Redis分布式緩存技術在Hadoop平臺上的應用
2017-06-27 08:14:13姚經緯楊福軍
計算機技術與發展 2017年6期
關鍵詞:作業
姚經緯,楊福軍
(1.江南大學 物聯網工程學院,江蘇 無錫 214122; 2.中國空氣動力研究與發展中心 計算空氣動力研究所,四川 綿陽 621000)
Redis分布式緩存技術在Hadoop平臺上的應用
姚經緯1,楊福軍2
(1.江南大學 物聯網工程學院,江蘇 無錫 214122; 2.中國空氣動力研究與發展中心 計算空氣動力研究所,四川 綿陽 621000)
在使用Hadoop進行大規模數據分析時,經常會遇到的一個較為典型的問題就是共享數據的快速訪問問題。該類問題存在的場景很多,如網頁排名算法、最小錯誤率訓練算法、最大期望算法等。雖然已有關于此類問題的解決方案,但實際取得的效果卻不盡如人意。為此,提出了使用Redis內存數據庫作為分布式緩存,以解決Hadoop中共享數據訪問的問題。驗證實驗結果表明,Redis分布式緩存的吞吐率與集群規模有較好的線性關系,所提出的方法能夠較好地解決Hadoop任務對共享數據的訪問問題,同時也為其他大規模共享數據訪問的問題提供了簡便的解決思路。Redis作為開源的商業化工具,使得所提出的方法具有較好的適用性,可為科研以及生產實踐中遇到的同類問題提供一種較為通用的解決方案。
Redis;分布式緩存;Hadoop;MapReduce
0 引 言
隨著信息技術的飛速發展,互聯網數據量也呈現出爆炸式增長,進入了大數據時代[1]。對于日益增長的海量數據處理,傳統的數據處理方式已無法支持如此龐大的數據量,因而云計算技術應運而生。在諸多云計算平臺中,Hadoop憑借其開源、廉價等優勢,在大數據的存儲和處理等方面應用廣泛[2],很多互聯網企業,如亞馬遜、阿里巴巴、中國移動等都紛紛使用Hadoop作為自己的數據處理平臺。Hadoop的核心主要是HDFS(分布式文件系統)和MapReduce分布式數據處理框架;除此之外,還有很多基于Hadoop的工具,如:HBase分布式數據庫、Hive數據倉庫分析工具、Spark流式數據處理框架等[3]。
Hadoop的出現大大簡化了分布式程序設計,使用者只需要簡單地將數據處理應用分解為Mapper和Reducer,就可以使之運行在Hadoop集群上,而不用關心各節點之間如何通信、如何傳遞數據等底層實現[4]。然而,Hadoop在實際使用中仍然存在一系列問題亟待解決,任務節點如何快速訪問海量共享數據則是其中一個較為典型的問題。
針對Hadoop任務節點如何快速訪問海量共享數據的問題,基于對典型實例的闡述和分析,提出了使用Redis作為分布式緩存解決共享數據的訪問問題。并以PageRank算法為例,研究分析了如何使用Redis解決PageRank算法中網頁得分數據的存儲和訪問問題,通過實驗對該方法的可行性和效率進行了驗證,并為其他相似問題的解決提供了思路。
1 MapReduce和Redis簡介
1.1 MapReduce框架
MapReduce[5]最先是由Google公司的Jeffrey Dean和Sanjay Ghemawat提出的一種用于解決大數據并行計算問題的編程模型。后來Apache基金會的Doug Cutting在Hadoop項目中實現了該模型并將其開源,大大推動了MapReduce框架的研究和發展。MapReduce程序以鍵值對
