科學數據使用統計應用及關鍵流程研究
2017-08-25 04:15:03丁培
現代情報 2017年7期
關鍵詞:評價
丁培
[摘要]科學數據使用統計是科學數據使用計量的重要構成,是科研學術評價的重要參考依據。對比三類數據使用計量的效果及應用難度,文章認為使用統計計量有良好的可信度和可操作性。在梳理研究現狀基礎上,文章分析數據使用統計的利益相關方,結合數據自身特點,總結流程,并重點闡述數據收集、規范、清洗、報告等關鍵流程問題,最后提出思考與建議。
[關鍵詞]科學數據;數據計量;使用統計;評價;在線電子資源使用統計
科學數據是現代科學研究的基礎支撐之一。它既是科研產出的重要內容,也是后續科學研究、科研創新的基石。近年來,學術界日漸重視科學數據的公開、共享以及重用。科研機構在數據長期保存、數據監護、科學數據開放及數據出版等方面取得諸多實質性的進展。科研人員也逐漸關注科學數據共享及重用所產生的價值,他們關注自己的數據被誰使用,自己的數據價值多高,使用他人的數據是否可靠等問題。科學數據的使用績效和影響評估已成為推動科學數據公開、共享以及重用的重要助力。
績效分析與影響評估包括定性與定量兩個方面,數據的使用計量則是定量分析的基礎。目前,科學數據的使用計量分三類,分別是科學數據的引用計量,科學數據的使用統計以及科學數據的替代計量。它們從不同角度計量科學數據的使用,并提供多樣化的數據以便評估。本文關注科學數據使用計量中的使用統計部分,梳理現狀,分析關鍵問題,并探討如何利用它為機構、學者、科學數據提供商、圖書館等角色提供科學數據的使用績效評價。
1科學數據使用計量
現有學術評估體系中,科研人員傾向于認可數據引用和數據下載作為科學數據的影響評價指標。研究數據聯盟(Research data alliance,RDA)文獻計量學小組的調查發現,研究人員認為評價數據影響力的前三個指標分別是數據引用計量、數據下載和同行評議文章中被提及的數量,社交媒體、博客等使用排序靠后。2014年的另一個在線調查中,95%的研究人員表示引用或者正式出版是獲知自己數據影響力的最佳方式,而60%左右的研究者認為數據下載量也是反映自身數據影響力的重要方式。
引用是傳統科研學術評估體系中的重要一環,在科學文獻領域廣泛應用。作為文獻領域中成熟的影響力評估數據,引用計量在科學數據影響力評估中也獲得優先考慮。科學數據引用計量是三類使用計量中最早進入研究,也獲得最多關注。文獻方面,幾乎所有關于科學數據評價計量的文獻都會涉及引用計量,研究角度包括引用規范、引用行為研究、引用評價模型等。實踐上,Datacite、英國數據監護中心(The Digital Curation Centre,DCC)、ESIP、RDA、英國聯合信息系統委員會(Joint InformationSystems Committee,JISC)等機構對數據引用標準、引用原則、引用應用等方面進行研究實踐。Springer、Nature,Elsevier等出版商也在生物醫學領域開展數據引用試點項目,獲得了許多的一手數據。
盡管數據引用計量被認為是最權威的評估數據來源,然而數據引用計量的廣范圍應用存在四大障礙。第一,鑒于數據出版成本高、出版流程不完善及研究者缺乏出版動力,科學數據公開出版還不具備廣范圍實施的條件;第二,盡管DataCite、PANGAEA、Dataverse、ICPSR、中國西部環境與生態科學數據中心、冰川凍土科學數據中心、基礎科學數據共享網等重要學術組織、數據倉儲和研究機構都提出了相應的科學數據引用和著錄標準,但世界范圍內缺乏統一的科學數據引用標準;第三,數據引用行為匱乏,許多作者在數據二次分析時不標明數據引用;第四,數據倉儲商對科學數據引用的不重視。Making Data Count項目調查了71個科學數據倉儲庫,結果顯示僅有23%的倉儲追蹤數據引用。
