云計算環境下的海量數據特定特征挖掘技術
2017-07-08 04:31:04蹇旭
現代電子技術 2017年13期
關鍵詞:云計算
蹇旭

摘 要: 針對傳統云端計算過程中的數據特定信息提取不精確的問題,提出一種云計算環境下的海量數據特定特征挖掘方法。采用矩陣節點差分模型進行數據的有序排列,避免傳統方法中的數據混亂造成提取數據不精確,龐大的云端數據量致使數據的定位不精準,為了避免此類問題的產生,使用多維數據定位計算,能夠有效地解決定位不準的問題,最終可以成功的對數據信息進行有效提取。為了驗證設計云計算環境下的海量數據特定特征挖掘方法的有效性,設計了對比仿真實驗,實驗結果充分證明了該方法能夠有效地解決數據提取不精確的問題。
關鍵詞: 云計算; 數據特定特征; 特征挖掘技術; 提取精度
中圖分類號: TN911?34; G420 文獻標識碼: A 文章編號: 1004?373X(2017)13?0178?03
Abstract: For the imprecise data specific information extraction in the process of traditional cloud computing, a specific characteristic mining method of massive data in cloud computing environment is presented. The matrix node difference model is used to arrange the data orderly, and avoid the imprecise extraction data caused by data confusion of the traditional method. The huge cloud data makes the data positioning imprecise. In order to eliminate the above problem, the multidimensional data positioning calculation is adopted to solve the problem of imprecise positioning effectively, and extract the data information successfully. In order to verify the effectiveness of the massive data specific characteristic mining method in cloud computing environment, the contrast simulation experiment was designed. The experimental results fully prove that the method can improve the accuracy of the data extraction effectively.