(1)任務分配:JobTracker將整個作業分解為多個任務,并分配到任務數據所在的節點上,由各節點的TaskTracker負責任務執行。
(2)Map階段:任務節點將當前節點上的數據塊解析為鍵值對
(3)洗牌:將鍵k2相同的記錄發送到同一個Reduce任務節點上。
(4)Reduce階段:任務節點將所有鍵k2相同的記錄以鍵值對
(5)作業結束:當所有Map任務和Reduce任務結束后,整個作業結束。
在MapReduce編程中,編程人員只需根據業務編寫Map函數和Reduce函數就可以實現比較復雜的并行計算作業,而不用關心各節點之間如何通信、如何傳遞數據等底層實現,大大簡化了并行編程的復雜度。MapReduce程序還具有很好的可擴展性,在大多數情形下,它不僅可以隨著數據規模的擴大表現出持續的有效性,而且在性能上能隨著節點數的增加保持接近線性的增長。同時,MapReduce還具有低成本和高可靠性等眾多特征,使其從一開始就受到了學術界和商業界的極大關注[4]。
1.2 Redis內存數據庫
Redis[6]是一種基于內存的Key-Value數據庫產品,是由遠程字典服務(Remote dictionary server)取名而來。它支持多種數據類型的存儲:字符串(string)、鏈表(list)、集合(set)、有序集合(zset)和哈希類型(hash),并且各種類型都支持豐富的操作,其中大多都支持原子操作。為了保證數據存取的效率,數據都保存在內存中;Redis還提供了對持久化的支持,它可以定期將更新的數據異步寫入磁盤,同時不影響繼續提供服務;在此基礎上,還實現了主從復制,這對預防單點故障和提高負載能力有很大幫助。Redis的出現,在很大程度上彌補了Memcached的不足,它不僅支持更加豐富的數據類型和操作,而且在讀寫效率上也比Memcached更勝一籌。根據Redis官方測試數據,Redis寫入速率為198 412.69條/s,讀速率為198 019.80條/s[7],相比Memcached要高出數倍。Redis具有如此多的優秀特性,使其從一開始就受到了廣泛關注,Redis可以適用于多種不同的應用場景,很多大型互聯網企業的后臺服務中都有使用,并且存在不少成功應用的范例。
雖然Redis讀寫性能非常優秀,但是因為內存容量的限制,僅使用單臺服務器一般是不夠的,這就需要使用集群的形式進行水平擴容。在舊版Redis中通常使用客戶端分片來構建集群,但這種方式有很多缺點,比如維護成本高,增加、移除節點較繁瑣等;但Redis 3.0版的發布解決了這一問題,因為它增加了對集群的原生支持。Redis集群采用無中心架構,各節點間使用Gossip協議進行通信;在對數據的分配上使用預分桶的策略,將每個鍵的鍵名有效部分使用CRC16算法計算出散列值,然后對16 384取余,使得每個鍵都可以被分配到預先分配好的16 384個插槽,進而在對應的節點中進行處理;集群具有較高的可用性,它采用主-從形式,確保當主節點失效后可以將一個從節點轉變為主節點,以此確保集群的完整性和可用性[8]。Redis集群的這些特性使得能夠很方便地將其作為分布式緩存使用。
