面向大規(guī)模地震體的多切片實時交互繪制優(yōu)化
2017-11-15 06:02:41紀連恩張笑林梁適宜
計算機應(yīng)用 2017年9期
紀連恩,張笑林,梁適宜,王 斌
(中國石油大學(xué)(北京) 計算機科學(xué)與技術(shù)系,北京 102249)(*通信作者電子郵箱jilianen@126.com)
面向大規(guī)模地震體的多切片實時交互繪制優(yōu)化
紀連恩*,張笑林,梁適宜,王 斌
(中國石油大學(xué)(北京) 計算機科學(xué)與技術(shù)系,北京 102249)(*通信作者電子郵箱jilianen@126.com)
在普通計算平臺上實現(xiàn)大規(guī)模地震體的多切片可視化時,傳統(tǒng)緩存調(diào)度方法由于未考慮體塊與切片的空間關(guān)聯(lián),導(dǎo)致交互時體塊命中率較低,而常用的多分辨率繪制方法也難以達到較高的繪制質(zhì)量,針對這些問題,設(shè)計了一種新的高速緩存調(diào)度策略——最大距離先出(MDFO)。首先,根據(jù)交互切片的空間位置改進緩存中體塊的調(diào)度優(yōu)先級,保證候選體塊在切片連續(xù)交互時有更高的命中率;然后,提出了兩階段切片交互繪制方法,通過使用固定分辨率體塊保證交互的實時性,通過漸進細化提升最終顯示質(zhì)量,并進一步結(jié)合體塊數(shù)據(jù)的信息熵提升用戶感興趣區(qū)域的分辨率。實驗結(jié)果表明,所提方法能夠有效提高體塊的整體命中率,提升比例達到60%以上,同時也實現(xiàn)了面向應(yīng)用需求的高質(zhì)量圖像顯示,較好地解決了大規(guī)模地震體可視化在交互效率與顯示質(zhì)量間的矛盾。
體可視化;多切片交互;緩存調(diào)度;兩階段繪制;信息熵
0 引言
三維可視化技術(shù)在地震數(shù)據(jù)建模和分析過程中具有重要作用,能夠有效降低油氣勘探的風(fēng)險和不確定性[1]。隨著地震勘探技術(shù)的不斷成熟,地震數(shù)據(jù)采集的速度與精度越來越高,地震體模型的數(shù)據(jù)量也提高到百GB甚至TB級別。而在地震采集設(shè)計等領(lǐng)域,考慮到作業(yè)現(xiàn)場使用的便攜性,目前使用的硬件設(shè)備仍基于普通計算平臺,內(nèi)存一般只有幾個GB,顯存也只有1 GB到2 GB,直接存儲和處理如此大規(guī)模的體數(shù)據(jù),將變得非常緩慢,以至于不能接受[2]。因此許多國內(nèi)外學(xué)者和技術(shù)人員針對海量體數(shù)據(jù)模型的三維可視化進行了相關(guān)研究[3-5]。
為了解決在普通計算平臺上進行大規(guī)模地震體可視化的問題,通常采用八叉樹結(jié)構(gòu)對原始地震體數(shù)據(jù)進行重新組織。空間中的體數(shù)據(jù)經(jīng)過三個維度的遞歸抽稀,依次將數(shù)據(jù)按照空間劃分成八個部分,最終形成基于多分辨率空間排列的體塊結(jié)構(gòu)。在繪制過程中,根據(jù)緩存容量通過遍歷八叉樹選取合適分辨率的體塊進行加載和繪制。
