基于運(yùn)動(dòng)歷史圖和支持向量機(jī)的手勢(shì)識(shí)別
2017-11-07 12:52:32于樂
電子技術(shù)與軟件工程 2017年17期
文/于樂
基于運(yùn)動(dòng)歷史圖和支持向量機(jī)的手勢(shì)識(shí)別
文/于樂
利用背景建模得到運(yùn)動(dòng)目標(biāo)的前景后,如何對(duì)動(dòng)作提取有效的信息進(jìn)行分類是能否成功識(shí)別手勢(shì)的關(guān)鍵。本文利用混合高斯模型GMM得到的前景圖像序列獲得運(yùn)動(dòng)歷史圖MHI,進(jìn)而對(duì)各個(gè)動(dòng)作的MHI提取HOG特征,通過支持向量機(jī)SVM的訓(xùn)練后可以準(zhǔn)確識(shí)別不同的手勢(shì)動(dòng)作。
手勢(shì)識(shí)別背景建模 MHI 支持向量機(jī)
運(yùn)動(dòng)的跟蹤和分類是計(jì)算機(jī)視覺中重要的研究方向,在視頻監(jiān)控、人機(jī)交互中有廣泛的應(yīng)用。目前利用深度傳感器和可穿戴傳感器可以準(zhǔn)確地識(shí)別動(dòng)作,但是成本較高,本文采用普通攝像頭采集圖像,通過分割前景、特征提取和訓(xùn)練分類器三步實(shí)現(xiàn)手勢(shì)識(shí)別。
1 基于背景建模提取前景
本文采用背景建模法中的混合高斯模型,該模型對(duì)每一個(gè)像素用多個(gè)高斯分布函數(shù)來描述,從而建立起場(chǎng)景的背景圖像,在用當(dāng)前幀與背景圖像進(jìn)行背景減除,再通過膨脹和腐蝕等操作得到運(yùn)動(dòng)前景。因?yàn)榛旌细咚共捎枚喾宸植迹钥梢詾V去反復(fù)抖動(dòng)的背景,從而提高了魯棒性和準(zhǔn)確性。
得到的運(yùn)動(dòng)前景圖和背景圖像如圖1所示,可見背景圖像保留了不運(yùn)動(dòng)的區(qū)域,而前景圖有效地分割出了運(yùn)動(dòng)區(qū)域。

圖1:基于混合高斯模型的前景圖和背景圖
2 獲取MHl圖像并提取特征
運(yùn)動(dòng)歷史圖MHI的原理是根據(jù)連續(xù)圖像序列在時(shí)間上的疊加,對(duì)運(yùn)動(dòng)動(dòng)作提供一個(gè)全局描述。具體操作是對(duì)一段時(shí)間內(nèi)每個(gè)像素的值進(jìn)行加權(quán)疊加,從而得到有方向性的動(dòng)作描述圖像。該方法的計(jì)算公式如式(1)所示,其中B(X,Y)是前景圖像序列,τ是時(shí)間窗口長度。
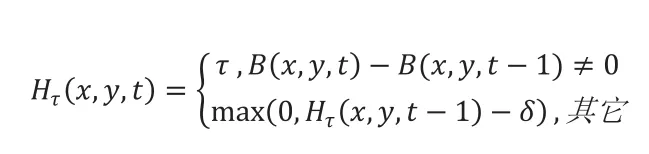
得到的當(dāng)前前景圖和運(yùn)動(dòng)歷史圖如圖2所示,其中前景圖值包含當(dāng)前幀運(yùn)動(dòng)目標(biāo)的信息,而運(yùn)動(dòng)歷史圖可以描述整個(gè)動(dòng)作,圖中為畫圓的動(dòng)作,其中顏色越深說明距離當(dāng)前時(shí)間越近,所以可以推斷出圖中的圓為逆時(shí)針畫圓。
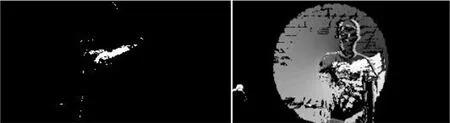
圖2:根據(jù)前景圖得到的運(yùn)動(dòng)歷史圖
在得到MHI后對(duì)其提取方向梯度直方圖HOG特征,因?yàn)橐环鶊D像中目標(biāo)的表象和形狀能夠被梯度或邊緣的方向密度分布來描述,所以可以通過計(jì)算和統(tǒng)計(jì)圖像局部區(qū)域的梯度方向直方圖來提取特征。具體操作為將MHI二值圖分成細(xì)胞單元,然后采集每個(gè)小的連通區(qū)域中像素點(diǎn)的方向直方圖,最后將直方圖結(jié)合起來。
在本文中先對(duì)MHI降維成64×64的圖像,進(jìn)行提取后每張MHI得到1764個(gè)HOG特征,將所有單元的HOG特征串聯(lián)起來就得到該時(shí)刻MHI的檢測(cè)子descriptor。

圖3:依次為向右、向下、對(duì)鉤、畫圓
3 手勢(shì)動(dòng)作的標(biāo)記和識(shí)別