2 問題探討
Hadoop在生產實踐中被廣泛應用于大數據的存儲和處理,并且存在很多成功應用的典范。但是在實際應用中也暴露出一些問題,其中一個較為典型的就是任務節點如何快速訪問海量共享數據的問題。存在該類問題的算法和情景不在少數,這里僅列舉三個典型對該類問題進行簡單闡述。
2.1 網頁排名算法
網頁排名算法(PageRank)[9-10]是由Google創始人Sergey Brin和Lawrence Page提出的用于在搜索引擎上對網頁進行排名,以此體現網頁重要性的一種算法。該算法初始時為每個網頁設置一個得分,經過多次迭代不斷更新各網頁的得分,最終各網頁得分收斂時算法結束。在每次迭代中,都需要根據每個網頁的得分給所有鏈出網頁打分,每個網頁根據所有鏈入網頁給出的打分,計算并更新自己的得分。在Hadoop上運行該算法時,網頁得分數據是所有任務的共享數據,在每個任務中都需要獲取和更新網頁得分數據,因此網頁得分數據的訪問效率會直接影響算法的執行效率。而且在實際應用中,網頁得分數據往往會達到數百億條,因此,如何存儲和訪問網頁得分數據則是接下來所主要討論的問題。
2.2 最小錯誤率訓練算法
最小錯誤率訓練算法(MERT)[11]是由Franz Josef Och提出的一種在機器翻譯中以翻譯質量為優化目標,以此調節對數線性模型參數的算法。該算法初始時生成翻譯候選和對應特征權重,經過多次迭代不斷對其進行更新,直到不再產生新的翻譯候選時算法結束。每次迭代中使用解碼器對翻譯候選進行解碼,生成新的翻譯候選與之前的合并,并在擴展的候選集上重新調整特征權重。在Hadoop上運行MERT算法時,特征權重數據是所有任務的共享數據,其訪問效率會直接影響到算法的執行效率。實際應用中,特征權重數據也可能會達到數十億條,那么又該如何解決數據的存儲和訪問問題。
2.3 最大期望算法
最大期望算法(EM)[12]是由Arthur Dempster等提出的在已知部分相關變量的情況下,尋找未知變量的最大似然估計或最大后驗估計的算法,在數據挖掘領域的聚類算法中應用廣泛。以基于高斯混合模型的EM算法為例,它分為兩個階段交替執行直到模型參數趨于收斂:
(1)步驟:根據數據集和模型參數計算對數似然函數的條件期望;
(2)更新模型參數,使對數似然函數期望最大化。
在Hadoop上運行EM算法時,模型參數為所有任務所共享,其訪問效率同樣會直接影響算法的執行效率。同樣,當模型參數數據量過大時,又該如何解決數據的存儲和訪問問題。
上述三類問題都涉及到任務節點如何訪問共享數據這一共性問題。雖然Hadoop提供了分布式文件緩存機制,可以將共享文件拷貝到每個任務節點并裝載到內存中以實現數據的共享,該方法確實可以在一定程度上解決上述問題;但是當共享文件過大無法正常裝載到任務節點的內存中時,該方法就不再適用,這在實際應用中并不罕見;況且,對每一個任務節點來說,它所需要的數據可能僅僅是全部共享數據的一小部分,這種情況下將全部共享數據拷貝到任務節點上不僅浪費網絡和內存資源,而且還可能拖慢任務的執行。因此,提出了使用Redis內存數據庫作為分布式緩存,實現在Hadoop任務節點間快速獲取共享數據的方法,從而更好地解決上述問題。
3 解決方案