基于三維紋理的體繪制技術(shù)早在1989年就被Cullip等[6]提出。在該方法中,充分利用了圖形處理器(Graphic Processing Unit, GPU)的并行計算能力和浮點運算能力,相對光線投射算法在復(fù)雜度和繪制效率上都有很大的提高。
Lamar等[7]則在此基礎(chǔ)上通過在八叉樹中創(chuàng)建分層細節(jié)(Level Of Detail, LOD)的體塊,實現(xiàn)了基于八叉樹的多分辨率體繪制技術(shù)。通過在八叉樹中對體塊的快速索引,可實現(xiàn)對體數(shù)據(jù)的不同層次分辨率顯示,以及細化切片時體塊數(shù)據(jù)的快速查找。使用LOD和多分辨率技術(shù)來對三維地震體進行管理,根據(jù)一定的體塊選取策略選擇合適的體塊組成體塊列表進行繪制,能夠顯著提高地震體的顯示效率[8-11]。
隨后Lamar等[7]又引入了基于視點的動態(tài)多分辨率切片顯示技術(shù),該方法根據(jù)視點的位置,確定切片哪些部分分辨率更高,哪些分辨率可以更低。這個方法假設(shè)人們對離視點越近的點越感興趣,也就賦予該點周圍更高的分辨率,離該點的位置越遠則切片分辨率越低。
針對大規(guī)模體數(shù)據(jù)的緩存調(diào)度問題,文獻[2]根據(jù)數(shù)據(jù)流向,分別設(shè)計了從外存到內(nèi)存和從內(nèi)存到顯存的調(diào)度策略,并在使用多分辨率技術(shù)篩選所需體塊時,通過限制一次性載入顯存的體塊數(shù)量來提高交互的流暢性。
文獻[12]為實現(xiàn)大規(guī)模體數(shù)據(jù)在普通計算平臺上的可視化,提出了半適應(yīng)的分塊方法,得到不同尺寸的數(shù)據(jù)分塊,并對某些空數(shù)據(jù)塊進行剔除,提高了體繪制效率,但仍然難以進行實時交互。
在上述研究中,體塊的緩存與調(diào)度通常采用基于時間相關(guān)聯(lián)的最近最少使用(Least Recently Used, LRU)算法,但是,在多切片應(yīng)用場景下,切片交互操作的隨機性較大,對時間的關(guān)聯(lián)性較弱,使得緩存中體塊的命中率較低。另外,僅采用視點與地震體的空間位置關(guān)系進行體塊分辨率選擇以確定生成最終圖像的體塊工作集,在該過程中沒有考慮到體塊數(shù)據(jù)所蘊含的信息量對可視化效果的影響,使得最終的繪制質(zhì)量不高。
針對上述問題,本文面向普通計算平臺,設(shè)計了基于距離度量的從外存到內(nèi)存再到顯存的數(shù)據(jù)緩存與調(diào)度策略,將候選體塊與切片的空間距離作為計算置換優(yōu)先級的重要因素,有效提高大規(guī)模地震體切片交互繪制時的體塊命中率;為進一步平衡大規(guī)模地震體可視化在交互效率與顯示質(zhì)量間的矛盾,提出了面向兩階段的切片實時交互與漸進繪制策略,并通過計算體塊的信息熵優(yōu)化體塊的細化等級,在保證交互實時性的同時提高最終圖像繪制質(zhì)量。
