分布式環境下端到端的多路并行傳輸機制研究
2017-06-27 08:14:13劉立明
計算機技術與發展 2017年6期
劉立明
(國家氣象信息中心 高性能計算室,北京 100081)
分布式環境下端到端的多路并行傳輸機制研究
劉立明
(國家氣象信息中心 高性能計算室,北京 100081)
在分布式環境中,不同的管理域之間的節點由于受到訪問控制機制的限制,導致端到端的數據傳輸無法直接進行,因此必須借助數據源節點和目的節點之間的節點進行中轉。此外,在復雜的分布式環境中,數據傳輸的源端和目的端之間存在多條傳輸路徑,需要考慮在端到端的數據傳輸過程中如何對多條傳輸路徑進行均衡利用,以提高數據傳輸效率。為此,利用端到端的數據傳輸的特點,基于緩沖區、數據分片、多路并行傳輸等技術,設計了一種適應高性能計算環境中的多路并行數據傳輸機制,研究了可靠性保證策略。理論分析表明,多路并行傳輸機制可以有效解決分布式環境下的數據傳輸訪問控制和傳輸效率等問題,尤其是對于較為復雜的分布式環境下進行的大數據傳輸,該機制充分利用了整個網絡環境的傳輸帶寬,同時解決了中間節點的數據落地問題,為端到端的數據傳輸提供了高效可靠的保障。
分布式環境;數據傳輸;傳輸效率;負載均衡;端到端
1 研究背景
分布式環境是一個在地理位置上廣泛分布的、開放的分布式系統,是把地理位置上分散的資源集成起來的一種基礎設施[1]。分布式計算環境為分散在整個Internet的用戶提供各種計算資源,這些資源由不同管理域中的節點提供,用戶可按需定制使用。
以計算網格的典型應用場景高性能計算(High Performance Computing,HPC)為例[2],對分布式環境下一種典型的數據傳輸場景進行描述。一個分布式作業的執行過程分為Stage-In、Execute和Stage-Out三個階段。前兩個階段都與數據傳輸密切相關。如圖1所示,位于管理域A中的用戶提交一個作業到位于管理域C中的計算節點,在Stage-In階段,需要將作業運行所需要的位于管理域B中FTP服務器上的輸入文件傳輸到位于管理域C中的計算節點上。當作業執行結束后進入Stage-Out階段,計算節點需要將作業執行所產生的輸出結果(數據文件)反饋給提交作業的網格用戶。
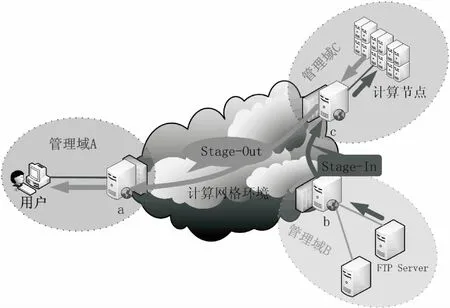
圖1 計算網格環境下“高性能計算”應用的數據傳輸場景
在這樣一個簡單的分布式環境中,不難發現在數據傳輸過程中存在的問題:用戶登錄節點、計算節點、作業執行需要的數據資源所在節點分別位于不同的管理域,而這些管理域之間存在訪問權限的問題,一般采用防火墻進行控制。每個管理域提供一個“頭節點”(head node)供其他管理域中的節點訪問,所有內部“私有節點”(private node)都不對其他管理域開放,這使得在Stage-In階段無法直接建立計算節點與作業執行需要的數據資源所在節點之間的連接進行數據傳輸;同樣,在Stage-Out階段也無法直接建立計算節點與用戶登錄節點之間的傳輸連接。