Keywords: cloud computing; data specific characteristic; feature mining technology; extraction accuracy
0 引 言
隨著科技的快速發展,數據信息時代逐漸向著云時代變遷,數據的運算存儲已經由傳統的硬盤存儲逐漸發展成為云端計算存儲[1]。通過云端的計算存儲已經在很大程度上摒棄了原有的算法規則,能夠更大程度的進行數據統計和數據運算[2]。在使用云端計算的環境下,存儲在云端的海量數據都是通過數據定位以及數據分析進行計算的,使用適當的調度方法可以在很大程度上進行數據的特征提取。所以,有效的數據調度可以充分提高數據的特征提取能力,但是傳統的云端計算過程由于數據存儲量過于繁雜,并且在進行數據定位的過程中需要進行數據識別。傳統的方法是使用數據的屬性進行標識識別,但是為了數據的存儲方便一般會進行適當的數據壓縮和數據轉換,數據進行調用過程中十分的繁瑣,并且數據的調用過程是一個識別提取的過程,這種方式極大地影響了數據特征提取的速度以及準確性[3?4]。在進行數據特征提取的過程中還存在一些數據節點,這些節點極大程度上限制了提取的精度[4?5]。綜上所述,本文設計了一種云計算環境下的海量數據特定特征挖掘方法,該方法能夠有效解決上述問題[6]。
1 運用矩陣節點差分計算方法進行數據特定特
征挖掘
使用矩陣節點差分計算可以提高數據提取的精準度,在計算之前需要進行數據的方位確定以及數據的預處理[7?8]。
式中:為單位下數據信息量;為數據的信息坐標;為提取條件下的屬性條件;為實際的屬性值域。
當限制節點傳輸信息至時,傳輸單位需要經過個節點才能進行屬性提取。關系式為:
保證數據的正確性和快速性是通過區域的劃分得到的,劃分前需要預設參數,通過設定能夠對選擇精度進行控制,避免誤差的產生。
式中:為離散參數;為整合參數域;為區域代理值;表示提取深度;代表數據衡量值。
進行數據的特征提取過程中,使用矩陣節點差分方法,因此需要進行數據的預處理[9],預處理之后才可以使用,首先是數據編續:
經過序號的排列以后,方便數據在大量數據中進行準確提取,但是排序之后的數據不能直接使用,需要一定的調用計算,方便在提取過程中屬性的搭配:
式中:表示單位時間數據能夠調用的屬性;表示實際區域范圍內數據的識別碼;是實際計算中的屬性參數;表示計算常量。
通過上述計算便可以進行矩陣節點差分方程的計算,建立如下矩陣:
通過化簡的公式可以看出數據與實際調用的關系,把公式進行加權處理就可以得到關系公式,這樣可以更加精確的在海量數據中完成特征提取。
限定好實用的屬性參數及屬性目標,進行加權計算:
本文運用矩陣節點差分計算方法進行數據特定特征挖掘,在計算前進行數據的預處理保證了數據的有效性,提高了結果的精準度,最后用條件進行限定保證在大量的數據中能夠進行精準的計算。
2 實驗驗證
為了驗證本文設計的云計算環境下的海量數據特定特征挖掘方法的有效性,設計了對比仿真實驗。選定某網絡數據公司大型云端數據庫進行數據特征提取,首先使用傳統的方法進行云端數據提取,然后使用本文設計的云計算環境下的海量數據特定特征挖掘方法進行數據的特征提取。
2.1 參數設置
為了保證實驗的有效性,同時進行實驗,設置調配參數為65.8;數據坐標分別為150,100;為了保證數據提取的速度,設置為68.5;設置分別為55,60,100。