1 基于距離度量的體塊緩存調(diào)度策略
由于內(nèi)存和顯存空間的限制,繪制時體塊數(shù)據(jù)不能全部載入,為了有效利用有限的存儲空間,需要解決外存、內(nèi)存和顯存之間頻繁數(shù)據(jù)交換導(dǎo)致的繪制效率較低的問題。
1.1 從外存到內(nèi)存的體塊緩存調(diào)度
體繪制中常用基于時間度量的緩存數(shù)據(jù)置換算法,如LRU算法,即當緩存區(qū)全部被使用時,新加載體塊將最久未被使用的體塊置換出內(nèi)存。
當場景中只有一個切片時,由于切片交互的連續(xù)性,最久未使用的體塊距離切片也最遠。如圖1所示,當拖動切片從位置A到位置B時,越久未使用的體塊(如圖中區(qū)域一所示),距離B越遠,被再次訪問的概率也越低(由于訪問區(qū)域一的體塊必須經(jīng)過AB中間的區(qū)域二,訪問區(qū)域二概率高于區(qū)域一),因此將距離切片最遠的區(qū)域一中的體塊作為無用塊置出。
然而在多切片應(yīng)用場景下,由于切片選擇和移動方向的不確定性,基于訪問時間的LRU算法可能導(dǎo)致緩存的命中率降低。如圖2所示,開始時A、B兩個切片分別在虛線A1,B1處,之后先把A切片從A1移動到A2,再將B切片從B1移動到B2。此時內(nèi)存占用如圖3(a)所示。當B切片繼續(xù)從B2移動到B3時,根據(jù)LRU策略,最久未使用的為A1,此時A1將被置出,緩存區(qū)如圖3(b)所示。此后,當用戶向上移動切片A時,將再次使用到A1,然而此時A1已經(jīng)被置換出緩存區(qū)。
如果按照體塊到切片的距離進行體塊的調(diào)度,距離切片最遠的B1將優(yōu)先被置出緩存區(qū),緩存區(qū)如圖3(c)所示。此時,若用戶移動切片A到A1位置時,依舊可以命中緩存。
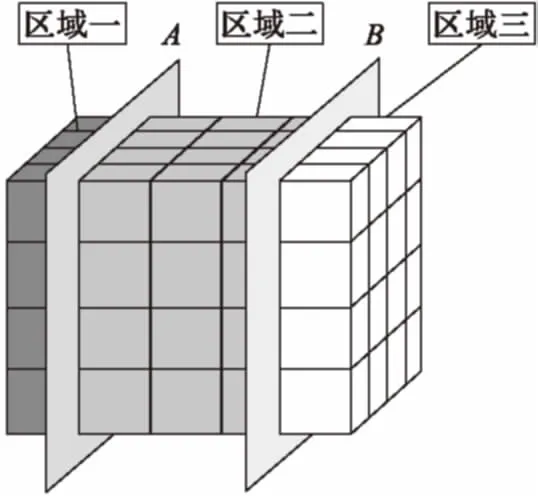
圖1 單切片交互時的體塊選擇情況
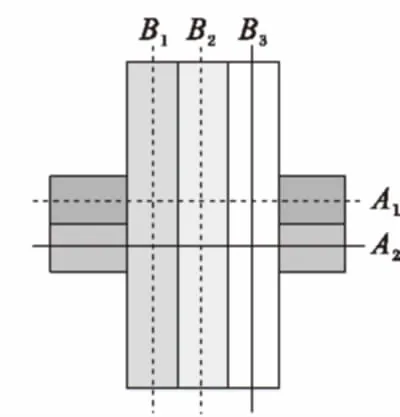
圖2 多切片交互時的體塊調(diào)度
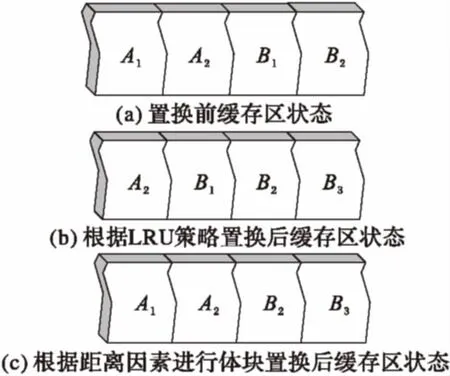
圖3 應(yīng)用不同策略進行置換后緩存區(qū)狀態(tài)
根據(jù)上述對數(shù)據(jù)調(diào)度過程的分析,提出基于距離度量的體塊內(nèi)外存調(diào)度策略——最大距離先出(Maximum Distance First Out, MDFO),MDFO策略的計算模型如下所示:
Pmdfo=kd×min{s×dstand,m×dmov}+kl×L+kt×T
(1)