在上述場景中,數據傳輸雙方無法以傳統的C/S模式直接建立連接,數據傳輸過程只能利用網格環境中的中間授權節點進行中轉。以Stage-In階段為例,現在使用較多的處理方式是:首先將數據資源從其所在節點傳輸到該節點所屬的管理域B的頭節點b,然后網格用戶利用網格身份登錄管理域B的頭節點b,將數據傳輸到節點b可以直接訪問的管理域C的頭節點c,最后網格用戶再登錄節點c,將數據資源傳輸到執行作業的計算節點上。利用這種重復“登錄→傳輸”的中轉方式將數據從源節點傳輸到目的節點。這種傳輸方式的缺點很明顯:對于網格用戶來說,需要利用網格賬號多次登錄不同網格節點才能完成一次數據傳輸操作;對于所用到的各個中轉節點來說,會在節點上留有數據副本,需要用戶在作業執行結束后手動刪除。這種傳輸模式無論是對用戶使用的便捷性還是對數據傳輸效率的保障都是個巨大的挑戰。
在分布式計算環境中,涉及傳輸過程的數據源端和目的端之間的傳輸操作無法直接進行,只能間接通過中間節點,找到從“源”到“目的”的傳輸路徑,并借助該路徑按照特定的策略通過一系列中轉操作將數據發送到目的節點上,這種傳輸模式稱為端到端的數據傳輸。這種數據傳輸模式不同于傳統客戶端/服務器(C/S)模式,因為傳輸雙方無法直接建立C/S連接;也不同于KaZaA[3]、Napster[4]等P2P模式,因為在P2P模式中資源請求節點先通過泛洪(Flooding)查詢來發現資源,找到資源后直接建立點對點的傳輸連接。
端到端的數據傳輸具有以下特點:首先,進行傳輸的數據源節點和目的節點之間無法直接互聯。其次,有了數據中轉節點的加入,在端到端的傳輸過程中存在多條可行的傳輸路徑。由于這些路徑上的鏈路帶寬不同、距離不同等因素存在,導致鏈路傳輸能力具有較大差別。不同傳輸路徑的選擇對端到端的數據傳輸效率有很大影響。
在分析影響端到端的數據傳輸效率的關鍵問題的基礎上,將其歸結為數學問題進行研究,設計并提出了一種適合端到端數據傳輸的多路并行傳輸機制,同時提供了可靠性保證策略,并對其進行了理論分析。
2 端到端的數據傳輸問題的數學描述
用帶權無向圖G=(V,E)表示分布式計算環境,圖的節點V=(v0,v1,…,vn)表示計算節點和傳輸節點,圖的邊E=(E0,E1,…,Em)表示節點間的網絡連接。權值w表示每條鏈路上的時間損耗(反映空閑網絡帶寬),加權函數w:E→R表示從鏈路到實型權值的映射。所以,每條可行的傳輸路徑P=(v0,v1,…,vk)的權為該路徑上所有可行鏈路的權值之和:
(1)
如果圖中u→v找到n條傳輸鏈路P1,P2,…,Pt,那么求解最短路徑的過程就是尋找單個傳輸任務的最短傳輸時間的過程。
最短傳輸鏈路的權可表示為:
δ(u,v)=
(2)
那么,端到端的數據傳輸可轉化為在帶權無向圖G中的多任務并發傳輸問題,任務數量用n(n>1)表示。從u到v間的傳輸鏈路P1,P2,…,Pt上的網絡負載是動態變化的,每個任務在傳輸過程中根據鏈路繁忙程度選擇最快傳輸鏈路即可獲得最大傳輸效率。所以,端到端的傳輸問題可轉化為最大化地均衡利用G中可行傳輸鏈路以獲得最高的吞吐率,使得總傳輸時間最短,可表示為:
