關聯規則在中職學校招生管理系統中的應用
2017-10-13 20:07:58唐堅勝張晶晶鄧珍榮
網絡安全技術與應用 2017年3期
◆何 萌 唐堅勝 張晶晶 鄧珍榮
?
關聯規則在中職學校招生管理系統中的應用
◆何 萌1唐堅勝2張晶晶1鄧珍榮1
(1.桂林電子科技大學計算機與信息安全學院 廣西 541004;2.桂林林業學校 廣西 541004)
針對中等職業學校招生規模的不斷擴大的現象,提高中職生源質量已經成為各培養單位的重點工作。傳統的生源質量分析主要是計算考生成績的均值、方差、區分度等,僅對單個獨立的數據進行分析,無法獲取數據間的有價值信息。本文將數據挖掘關聯規則應用于分析中職學校學生入學成績、在校生學習成績、就業狀況和生源質量之間的內在關系,找出對影響招生質量有價值的信息,為招生政策的制定提供參考。
數據挖掘;關聯規則;生源質量
0 引言
當今大數據時代,數據處理量越來越大,僅僅依靠傳統的數據處理方式已經遠遠不能滿足人們現實生活中的需求,數據挖掘技術的發展引起了各行各業的高度關注。近年來,中等職業教育得到國家政策大力扶持,職業學校規模逐漸擴大、自主招生程度不斷提高,生源數量已經成為政府和社會評價中等職業學校辦學實力的一個重要指標。如何從學校豐富的數據信息中提取出有價值的數據資料,已經成為教學管理中值得探索的問題之一。數據挖掘技術可以為學校科學決策助一臂之力。將數據挖掘技術應用于中等職業學校招生信息系統,搜集各種數據表征的內容及其相互關系,根據學生入學前的信息與在校就讀期間的學習成績等特點,分析中職學校生源質量,可為中職學校制定招生計劃、提高生源質量提供有效的參考信息。有助于及時發現教學與管理中的問題,促進教育教學改革,提高教學管理工作的質量和效率。
1 關聯規則
1.1 數據挖掘技術概述
從具有隨機干擾、噪聲、錯誤、缺失和不完整的大量數據中,將對人們有用的、隱含的、潛在的、未知的信息提取出來的操作,稱為數據挖掘。數據挖掘技術在當前形勢下應運而生。數據挖掘是一種深層次的數據信息分析方法,是從數據庫中知識發現和決策支持的過程,主要基于人工智能、機器學習、統計學等技術,高度自動化地分析原有數據,做出歸納性的推理,從數據中挖掘出潛在的模式,預測分析對象的行為趨勢,從而幫助決策或調整策略。數據挖掘的任務有關聯分析、聚類分析、分類分析、異常分析、特異群組分析和演變分析等,其中最常用的是聚類分析和關聯規則分析。數據挖掘技術已成功地應用在許多企業中,對提高企業經濟效益和管理效率有顯著的影響。
在中等職業教育領域,有很多可以挖掘的信息,如學生入學成績管理、學生在校成績管理、學生家庭狀況、入學率情況和畢業就業質量等。將數據挖掘技術應用于對中職學校學生成績的分析,分析生源質量與各種因素之間隱藏的內在聯系,這對整個中職院校擴大規模、提高辦學質量具有重要的實踐意義。
1.2 關聯規則概述
數據挖掘中有一類問題,叫做關聯規則挖掘或頻繁項集挖掘。關聯規則是數據挖掘應用最廣的一種方法。關聯規則挖掘是在海量的數據中發現數據各項之間的關系關聯規則的支持度和置信度。它們分別反映了所發現規則的有用性和確定性。通過設定最小支持度閾值和最小置信度閾值,選取有趣的關聯規則。當挖掘出的關聯規則的支持度和置信度都滿足這兩個閡值時就認為這個規則是有效的,否則就是無效的,這些閾值一般可由領域專家設定。挖掘關聯規則的整個過程主要包括兩個方面,一個是發現頻繁項集:找出支持度大于等于用戶設置的最小支持度的項集;另一方面是生成關聯規則:由步驟一發現的頻繁項集生成關聯規則,并且這些關聯規則的置信度不小于用戶給定的最小置信度挖掘關聯規則的整個過程如圖1所示。

圖1挖掘關聯規則的過程
數據發掘技術中的關聯規則挖掘,是利用計算機自動從大量的數據中去分析和發現有關聯的規則。計算機本身需要了解所有發生的情況,并依次整理,把相關的事件合并整理在一起,然后對每件事進行掃描分析,以總結出事物的關聯性規律。數據挖掘技術對于中職的學生信息管理工作來說,是一種可以化繁瑣為簡單的技術,對于工作效率的提高以及工作準確度的保證都有很重要的意義,因此在很多中職學校中,數據挖掘技術都被作為了其學生信息管理的研究工作的重點。
2 Apriori算法
Apriori算法是經典的關聯規則的挖掘算法,被廣泛應用于各種領域。Apriori算法主要用于發現事務數據庫中的布爾型關聯規則,是一種尋找頻繁項集的基本算法,其基本原理是使用一種稱作逐層搜索的迭代方法,即用k項集去探索(k +1)項集針對大量的事務數據。從單個項開始逐個遍歷所有事務,并與預設的最小支持度閾值相比較,如果支持度小于預設的閾值,則這一項將被刪除,進而擴充到所有事務,頻繁項集就是最終保留下來的項的集合。關聯規則通過子集產生法來生成,與用于預設的最小置信度閾值相比,如果置信度低于這一閾值,則將這一關聯規則刪除,最終保留下來的關聯規則符合用戶需要。Apriori 算法可以描述如下:
