海量圖書檢索中的模糊目標確定技術
2017-07-08 03:46:10張艷菊
現代電子技術 2017年13期
張艷菊

摘 要: 傳統圖書檢索技術如人工檢索和模糊目標確定模型對海量圖書信息進行檢索時,存在檢索效率低和準確性差的弊端。因此,設計一種新的海量圖書檢索模糊目標確定模型,給出模糊目標確定技術的四大優勢,引入讀者相關性概念,利用檢索相關模型和檢索無關模型分別對模糊關鍵詞進行內容檢索,得到兩種與讀者相關性有關的檢索排列結果,選擇兩種結果中模糊關鍵詞性質比重較大的排列順序實現檢索輸出。實驗評估結果表明,所設計的模型檢索結果符合讀者需求,具有較高的檢索性能。
關鍵詞: 海量圖書檢索; 模糊目標確定技術; 排列; 讀者相關性
中圖分類號: TN911.1?34; TP391.3 文獻標識碼: A 文章編號: 1004?373X(2017)13?0137?04
Abstract: The traditional book retrieval technology, such as artificial retrieval and fuzzy target determination model, has the disadvantages of low retrieval efficiency and poor accuracy when it is used to retrieve the massive book information, therefore a new fuzzy target determination model for massive book retrieval was designed. Four major advantages of fuzzy target determination technology are given. The concept of reader relevance is introduced. The retrieval relevant model and query independent model are adopted to perform the content retrieval for fuzzy keywords respectively. Two retrieval arrangement results related with reader relevance are obtained, in which the arrangement sequence with high proportion of fuzzy keyword retrieval property is selected to realize the retrieval output. The experimental evaluation results show that the retrieval results of the model can meet the needs of readers, and the model has high retrieval performance.
Keywords: mass book retrieval; fuzzy target determination technology; arrangement; reader relevance
0 引 言
傳統海量圖書進行目標檢索有兩種人工方式:第一種是為圖書粘貼寫有圖書分類以及內容信息的卡片,由讀者在圖書館中瀏覽選擇;另一種是利用掃描設備進行檢索[1]。兩種方法在索引中都要浪費大量時間,不能給讀者帶來優質的閱讀體驗,在進行海量圖書信息卡片粘貼時成本較高,不利于圖書館長期盈利。信息是人們日常生活中最基本的溝通介質,就業、念書、購物、行路都離不開信息,信息時代的來臨加速了經濟與人文發展,不斷為人們帶來新的生活方式和文化理念。目前,紙質圖書館也漸漸受到信息時代的影響而向智能化方向發展,打破了海量圖書人工檢索的弊端,大大加快了檢索效率。