(3)
為了和傳統路由傳輸加以區分,在表1中將端到端的數據傳輸和傳統的路由傳輸進行了對比。
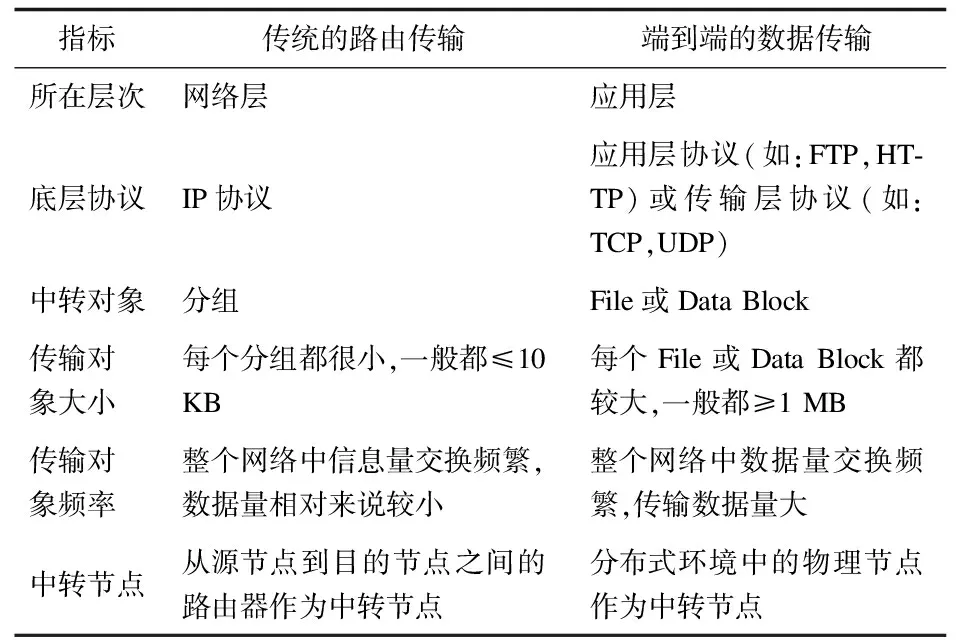
表1 傳統路由傳輸與端到端數據傳輸的對比
端到端的數據傳輸應考慮兩個重要問題:采用何種傳輸機制來提高傳輸效率;對于存在的多條傳輸路徑,如何充分利用以實現合理的網絡分流,提高網絡資源的利用率。
3 相關工作
3.1 網格文件傳輸服務GridFTP
GridFTP是美國Argonne國家實驗室在GT(Globus Tools)項目中設計的數據傳輸協議,它對標準FTP協議(RFC959)進行了擴展,有12所大學和科研機構參與該項目研發。GridFTP為Globus Toolkit提供了高效的傳輸工具[5]。
(1)自動調整TCP緩沖窗口的大小(Auto Negotiation)。用戶可以選擇手動設置或者讓GridFTP自動設置TCP緩沖窗口的大小,提高數據傳輸的性能。
(2)支持由第三方控制的數據傳輸(Third-party Data Transfer)。GridFTP將操作控制通道的邏輯單元稱為協議解釋(PI),對數據通道的操作過程稱為數據傳輸過程(DTP),實現了傳輸和控制的分離。Client端通過控制通道發送命令,讓Server端與其他節點建立傳輸連接,實現數據傳輸。
(3)支持并行數據傳輸(Parallel Data Transfer)。GridFTP通過多個并行的TCP可有效利用鏈路帶寬[6],它對指令和數據通道進行了擴展,支持并行數據傳輸。
(4)支持部分文件傳輸(Partial File Transfer)。GridFTP支持數據文件中特定部分的數據傳輸。它引入新的控制指令支持對一個數據文件的任意部分進行傳輸操作。
Condor Stork[7]、Globus RFT以及gLite FTS等文件傳輸服務都使用GridFTP。但GridFTP和防火墻等管理工具的結合沒有很好地被解決,三方傳輸功能受到限制[8]。
3.2 CNGrid數據傳輸子系統
CNGrid數據傳輸子系統[9]是由國防科技大學和清華大學聯合開發的,應用在CNGrid系統端到端的數據傳輸中,可滿足兩種傳輸情景。它設計了簡單數據中轉的傳輸方法,稱為一跳傳輸和二跳傳輸,如圖2所示。其中,圖中的黑色節點是具有公網IP的服務器(稱為頭節點),其余節點為私有節點(只能被頭節點訪問)。

圖2 CNGird數據傳輸子系統的研究場景
CNGrid數據傳輸子系統提供了一種分布式環境下簡單的端到端的數據傳輸方法,但該方法存在一定的局限性:首先,這種數據傳輸路徑由用戶指定,用戶需要清楚實際部署環境中的部署情況和傳輸情景;其次,該系統只簡單地實現了一跳傳輸和兩跳傳輸情景,對于需要多于兩跳才能完成的傳輸情景無能為力;第三,傳輸過程中會在路由節點上生成臨時文件,占用大量磁盤空間,最后還需要進行刪除處理的善后操作,增加了操作的復雜性和寫磁盤帶來的性能開銷。
