材料數據在材料創新發展中的作用與存在問題的思考
2017-07-18 11:33:33尹海清張瑞杰劉國權鄭清軍曲選輝
中國材料進展 2017年6期
關鍵詞:數據庫
尹海清,姜 雪,張瑞杰,劉國權,鄭清軍,曲選輝,3
(1.北京科技大學鋼鐵共性技術協同創新中心,北京100083)
(2.美國肯納金屬有限公司,賓夕法尼亞州15650)
(3.北京科技大學新材料技術研究院,北京100083)
材料數據在材料創新發展中的作用與存在問題的思考
尹海清1,姜 雪1,張瑞杰1,劉國權1,鄭清軍2,曲選輝1,3
(1.北京科技大學鋼鐵共性技術協同創新中心,北京100083)
(2.美國肯納金屬有限公司,賓夕法尼亞州15650)
(3.北京科技大學新材料技術研究院,北京100083)
材料數據是材料基因組計劃的三大核心工具之一,近年來在國際上引起強烈關注,美國、日本等國相繼資助了大型數據庫建設和數據分析的項目。材料數據的準確性與完整性,是數據分析與挖掘的根本保障,并直接影響材料數據庫的建設以及材料數據價值的深度開發和應用。材料大數據的特征主要表現在材料屬性的高維以及屬性間的復雜關聯關系,在材料數據分析挖掘中應重視與材料領域知識的充分結合,以及離群點分析上的學科特點及需求特殊性。而材料數據相關的基礎教育,尤其是在本科階段數學與計算機相關基礎課程的設置,則成為今后材料數據成為材料創新發展手段的保障。本文就材料基因工程框架下材料數據長久發展進程中目前亟待重視和解決的問題加以討論。
材料數據;材料基因工程;數據質量;數據挖掘;基礎教育
1 前 言
數據在當今時代發展中的作用是不容置疑的,由于計算機和互聯網技術的飛速發展,數字化的信息以及數據傳輸已經成為社會發展的基礎,而數據分析已成為國家安全、經濟發展和風險分析等的重要手段,曾有人預言,支撐數據傳輸的電力系統如果出現全球性的停電,將對人類造成毀滅性打擊。
科學技術的發展決定了一個國家發展的加速度。科學數據包括人文與社會科學數據和自然科學數據兩大不同類別,后者以其專業性強、理論知識抽象復雜等特點,成為很小眾的學科,受眾群體相對少數且集中。國家科技部科技基礎條件平臺中心自21世紀初,支持了一批科學數據平臺建設項目,建設了地理、天文、生物、遙感、醫學、材料等領域的數據庫,其中材料數據庫包括兩大數據庫,即中國腐蝕與防護網和材料科學數據共享網。這些數據庫成為各領域發展與應用的重大基礎資源。2009年發表在科學雜志上的?科學發現的第四范式?[1]中提出,數據科學是繼理論分析、計算模擬和實驗以外的第四種科學發現的范式,將數據正式定義為科學發現的新模式。
美國于2011年6月由總統發布了“先進制造伙伴計劃”,該框架中最為重要的一部分是“材料基因組計劃”(Materials Genome Initiative,MGI),受到全球的關注。材料基因組計劃,在中國又被稱作材料基因工程,是以計算模擬、實驗表征與數據作為三大工具(如圖1所示),基于材料理論,推動材料研發從試錯法向以計算為牽引的創新設計的轉型,以期達到加速材料研發進程、降低研發成本的目標。材料基因組計劃自發布后獲得了國內外材料領域專家學者們的高度關注,美國資助了Materials Project等第一性原理計算相關的以電池材料為代表的功能材料數據庫[2],日本批復了材料信息學的國家級項目“Material Research on information integration”Initiative(Mi2i)[3],我國在過去的五年時間里展開了多次高層次的討論,并推動形成了“十三五”期間科技部等部門的國家重點研發項目的大力度支持。
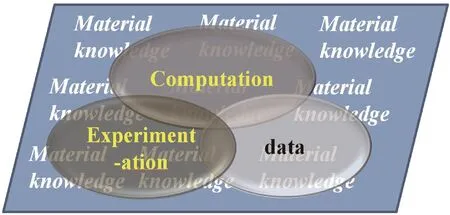
圖1 材料基因工程可以理解為構建在材料知識基礎上的計算、實驗和數據三大工具的創新融合Fig.1 Materials Genome Initiative is the innovative combination of computation,experimentation and data,based on the materials knowledge
目前,材料基因工程被業界大多數學者認識是一種新的方法論。由于材料計算與實驗表征,早已經成為材料研究的兩大基本手段,因此,對于材料數據的研究,被認為是材料基因工程研究的最具可能的亮點。然而,材料數據,就數量而言,尚未達到生物、地理、高能物理等領域的大數據的數量規模,但材料種類眾多,影響因素錯綜復雜,數據關系尚待明確和梳理,本文擬對材料數據的發展及存在的潛在問題進行較為深入的討論,以期進一步明晰材料基因組計劃在材料研發創新思維的實施上的行動方案。
