項(概念)S21,S22,…,S2m,規定W1和W2之間的相似度是各個義項的相似度最大值,即

其中Sim(W1,W2)表示兩個詞語的相似度,Sim(S1i,S2j)表示兩個詞語中義項的相似度,這樣就把兩個詞語的相似度計算歸結到兩個詞語中義項的相似度計算上。由于義項由一系列義原構成,這樣就把義項的相似度計算歸結到義原相似度計算上。所有的義原根據上下位關系構成了一個樹狀的義原層次體系,通過語義距離計算相似度的辦法來計算義原的相似度,即

其中P1,和P2表示兩個義原,d表示兩個義原在義原樹上的距離,α為一個可調節的參數。
參照《知網》對實詞義原的分析及分類,可以把實詞的義原分為四類:第一獨立義原描述式,將兩個義項的這一部分的相似度記為 Sim1(P1,P2);其他獨立義原描述式,將兩個義項的這一部分的相似度記為Sim2(P1,P2);關系義原描述式,將兩個義項的這一部分的相似度記為Sim3(P1,P2);符號義原描述式,將兩個義項的這一部分的相似度記為Sim4(P1,P2)。
于是,兩個概念語義表達式的整體相似度記為

其中βi是可調節參數(1≤i≤4),且β1+β2+β3+β4=1,由于第一獨立義原反映了整個義項的主特征,所以第一獨立義原的系數β1一般大于等于0.5。
1.2 改進的詞語相似度算法
筆者認為,第一獨立義原是對義項做了基礎的解釋,其表述該義項[9]所屬的范疇,但是并不能闡述出義項的特征。隨著對義項解釋的不斷深入,第一獨立義原對整個義項的影響越來越低,并且與義原樹的根結點的距離都比較近。因此,給四類義原分配固定的系數是不合適的。例如對“教師”的描述:
DEF=human|人,#occupation|職位,*teach|教,education|教育
由上述DEF可知,首先,教師是屬于“人”的范疇,并且與“職位”相關,是給其他同屬于“人”這個范疇的對象實施“教”的,最后還和“教育”有關。隨著解釋的慢慢深入,把教師這個詞語的特征慢慢的表露出來。與第一獨立義原相比,后面三個義原就成為“教師”區別于其他同屬“人”這個范疇的關鍵性因素。如果此時還是給予第一獨立義原最大系數的話,那么后面“#occupation|職位,*teach|教,education|教育”這三個義原所屬的義原類就不能獲得較大的系數,使得這些能突顯教師特征的義原類的相似度值很小,使得教師與其他“人”這個范疇的實體無法區分開來。另一方面,《知網》要求第一獨立義原能夠最大的體現出這個義項的含義,但是有些往往與人們的主觀意識不相符,比如“鉆石”的描述:
DEF=material|材料,?tool|用具,#decorate|裝飾,precious|珍
鉆石給人的第一印象就是一種珍貴的飾品,但是《知網》給出的第一獨立義原卻是“材料”,和人們平常的認知有很大的出處,反而“precious|珍”更加的符合人們平常的認知。
去除義原之間的約束,改進的義項相似度計算公式為