4 影響端到端傳輸效率的關鍵問題
4.1 存儲轉發問題
在端到端的數據傳輸系統中,CNGrid數據傳輸子系統利用磁盤暫存傳輸數據再進行轉發,這種傳輸方式需要在傳輸任務完成后再將暫存的臨時數據文件刪除。這種方式產生的時間開銷極大地降低了傳輸效率。第一,讀寫磁盤的速度要遠遠低于處理器的處理速度,兩者不在一個數量級上,所以利用磁盤文件落地后中轉會嚴重浪費CPU的處理周期。第二,中轉文件要在中間節點存儲完成后才能進行轉發,會浪費大量的等待時間,從而極大地降低了傳輸效率。
4.2 點對點傳輸問題
單流式順序傳輸對于數據傳輸來說有很多不利的方面。第一,標準傳輸協議都是基于TCP/IP協議簇設計的,它們的窗口機制并不匹配高速網絡設備的處理速度,致使現有傳輸協議不能充分利用鏈路的網絡帶寬[10]。第二,雖然標準傳輸協議的順序傳輸保證了傳輸過程的數據容錯處理,但是卻在很大程度上降低了傳輸效率,因為在傳輸時需要對數據流上的傳輸字節的順序進行監控,無法進行并行傳輸。
4.3 多路傳輸問題
在端到端的傳輸過程中利用磁盤做存儲轉發只是利用單流式順序傳輸使文件落地,無法利用分布式環境中的多條空閑鏈路,使得整個網絡環境的利用率極低,無法獲得較高的傳輸時效。同時,這些可行的傳輸鏈路在網絡帶寬、擁塞程度、節點性能等方面可能會有較大差別,利用它們進行中轉傳輸時不能統一對待。如果可以充分考慮這些傳輸鏈路各方面的差別,研究一種合理的多路利用策略,以充分利用多條可行傳輸路徑對傳輸任務進行傳輸,則可以提高整個網絡的利用率以及數據傳輸的效率。
5 多路并行傳輸機制的設計
5.1 數據緩沖區策略
眾所周知,讀寫寄存器的速度與CPU的處理速度最接近,但是寄存器的存儲空間小、價格高,只適合緩存臨時數據,不能用作存儲大數據。除此之外,用內存作為數據存儲可以獲得磁盤無法比擬的讀寫速度,更接近處理器的處理速度,是一種高效的存儲方法。但是存儲數據不能在內存上進行持久化。
設計一種數據緩存機制,讓傳輸過程可以有效利用內存區的存取速度,稱為緩沖區機制。即在中轉節點上構建一塊內存區域專門用作中轉數據的緩沖區,實現對轉發數據的緩存,降低存儲轉發過程所產生的時間開銷,從而提高中轉效率。緩沖區只能存儲部分數據,無法存儲大數據文件。后面會引入數據分片機制的設計,實現緩存與動態轉發機能,快速處理緩沖區的數據塊,充分利用內存區域,更大的優勢是解決了中轉節點需存完整個文件后才能轉發的問題,同時解決了內存空間大小的限制,如圖3所示。
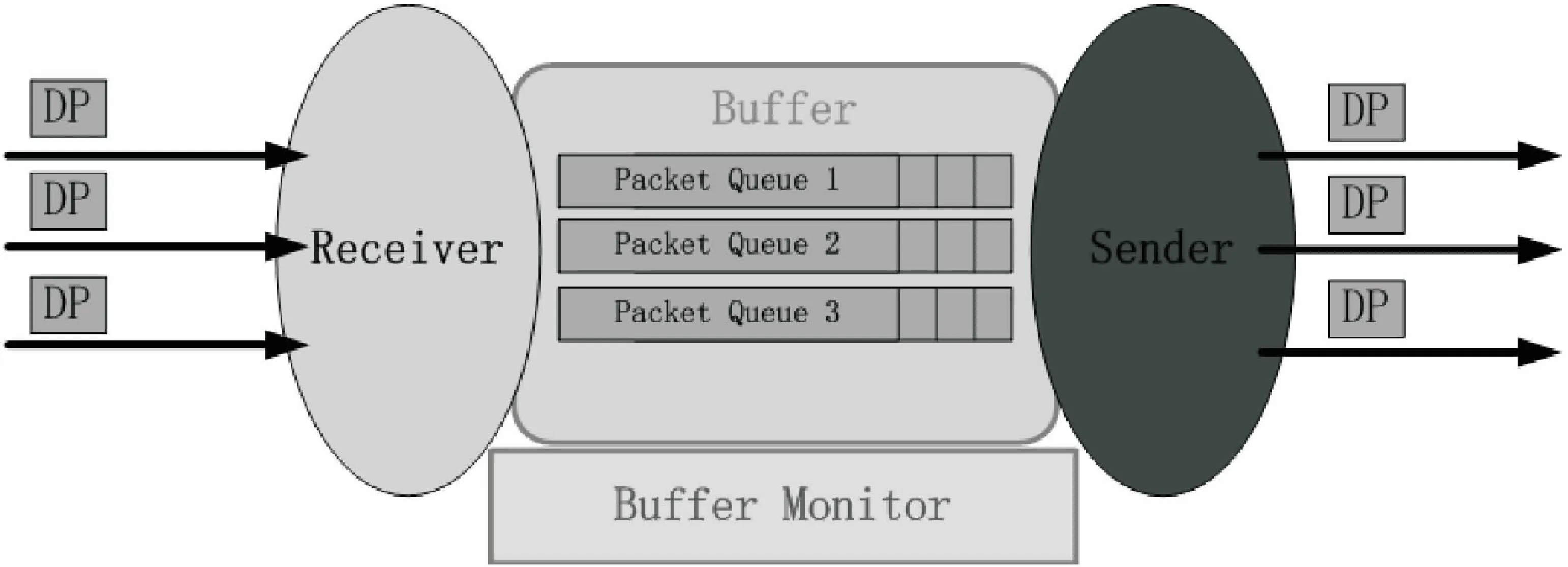
圖3 利用緩沖區機制存儲轉發示意圖
5.2 多路并行傳輸的實現機制
5.2.1 多路分流策略
前面在分析影響端到端的傳輸效率的關鍵問題時,提到當前大多數端到端數據傳輸系統都是利用在分布式環境中按照一定的策略選擇一條比較優的路徑(或者指定路徑)的方式完成端到端的數據傳輸,沒有充分利用網絡中源節點和目的節點之間存在的多條可行傳輸鏈路,如圖4所示。