數據下載是科研人員認可的另一大計量數據。它是數據使用統計的主要構成之一。NISO定義數據使用是用戶訪問以及下載一個公開出版的數據集的行為,其統計范圍包括數據的下載、數據訪問、數據集標注等。相比引用計量,科學數據的使用統計計量具有預先、直觀的特點。預先性指我們可以在數據正式被引用發生前就洞悉數據的可能影響,而直觀性表現為我們能夠從數據的瀏覽或者下載直觀了解數據或者數據集受歡迎和關注的程度。此外數據使用統計比引用更為廣泛。John等調查71個數據倉儲,發現90%的倉儲提供數據下載統計,僅有23%的數據倉儲引用獨立數據集,20%的引用將數據倉儲作為整體引用。由此看出,數據使用統計比數據引用計量更具可操作性。但使用統計數據并不能完全反映出數據本身質量的問題。數據使用統計具有來源復雜、數據量龐大的特點,尤其需要在統計來源、數據清洗、數據標準等方面進行大量工作,本文第三部分將對這些內容詳細闡述。
替代計量學是文獻計量學領域的新寵。它作為傳統引用計量的補充,主要關注學術資源的網絡使用。科學數據的替代計量學內容和文獻的替代計量學內容區別不大,主要統計對象包括科學數據的社交媒體提及、評論、訪問等。近年來也有部分研究探索科學數據的替代計量模型。如NISO的替代計量小組將計劃研究科學數據的替代計量方式。雖然替代計量學的研究在持續增加,但由于缺乏標準化的數據集以及數據統計來源,其應用的普遍性受到限制。
目前而言,數據引用、數據使用及數據替代計量尚未形成完整的評估體系,其中數據引用和替代計量受制于數據來源較少,短期內無法普遍適用。而科學數據的使用數據一直存在于數據倉儲的日志中,獲取難度低,其評價績效的效果也得到科研人員的肯定,因此,利用科學數據的使用數據來幫助評價科學數據的影響力具有可行性。
2數據使用統計研究現狀與實踐
科學數據作為科學研究的另一個重大產出,其成果管理、利用、評估的發展路線基本上遵循科學文獻的模式。科學數據早期作為科學文獻的附加材料,僅僅在保存和數據驗證上發揮作用。伴隨著科學數據日漸受到科研機構、科研人員的重視,科研數據的使用統計也得到關注。
倉儲機構及數據中心是最早利用科學數據使用統計的主體之一。它們基于使用統計數據評價科學數據的傳播和推廣的力度。隨著科研人員反思引用作為學術評價計量指標的單一性和絕對性,利用使用統計評價學術影響的研究逐漸興起。Bollen等提出基于使用且覆蓋整個研究過程的影響計量方法,計量內容涵蓋引用、發現、下載、同行評議郵件數、閱讀以及保存等。Fear指出學術數據集的評價計量不能依據單一指標,應多因素考慮,如數據引用計量、二次影響(如G指數)、數據重用的學科廣度以及數據下載量。
2009年,Chavan等提出數據使用索引(Data usageindex)是數據出版框架中三大技術基礎設施之一,其統計指標涵蓋訪問、下載頻率、下載量、使用度等。這是學術界第一次正式提出數據使用統計,并將其作為單獨對象進行研究。GBIF數據出版工作組進一步細化數據使用索引中指標的統計及用途,提出利用下載、檢索、記錄數量、數據集數量等數據可以計算出數據使用影響、興趣影響、使用率、使用評分等評價指標。Rodrigo Costas(2012)提出數據計量的概念,認為數據使用統計也是計量的重要組成。NISO報告認同研究數據使用統計是重要評價衡量,建議研究數據共享平臺(包括數據倉儲)為研究數據使用統計建立標準和最佳實踐。國內目前主要關注科學數據引用對數據影響評估的作用,尚未對專門研究數據使用統計,僅在科學數據共享平臺績效評估指標中提及或科學數據出版環境中建議包含使用統計的科學數據評價指標。