根據討論中提及的三個問題,需要一種能夠在Hadoop任務節點間快速獲取共享數據的機制,并且必須滿足以下條件:
(1)鍵必須保證全局唯一性;
(2)必須能夠支持大規模的數據存儲;
(3)必須確保在高并發量前提下數據訪問的高效性。
Redis內存數據庫的特性剛好滿足上述需求[13],因此,提出子在Hadoop中引入Redis分布式緩存來解決共享數據的存儲和訪問問題。
使用Redis作為分布式緩存,需要確保Hadoop集群中各節點都能同等地訪問Redis中存儲的數據,因此,采用圖1的架構方式。這種將Hadoop集群與Redis分布式緩存直接相連的方式,不僅在實現上比較簡單,而且也最大程度地保證了數據存取的效率。對于分布式緩存的使用,一般分兩步進行:
首先將HDFS上的共享數據加載到分布式緩存中。這一步并不需要用到Reduce,因此發起一個只有Map階段的作業即可完成,各Map任務可以并行地讀取數據,并保存到分布式緩存中。
當分布式緩存數據準備完成后,啟動需要執行的MapReduce作業。各任務節點在初始化時使用Jedis客戶端建立起到Redis集群的連接,這樣,在任務執行中需要訪問緩存時就可以隨時通過連接讀寫共享數據。

圖1 Hadoop與Redis分布式緩存架構圖
為了進一步闡述問題,并驗證Redis作為分布式緩存的性能,以網頁排名算法為例,闡述Redis分布式緩存在Hadoop任務中的應用。在實例中使用原始的網頁排名算法進行闡述,一方面,研究的主要目的在于使用Redis分布式緩存解決大規模共享數據問題,而非僅僅論述網頁排名算法的優化問題,對網頁排名算法的優化不作為研究重點;另一方面,對網頁排名算法的優化大都集中于如何減少迭代次數或如何在每次迭代中減少需要處理的數據等方面,優化后的算法仍可能出現上述問題,而原始的網頁排名算法具有很好的代表性,能夠較簡明地說明問題。
網頁排名算法計算網頁排名基于以下兩個基本假設:
(1)數量假設:一個具有較多鏈入的網頁會有較高得分。
(2)質量假設:一個得分較高的網頁能夠給其鏈出的網頁打出較高的分數。
根據這兩個假設,可得[9]:
(1)
其中,pi和pj表示兩個不同的網頁;PR(pi)和PR(pj)分別表示pi和pj的得分;M(pi)表示所有鏈入pi的網頁集合;L(pj)表示pj鏈出的網頁數目;N表示全部網頁數目;d表示阻尼系數(表示用戶到達某網頁后繼續向后瀏覽的概率,一般取0.85)。
網頁排名算法計算網頁得分是一個迭代計算的過程。初始時賦予每個網頁相同的得分,在之后的每次迭代中,使用式(1)更新得分,直到所有網頁得分穩定時算法終止。
使用Redis作為分布式緩存,在Hadoop上實現網頁排名迭代算法的步驟如下:
(1)原始數據的預處理。對原始數據進行處理,生成符合格式要求的網頁鏈接數據文件,并保存到HDFS中。網頁鏈接數據文件的每行第一列表示當前網頁鏈接地址,后面的各列表示當前網頁所有鏈出的網頁地址,各列以Tab鍵分隔,后文出現的網頁鏈接數據,如無特別說明,都使用該格式。
(2)初始化網頁得分數據并保存到Redis中。啟動一個只有Map階段的作業用來讀取網頁鏈接數據,Map函數中,將當前的鍵(url)和初始化得分(score)以鍵值對
1 //key:當前網頁的鏈接地址;value:以Tab鍵分隔的所有鏈出地址