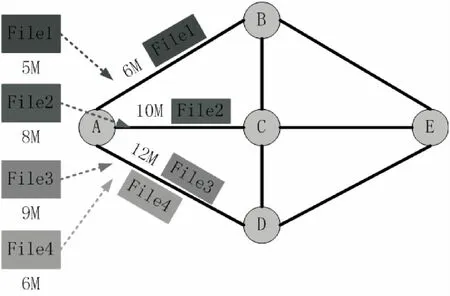
圖4 多路并行傳輸
從數據源節點到達目的節點存在多條可行路徑,每個中轉節點接收的數據塊都有多條可達目的節點的傳輸鏈路可以選擇。在每個節點上都充分利用所有可行鏈路去完成數據塊的傳輸,那么帶寬的總體吞吐量將獲得很大程度的提高。單條鏈路k上的帶寬設為BWk,那么在理論上可用于傳輸的網絡總帶寬變成:
(4)
此外,多路徑傳輸機制帶來的另一個好處是:如果在傳輸過程中遇到局部節點或鏈路崩潰的情況,多路徑傳輸策略能夠使用備用路徑完成傳輸,因此在一定程度上保證了傳輸的可靠性。
5.2.2 數據分片策略
在分布式計算、云計算等并行計算領域,一般會將單個計算任務分解,每個任務在一定的顆粒度上分解為多個獨立的子任務,以便并行處理來充分利用計算資源,提升計算效率。端到端的傳輸可以借鑒這種原理。為了提高數據傳輸效率,可以對一個傳輸任務進行切分,將其切分成若干子傳輸任務,結合下面介紹的多流并發傳輸機制,充分利用網絡帶寬,提高傳輸任務的執行效率。
為此,將需要傳輸的數據文件按設定尺寸切分成若干大小相等的數據塊(Block,數據文件的最后一個數據塊小于等于數據塊設置大小),每個數據塊具有獨立的數據結構,構建成數據包(Packet),作為單獨的傳輸子對象,從而實現了對單個傳輸任務的并行切分。中轉節點的緩沖區會接收并解析每個接收到的數據包的數據結構,包含傳輸的源地址、目的地址、源文件信息、目的文件信息、數據塊號、起始位置、數據塊大小、校驗和、時間戳、實際數據等信息。然后根據對鏈路傳輸能力的評估選擇隊列進行轉發,最終所有數據包到達目的節點后進行任務合并,通過解析數據包頭部信息,將數據塊寫入到目標文件并進行校驗,最終完成傳輸任務。對于數據分塊的大小,按照文獻[11],設置數據分塊大小為1 MB。
圖5演示了上述過程,可以清晰地看到與圖4的區別。四個傳輸任務(File1~File4)到達節點A后,File1~File3分別選擇鏈路ABE(5 MB)、ACE(8 MB)和ADE(9 MB)進行轉發,每條可用鏈路都有剩余帶寬,File4整體傳輸只能選擇最優的鏈路ADE(剩余3 MB),但是利用數據分片機制可將其切分成6個單獨的數據塊(1 MB)。然后并行分布到三條具有剩余帶寬的鏈路上實現轉發,最終在目的節點E對所有數據塊進行合并。這種機制在很大程度上提高了帶寬的利用率。
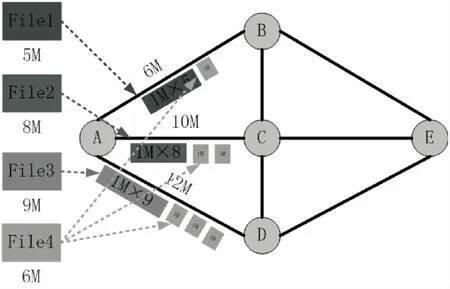
圖5 數據分片傳輸
此外,數據分片傳輸帶來的另一個好處是:在一定程度上增強了端到端傳輸過程中數據的安全性。因為在多路徑并行傳輸的情況下,數據包經不同的鏈路傳輸到目的端,數據包在任何中間節點上被截獲也無法被構造出源文件,所以說數據分片傳輸增強了數據傳輸的安全性。
5.2.3 多流并發策略