根據以上情況,使用計算機技術解決傳統檢索方法比較適合信息時代發展。針對海量圖書索引,模糊目標確定技術是很好的解決方法,如文獻[2]所表述的模糊目標確定模型,其檢索范圍大、準確性強,可令紙質圖書變成信息集合體,同時兼具圖書推廣功能。但該模型的檢索關系需要進行改進,這是因為其檢索結果未能依照特定規則進行排列,讀者往往不能快速找尋到所需內容,這樣的檢索相當于無效。因此,模糊目標確定技術還需要對讀者的檢索目標進行條件組合,以求取全面、快速、高質量的檢索能力。
1 模糊目標確定技術
1956年,美國一位數學家率先提出“模糊集合”的概念,其目的是針對一些無法獲取表面含義的事件進行模糊推理,從而令事件具有條理性。之后,模糊目標確定技術在智能控制領域迅速發展起來,具體是指一個針對事件重要信息進行檢索的過程。模糊目標確定技術能夠從檢索關鍵詞中發現模糊關鍵詞,從而拓寬檢索范圍,得到更加全面的檢索結果。如果檢索內容過于復雜,該項技術還可以接受一些比較簡短且模糊的關鍵詞,具備十分強烈的友好性。
模糊目標確定技術可應用在所有關系型數據庫中[3],例如Oracle數據庫,其在檢索關鍵詞“愛”時,模糊目標確定技術先對關鍵詞的定義進行模糊確定,給出“喜歡”、“崇拜”、“愿意”、“友誼”、“享受”等模糊關鍵詞,再采用通用符號對事件中的模糊關鍵詞進行限制。通用符號一般包括四種,即“%”、“_”、“[ ]”、“[^]”,分別代表多字符、單字符、多字符框選、單字符框選[4]。如事件“愛與友誼的建立都是人生中的享受過程”在檢索結果中的鏈接定義為:愛“_”與友誼“%”的建立都是人生中的享受“%”過程。
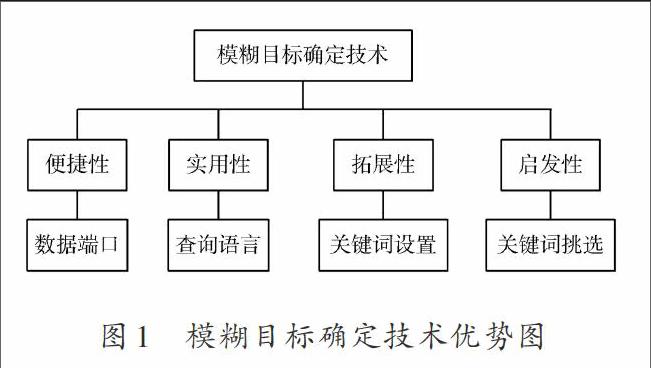
與傳統檢索技術相比,模糊目標確定技術擁有四大優點,即便捷性、實用性、拓展性和啟發性,如圖1所示。便捷性為用戶設置出便于理解的數據端口;實用性表示該項技術實用的查詢語言比較大眾;拓展性指其在模糊關鍵詞的設置上涉及范圍廣泛,詞義靈活;啟發性表示用戶可以在歷史檢索結果中進一步挑選關鍵詞,逐漸實現精準檢索。
2 海量圖書模糊檢索相關性排列模型
2.1 讀者相關性影響因素
相關性是檢索技術中的重要內容,海量圖書檢索的作用是屏蔽無用內容、查詢讀者所需內容。在模糊目標確定技術中,海量圖書模糊檢索相關性表示圖書數據庫的圖書內容與模糊關鍵詞之間的配合程度,其可能是立體動態的,也可能是一維靜態的。
通過分析文獻[2]中模糊目標確定技術的使用弊端,引入“讀者相關性”這一概念,對海量圖書檢索性能進行改進。讀者相關性基本定義式如下:
式中:表示模糊關鍵詞與圖書檢索詞條真實值集合;表示對進行協方差計算;表示模糊關鍵詞與圖書檢索詞條平均值。
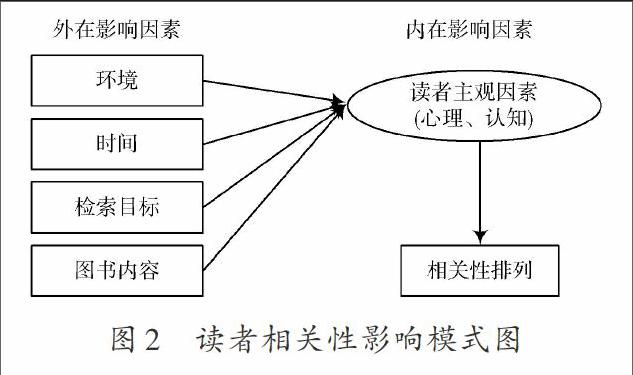
讀者相關性是指模糊關鍵詞與圖書檢索詞條之間的良性配合程度。海量圖書檢索作業中的檢索數據量大,讀者心理變化是連接關鍵詞的重要溝通介質,它受到讀者性格與情緒、圖書館環境、檢索時間、目標定義復雜性等多種因素的影響[5],圖2為讀者相關性影響模式圖。
讀者相關性能夠從側面映射模糊目標確定技術所給出海量圖像檢索結果的真實可信度,由于受到以上因素的影響,讀者相關性在相同的檢索關鍵詞上進行模糊目標索引,所得到的結果是無法一直保持不變的[6],因此,需要使用兩個相關性排列模型綜合兩個模型的結果做出最佳決策。
2.2 檢索相關模型
檢索相關模型負責進行模糊關鍵詞相關內容的讀者相關性排列,使用的是概率檢索理論,這種模型可以對模糊關鍵詞實施量化處理,對讀者相關性的概率定義比較精準,檢索相關模型目標函數如下:
式中:表示檢索相關模型對海量圖書檢索內容的排列結果;表示詞條模型;表示詞條在圖書內的詞條出現頻率;表示圖書內的詞條數量;表示模糊關鍵詞詞條長度;表示第個詞條中關鍵詞的比重;與均表示模糊檢索參數。
可以看出,在檢索相關模型中使用讀者相關性基本定義式并不合適,原因是計算海量圖書檢索詞條平均值需要花費大量時間,故將讀者相關度的表示形式轉化為:
式中:表示平滑參數[7],表示詞條最大頻率。
2.3 檢索無關模型
檢索無關模型采用網頁鏈接形式刪除與模糊關鍵詞無關的海量圖書詞條,并對剩余內容進行讀者相關度排序,此時,讀者相關度排序的計算公式為:
式中:表示非模糊關鍵詞,是圖書詞條出鏈集合;表示阻尼系數;是出鏈數量。
采用檢索無關模型對讀者相關度進行排列,所得結果可以表示為:
式中表示含有鏈接的網頁數量。
