基于基本塊指紋的二進制代碼同源性分析
2017-10-13 20:08:47劉露平
網絡安全技術與應用 2017年3期
◆顏 穎 方 勇 劉 亮 劉露平 賈 鵬
?
基于基本塊指紋的二進制代碼同源性分析
◆顏 穎 方 勇 劉 亮 劉露平 賈 鵬
(四川大學電子信息學院 四川 610065)
二進制代碼同源性分析在代碼的專利保護和惡意代碼溯源分析中有重大意義,本文提出了一種基于基本塊指紋的、以更細粒度的對比分析算法來確定二進制代碼同源性的方法。該方法從基本塊中提取三個指紋信息:跳轉邏輯特征、代碼序列特征和子函數名特征,將基本塊的控制流程圖根據跳轉邏輯表示成由0、1構成的序列以計算基本塊跳轉邏輯特征的相似度,利用基于滑動窗口的點距陣方法計算代碼序列特征的相似度,并用Levenshtein Distance算法計算基本塊子函數名特征的相似度,最后綜合計算出二進制代碼基本塊的相似度,從而進行二進制代碼同源性分析。實驗結果表明,三種指紋信息的綜合對比分析能有效區別基本塊的異同,進行二進制代碼基本塊的同源性分析。
二進制;指紋;同源性比較;控制流程圖;代碼序列
0 引言
近年,無論是甲骨文公司起訴谷歌非法使用自己的多行Java代碼事件,還是銀行SWIFT系統被攻擊后,安全團隊根據惡意代碼追查背后的攻擊者,無不顯示出分析代碼同源性在實際應用中的重要性。二進制代碼同源性的分析不僅能鑒別代碼作者是否有抄襲行為以維護知識產權,而且能對惡意代碼的家族進行聚類[1]以追溯和確定惡意代碼的作者或組織。
在現有的代碼同源性分析技術研究中,大致分為基于源碼和基于二進制代碼的同源性分析技術兩個方向。
基于源碼的同源性分析的依據有四類:基于語義的相似性、基于編程風格的相似性、基于文本的相似性以及抽象語法樹的代碼同源性鑒別技術。基于文本的相似性檢測方法比較簡單,易于操作,缺點但該方法忽略了源代碼本身的語義特征,代碼抄襲者很容易利用這一點逃過鑒別,漏檢率較高。基于編程風格的檢測方法需要利用模塊檢測方法確定克隆的位置,這會導致耗費大量人力而難以實現自動化,可行性較差。而基于抽象語法樹的檢測方法是依靠語法分析生成屬性存儲結構,保存樹節點相關信息再進行比對,該方法技術實現復雜,理論上有很大誤檢可能。
基于源代碼的同源性分析技術的首要條件就是要有完整的源代碼,但實際運用中由于企業知識產權和專利的保護,源代碼是不會公開的。因此基于二進制代碼的同源性分析技術的重要性便顯現出來。
現階段的二進制代碼同源性分析技術中,基本以控制流程圖的特征[2]來進行同源性的分析。崔寶江等分別提出了“基于基本塊簽名和跳轉關系的二進制文件比對技術”、 “二進制文件同源性檢測的結構化相似度計算”和“基于特征提取的二進制代碼比較技術”。這些方法闡述的基本策略是:提取反匯編代碼后的代碼基本塊,用小素數乘積法[3]對基本塊處理后對264取模的值作為基本塊的指紋簽名;用基本塊的出入度表示該基本塊的調用頻率;用基本塊中子函數調用次數表示該基本塊的活躍程度;用IDA插件提取代碼基本塊的控制流程圖;最后綜合兩個代碼基本塊的控制流程圖和指紋簽名及出入度和子函數調用頻率的吻合度來確定這兩段代碼的相似性和同源性。該策略中小素數乘積法克服了代碼重排對簽名的影響,但是在應用過程中素數的乘法增長快、開銷大,在考慮效率的情況下,基本塊內的語句最好在14條以內[4],適用性受到限制。