根據材料數據的來源,可分為計算數據、實驗數據和生產數據等3類,數據經過收集整合并存儲于數據庫、數據倉庫及云存儲,并進一步用于數據的應用服務和深加工,其邏輯關系如圖2所示。本文重點討論材料數據及其在應用中的關鍵點或易被忽略之處。

圖2 材料數據及其應用的邏輯關系Fig.2 Correlation between materials data and application
2 材料數據的質量
2.1 數據的準確性
數據的質量是決定數據庫及其應用的根本要素。
目前,大部分材料數據是從公開發表的文章、手冊等收集得來,包括已商業化的無機材料晶體結構數據庫(Inorganic Crystal Structure Database,ICSD)與Pauling file等。盡管正在開展的高通量計算與高通量制備表征的研究在今后會產生自動化流程數據,在今后相當長的一段時間里,收集數據仍是數據來源主流。這就對數據收集者和數據庫的管理提出了很高的要求。
數據的數值超過可能的取值范圍或不合理的數值等明顯錯誤,通過數據庫建設時對數據的規范性約束,在存儲等環節可以被計算機自動識別發現。然而由于數據錄入人員的疏忽等原因造成的數值的非明顯錯誤,對于存有大量數據的數據集,管理者和使用者是難以發現的,至今國際上尚無明確的方法或技術能夠對材料數據庫中大量數據的準確性進行逐一把關或驗證,而此類數據的存在,對今后的數據分析與挖掘的準確性的影響不容忽視。
因此,數據規范的建設,對于不同材料的數據的整合是關鍵而有效的,同時,數據生產者和收集人的知識水平和工作態度是數據庫質量的保證。今后,數據采集的自動化操作,可能成為解決問題的手段之一,但由于目前實驗數據的完整采集,生產環節數據記錄的人工介入,以及計算的跨尺度需要等現狀或問題,可知數據采集的自動化過程尚需時日。
2.2 數據的完整性
數據的完整性指的是一條數據包含的信息的完整性。
材料基因工程的新材料設計、現有材料性能提升以及新工藝的優化,對材料信息完整性的需求是不同的。如以選材和材料替代為目的的數據需求,材料的成分與性能數據是核心,數據來源的可靠性可以成為評價數據質量的有效標準。而以發現新材料為目的的數據需求,則對材料數據的內容的完整性提出了更高要求,僅僅有成分與性能數據是遠遠不夠的,需包括計算的邊界條件和初始條件、模型、算法等,實驗工藝及其詳細參數,表征方法及設備的基本參數指標等。我們基于國家材料科學數據共享網的建設經驗與教訓,制定了?材料數據提交規范?(草案)[4],對計算數據、實驗數據和生產數據所應包括的內容提出了通用格式規范。
數據的完整性與數據的準確性相輔相成,信息缺失的不完整數據在數據清洗中將被過濾掉。一條數據,如果出現信息缺失,那么該條數據的質量是不夠好的,如果關鍵內容缺失,那么該數據的質量將被視為不合格的。只有信息完整,對數據準確性的評價,以及重復性驗證才有可能,正如在眾多領域的實驗研究中形成的共識,即實驗結果如果不能被重復出來,往往結果被質疑,甚至被認為是錯誤或無效的。
2.3 數據的數量與科學覆蓋面
大數據的概念在當今時代已是耳熟能詳的術語了。對于材料數據,其產生途徑難以形成測繪衛星或正負離子對撞機產生數據的規模,在數據量上難以同高能物理等領域的數據量相提并論,但材料數據間關聯關系的復雜性是材料數據能夠被稱之為大數據的核心,同時MGI強調的高通量計算與高通量實驗的發展與應用,將成為材料數據量快速增長的途徑之一。梅宏院士曾指出,真正的大數據應該體現在多源數據的融合,絕不僅僅是數據的“海量”[5]。數據融合與數據倉庫(Data Warehouse)、數據一體化(Data Integration)不同。它的目的不是將一個企業(Enterprise)或組織的所有數據集中在一起并標準化而產生唯一的真相(Single Truth)。它是以產生決策智能為目標將多種數據源中的相關數據提取、融合、梳理整合成一個分析數據集[6]。
除了數據量,材料數據的覆蓋面及其科學性和系統性是影響材料數據分析處理質量但常常為人們忽略的因素。因為如果數據大量集中在某些方面,則會造成盲人摸象的現象,導致分析結果的偏差和應用上的誤導。而數據的科學性和系統性,往往是領域專家才能給出的正確定義和范疇,單純的數據專家是難以勝任的,因此,在材料領域,同其他自然科學領域一樣,領域專家與數據專家的緊密合作,是促進數據成為科學發現第四范式的基礎要素。