可以看出,檢索無關模型的計算量要遠遠小于檢索相關模型,但檢索精度不高[8]。因此,在進行排列結果融合的過程中,仍然以檢索相關模型為主,如果兩種檢索結果的交集為空,則為讀者顯示檢索相關模型給出的結果。
3 海量圖書索引模糊目標確定模型
海量圖書檢索模糊目標確定模型負責將兩種讀者相關性排列模型的檢索結果進行融合。由于兩種讀者相關性排列模型將讀者相關性分為概率相關性和結構相關性,因此在進行結果融合時,需要著重考慮模糊關鍵詞性質比重,模型目標函數可直接表示成模糊關鍵詞性質比重的計算公式。設模糊關鍵詞性質比重為根據式(1),模糊關鍵詞與圖書檢索詞條真實值集合的協方差越大,模糊關鍵詞在某圖書中出現的頻率越高,讀者相關度就越大[9]。如果讀者提供的某個關鍵詞有個模糊關鍵詞,用…,表示,圖書檢索結果用…,表示,其中,每條檢索結果的字節數為字節內容表示為…,那么,檢索無關模型和檢索相關模型中第個模糊關鍵詞在第一個排列結果上的性質可表示為和。
設檢索無關模型和檢索相關模型的某條檢索結果上存在和個模糊關鍵詞,如果讀者的思維情緒確定其索引目標屬于類別則模糊關鍵詞性質比重可表示為:
最佳檢索結果應取檢索無關模型模糊關鍵詞性質比重和檢索相關模型模糊關鍵詞性質比重中的較大值。
為海量圖書檢索模糊目標確定模型的檢索語言進行定義,表示如下:
Opt Form Book List;
FROM Table Book List;
When
Contrast and
Set Up .
其中,表示綜合輸出結果,其滿足。
采用模糊關鍵詞性質比重進行海量圖書檢索結果處理,可以將比重大的結果優先顯示,令檢索輸出更加符合讀者需求,同時過濾掉了與關鍵詞無關的檢索結果,收縮了輸出結果。
4 模型性能測試
4.1 數據處理規則
實驗采用歸一化累積增益評估方法,對文獻[2]中傳統模糊目標確定模型與本文中海量圖書檢索模糊目標確定模型進行評估。歸一化累積增益評估將展示檢索輸出的有效性,其目標函數為:
式中:表示歸一化;表示檢索因子;表示類別的排列位置有效性度量;表示檢索輸出總數。
為一個市級大型圖書館建立Oracle數據庫,實驗將在兩種情況下計算兩種模型的歸一化累積增益評估值。分別設傳統模糊目標確定模型和本文模型的歸一化累積增益評估平均值為和,如果則預示著本文模型的檢索結果更加符合讀者需求。
4.2 對比計算
設置兩個關鍵詞,分別是“2015”和“通知”。傳統模糊目標確定模型與本文模型檢索結果的排列位置有效性度量如表1,表2所示。
設關鍵詞“2015”和“通知”在兩種模型中的歸一化累積增益評估值分別為和計算和值,有:
可知,因此,本文模型的檢索結果更加符合讀者需求,檢索性能高。
5 結 論
圖書檢索是現代圖書館內一項非常重要的工作,好的檢索模型對提高讀者閱讀體驗意義非凡。對此,本文設計海量圖書檢索模糊目標確定模型,其針對傳統模糊目標確定模型的重大弊端進行改進,將不同檢索結果排列模型輸出進行重新組合,在改進檢索效率的同時提高了模型的有效性,使檢索結果更加符合讀者需求。
參考文獻
[1] 劉中.海量圖書關鍵詞特征檢索定位優化仿真研究[J].計算機仿真,2016,33(9):422?425.
[2] 王敏,嵇紹春.基于模糊聚類和模糊模式識別的數字圖書館個性化推薦研究[J].現代情報,2016,36(4):52?56.
[3] 繆豐羽,王宏志.圖結構模糊XML文檔上的模式匹配算法[J].計算機科學,2016,43(11):284?290.
[4] 鄧創,鞠立偉,劉俊勇,等.基于模糊CVaR理論的水火電系統隨機調度多目標優化模型[J].電網技術,2016,40(5):1447?1454.
[5] 黃裕文.基于模糊邏輯的風廓線雷達目標檢測技術[J].現代雷達,2016,38(8):43?45.
[6] 劉文學,梁軍,贠志皓,等.考慮節能減排的多目標模糊機會約束動態經濟調度[J].電工技術學報,2016,31(1):62?70.
[7] 趙安學.海量題庫中的特定數據搜索系統的設計與實現[J].現代電子技術,2016,39(20):49?52.
[8] 魏江來.數據庫模糊邏輯推理中的關鍵信息索引優化[J].計算機仿真,2016,33(8):457?460.
[9] 申艷光,張猛,范永健.面向加密云數據的多關鍵詞模糊檢索方法[J].計算機工程與設計,2016,37(12):3156?3160.