其中βi={0.4,0.3,0.2,0.1},每類義原系數βi的值是根據兩個義項每類義原個數總和占四類義原比值,然后根據比值從高到低的排序從βi={0.4,0.3,0.2,0.1}中獲取相對應的值。對于一些特殊情況做出如下規定:如果四類義原占比一樣,那么默認給予第一獨立義原最大系數值,其他三類義原隨機獲取;如果出現某一個義項某類義原沒有,那么當其他類義原獲取完系數后,把最后那個系數平均到其他三類義原系數上;如果只有第一類獨立義原那么系數βi的值就為1。
2 擴充詞匯鏈的構建以及文本關鍵詞選擇方法
2.1 擴充詞匯鏈的構建
文中詞匯鏈的構建方法是在文獻[7]的基礎上進行了擴充。原方法中只提取了名詞作為備選關鍵詞,筆者覺得不太合理,因為有些詞語既是名詞也是動詞,在很多文本內容中充當著關鍵詞的角色,所以文中采用名詞和動詞作為關鍵詞的備選關鍵詞。
詞匯鏈構建的具體方法是:從備選關鍵詞中,選出一個詞,建立一個詞匯鏈,然后從集合中提取出一個詞與詞匯鏈中每個詞作對比,相似度大于或等于閾值就插入到詞匯鏈中,小于閾值的就以該詞語新建一條詞匯鏈,往復循環,直到集合中的詞語插入完為止。
2.2 文本關鍵詞選擇方法
文章不同的區域具有不同的功能,某些區域的詞語具有特殊的價值,是選擇關鍵詞的重要區域。文獻[7]提出如下關鍵詞選擇方法
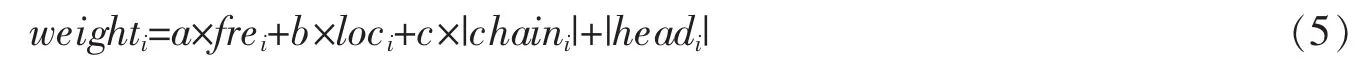
其中,weighti表示第i個詞語的權值;frei表示第i個詞語的詞頻因子;loci表示第i個詞語的區域因子,一般地,當詞語i出現在標題中時,loci=5,否則loci=1;|chaini|表示第i個詞語所在詞匯鏈的詞匯數目(詞匯鏈長度);|headi|表示第i個詞語所在詞匯鏈中包含標題詞的數目。a、b、c是frei、loci、|chaini|之間的調節因子,一般為1。
根據公式(5)計算出每個詞語的權重,按照遞減排序,最后從詞匯鏈中依次選取關鍵詞匯,直至關鍵詞匯的數目達到要求為止。
2.3 改進的文本關鍵詞選擇方法
一篇文章中每個區域都有自己的職能,比如摘要是對文章的精煉,關鍵詞表達文章的主題,結論是對文章的總結。文獻[10]統計表明從標題和摘要中提取關鍵詞,則可達到人工標引的74.68%,所以該文關鍵詞提取方法中每個詞語的權重更傾向于通過累加詞匯鏈中那些存在于標題、關鍵詞、摘要、結論中的詞語的個數與自身權重的積得到。在處理詞匯鏈長度時,只獲取出現在特征區域詞語的數目,忽略那些非特征區域的詞語,因此,提出了有效權重,有效權重就是為了防止詞匯鏈中沒有特征區域的詞語,但是通過加上詞匯鏈的長度,增加了自身的權重,對最后的關鍵詞提取造成偏差,所以文中的方法會對標題、摘要、關鍵詞、結論這四處區域的詞語增加它們的權重,如公式
weighti=frei+loci+0.4×(|headi|×5+(|abstracti|+|keywordi|+|conclusioni|)×3)+|effectiveChaini| (6)其中,weighti表示第i個詞語的權重,frei表示詞語i的頻率;loci表示的是位置權重,一般地,在標題處loci=5,在摘要、關鍵詞、結論處loci=3,其他處則為1;headi、abstracti、keywordi、conclusioni分別表示詞語i所在詞匯鏈中出現在標題、摘要、關鍵詞和結論處的個數;0.4是構建詞匯鏈時的閾值;|headi|×5+(|abstracti|+ |keywordi|+|conclusioni|)×3表示詞語i所在的詞匯鏈中出現在標題、摘要、關鍵詞、結論處詞語的個數與其權重積的和。