2 Map(key,value) {
3 init = 0.5; //默認初始得分
4 setToRedis(key,init); //將鍵值對保存到Redis分布式緩存中
5 }
(3)使用一次MapReduce作業完成網頁排名算法的一次迭代。在每次迭代的Map函數中,從分布式緩存中獲取當前網頁得分(score),將該得分平均分配給各鏈出地址(url,共n個)作為對該鏈接的打分,并以鍵值對
1 //key:當前網頁的鏈接地址;value:以Tab鍵分隔的所有鏈出地址
2 Map(key,value) {
3 //根據鍵從Redis分布式緩存中獲取相應的值
4 score=getFromRedis(key);
5 urls=value.split(" ");//將value以Tab鍵分割得到數組
6 for(url :urls) {
7 context.write(url,score/urls.length);//Map的輸出
8 }
9 }
在每次迭代的Reduce函數中,將其他網頁給本網頁(url)的打分計算匯總后得出本網頁的得分(score),并以鍵值對
1 //key:本網頁的鏈接地址;values:其他網頁給本網頁的打分集合
2 Reduce(key,values) {
3d=0.85; //阻尼系數
4 //sum(values):對values集合進行求和
5 score=(1-d)+d*sum(values);
6 setToRedis(key,score); //將鍵值對保存到Redis分布式緩存中
7 }
4 實驗結果及分析
實驗中使用9臺普通PC,每臺PC配置如下:3 GB內存,酷睿2雙核CPU,500 GB硬盤,Ubuntu 14.04操作系統。實驗使用Apache Hadoop 1.2.1,其中1臺作為NameNode和JobTracker,其他8臺作為DataNode;Redis版本3.0.7,分別搭建在8臺DataNode上,構成一個8節點的Redis集群作為分布式緩存。
實驗數據使用網絡爬蟲從互聯網上爬取,經過過濾和預處理后得到符合格式要求的網頁鏈接數據。鏈接數據共包含36 323 864個網頁節點,大小約37 GB。實驗按照第三節中的步驟進行,作業執行時間使用4次迭代的平均時間計算。在每次迭代中,需要讀取緩存36 323 864次,寫入緩存36 323 864次,共計訪問緩存72 647 728次。
實驗結果如表1和圖2所示。
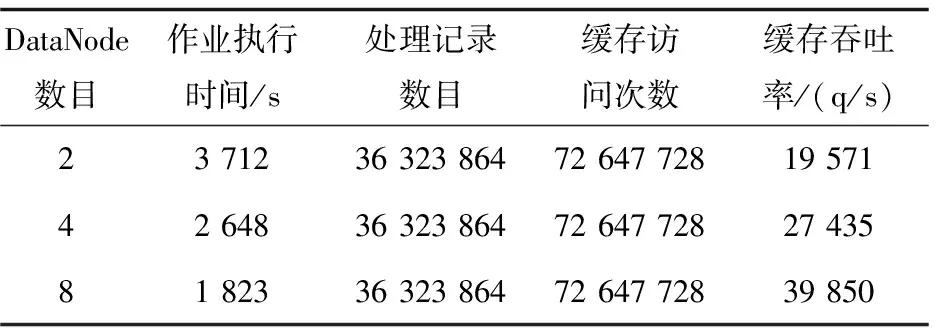
表1 Redis分布式緩存實驗結果
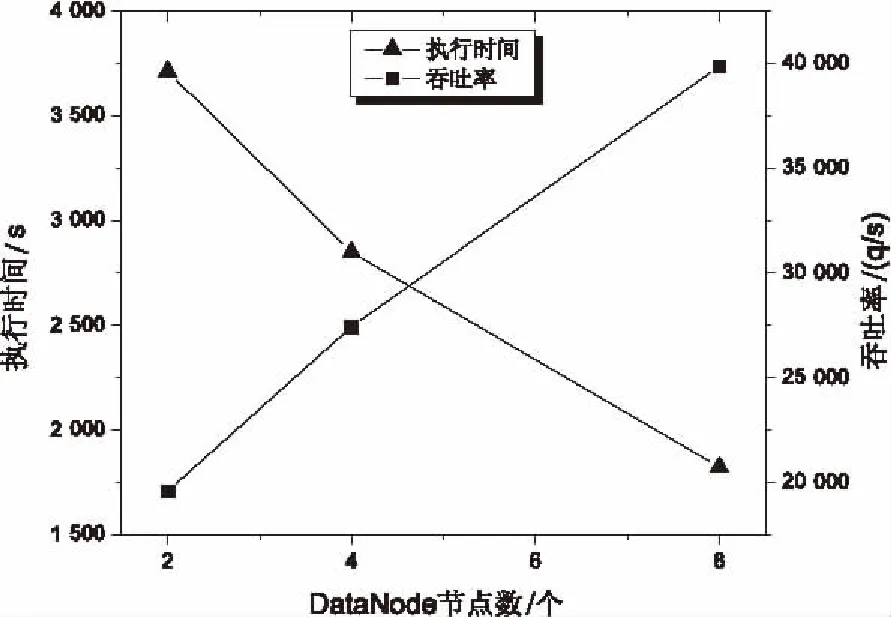
圖2 節點數與執行時間和吞吐率關系圖
從圖2中可以看出,隨著Hadoop集群節點數的增加,作業執行所需的時間在減少。這是因為隨著任務并發量的增大,相同時間內能夠處理更多的數據,因此作業執行所需的時間也會相應減少。與此同時,隨著Hadoop集群節點數的增加,Redis分布式緩存的吞吐率接近直線增加(R=0.996),也就是說,Redis分布式緩存的吞吐率與并發訪問量有較好的線性關系。