綜上,材料數據的質量是數據應用的基礎與根本保證,直接影響數據共享、知識應用及價值提取,其關系如圖3所示。

圖3 數據質量與數據存儲及數據挖掘質量的關系Fig.3 Correlation among the data quality,data storage and quality of material data mining
3 數據分析挖掘的質量
數據分析與挖掘的質量受材料數據質量的影響,并直接影響數據的應用(圖3)。例如基于計算數據的分析,眾所周知,計算往往是對真實環境進行了簡化或特定理想條件下獲得的,如果分析方法或模型選取不當,數據分析時勢必造成誤差的累積,導致數據分析的結果難以令人信服。因此,同計算結果需要實驗驗證的作用相同,材料數據分析挖掘結果的實驗驗證,是今后數據分析人員的工作重點之一。
3.1 數據分析挖掘與材料知識的融合
當數據分析與挖掘方法應用于材料科學領域時,只有基于材料科學的基礎知識、自身特點以及發展規律的數據分析與挖掘,才有可能得出有價值的結果。材料數據的分析早在20世紀就已經應用在不同材料研發上了,但數據量較小,多數來源于實驗室自產數據。
在大數據時代,材料數據量的絕對數值相對較小,但數據間的復雜關系的融入使得在分析和處理過程中需要更多的專業人員的介入,并將相應的關系在分析模型和算法中體現出來[6]。在MGI高通量計算上,Gerbrand Cedar教授[7,8]帶領團隊構建了Material project數據庫,用于電池材料設計,并取得了顯著成果,已發現幾種性能優異的成分。Stefano Curtarolo等[9,10]構建了Aflow數據庫,并以特征值(descriptor)作為篩選的依據,目前,研究中所用的特征值基本是單一參數,而基于多參數組合的特征值的數據分析將是今后研究的方向之一。跨尺度計算是MGI架構下材料計算的研究方向之一,在材料制備過程中,單一工序的參數優化難以獲得系統最終性能的最優,而數據分析與挖掘,是目前研究者正在嘗試的實現跨尺度計算和實驗過程的系統優化的手段與技術。Agrawal A等[11]基于日本國家材料研究所(NIMS)的數據研究金屬材料的高溫疲勞性能,用成分和工藝的數據,采用多項技術來預測鋼的疲勞性能,發現采用神經網絡、決策樹以及多元多項式回歸等技術可以得到較為理想的預測精度。Singh S等[12]利用人工神經網絡與貝葉斯算法等方法,實現了對鋼的工藝過程的參數優化和成分對最終性能的作用規律的揭示。Jae Hoon Jeong等[13]采用降維和線性回歸技術確定了材料成分、中間階段性能和最終性能間的相關關系。
然而對數據含義的理解不足,或數據集選取不當,可能會導致不符合材料科學規律的結果出現。例如Agrawal A等[11]對不同影響因素的重要性分析時得到的一個結論是回火溫度的重要性高于固溶處理溫度,顯然這與材料知識相悖,分析其原因在于,回火溫度較固溶溫度的波動大,而作者選擇了幾種不同材料的數據,回火處理可能是低溫、中溫或者高溫回火,回火溫度相差可達幾百度。
因此,作為材料數據的分析挖掘的第一步,依據材料基本知識對數據集進行初步認識和預處理,是保證分析質量的主要步驟。
3.2 離群點的分析
離群點是指在數值上遠離數值的一般水平的極端大值和極端小值,也稱為歧異值,由于離群值跳躍度比較大,會直接影響分析模型的擬合精度,因此常被認為是壞的數據而在數據清洗中丟棄。然而,材料科學與工程的研究與應用發展到今天的水平,從數據中尋找主流已經難于滿足向國際一流水平前進的需求了,而在一些關鍵點上發現問題并形成突破往往是當前的思路,如對最低值的分析,可以發現問題存在和影響規律、作用機理等。Paul Raccuglia等[14]從失敗的實驗數據中發現了規律,就充分證實了這一點。在材料學科中,關鍵點往往存在于一些離群點上,在微觀組織的圖像分析上尤為明顯,即在相界、晶界和界面等處,在數據分析中為簡化起見,如果直接用一條簡單曲線代替,使原有界面上的信息都丟失了[15]。可見,離群點分析,在材料大數據的分析中顯得尤為重要,可能成為服務于材料優化設計的有效手段。
4 MGI的基礎教育