在得到大量手勢(shì)識(shí)別的樣本后,可以進(jìn)行SVM訓(xùn)練。其中正樣本為每個(gè)動(dòng)作結(jié)束時(shí)的運(yùn)動(dòng)量歷史圖,標(biāo)記為1,負(fù)樣本為其他非特殊動(dòng)作圖像,標(biāo)記為0,將正負(fù)樣本的HOG特征作為輸入向量放入SVM中進(jìn)行訓(xùn)練,訓(xùn)練好的分類器保存在XML文件中,在之后識(shí)別時(shí)不再需要訓(xùn)練SVM,只需載入該分類器即可。
4 實(shí)驗(yàn)結(jié)果分析
本文采用的樣本包括上下左右移動(dòng)、對(duì)鉤、打叉、畫圓七個(gè)動(dòng)作,最終測(cè)試錄像未參與訓(xùn)練。分類器得到的結(jié)果會(huì)實(shí)時(shí)顯示在圖像上,結(jié)果如圖3所示。
將7個(gè)動(dòng)作一次標(biāo)號(hào)為1-7,未檢測(cè)標(biāo)號(hào)為0,得到動(dòng)作-時(shí)間圖像如圖4所示。
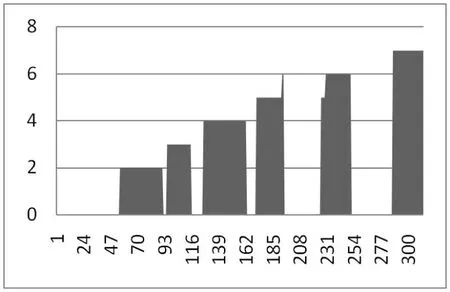
圖4:動(dòng)作序號(hào)-時(shí)間圖像
由圖像可以發(fā)現(xiàn)兩個(gè)問題,一是第一個(gè)動(dòng)作沒有識(shí)別處理,這是因?yàn)殚_始混合高斯模型還未完全建立,此時(shí)無法準(zhǔn)確提取出前景目標(biāo),想要快速建立可以提高模型更新的學(xué)習(xí)率。二是在第五個(gè)和第六個(gè)動(dòng)作中出現(xiàn)了誤檢,這是因?yàn)樵谟?xùn)練SVM分類器時(shí)正樣本數(shù)量還不夠,若繼續(xù)增加樣本數(shù)量,可以進(jìn)一步提高準(zhǔn)確率。
至此完成了對(duì)手勢(shì)動(dòng)作的識(shí)別,其中準(zhǔn)確率較高,誤檢率為1.9%,同時(shí)處理圖像的速度也滿足實(shí)際應(yīng)用的要求。在此基礎(chǔ)上,可以將識(shí)別出的結(jié)果應(yīng)用于諸多領(lǐng)域,實(shí)現(xiàn)手勢(shì)操控的人機(jī)交互。
[1]Stauffer C,Grimson W E L.Adaptive Background Mixture Models for Real-Time Tracking[C].cvpr.IEEE Computer Society,1999:2246.
[2]Davis J W.Hierarchical Motion History Images for Recognizing Human Motion[C].Detection and Recognition of Events in Video, 2001.Proceedings. IEEE Workshop on. IEEE,2001:39-46.
[3]Dalal N,Triggs B.Histograms of oriented gradients for human detection[C].IEEE Computer Society Conference on Computer Vision & Pattern Recognition.IEEE Computer Society,2005:886-893.
作者單位東南大學(xué)自動(dòng)化學(xué)院 江蘇省南京市 210096
猜你喜歡
汽車工程師(2021年12期)2022-01-17 02:29:54
建材發(fā)展導(dǎo)向(2021年6期)2021-06-09 05:57:08
現(xiàn)代國際關(guān)系(2021年2期)2021-04-13 01:59:16
當(dāng)代陜西(2020年14期)2021-01-08 09:30:42
中國外匯(2019年11期)2019-08-27 02:06:32
小學(xué)生作文(低年級(jí)適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學(xué)低年級(jí)(2017年4期)2017-06-09 16:22:28
作文評(píng)點(diǎn)報(bào)·低幼版(2017年7期)2017-03-11 20:49:41
貴州師范學(xué)院學(xué)報(bào)(2016年4期)2016-12-01 03:54:07
太空探索(2016年10期)2016-07-10 12:07:01