為了對使用了Redis分布式緩存的作業與普通MapReduce作業的執行效率進行比較,實現了PageRank算法的MapReduce程序[10,14]:首先啟動一個Hadoop作業,將網頁鏈接文件和鏈接得分文件同時輸入,通過Reduce匯總后計算得到該網頁對其他網頁的打分,作為中間文件輸出到HDFS上;然后啟動另一個Hadoop作業,將中間文件作為輸入,通過Reduce匯總后計算得到每個網頁的打分并輸出。這樣就完成了PageRank算法的一次迭代。使用與上述實驗同樣的數據集和集群進行實驗,結果如表2和圖3所示。
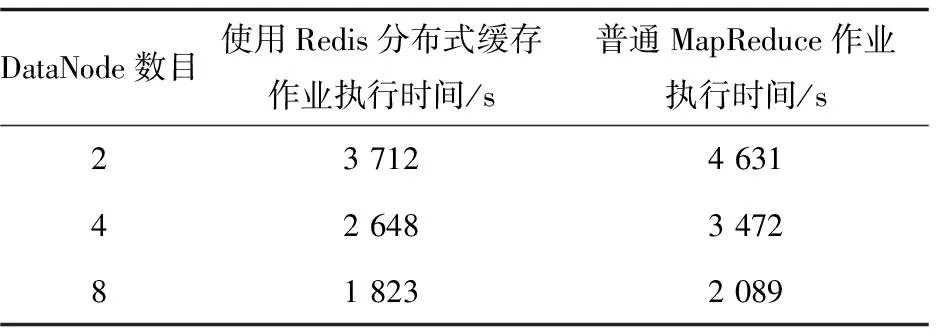
表2 使用Redis分布式緩存與普通MapReduce作業的實驗結果
從圖3中可以看出,使用Redis分布式緩存后,PageRank作業的執行效率與普通基于MapReduce的作業執行效率相比有所提高,這主要是因為從內存中讀取數據與從硬盤讀取數據相比更加高效的緣故;其次,直接從Redis中獲取共享數據與采用其他替代的方式間接獲取共享數據相比,不僅降低了程序的復雜度,而且更加簡便高效。
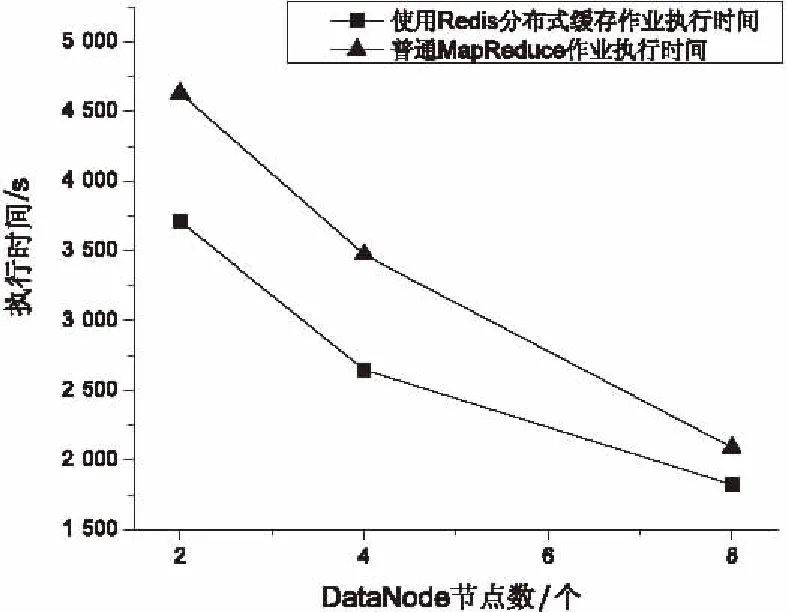
圖3 使用Redis分布式緩存與普通MapReduce的作業執行時間
以上結果表明,Redis集群在高并發的情況下仍然能夠保持優良的性能,因此Redis能夠很好地與Hadoop平臺相結合,作為在任務執行過程中高效獲取共享數據的分布式緩存,解決共享數據的存儲問題。而且,Redis集群本身還具有很好的可擴展性,可以通過增加節點數目擴大集群的容量,而且在性能上也能保持接近線性的增長,這一特性使得日后數據規模擴大后可以比較簡單地通過增加節點的方式實現擴展,而不用對源程序作任何修改。同時,Redis作為成熟的商業產品,具有使用簡單、易于推廣的特點,使得該方案能夠比較容易地運用于實踐中,為Hadoop任務中共享數據的訪問提供一種簡單、高效的解決方案。
關于所提到的最小錯誤率訓練算法和最大期望算法的問題,也可以使用與上面所提到的網頁排名算法類似的解決方案,即將共享數據加載到Redis分布式緩存中,這樣在任務執行時各任務節點就可以隨時訪問分布式緩存中的數據,此處就不再一一贅述。
綜上所述,Redis分布式緩存具有性能高、擴展性好、使用簡單等特點,因此可以作為在Hadoop任務中訪問共享數據的有力工具,為相關問題提供一種簡單高效的解決方案。雖然Redis作為分布式緩存在性能上已經足夠高效,但是仍有可以進一步優化之處,比如:使用批量提交請求的方式減少交互次數,使用異步的請求方式提高并行度,使用UDP協議加快訪問速度,實現Redis集群負載均衡以提高效率……這些Redis性能優化問題值得進一步深入研究。
5 結束語
為了解決實際應用中Hadoop任務節點快速訪問較大規模的共享數據的相關問題,以在Hadoop集群中引入Redis分布式緩存的方式,為該類問題提供了一種簡單、高效的解決方案。實驗結果表明,Redis分布式緩存在高并發訪問時仍具有優異的性能,同時還具有擴展性好、使用簡單等特點,這些使得該方案能夠很好地與實踐相結合,解決Hadoop任務中共享數據的訪問問題。
[1] Viktor M S,Cukier K.大數據時代[M].杭州:浙江人民出版社,2013.