MGI作為IT和互聯網技術發展下的新的材料研究方法論,具有典型交叉學科的發展特點。MGI對材料計算與實驗表征的融合提出了更高的要求,而兩者在新材料設計開發的時效性的需求下形成的高通量技術,以及鋼鐵等材料生產中設備的數據自動采集功能,則將數據科學引入材料研究和生產中,引導材料研究人員以一種全新的方法來開展研究。可見,MGI要求計算、實驗與數據三者融合,對材料工作者的能力要求顯著提高,沿用原有的教育教學方案已經不能滿足MGI實施的需求。因此應從本科生教學入手,開展相關專業課程的建設,尤其是數據及其分析處理的知識。因為相比材料計算和實驗,數據分析與挖掘是一個全新的課程,尤其對于材料制備加工,將材料成分、組織與復雜工藝相結合,研究變得很復雜,僅憑對單一參數的優化,無法獲得最終性能與工藝的最優方案,而基于數據的分析可以考慮多個參數的作用,形成一個全局性的解決思路。
在課程的設置上,加入數據分析與挖掘的內容,不僅要考慮數據處理技術,而且需要這些技術在材料或相關科學中應用的示例,使之真正成為一門數據挖掘技術在材料科學中的應用課程。同時因為數據分析與挖掘技術大量涉及計算機和數學等方面的知識,相應地在這些基礎課程的學習過程中需要加大難度。
在授課教師的選拔和教師隊伍的建設上,需要一支具有交叉學科知識、勇于創新精神、肯于和善于不斷學習新知識新技術的人才隊伍。不同于金屬結構材料計算中多尺度計算的跨層次的要求,也不同于功能材料的第一性原理計算結果的單一參數作為判據的篩選,材料數據的分析與挖掘作為一門相對獨立的方向時,由于數據的生產途徑和代表的含義不同,其研究內容覆蓋了幾乎材料研究的所有內容,即成分、工藝、組織、性能及服役等材料五要素間的復雜關系和交互影響。
因此,作為一個全新的材料研究方法論,材料基因工程的基礎教育開展的難度是不容忽視的,但其意義重大,關乎材料創新發展的步伐。抓住信息時代的機遇,培養能夠滿足時代需求的材料人才,是材料基因工程得以長期發展的關鍵基礎設施。
5 存在的問題與展望
材料基因組計劃與大數據計劃在美國的相繼提出,催生了中國的材料基因工程熱,繼而出現材料數據熱,使材料數據的發展獲得了新生。然而,對于材料數據的理解和材料大數據的理解,仍處于初級階段,甚至對于數據的整合和數據庫的建設,仍理解為一件很簡單的事,使得在材料數據庫的建設初期,就出現因材料專家對數據庫專家的過高且不現實的要求而導致工作進程推動緩慢的情況。因此,個人觀點認為,對材料數據存在虛熱,需要等待降溫后留下的一批真正熱愛材料數據的人,將材料數據扎實而穩步地開展下去。
材料數據的整合是數據挖掘的基礎,而挖掘是數據儲備后的延伸工作。目前數據分析與挖掘技術在應用于材料科學領域時,需要與材料理論知識以及現有發展成果相結合,在方法選擇和建模等步驟中都要將材料已有成果抽象化進行考慮。這就需要材料學科專業人員的大量介入和對數據分析處理的知識儲備。然而,由于目前基礎教育尚未跟進數據時代的發展,導致一個較為普遍的情況是材料與數據分析人員的需求無法對接,材料專業人員在數據分析上的知識匱乏導致雙方的協同難以盡快推進。
材料數據的發展不是孤立的。數據來源于材料計算模擬和實驗表征,本身被賦予了材料的含義及其與其他知識與數據的復雜關系,材料數據最終將成為材料知識的載體,成為新材料發現和發展的基礎和手段。以需求出發的材料知識的抽象化和數字化可能成為今后的發展趨勢之一。
6 結 語
依托于大量材料數據庫資源和不斷激增的數據,對材料數據的研究和分析挖掘正在成為新的材料研發模式。包括數據準確性和完整性的材料數據質量,以及基于對材料知識充分理解的材料數據的分析挖掘的質量,是決定材料數據作為研發新模式的發展進程的關鍵。材料數據分析挖掘要求材料知識與計算機和數學知識的高度融合,從本科生的基礎教育抓起,才能保證新的研發模式的充分應用和可持續發展。
致 謝 本研究得到了國家科技部科技基礎條件平臺建設項目“材料科學數據共享網”(2005DKA32800)、國家高技術研究發展計劃(“863”計劃)“基于材料基因工程的高性能材料設計、制備與表征技術”(2015 AA034201)、國家重點研發計劃項目“材料基因工程專用數據庫和材料大數據技術”(2016YFB0700503),北京市科技計劃項目(D16110300240000)以及美國肯納金屬有限公司的支持。
References
[1] Hey T,Tansley S,Tolle K.The Fourth Paradigm:Data-Intensive Sci-entific Discovery[M].Washington:2009:109-130.