以上所述的方法都是針對于整個文件的比對結果來確定相似度和同源性的,比對方法中涉及的都是基本塊與基本塊的關系。但是在如今的惡意代碼的分析工作中,經常遇到一個惡意程序只是引用或借鑒了已知惡意程序的某一功能模塊,如果用整個文件的匹配度來確定兩個代碼文件的同源性,往往會因漏報而降低正確率。由此,本文提出了一種針對于基本塊的內部指紋、以更細粒度的對比分析方法來進行二進制代碼同源性的度量。
1 二進制代碼同源性分析算法
本文實驗中的基本塊由IDA逆向工具提取,一個視圖下的控制流程圖視為一個完整的基本塊,該基本塊常以ret指令、call指令或jmp指令結束。以Win XP 系統下的kernel32.dll中的LoadLibraryA為例,在控制流程圖下的一個基本塊如圖1所示。
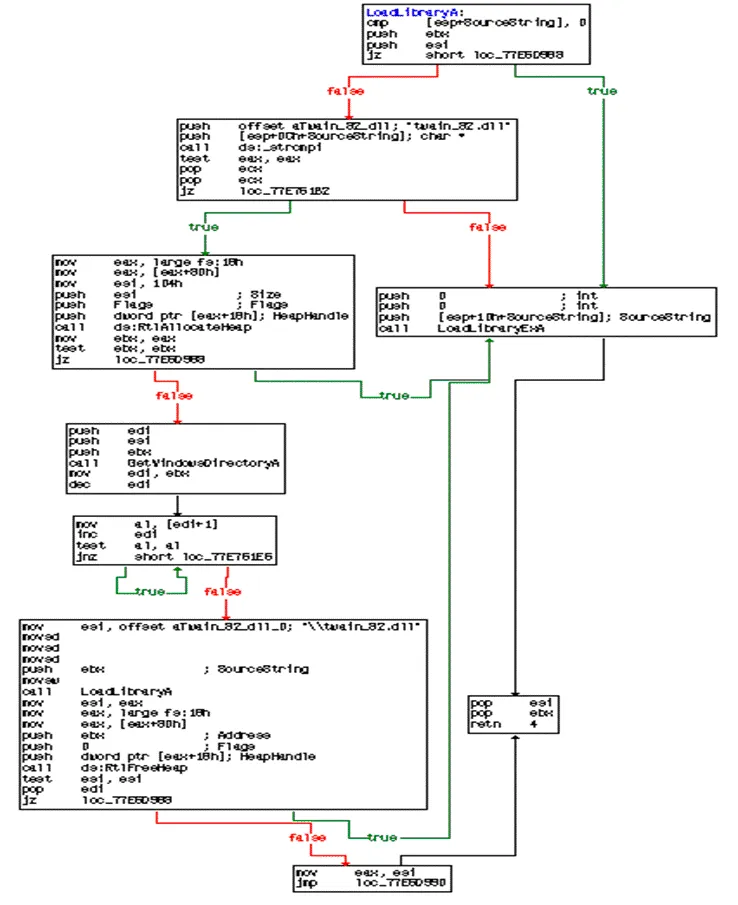
圖1 win XP 32位LoadLibraryA控制流程圖
1.1 基本塊跳轉邏輯特征
現階段的二進制代碼同源性分析技術中,基本以控制流程圖的特征來進行同源性的分析。
提取基本塊的所有完整執行流程中的跳轉邏輯,生成跳轉邏輯序列,表示如下:L=(n,t1,t2,t3,….,tn),t有兩種取值:在跳轉處為true的分支,t=1;在跳轉處為false的分支,t=0;為call、jmp的分支,略過。
設基本塊A和基本塊B,基本塊A的執行流程有CA個,基本塊B的執行流程有CB個,基本塊A和基本塊B的執行流程中的跳轉邏輯表示為:
基本塊A和基本塊B的跳轉邏輯相似度L-Similarity可表示為:
對于n值相等的兩個跳轉邏輯序列才計算其相似度。對于的,或許有幾個的值與它相等。
以圖1為例,跳轉邏輯序列集為:
以win7 32位系統下的kernel32.dll的LoadLibraryA為對比,將圖1所示基本塊的控制流程圖轉換為跳轉邏輯序列集:
由公式(1)得
1.2 基本塊代碼序列特征
在生物學上,常用矩陣作圖法計算DNA序列的相似度,其原理如下:構成DNA序列的四種堿基對分別表示為{A,C,G,T},將生物分子序列抽象為對應的字符串,進行序列比較的兩個序列分別放在矩陣的X軸和Y軸上,當對應的行與列的序列字符匹配時,就在矩陣對應的位置做“點”標記,最終形成點矩陣。如果兩條序列完全相同,則點矩陣中所有的點將構成一條對角線,如圖2。
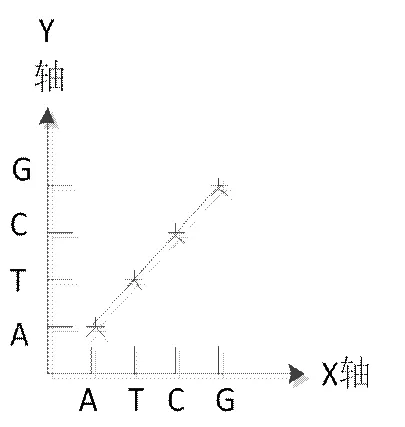
圖2 完全相似序列點陣圖
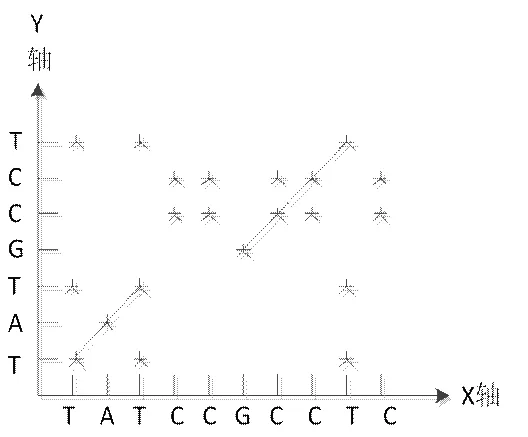
圖3 非等長不完全相似序列點陣圖
如果兩條序列存在相同子串,則對于每一個相同的子串對都有一條與對角線平行的由標記點組成的斜線,如圖3。所以找兩條序列的最佳比對實際上就是在矩陣標記圖中找非重疊平行斜線的最長的組合。
當兩條序列中有很多匹配的字符時會形成很多點標記,導致點陣圖變得復雜和模糊,此時便需要引入滑動窗口來代替一次一個點位的比較。設滑動窗口為H,相似度閾值為h(h 因此,本文借鑒了生物學上計算DNA序列相似度的矩陣作圖法和打分矩陣[5]的方法及思路,利用二維數組編程模擬點矩陣,實現對可執行二進制匯編代碼序列的相似性度量。 