[2] 嚴霄鳳,張德馨.大數據研究[J].計算機技術與發展,2013,23(4):168-172.
[3] 王彥明, 奉國和, 薛 云.近年來Hadoop國外研究綜述[J].計算機系統應用,2013,22(6):1-5.
[4] 杜 江,張 錚,張杰鑫,等.MapReduce并行編程模型研究綜述[J].計算機科學,2015,42(6A):537-541.
[5] Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[6] Redis[EB/OL].2016-01-28.http://redis.io.
[7] How fast is Redis[EB/OL].2013-08-20.http://redis.io/topics/benchmarks.
[8] Redis cluster specification[EB/OL].2014-10-09.http://redis.io/topics/cluster-spec.
[9] Rai P,Lal A.Google PageRank algorithm:Markov chain model and hidden Markov model[J].International Journal of Computer Applications,2016,138(9):9-13.
[10] 李遠方,鄧世昆,聞玉彪,等.Hadoop-MapReduce下的PageRank矩陣分塊算法[J].計算機技術與發展,2011,21(8):6-9.
[11] Och F J,Jahr M E,Thayer I E.Minimum error rate training with a large number of features for machine learning:US,2013/0144593 A1[P].2013-06-06.
[12] 胡愛娜,蔡曉艷.基于MapReduce的分布式期望最大化算法[J].科學技術與工程,2013,13(16):4603-4606.
[13] 曾超宇,李金香.Redis在高速緩存系統中的應用[J].微型機與應用,2013,32(12):11-13.
[14] Leskovec J,Rajaraman A.Mining of massive datasets[M].Cambridge:Cambridge University Press,2014.
Application of Redis Distributed Caching Technology in Hadoop Framework
YAO Jing-wei1,YANG Fu-jun2
(1.School of IoT Engineering,Jiangnan University,Wuxi 214122,China; 2.Computational Aerodynamics Institute,China Aerodynamics Research and Development Center,Mianyang 621000,China)
In the scene of large scale data analysis with Hadoop,rapid accessing to shared resources is a typical problem that has not been satisfactorily solved so far.Examples of such problem include page rank algorithm,minimum error-rate training algorithm,expectation maximization algorithm and so on.Although solutions to such problems have existed,the actual effect is not satisfactory.Thus,an open-source distributed in-memory database,Redis,has been explored to provide high-throughput access to shared resources in Hadoop.Experimental results illustrate that Redis has the characteristic of linear increase in throughput with respect to cluster size so that it can provide a general-purpose solution for rapid accessing to shared resources in Hadoop cluster,and that it has provided an easier implementation of algorithms that has not been satisfactorily solved at large scale with Hadoop.Meanwhile,the use of Redis,the commercial-grade open-source tool,implies that the proposed solution has been easily adapted in both research and production environments.
Redis;distributed caching;Hadoop;MapReduce
2016-07-08
2016-10-11 網絡出版時間:2017-04-28
工信部高技術船舶項目(2016[26])
姚經緯(1991-),男,碩士,研究方向為計算機應用技術、軟件工程。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170428.1703.060.html
TP311.5
A
1673-629X(2017)06-0146-05
10.3969/j.issn.1673-629X.2017.06.030
猜你喜歡
小主人報(2022年1期)2022-08-10 08:28:44
新作文·小學低年級版(2021年9期)2021-11-27 07:57:46
學生天地(2020年17期)2020-08-25 09:28:54
作文成功之路·小學版(2020年7期)2020-08-24 08:19:30
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
作文成功之路·小學版(2020年7期)2020-01-02 10:10:44
趣味(數學)(2018年12期)2018-12-29 11:24:10
小學生作文(中高年級適用)(2017年10期)2017-11-13 06:01:00
能源(2016年2期)2016-12-01 05:10:46
故事大王(2016年7期)2016-09-22 17:30:08