國際上已有多個項目對科學數據使用統計進行研究和實踐。如研究數據聯盟下的數據出版計量小組正在研究如何對數據計量概念化;NISO的替代計量指標小組考慮將替代計量指標擴展到非傳統的軟件或科學數據;JISC資助的數據計量項目準備基于COUNTER標準進行數據使用計量實踐;由NSF資助,加州數字圖書館、PLOS和DataONE共同參與的Making Data Count項目創建了一個數據計量的試點網站。
3科學數據使用統計流程及關鍵問題
3.1科學數據使用統計的利益相關方
3.1.1數據提供者
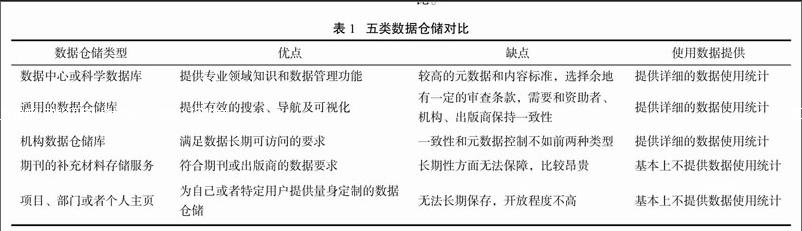
數據保存是數據使用的最基本前提。使用統計數據最主要的來源是數據倉儲。英國數據監護中心DCC將數據倉儲分為公共獲取的科學數據倉儲數據中心或科學數據庫、通用的數據倉儲庫、機構數據倉儲庫、期刊的補充材料存儲服務、項目、部門或者個人主頁五類。表1對這五類數據倉儲的優缺點及使用統計數據提供的力度進行對比。
可以看出,機構倉儲、數據中心、通用的數據倉儲庫是科學數據使用統計的主要數據提供方。從供應方的角度,使用統計能直觀的了解其資源的利用情況,為后續資源推廣、用戶行為分析、資源個性化加工、提供數據分析服務奠定數據基礎。
3.1.2數據消費者
科研人員、科研機構、學術資助機構既是統計數據產生過程中的數據使用者,也是使用統計數據消費的主體。科研人員可利用科學數據使用統計幫助評估個人科學數據的受關注程度,利于開展同行甚至是跨行業的科研合作,有條件的情況下,還可將其作為自身科研績效評價的一項佐證數據。科研機構可以利用使用統計數據評估機構的學術影響力和傳播范圍,還可以基于數據分析熱點活躍的學科及主題,進行針對性的學科建設。使用統計數據還可以作為機構特色科學數據資源建設的依據;對于學術資助機構而言,國外許多機構,如美國自然科學基金會(NSF)、英國人文研究委員會(AHRC)等機構要求科研人員在項目中提交科學數據的倉儲及管理計劃,而科學數據的使用統計可以作為資助成果績效評價的一個參考。
3.2科學數據使用統計流程
科學數據的使用統計并非簡單的數字統計,而是一個完整的數據分析流程。它涵蓋了數據準備、數據采集、數據清洗、數據規范化、數據分析及報告以及最終使用統計數據報告應用等一系列流程。數據和文獻同作為科學研究的產出,在成果保存、傳播及共享等方面有諸多相似之處,因而其使用統計在流程和方法上也類似。然則科學數據缺乏成熟共享的傳播模式,加之其具備分布式倉儲、表現粒度不一、缺乏統一描述及應用標準等特點,所以數據的使用統計也需具體情況具體分析。
3.2.1數據準備
數據采集的穩定性和可靠性關系到最終數據應用的效果。無論是數據引用、數據使用或者是數據的替代使用,都需要保證數據來源的可靠、穩定以及效率。數據的使用統計需要在以下方面進行準備。
首先是使用統計數據的可信度。數據中心、通用數據倉儲以及機構數據倉儲庫,擁有較完善的數據提交審核機制,提供數據的元數據描述,還基于唯一數據標識符追溯數據來源,可以保證數據的穩定獲取,是合適的使用數據來源。