|effectiveChaini|為有效權重,是該詞匯鏈包含標題、摘要、關鍵詞、結論處詞語的個數。根據公式(6)計算出每個詞語的權重,然后按照遞減排序。從詞匯鏈中選取詞匯,直到達到要求的關鍵詞個數為止。
3 結果與分析
3.1 詞語相似度改進算法的結果與分析
因為文獻[7]采用的就是文獻[11]的詞語相似度算法,為了便于對比結果,所以直接從文獻[11]選取一些實驗結果,第三列為文獻[11]中的實驗結果,第四列為公式(4)的實驗結果。其對比結果見表1。

表1 文獻[11]與公式(4)詞語相似度對比結果
男人的描述:DEF=human|人,family|家,male|男
母親的描述:DEF=human|人,family|家,female|女
從“男人”和“母親”的描述可以看出,這兩個詞語的唯一區別來自于第二類義原中的“male|男”和“female|女”,由于它們的第一獨立義原相同,根據文獻[7]的算法,第一類義原具有最大系數而且還約束其他義原,這就造成了相似度值相當的高,達到了0.833,與實際不符。
深紅的描述:DEF=atribute|屬性,color|顏色,red|紅,&physical|物質
粉紅的描述:DEF=aValue|屬性值,color|顏色,red|紅
從第七行結果看出根據文獻[7]中方法“深紅”和“粉紅”相似度很小。因為這兩個詞語的第一類獨立義原完全不相同,造成第一類獨立義原相似度很低,而且還讓第一類義原約束其他類義原,這就是造成這兩個詞相似度低的原因。反觀根據文中算法得到的結果0.466,因為是根據每類義原在兩個詞語中占得比例來分配系數的值,也不讓第一類義原去約束其他義原,所以文中的詞語相似度算法更符合實際。第十二行中的詞語“走”和“跑”每個義項都只有第一類獨立義原,因此,第一獨立義原就能充分說明該義項的特征。由于沒有其他類義原,那么再給予其他類義原系數就沒有意義。文獻[7]的方法缺少對只有第一類獨立義原的考慮,結果為0.222,與實際不太相符。文中方法得到的結果0.444,相較于文獻[7]方法的結果提高了一倍,因此,用對比的兩個詞語每類義原個數的和與四類義原個數的總和的比值替代固定系數,結果更加貼近實際。
3.2 改進的文本關鍵詞提取方法的結果與分析
以《體育科學》中一篇名為《廣東省高校高級知識分子體育參與特征研究》為例。分詞工具使用的是中科院計算機研究所的ICTCLAS,該分詞系統具有中文分詞、詞性標注等功能。
對文章分詞后,動詞和名詞總共352個,為降低計算時的復雜度以及提高計算的速率,以1∶2的比例挑選出現頻率最高的前20個詞語作為候選詞進一步處理。先根據文獻[11]中的公式(3),閾值設置為0.3得到的詞匯鏈,再根據公式(5)提取的關鍵詞為:體育、知識分子、活動、高校、年齡、選擇、研究、特征、消費、人口。