2.2 數據對比分析
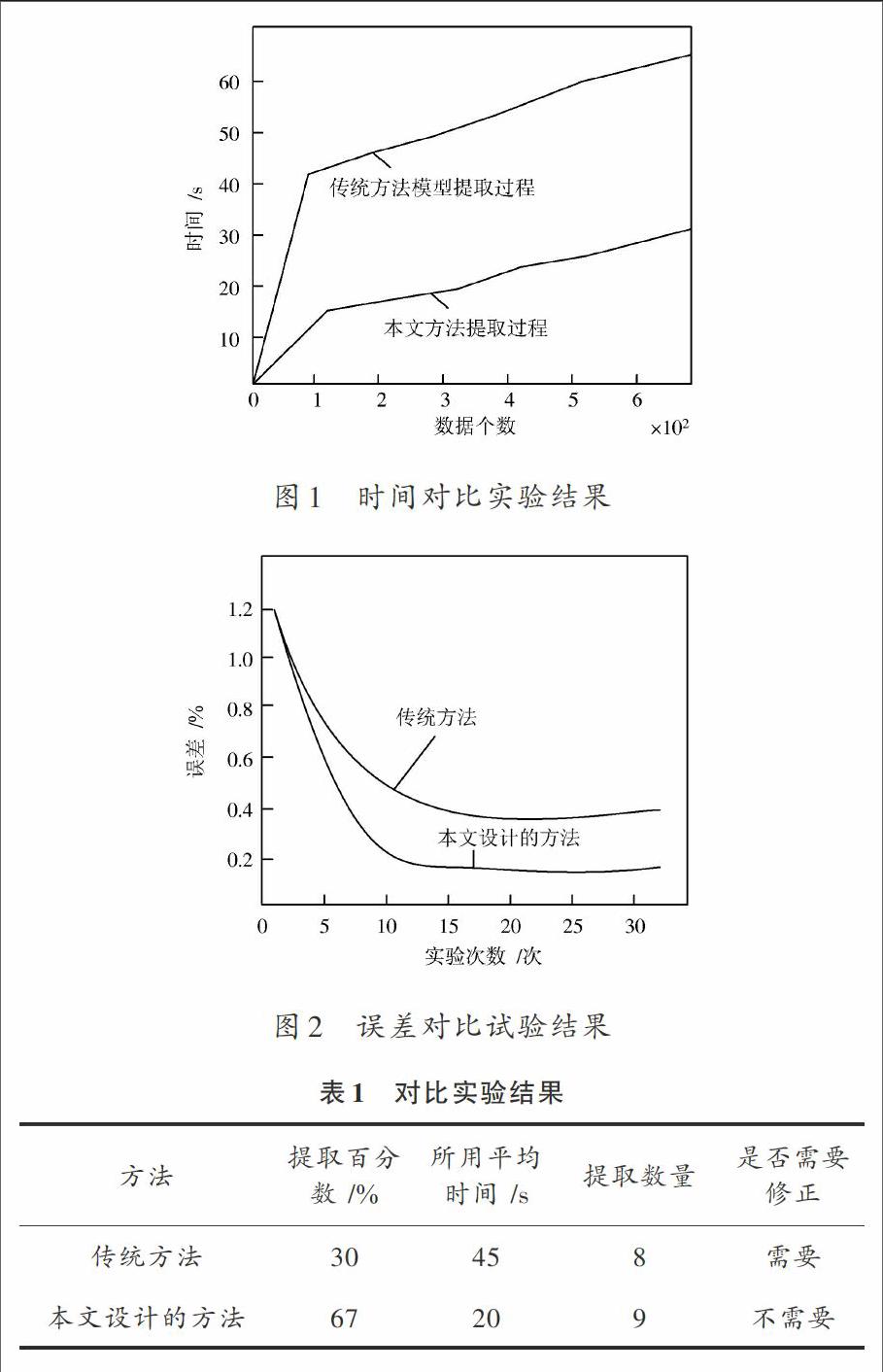
實驗對比結果如圖1,圖2,表1所示。
通過圖1可以看出本文設計的方法能夠在更短的時間內得到結果,同時所用的時間是傳統方法的一半左右。
通過圖2的誤差對比結果可以看出,本文設計的云計算環境下的海量數據特定特征挖掘方法能夠有效地降低誤差,保證在海量數據下的特征提取。
表1的實驗結果能夠充分證明,本文設計的云計算環境下的海量數據特定特征挖掘方法能夠有效地提高數據特征百分比,同時能夠在更短的時間內進行更多的特征提取。
3 結 語
本文設計的云計算環境下的海量數據特定特征挖掘方法能夠有效地解決數據特征提取過程中提取不精確的問題,同時所需要的時間更短,得到的結果不需要進行修正,能夠更好地完成對海量數據的特征提取。本文的研究能夠為云端數據提取提供良好的理論依據。
參考文獻
[1] 廉文武,傅凌玲,黃潮.云計算環境下數據弱關聯挖掘模型的仿真[J].計算機仿真,2015,32(4):359?362.
[2] 盧小賓,王濤.Google三大云計算技術對海量數據分析流程的技術改進優化研究[J].圖書情報工作,2015,59(3):6?11.
[3] 何清,莊福振,曾立,等.PDMiner:基于云計算的并行分布式數據挖掘工具平臺[J].中國科學:信息科學,2014,44(7):871?885.
[4] 劉輝.云計算環境下海量激光點云數據的高密度存儲器邏輯結構設計[J].激光雜志,2016,37(9):91?95.
[5] 白紅偉,馬志偉,朱永利.基于云計算的絕緣子狀態監測數據的處理[J].電瓷避雷器,2011(4):19?22.
[6] 錢維揚,王俊義,仇洪冰.基于Hadoop的數據挖掘技術在測光紅移上的研究[J].電子技術應用,2016,42(9):111?114.
[7] 劉海龍,宿宏毅.利用Hadoop云計算平臺進行海量數據聚類分析[J].艦船科學技術,2016(14):148?150.
[8] 曹建春,李聰.海上軍事海量數據的物聯網數據庫存儲系統研究[J].艦船科學技術,2016(12):175?177.
[9] 任瓊,常君明.基于任務分類思維的云計算海量資源改進調度[J].科學技術與工程,2016,16(12):101?105.
猜你喜歡
數字技術與應用(2016年9期)2016-11-09 22:56:18
數字技術與應用(2016年9期)2016-11-09 00:07:05
知音勵志·社科版(2016年8期)2016-11-05 04:28:47
電腦知識與技術(2016年21期)2016-10-18 23:34:52
電腦知識與技術(2016年21期)2016-10-18 23:24:44
電腦知識與技術(2016年21期)2016-10-18 22:11:15
科技視界(2016年22期)2016-10-18 14:33:46
中國新通信(2016年16期)2016-10-18 10:49:17
大學教育(2016年9期)2016-10-09 08:54:03
科技視界(2016年20期)2016-09-29 13:34:06