其次是數據版本。區別于文獻,數據具有多版本的特點。例如研究者提交一份數據后,后續新的研究對原有數據進行了增改刪除,新的數據是原有數據的高級版本。此種情況下,數據的版本控制需要發揮作用。版本控制前需要明確一個問題,即同源數據不同版本是屬于一個還是多個處理對象?現有的數據管理實踐將科學數據的不同版本認定為原始數據的升級,作為同一個對象處理,同時保留數據的版本信息。例如UK DATA ACHIVE、Leicester大學的數據倉儲實踐。因而我們建議在數據命名上體現出版本信息,采用唯一標識符定位數據,跟蹤數據保存位置,并在統計數據使用量時,將同源數據集的不同版本在不同平臺上的使用量歸一。此外我們也可借助版本控制工具,在數據庫中對科學數據進行版本化,并基于算法和工具來追蹤數據版本。
第三是數據粒度。湯森路透(Thomson Reuters)公司的數據引用索引DCI將科學數據粒度劃分為三個層次:數據倉儲,數據研究,數據集。數據倉儲是數據的實際存儲地,包含數據研究和數據集。數據研究是指某一項研究或者實驗中產生的一系列關聯的數據集合,通常包含若干數據集,可根據項目或主題分類。數據集是DCI中的最小單元。也有研究關注更細粒度的科學數據。如數據使用索引以文獻數據作為基準,把科學數據統計粒度分兩層:第一層是數據集,相當于期刊;第二層是數據集的記錄,相當于期刊文章。
原則上,數據統計的粒度越細越好,然而在實際操作中,數據倉儲范圍太大,數據研究適用性較窄,數據記錄則由于不同數據倉儲或數據中心對數據記錄的定義不一致,導致統計困難。目前科學數據的數字標識主要集中數據集層次,異構數據倉儲中對于數據集的定義和描述相比更為統一,因而在數據集粒度層進行使用數據的統計更具有效率。
第四是數據標識符。持續獨特的標識符可以永久保證一個數據集甚至是一條數據記錄獨立、唯一的位置,它在保證數據的可訪問性以及重用性上有著非常重要的作用。同時在數據使用中,應用數字對象唯一標識符可以合并不同版本的同源數據使用以及同一數據在不同的數據倉儲中的使用。目前國際范圍內有多種數字對象標識符應用,如Digital Object Identifiers(DOIs),Archival Resource Keys(ARKs),Persistent Uniform Resource Locators(PURLs),Uniform Resource Names(URNs),Life Science Identifiers(LSIDs)等。其中DOI應用范圍最廣,也得到許多機構的承認。
3.2.2數據采集
倉儲平臺的兩種主流使用數據采集方式是日志文件和頁面標簽。
日志文件記錄了所有記錄的原始使用情況,涵蓋各種類型的訪問,訪問來源、響應情況、IP地址等,內容詳細但瑣碎。因而日志文件需要清洗和轉換后才可作為使用統計來利用,轉換過程中還涉及日志數據和統計標準對接的問題。日志數據可以直接在數據倉儲平臺下載,或借助協議自動、定時采集。下載方式直接簡單,但面對多個平臺使用日志時,用戶或者機構需要手動搜集、保存和整理使用日志,這樣的方式復雜、低效。協議收割方式可以解決多平臺數據自動采集和統一處理,是最理想的數據收集方式。
頁面標簽方法是在每一個頁面上使用JavaScript,當頁面被瀏覽器訪問時,JavaScript將通知第三方服務進行統計。
這兩種數據采集方式各有長短。日志統計方式不需要額外改造網站和查詢DNS,因而不會增加服務器的負擔,但其數據噪音大,無法直接去除無效訪問和網絡爬蟲訪問等;頁面標簽方式在數據噪音處理上優于日志,日漸成為網絡分析的一個標準。它允許第三方服務訪問網絡服務器,以頁面激活打開作為計數,并非以請求作為依據,可排除未響應請求和爬蟲請求,但是其不能追蹤下載完成事件和搜索引擎蜘蛛,對服務器負擔大。