對需要比較的兩個二進制匯編代碼序列提取匯編指令操作符,分別表示為: 滑動窗口值設為H,打分規則為: sequenceA和sequenceB比對得出打分矩陣ScoreMatrix,掃描ScoreMatrix得到打分矩陣非重疊平行斜線的最長組合的序列長度: sequenceA和sequenceB中出現的相同序列長度為SC。 該矩陣算法能檢測出連續相同指令序列,并且能有效消除指令重排的影響,準確地得出兩個指令序列的相似度。 1.3 基本塊子函數名特征 由于每個代碼作者在給函數和變量取名時會有一定的習慣和慣性思維[6],所以基本塊中的字符特征能作為代碼同源性檢測的重要依據。 在二進制代碼中,call指令常常會泄露一定的字符串特征,這些字符串有些是代碼作者命名的,也有些是系統提供的API接口函數名。經過編譯鏈接的可執行二進制代碼在功能相同處調用的系統函數是相同的。因此本文從call指令的操作數中提取有效的子函數名作為另一重要的匹配特征。 子函數名的相似性判斷采用俄國科學家Vladimir Levenshtein發明的Levenshtein Distance算法[7]。該算法的原理是計算兩個字符串之間通過最少步驟使兩個字符串相同。每個步驟的操作方法是修改、增加或者刪除一個字符。這個最少步驟即為編輯距離ED。 設基本塊A和基本塊B,分別掃描A、B基本塊所有的call指令,提取call指令的操作數即子函數名稱,過濾掉為8個16進制數的函數名,得到兩個字符串集StrA和StrB,并且m>n。 兩個字符串集的相似度為: 以圖1和圖2為例,提取字符串特征: StrA=(6,_strcmpi,RtlAllocateHeap,LoadLibraryExA,LoadLibraryA,GetWindowsDirectoryA,RtlFreeHeap) StrB=(8,_strcmpi,LoadLibraryExA_0,LoadLibraryA,KernelBaseGetGlobalData,__imp_RtlAllocateHeap,GetWindowsDirectoryA_0,strncat_s,__imp_RtlFreeHeap) 對比結果如表1所示,因此: 表1 win xp與win7 32位kerlnel32.dll LoadLibrary子函數名特征對比 1.4 權重與閾值 為考慮到函數名變化太大無可比較性時(借鑒代碼者很容易更改函數名),則字符串特征指紋信息的相似度會拉低總體相似度的值而產生漏報。所以,通過提供調節指紋信息權重的接口,來排除已確定可不予比較的因素或減小某一指紋信息的影響程度以減小誤報率。即用u、v和(1-u-v)分別表示邏輯跳轉特征、代碼序列特征和子函數名特征的所占權重,通過調節權重比例,綜合量化出兩個基本塊的整體相似度,總相似度可表示為公式(4)。 利用Win XP 32位系統與Win7 32位系統下的同名DLL文件以及常見文字處理工具notepad的不同版本作為實驗樣本,得出相關測試結果如表2。 表2 u=v=1/3 測試結果 在win XP和win7 32位的kernel32.dll的LoadLibrary基本塊的對比中,Fsimilarity的值為0.8576,說明盡管系統版本不一樣,但調用的子函數基本上是相同的,并且跳轉邏輯相似度也遠遠高于表中其他對比項;在win7 32位的kernel32.dll的LoadLibrary與DllEntryPoint基本塊的對比中,Fsimilarity為0說明兩個基本塊調用的子函數完全不同,這反映出兩個基本塊所完成的功能是完全不一樣的,并且跳轉邏輯的相似度也只有0.0370;用VS2010編譯的Helloworld.exe與win7 