[2] The White House.[EB/OL].[2016-08-01].https:// www.whitehouse.gov/blog/2016/08/01/materials-genome-initiative-first-five-years.
[3] Austin T.Materials Discovery[J],2016(3):1-12.
[4] 材料科學數據共享網[EB/OL].(2016-07-01)[2017-01-10] http://matsec.ustb.edu.cn/uploadFiles/shujutijiao.pdf.
[5] Nosengo N.Nature[J],2016,533:22-26.
[6] Jain A,Persson K,Ceder G.APL Materials[J],2016,4(053102): 1-14.
[7] Jain A,Ong S P,Hautier G,et al.APL Materials[J],2013,1 (1):011002.
[8] Richards WD,Tsujimura T,Miara L J,et al.Nature Communications [J],2016,7:11009.
[9] Curtarolo S,Hart G L,Nardelli M B,et al.Nat Mater[J],2013(12): 191-201.
[10]Perim E,Lee D,Liu Y,et al.Nat Commun[J],2016,7:12315.
[11]Agrawal A,Deshpande P D,Cecen A,et al.Integrating Materials and Manufacturing Innovation[J],2014,3:8-26.
[12]Singh S,Bhadeshia H,MacKay D,et al.Ironmak Steelmak[J],1998 (25):355-365.
[13]Jeong J H,Ryu S K,Park S J,et al.Computational Materials Science [J],2015(100):21-30.
[14]Raccuglia P,Elbert K C,Adler P D F,et al.Nature[J],2016 (533):73-77.
[15]Rajan K.Informatics for Materials Science and Engineering[M]. Elsevier Inc.,2013:21-23.
(編輯 惠 瓊)
Role of Materials Data in Materials Innovation Development and Thoughts on the Existing Problems
YIN Haiqing1,JIANG Xue1,ZHANG Ruijie1,LIU Guoquan1,ZHENG Qingjun2,QU Xuanhui1,3
(1.Collaborative Innovation Center of Steel Technology,University of Science and Technology Beijing,Beijing 100083,China)
(2.Kennametal Inc.,Pennsylvania 15650,USA)
(3.Institute for Advanced Materials and Technology,University of Science and Technology Beijing,Beijing 100083,China)
The materials data is one ofthe three key tools in materials genome initiative(MGI),which has been attrac-ting great attention worldwide.Projects on large scale databases construction and data mining have been implemented in US,Japan and other countries.The accuracy and integrity ofthe materials data are the foundation ofdata analysis and min-ing and they willdirectly influence the quality ofdatabase construction and deep extraction of the data value.The main fea-tures of materials data are high dimensions of materials attributes and complex interactive relationships.It?s worth noting that the data mining should be associated with domain knowledge of materials and the typical requirement of materials on the outlier analysis.Education on materials data and related disciplines,especially the college education on math and IT technology,will be the basic guarantee for the data being as the paradigm of innovation.The problems to be settled con-cerning the long term development of materials data were discussed in this paper.
materials data;materials genome initiative;data quality;data mining;college education
N37
A
1674-3962(2017)06-0401-05
2016-12-08
科技部“863”計劃項目(2015AA034201);國家重點研發計劃項目(2016YFB0700503);北京市科技計劃項目(D16110300240000)
尹海清,女,1971年生,教授,博士生導師,Email: hqyin@ustb.edu.cn
10.7502/j.issn.1674-3962.2017.06.01
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