科學數據的使用統計具有跨平臺、海量的特點,在內容豐富化,實時性和標準化上有較高的要求。因而經過標準化清洗并且可以自動收割的日志方式是優秀的解決方案。標準化清洗可基于標準進行,自動收割則需要標準化的數據交換和采集協議。SUSHI(Standardized Usage StatisticsHarvesting Initiative,標準化使用統計收割協議)是由NISO發起的項目。它是一個請求數據的網絡服務模型,可以實現通過一個XML框架將使用數據在不同的系統中自動傳遞。SUSHI協議解決了符合COUNTER規范的使用統計報告自動收集及跨平臺雙向傳遞的問題。但是國外的實踐也只是解決了SUSHI自動收集符合COUNTER規范數據的問題。
3.2.3數據規范
使用統計的最大障礙在于缺乏對下載、瀏覽等統計的標準。只有規范化的數據,才能相互比較并發現資源的價值。
在線電子資源使用統計(Counting Online Usage ofNetwork Electronic Resources,COUNTER)是規范電子資源使用統計報告數據處理、審核和提交的國際化標準,于2002年由高校、出版界和中間商共同發起,其統計報告解決了使用統計數據的統計標準和格式的一致性問題,并對數據庫、電子期刊、電子圖書和參考文獻的統計格式分別進行了規定。目前已經被數十個數據庫商所支持,還有多個基于COUNTER標準的使用數據分析平臺。科學數據的使用統計缺乏規范,鑒于文獻和數據的同源性,部分研究實踐嘗試利用COUNTER標準規范科學數據的使用統計。例如JISC的數據計量項目與IRUS-UK合作嘗試基于COUNTER統計數據集使用;Making Data Count項目組對150000個數據集進行了COUNTER規范的統計實驗;NISO的替代計量指標小組的報告中建議基于COUNTER標準并考慮特殊情況對科學數據使用進行統計。
科學數據使用統計借鑒COUNTER規范益處良多。首先它可以利用COUNTER標準在數據清洗、數據標準化、數據審核、標準化報告格式方面的豐富經驗。其次,SUSHI和COUNTER已經建立了一套完整的數據交換方式,基于兩個規范可以實現標準化使用數據的自動收集。
但是COUNTER標準應用于科學數據還存在一些問題。如COUNTER標準中未定義科學數據資源類型,所以沒有對應的使用統計報告;COUNTER對機器自動獲取的數據實行完全過濾,這在科學數據使用統計中不可取。
3.2.4數據清洗
通過日志或頁面標簽方式獲取原始的使用數據后,我們需要清洗和處理數據。這些處理包括對數據分類、識別有效的使用等。
數據分類主要是對數據使用的用戶分類,可以參照IP地址、機構用戶、個人注冊用戶等類型對使用數據分類。
在COUNTER規范中,使用數據的有效計數有嚴格規定,如只計算成功和有效的請求、HTML格式鏈接上間隔不足lOs的雙擊只計數一次、PDF格式鏈接上不足30s的雙擊只計數一次等。但是COUNTER規范并非完美。如COUNTER并未定義檢索行為是服務器端響應還是用戶端實際接收完整結果。但實際操作中多數以服務器端響應來進行統計,未考慮用戶是否成功接收到數據,也未明確定義服務器端會話不完整和用戶自行點擊取消下載情況如何計數。
科學數據的使用與電子資源使用有一明顯區別,即利用APIs或者爬蟲等所產生的使用應計入科學數據的使用統計。COUNTER針對電子資源使用,專門提供一個附錄記錄已知的集成和自動搜索引擎列表以及網絡機器人、網絡爬蟲、網頁、爬蟲等列表,并在頭標區中設有參數來排除非人下載以及消除同一個機器的重復下載。這并不適合科學數據的使用統計。因而NISO建議采用兩種方式統計科學數據下載,一種針對人類使用,另一種包括合法的機器訪問和下載,可以通過白名單的方式,保存合法的機器訪問數據。