根據文中的詞語相似度算法公式(4),閾值設置為0.4,構建詞匯鏈,再根據公式(6)提取的關鍵詞為:體育、知識分子、活動、年齡、高校、選擇、研究、進行、特征、參與。具體結果見表2。

表2 提取的關鍵詞的頻率與權重
從文章的題目可以得出該篇文章講的是對廣東省高校的高級知識分子參與體育活動特征的研究,從文獻[7]算法提取出來的關鍵詞中,只能得到:高校、知識分子、體育活動、特征、研究。但是從文中改進的算法中可以得到:高校、知識分子、參與、體育、活動、特征、研究,明顯與標題的語義關系更加貼近。再看通過文中方法提取關鍵詞結果的最后一行,“參與”為關鍵詞但是其詞語的頻率只為9,文中方法把詞頻低但卻是關鍵詞的詞語提取出來,較原文的方法好了很多。
按照上述過程,從復旦大學語料庫提取經濟、教育、體育、環境、科技各20篇文獻,從每類中選取10篇作為訓練集,用來確定構建詞匯鏈時的閾值s。把s設置為0.3、0.4、0.5、0.6、0.7分別統計獲得的詞匯鏈數目,再根據關鍵詞提取的召回率,確定最佳的相似度閾值為0.4。
為了驗證文中算法的有效性,將剩下的經濟、教育、體育、環境、科技50篇文獻按照方法2.2與方法2.3進行對比實驗。利用準確率和召回率來評定自動提取關鍵詞的結果,公式為

表3列出了文獻[7]的詞匯鏈提取關鍵詞算法和文中改進的詞匯鏈提取關鍵詞算法的結果對比。
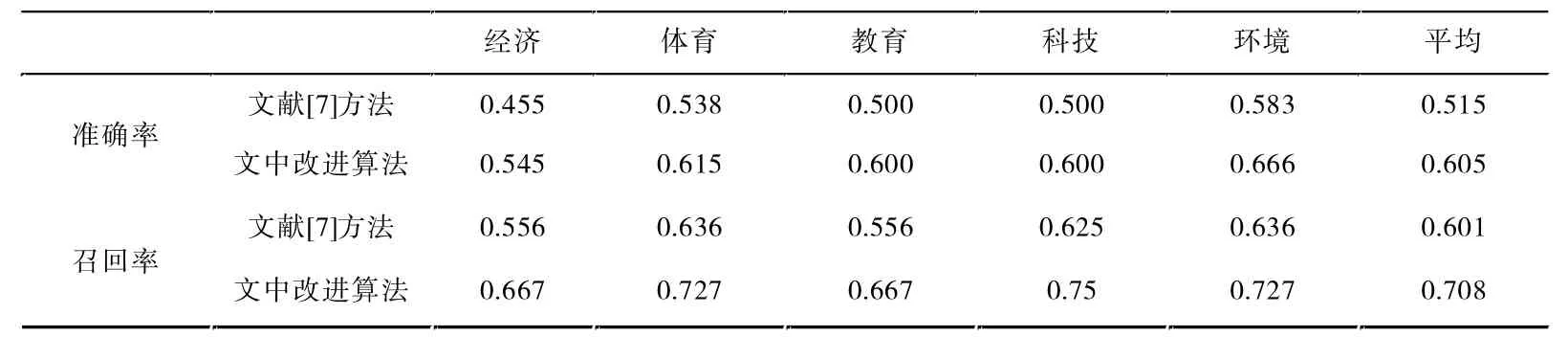
表3 關鍵詞提取結果對比
從表3中可以看出,文中改進的算法較文獻[7]中的算法在召回率上有9%提升,在準確率上有10.7%的提升。進一步,通過對文獻的分析,發現基于擴充詞匯鏈改進的關鍵詞提取算法存在的問題有以下幾個方面:分詞方面受到分詞系統ICTCLAS影響較大,ICTCLAS把“中美”切分成“中/b”、“美/b”,顯然拆分后的詞語不是關鍵詞,但是手動標引“中美”卻是關鍵詞。這個問題在所有利用分詞系統的方法中都會存在,因此,要解決此問題,必須提高分詞系統的新詞與未登錄詞的識別能力。
詞語相似度的閾值設置對詞匯鏈的構建影響較大。構建詞匯鏈時的主要依據還是閾值,閾值大了,詞匯鏈過多,每條詞匯鏈中的詞數會很少;閾值小了,詞匯鏈過少,每條詞匯鏈的詞數會過多。因此,定義閾值的大小顯得尤為重要,解決的辦法就是自定義一個或者根據訓練集獲取一個。
4 結語
文中提出的基于擴充詞匯鏈改進的關鍵詞提取方法,每類義原系數βi的值是兩個義項每類義原個數總和占四類義原比值,然后根據比值從高到低的排序從系數集合中獲取相對應的值。
但是在計算詞語相似度時,只考慮了上下位關系,在提取關鍵詞時,先依據詞頻選取詞語,構建關鍵詞備選集合,這會忽略某些頻率低,但卻是關鍵詞的一些詞語。在后續研究工作中筆者將研究同義關系以及反義關系,提高詞語相似度計算的準確率,在構建詞匯鏈時,使詞匯鏈的數目以及每條鏈中詞數達到較好的標準,再結合網絡節點中心度理論,提取出那些詞頻低卻是關鍵詞的詞語。
[1]王立霞,淮曉永.基于語義的中文文本關鍵詞提取算法[J].計算機工程,2012,38(1):1-4.