32位的kernel32.dll的LoadLibrary基本塊做對比發現Ssimilarity的值與前兩項對比值較接近,這是因為這些對比中的二進制文件都是同一編譯器生成的,在調用函數時的堆棧操作的代碼特征是一樣的,而在win7 32位系統自帶的notepad.exe與asm編譯的wordpad.exe的對比中,Ssimilarity的值卻只有0.0571,這是因為雖然兩個文字處理程序notepad.exe和wordpad.exe的功能大致相同,但是由不同語言、不同編譯器生成的,不僅在調用函數時的堆棧操作的特征不一樣,在功能實現的調用函數以及調用函數的順序都是不一樣的,反映在Ssimilarity上的結果就是Ssimilarity的值非常低。 本文從主流安全網站上收集到被曝光的10個APT組織流出的相關代碼樣本,將這些代碼樣本作為測試數據,對比傳統的基于控制流程圖的同源性檢測方法,得到測試結果如表3。 實驗中所用的同源測試樣本來自于不同的APT組織被曝光的利用代碼,由于這些被捕獲到的代碼樣本并不是完整的可執行二進制文件,所以傳統的基于控制流程圖的同源性分析方法能檢測出的同源樣本數量有限,而本論文提出的方法能以更細粒度的分析策略檢測出二進制可執行代碼的同源性。 表3 同源樣本檢測對比結果 二進制代碼的同源性分析對惡意代碼的溯源和代碼抄襲的確定有著重要的輔助作用。本文通過提取基本塊內部的跳轉邏輯、代碼序列和子函數名的指紋信息,以更細粒度的對比分析算法來確定二進制代碼同源性,該方法能對可執行二進制代碼進行量化分析,以準確的代碼特征取證完成二進制代碼同源性的判斷過程,得到準確結果。 [1]錢雨村,彭國軍,王瀅等.惡意代碼同源性分析及家族聚類[J].計算機工程與應用,2015. [2]Kunhua Zhu,Yancui Li.Binary Software Copy Detection Scheme based on Fingerprint Signatures.Journal of Convergence Information Technology(JCIT)and Control Flow Graph[J],2012. [3]趙連朋.一種基于素數存儲的關聯規則算法[J].計算機工程與應用,2006. [4]王建新,楊凡,韓鋒.二進制文件比對中的指令歸并優化算法[J].計算機應用與軟件,2013. [5]袁二毛,郭丹,胡學鋼,吳信東.基于打分矩陣的生物序列頻繁模式挖掘[J].模式識別與人工智能,2016. [6]董志強.編碼心理學分析病毒同源性[J].信息安全與通信保密,2005. [7]Frederic P. Miller,Agnes F. Vandome,John McBrewster. Levenshtein Distance[M], 2013.
2 實驗結果及分析


3 總結
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
山東工業技術(2016年15期)2016-12-01 05:31:22
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