提高帶寬利用率的一類方法是通過調節TCP緩沖窗口的大小來提高鏈路的帶寬利用率[12-14]。這種方式的原理是當TCP最優緩沖窗口大小(Optimal Buffer Size)等于鏈路帶寬(Bandwidth)與往返時延(RTT)的乘積時,可以最大程度地利用傳輸鏈路的帶寬。GridFTP利用這種方式來提高網絡帶寬利用率。這種調整方法對于應用層的傳輸來說復雜性較高。一方面,由于網絡實際的可用帶寬具有動態變化性,所以調整TCP緩沖區的做法復雜性高,需要不斷動態調整才能滿足要求;另一方面,在應用層的傳輸需要操作傳輸層TCP緩沖窗口大小,從設計的角度來說不符合設計規范。
另一類提高帶寬利用率的方法是多數據流并發傳輸機制[10]。這種方法的本質是在相鄰兩個節點間構建多個并行的Socket對,根據特定的調度機制進行數據的并行發送和接收。具體方法是每個中轉節點在應用層建立N(N>1)個TCP流,根據調度機制進行監聽、接收、發送操作。該方法的優點是不用手動調整網絡層的TCP緩沖區大小,規避了傳統傳輸協議的劣勢,同時提高了鏈路的帶寬利用率。文獻[10]分析了該機制的優勢,并實驗對比了與調整緩沖區方案的傳輸效率區別,證明了多流并發機制在提高鏈路吞吐率方面的優勢,可以獲得更高的傳輸效率。
行業性質:絕大多數企業位于產業鏈利潤最低的制造環節:超過90%的企業均為生產型企業;占據產業鏈高端環節的企業很少:總部、研發設計、采購及業務等比例較小,占比最大的采購環節亦僅五分之一左右。
在實驗評測中,通過多組實驗數據證明了在百兆網環境中,使用系統默認的TCP緩沖區大小時的并發流數目為5~12時,可以獲得較優的傳輸效率。
6 傳輸過程的可靠性保證
Condor中設計的Stork[7]采用集中式的管理策略保證數據傳輸的可靠性,缺點是過于依賴監控節點,一旦監控節點異常,可靠性保證機制將失效。受傳輸層TCP協議可靠性保證策略[15]啟發,設計一種請求重傳與超時重傳相結合的可靠性保證策略,并針對網絡傳輸性能動態變化的特點,提供了一種動態估計最大超時時間的方法。
6.1 出錯請求重傳
在傳輸源節點為每個數據塊構建數據包時,采用MD5計算其校驗值,并記錄到數據包的數據結構中。每個中轉節點收到傳輸數據包時,首先對其解析并進行MD5校驗,根據校驗結果判斷收到的數據包是否已被破壞。如果發現數據包被破壞,則丟棄,同時根據該數據包攜帶的信息向源端發送重傳消息,重傳消息中攜帶了請求重傳的數據塊信息。
6.2 超時重傳
在傳輸源節點為每個數據塊構建的數據包在傳輸時為其記錄一個時間戳,目的端每成功接收一個數據包則返回給發送端一個響應消息,響應信息攜帶了傳輸成功的數據塊的信息,對于收到響應信息的數據塊則將其標記為傳輸成功狀態。源端采用輪詢方式檢查各數據塊傳輸是否超時,如果發現超時,則對相應的數據塊發起重傳操作。當發現有數據塊的重傳次數超過最大重傳次數的限制時,放棄重傳,通知用戶傳輸任務失敗,并將傳輸任務移除。
6.3 動態估計最大超時時間