[2]WITTEN I H,PAYNTEER G W,FRANK E,et al.KEA:Practical automatic keyphrase extraction[C]//The 4thACM Conference on Digital Libraries California,USA:ACM Press,1999:254-256.
[3]TURNEY P D.Learning algorithms for keyphrase extraction[J].Information Retrieval,2000,2(2):303-336.
[4]李素建,王厚峰,俞士汶,等.關鍵詞自動標引的最大熵模型應用研究[J].計算機學報,2004,27(9):1192-1197.
[5]張建娥.基于TFIDF和詞語關聯度的中文關鍵詞提取方法[J].情報科學,2012,30(10):1542-1545.
[6]姜芳,李國和,岳翔.基于語義的文檔關鍵詞提取方法[J].計算機應用研究,2015,32(1):142-145.
[7]索紅光,劉玉樹.一種基于詞匯鏈的關鍵詞抽取方法[J].中文信息學報,2006,20(6):25-30.
[8]王良芳.文本挖掘關鍵詞提取算法的研究[D].杭州:浙江工業大學,2013.
[9]楊林.基于文本的關鍵詞提取方法研究與實現[D].馬鞍山:安徽工業大學,2013.
[10]劉開瑛,薛翠芳,鄭家恒,等.中文文本中抽取特征信息的區域與技術[J].中文信息學報,1998,12(2):1-7.
[11]劉群,李素建.基于《知網》的詞匯語義相似度計算[C]//第三屆漢語詞匯語義學研討會論文集.臺北:[s.n.],2002:59-76.
An improved keyword extraction algorithm based on extended lexical chains
WANG Xiaolin,ZHU Lei,TAI Weipeng
(School of Computer Science&Technology,Anhui University of Technology,Ma’anshan 243032,China)
Keyword extraction plays an important role in the text classification,text clustering and information retrieval.In calculating word similarity,the conventional keyword extraction method based on lexical chains gave the first class independent sememe coefficient the maximum value and restrained the other three sememe similarity through the first independent sememe similarity.In extracting keywords through the regional characteristics and word frequency,it could not take advantage of regional characteristics because of the over-reliance of word weight on lexical chain length.In order to improve the accuracy of keyword extraction,in calculating word similarity,we obtained the coefficients dynamically based on the ratio sorted from the largest to the smallest of the sums of the number of each sememe category of the two words to the sums of four categories of sememes instead of fixed coefficients.And we also removed the restraint of each sememe from the primitive types.In extracting keywords,we replaced the length of lexical chains with their effective weight.Experimental results show that this algorithm has improved the accuracy.
keyword extraction;regional characteristics;word similarity;effective weight;lexical chain;sememe
責任編輯:艾淑艷
TP368.1
:A
:2096-3289(2017)02-0049-06
2015-06-27
國家自然科學基金資助項目(61402009)
王小林(1964-),男,安徽安慶人,教授,碩士生導師,研究方向:人工智能,中文信息處理。
猜你喜歡
法制博覽(2016年12期)2016-12-28 18:50:33
中國科技博覽(2016年24期)2016-12-28 17:53:32
綠色科技(2016年20期)2016-12-27 18:10:47
現代農業科技(2016年20期)2016-12-20 14:58:09
文藝生活·中旬刊(2016年11期)2016-12-13 00:21:13
法制與社會(2016年32期)2016-12-01 16:28:51
中國科技縱橫(2016年17期)2016-11-30 11:49:34
企業技術開發·下旬刊(2016年9期)2016-11-23 03:54:44
中學生物學(2016年10期)2016-11-19 12:48:29
文藝生活·中旬刊(2016年9期)2016-11-07 03:34:57