(1)產生頻繁一項集;
(2)產生頻繁k(2→end)項集;
(3)產生頻繁候選k項集;
①由頻繁k-1項集連接成為k項集;
②檢測k項集的所有的k-1子集是否為頻繁項集,若是該k 項集就成為了頻繁候選項集;
(4)掃描事務數據庫D對每個候選k項集計數。
(5)達到最少支持度的頻繁候選k項成為頻繁k項集。
3 關聯規則在中職學校管理系統中的應用
3.1 數據分析過程
實驗使用的數據為桂林市衛生學校2013、2014、2015級學生的數據,數據分析過程如下圖2,從原始數據到發現規則的過程大致要經過數據的準備、預處理、數據挖掘與結果分析四個步驟。
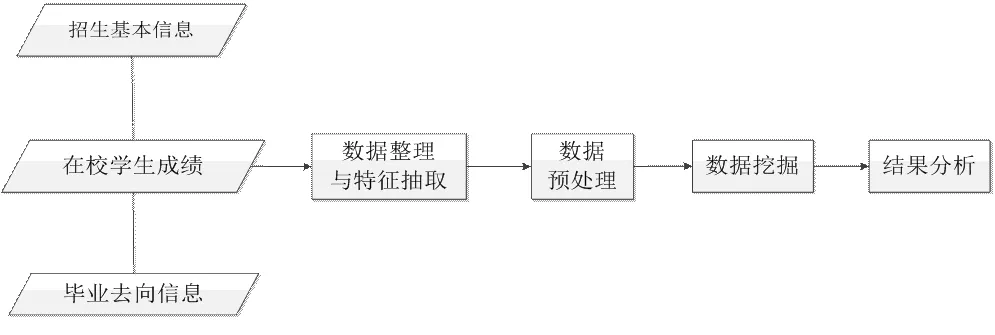
圖2數據分析過程
3.2 關聯規則挖掘算法在中職招生中應用
在桂林市衛生學校學生數據集合中,既存在布爾型的數據(如學生的性別、家庭住址),又存在數值型的數據(如學生的成績)。根據數據的特征,選用Apriori作為數據挖掘算法,發現數據集合之間的關聯關系。將桂林市衛生學校學生的入學成績與畢業信息進行數據關聯分析,得出有利于選拔優質生源的有用信息。對2010-2012年學生的入學成績信息、在校成績信息和畢業信息進行分析,設定支持度=10%,置信度=30%,挖掘出如表 1 所示的參考規則。
表1參考規則

序號參考規則 1初高中學校=重點學校→畢業生質量=優 2初高中學校=重點學校→畢業生質量=良 3入學成績(平均分)=A或B→畢業生質量=優 4入學成績(平均分)=A或B→畢業生質量=良 5入學成績(語文)=A或B→畢業生質量=差 6入學成績(語文)=C或D→畢業生質量=差 7在校成績(平均分)=A或B→畢業生質量=優 8在校成績(政治)=A或B→畢業生質量=差 9在校成績(政治)=C或D→畢業生質量=優 ……
數據挖掘的結果在實際中不一定存在必然的聯系,要結合實際情況對得到的關聯規則加以分析,通過設置不同的支持度閥值和置信度閥值,可以得到不同的關聯規則。將規則庫加以調整,為招生工作提供輔助支持。例如:表1挖掘的規則是學生的生源入學成績與畢業生是否優秀之間的關聯規則,先判斷產生的子集是否屬于生源特征資料維的,滿足這個條件才能挖出規則來。這樣可以有效地濾除有意義的關聯規則,減少數據的冗余。
參考規則中的規則5和6入學成績(語文)=A或D→畢業生質量=良,無論學生入學考試語文成績是高或是低,學生畢業的質量都不是優,此條規則在挑選生源時沒有任何實際意義。而規則3和4入學成績(平均分)=A或D,學生畢業的質量則是可以直觀看出,可見可以通過平均分來判斷生源質量是否優秀,此信息可以提供給學校作為是否錄取該生的條件。
4 結論
通過將關聯規則應用到中職學校招生管理系統,可對生源的質量優劣進行初步的分析和評價。關聯規則挖掘提供了一個進行合理挖掘的模式和挖掘方向,加快了挖掘速度、減少了數據的冗余度,為該中職專院校招生管理提供了一個方向。
招生階段是整個學生培養周期的最初階段,高質量的生源是學生培養質量的有力保證。數據挖掘技術作為中職專院校管理學生信息工作的有力工具,不但可以提高信息管理工作的效率,還對招生工作及相關政策的制定有一定的指導和幫助。數據挖掘技術在中職學生信息分析中可以發揮重要的作用,為制定科學的教育策略提供依據。只要選擇合適的分析對象、進行合理的算法選擇,數據挖掘技術將在教育領域的其它方面獲得更多應用。
[1]王毅鵬.高職院校招生與就業管理信息系統的研究與實現[D].西安電子科技大學,2012.
[2]王暉,王琪,何瓊.數據挖掘理論與實例[M].北京:經濟科學出版社,2012.
[3]郭濤,張代遠.基于關聯規則數據挖掘Apriori算法的研究與應用[J].計算機技術與發展,2011.
[4]馮璐妹,趙建寧.基于Apriori的高效關聯規則挖掘算法在教育考試系統中的應用研究[J].軟件,2013.
[5]Huang Hong-zhi,Cai Yan-rong.Web-based design of the management information system for the chemical laboratory in the university. International Conference on Computer Design and Applications(ICCDA),2010.
桂林市科學研究與技術開發計劃項目(2016010406-4)。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
信息通信技術(2015年6期)2015-12-26 01:16:46