首先,在每個傳輸任務開始前,發送若干攜帶傳輸任務信息的數據包進行路徑探測,返回的響應信息作為探測結果。如果發現目的節點不可到達,則通知用戶傳輸失敗,這樣可以防止在目的節點不可達的情況下盲目傳輸造成的網絡帶寬浪費;如果返回消息顯示目的節點可達,則記錄消息的往返時延(RTT)。然后根據消息數據包大小、往返時延以及實際傳輸數據包大小,按式(5)計算數據包最大超時時間:
(5)
其中,sizebp為傳輸數據包大小;sizeba為后行消息數據包大小;sizem為探測消息大小;RTTm為探測消息往返時延;ω為超時系數,根據文獻[16],一般ω取4。
然后,當傳輸任務被調度并開始執行后,源節點會不斷地收到標識各數據塊傳輸成功的響應消息,它將定期根據數據包發送時間timebp和消息返回時間timeba,按式(6)動態更新數據包最大超時時間:
(6)
這種策略的優點是:傳輸過程的可靠性不依賴于集中式的節點控制;動態更新最大超時時間可以實時應對網絡傳輸性能動態變化導致的數據包傳輸時延差異;出錯請求重傳可以及時發現傳輸過程中的錯誤并及時進行處理。
7 結束語
在研究分析影響端到端數據傳輸效率的關鍵問題基礎上,基于緩沖區、數據分片、多路并行傳輸等技術,設計了一種適合端到端數據傳輸的多路并行傳輸機制,同時提供了可靠性保證策略,旨在充分利用網絡帶寬以提高傳輸效率。
理論分析表明,該機制有效解決了分布式環境下數據傳輸的訪問控制和傳輸效率等問題,尤其是對于較為復雜的分布式環境下進行的大數據傳輸,該機制充分利用了整個網絡環境的傳輸帶寬,同時解決了中間節點的數據落地問題,為端到端的數據傳輸提供了高效可靠的保障。
[1] 徐志偉,馮百明,李 偉.網格計算技術[M].北京:電子工業出版社,2004.
[2] Wasson G,Humphrey M.HPC file staging profile[C]//Conference on active media technology.[s.l.]:[s.n.],2008:58-70.
[3] 蔣 成.混合式對等網絡Kazaa模型結構及其分析研究[J].信息安全與技術,2013,4(6):69-71.
[4] Bengt C,Rune G.The rise and fall of napster-an evolutionary approach[C]//Proceedings of the 6th international conference on computer science.[s.l.]:[s.n.],2009:347-354.
[5] Itou T,Ohsaki H,Imase M.On parameter tuning of data transfer protocol GridFTP in wide-area grid computing[J].IEICE Technical Report Information Networks,2004,104(4):19-24.