3.2.5數據分析和報告
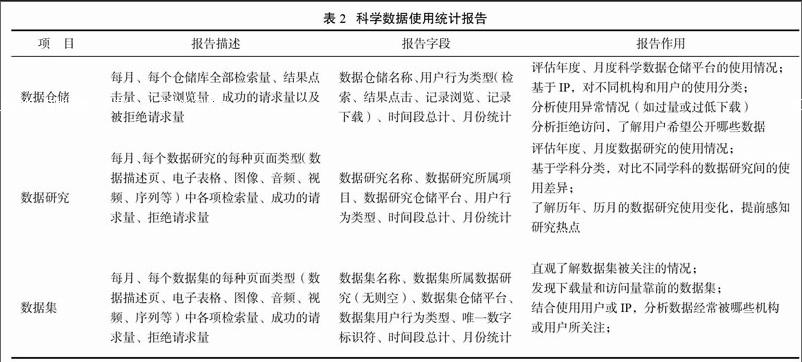
收集、清洗和規范化使用數據,其最終是為了分析數據,以幫助科學數據提供和使用的各方來評價科學數據的效果和價值。
基于數據集的使用統計數據,科學數據使用統計報告可從數據倉儲、數據研究以及數據集三個維度展示。表2參考COUNTER規范,結合科學數據存儲和使用方式,大致對科學數據的使用數據報告的內容和字段進行說明。
4思考與建議
4.1重視對科學數據使用統計
隨著科學數據共享和開放程度提高,科學數據的使用績效評估日漸受到重視。鑒于引用在學術評價中正的重要地位,科學數據引用的機制、行為、規范等內容得到廣泛關注。而科學數據使用統計作為第一手評價數據,關注明顯少于引用。
事實上,使用統計數據比引用數據更容易獲取,有廣泛的基礎數據來源。一手的使用統計可以直觀了解數據資源使用情況、追蹤和分析用戶使用行為、檢驗科學數據倉儲商的服務品質,還能夠快速反映出科學數據領域內的研究熱點,甚至可以基于使用數據來測量學者的學術影響力。已有多個學者研究發現學術資源下載和引用問存在很強的正關聯。因此科學數據倉儲平臺、研究機構、科研資助機構以及研究者都要重視科學數據使用統計。
科學數據倉儲平臺應該積極探索、解決科學數據使用統計實際操作過程中的技術問題,例如為科學數據分配機器可讀的永久標識符、創建科學數據的登錄頁面、使用數據下載接口提供等,并且致力于為用戶提供基于標準(例如COUNTER)的使用數據報告,多角度、多層次的分析用戶使用行為。
科研資助機構和大學等學術機構應該積極鼓勵研究者制定詳細的科研數據管理計劃,并鼓勵他們將科學數據保存到合適的數據倉儲庫中。同時,學術機構可以考慮將數據使用統計引入到學術績效評價或職業獎勵結構體系中,這樣有助于使數據共享與數據發布成為學者常規工作中的重要活動,激勵數據共享。
科研人員應該重視科研數據的長期保存,建立良好的數據管理計劃,共享科學數據,主動利用科學數據使用統計,積極從中尋找合作機會。
4.2科學數據使用統計標準建設
只有遵循規范,才能產生一致性的數據,才能合理分析數據。現行背景下尚未有專門的科學數據使用統計標準,這是使用統計應用過程中的最大障礙。標準的制定是一個復雜的過程,它需要多方參與,并且可以用于指導實踐。COUNTER標準是一個成熟的學術電子資源使用統計規范,其在使用數據收集、清洗等處理過程、標準化的統計報告的經驗和大量數據庫商與圖書館推動的COUNTER實踐都能夠在科學數據使用統計應用過程中提供有力指導。
我們建議標準制定機構、科學數據倉儲平臺及科研資助機構通力合作,以COUNTER規范為基礎藍本,結合科學數據使用的獨有特點,制定合適科學數據的COUNTER報告規范。科學數據倉儲平臺也可以自主探索并實踐新的科學數據使用規范。同時需要將數據倉儲商納入到SUSHI注冊商體系內,確保可以基于SUSHI協議自動傳遞標準化的科學數據使用統計報告。
4.3建設統計平臺
使用統計平臺是一站式的收集、集成、瀏覽、下載、保存及分析利用數字資源使用統計數據門戶。借助SUSHI協議,統計分析平臺定期從不同的數據倉儲平臺中自動收集標準化的使用統計數據,并整合數據。統計平臺可以對統計數據長期保存,即使源數據已經被刪除。基于標準化的報告,統計平臺為科學數據使用中參與各方提供豐富數據報表,例如倉儲庫訪問的年、月度變化,國家下載排名、機構下載排名、熱點學科科學數據下載排名等。
目前已經有使用數據統計平臺在嘗試科學數據使用計量分析。IRUSdata-UK是代表之一。IRUS-UK是JISC資助的國際服務,為機構提供機構倉儲內容的使用統計,并提供基于COUNTER標準的可對比統計報告。IRUSdata-UK項目是IRSU-UK項目基礎上針對科學數據集的使用統計數據分析項目。該項目與UK Data Service等15個科學數據倉儲(類型涵蓋EPrints,DSpace和Fedora等)合作,利用倉儲自身后臺日志文件,統計數據集級別的科學數據下載,基于COUNTER標準,過濾噪音內容(多重點擊、不完全下載、網絡機器人反復隨機下載鏈接等),最后分析使用績效。
盡管目前國內并未有科學數據的使用統計平臺實踐,但國內已經有基礎數據的整合平臺,如基礎科學數據共享網等。建議由圖書館或數據出版商推動研制專門的科學數據資源使用統計平臺,基于出版商提供的符合COUNTER規范的使用統計數據,側重數字資源使用數據的收集、集成和分析。
4.4圖書館積極參與科研數據影響評價
一直以來,圖書館是科學數據管理及共享的積極推動者和實踐者。尤其是高校圖書館和研究型圖書館。它們創建機構存儲庫對科研數據長期保存,幫助科研人員制定數據管理計劃,參與科學數據共享規范的研究,幫助學校或機構創建科研數據管理政策,與出版社一道推動數據出版實踐,可以說,圖書館是科學數據管理領域的先驅者和重要貢獻者。
參與科學數據影響評價實踐也是圖書館參與數據管理的重要方向。一方面,圖書館應繼續推動科學數據共享及重用理念的傳播,為學校或者機構的科研人員提供數據管理相關服務,例如提供科學數據長期保存、元數據規范、數據工作流管理等。另一方面,圖書館可以多方式參與到科學數據影響評價過程中。圖書館可以積極推動學校或機構的決策層將科學數據使用納入科研學術的績效評估體系,并提供相應的科學數據使用計量數據;提供科學數據機構倉儲的圖書館可以嘗試基于COUNTER規范提供科學數據使用統計分析報告;圖書館還可以參與數據使用統計標準規范的制定和測試過程。
5結語
在未來的時間里,科學數據的影響績效評估將會變得愈發重要。全面綜合的科學數據計績效評估,不應僅僅將數據引用作為考量標準,科學數據使用統計和替代計量也應納入考核的數據支撐。科學數據的使用統計應用的主要障礙在于數據采集和數據標準化。而建立一個長效、規范化、多層次的科學數據使用統計體系,需要科學數據倉儲平臺、科研機構、科研資助機構、科研工作者、圖書館、標準制定機構各方的積極參與及合作。
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
世界科學技術-中醫藥現代化(2021年10期)2021-03-02 05:52:06
現代檢驗醫學雜志(2016年3期)2016-11-15 01:59:56
中學語文(2015年21期)2015-03-01 03:52:11
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中國工程咨詢(2015年2期)2015-02-14 02:59:26
西南軍醫(2015年1期)2015-01-22 09:08:16
中國音樂教育(2014年9期)2014-05-20 10:26:24
治淮(2013年1期)2013-03-11 20:05:18
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