[6] Cannataro M, Mastroianni C, Talia D.Evaluating and enhancing the use of the GridFTP protocol for efficient data transfer on the grid[C]//Lecture notes in computer science.Berlin:Springer,2003:619-628.
[7] Kosar T,Livny M.Stork:making data placement a first class citizen in the grid[C]//24th IEEE international conference on distributed computing systems.[s.l.]:IEEE,2004:342-349.
[8] Niederberger R,Allcock W,Gommans L,et al.Firewall issues overview[R].[s.l.]:[s.n.],2006.
[9] 中國國家網格軟件數據網格工作組.數據網格進展匯報[R].北京:中科院計算所,2008.
[10] Sivakumar H,Bailey S,Grossman R L.PSockets-the case for application-level network striping for data intensive applications using high speed wide area networks[C]//ACM/IEEE conference on supercomputing.[s.l.]:IEEE,2000:38.
[11] Kola G,Livny M.DiskRouter:a flexible infrastructure for high performance large scale data transfers[R].Ameracan:University of Wisconsin,2003.
[12] Lee J,Dan G,Tierney B,et al.Applied techniques for high bandwidth data transfers across wide area networks[C]//Proceedings of international conference on computing in high energy and nuclear physics.[s.l.]:[s.n.],2011:428-431.
[13] Semke J,Mahdavi J,Mathis M.Automatic TCP buffer tuning[J].ACM SIGCOMM Computer Communication Review,2000,28(4):315-323.
[14] Lakshman T,Madhow U.The performance of TCP/IP networks with high bandwidth-delay products and random loss[J].IEEE Transactions on Networking,1997,5(3):336-350.
[15] Tanenbaum A S.Computer networks[M].5th ed.Beijing:China Machine Press,2012:258-309.
[16] Jacobson V, Karels M J. Congestion avoidance and control[J].ACM SIGCOMM Computer Communication Review,1988,18(4):314-329.
Research on End-to-end Multipath Parallel Transfer Mechanism in Distributed Environments
LIU Li-ming
(HPC Department,National Meteorological Information Centre,Beijing 100081,China)
In distributed environment,nodes in different management domains can’t transfer data to each other directly because of restrictions of access control mechanism,so that the end-to-end data transfer has to rely on the mid nodes between the source and destination to transit.In addition,there are more than one transfer path between the source and destination in complex distributed environments,and a way to utilize those transfer paths balanced to improve the end-to-end data transfer efficiency needs to be considered.According to the characteristics of end-to-end data transfer,an efficient end-to-end multipath parallel transfer mechanism has been designed with the technology of buffer area,data segmentation and multipath parallel transfer and effective strategies to ensure the transfer reliability.The results of analyses show that this mechanism has effectively solved the problems of access control and transfer efficiency in distributed environment which is a highly efficient and reliable transfer security mechanism for end-to-end data transfer,and that especially for big data transmission in more complex distributed environment,the bandwidth of the network environment could be made full use of and the problem of the data to disk on intermediate node has been solved.
distributed environment;data transfer;transfer efficiency;load balancing;end-to-end
2016-06-13
2016-09-22 網絡出版時間:2017-03-13
國家發改委中國氣象局“十二五”重點工程建設項目(ZQC-H14175)
劉立明(1981-),男,碩士,工程師,研究方向為分布式計算。
http://kns.cnki.net/kcms/detail/61.1450.tp.20170313.1546.050.html
TP309
A
1673-629X(2017)06-0001-06
10.3969/j.issn.1673-629X.2017.06.001
猜你喜歡
四川勞動保障(2021年9期)2022-01-18 05:11:08
甘肅教育(2020年14期)2020-09-11 07:57:42
中學生數理化(高中版.高考數學)(2020年5期)2020-06-02 09:19:08
文苑(2018年21期)2018-11-09 01:23:06
商周刊(2017年9期)2017-08-22 02:57:49
中國衛生(2016年9期)2016-11-12 13:28:08
中國衛生(2015年9期)2015-11-10 03:11:12
時代英語·高二(2015年1期)2015-03-16 00:08:11
中國衛生(2014年3期)2014-11-12 13:18:12
中國衛生(2014年11期)2014-11-12 13:11:32