在每次進行切片交互時,使用式(1)計算緩存中各個體塊的置出優(yōu)先級。其中,dstand和dmov分別為當前體塊中心到靜止切片和移動切片的距離,s、m分別為靜止距離系數(shù)與移動距離系數(shù),距離切片越遠則再次被用到的幾率越小。在切片交互過程中,考慮到交互操作的連續(xù)性,靜止切片附近的體塊應(yīng)該被優(yōu)先置出,通過實驗測試,本文設(shè)置s=1.5,m=1.0;L為體塊的分辨率級別,L值越大體塊的分辨率越高,體塊的空間跨度越小,使用的概率也越小;T為體塊最近一次被用到的時間到當前幀的時間,T值越大則說明最近一次使用該體塊的時間點越久,再次被用到的概率也越小。Kd、Kl、Kt分別為距離、分辨率級別、時間跨度的系數(shù),根據(jù)切片到體塊的距離和體塊的分辨率級別以及時間跨度對體塊置出優(yōu)先級的貢獻度不同,經(jīng)過實驗測試,設(shè)置參數(shù)Kd=5,Kl=10,Kt=1。Pmdfo為體塊調(diào)出緩存的優(yōu)先級度量,Pmdfo值越大,則體塊越被優(yōu)先置出緩存區(qū)。
1.2 GPU紋理對象的緩存調(diào)度策略
在體繪制過程中,需要將體塊列表中對應(yīng)體塊的紋理數(shù)據(jù)加載到顯存中生成對應(yīng)的紋理對象。在普通計算平臺上,顯存資源更為稀缺,其能夠存儲的紋理對象數(shù)量更為有限,因此也需要更加精細的管理和調(diào)度。有效利用顯存空間來緩存紋理對象,同時使用合理的緩存調(diào)度策略,可以有效地減少從內(nèi)存到顯存的數(shù)據(jù)加載次數(shù),提高繪制效率。
根據(jù)以上對多切片交互的討論,本文設(shè)計了一種基于距離度量的GPU紋理對象緩存與調(diào)度策略。如圖4所示,將顯存空間劃分為三個區(qū)域:StableArea、ActiveArea和UnusedArea。StableArea存放連續(xù)幾幀被使用的紋理對象,該區(qū)域較為穩(wěn)定,可以減少常用紋理對象換入換出的次數(shù);ActiveArea存放當前幀剛加載的紋理對象;ActiveArea中在當前幀未被使用到的紋理對象被移動到UnusedArea。
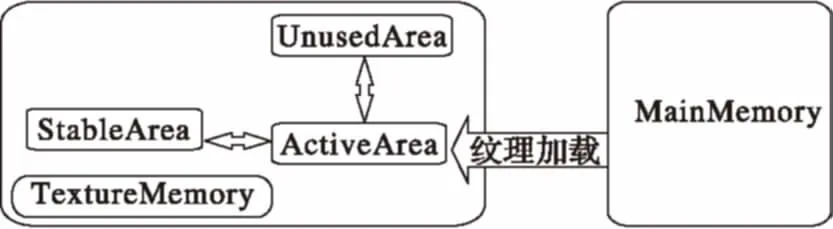
圖4 體紋理數(shù)據(jù)加載與調(diào)度
切片繪制根據(jù)體塊選取階段產(chǎn)生的體塊列表進行三維紋理的生成與加載。在加載紋理時,首先掃描顯存的三個緩存區(qū),判斷體塊紋理是否命中。如果所需的紋理對象在UnusedArea區(qū)域命中,則將該紋理對象從UnusedArea移動到ActiveArea;如果在ActiveArea命中,則計算該紋理對象在最近幾幀中命中的次數(shù),若命中次數(shù)達到閾值N則將該紋理對象從ActiveArea移動到StableArea,否則依然存放在ActiveArea中,并更新命中次數(shù);如果在StableArea區(qū)域命中,則更改該紋理對象的優(yōu)先級Pgpu;如果沒有命中任何區(qū)域,則將紋理從內(nèi)存加載到ActiveArea。
當某個區(qū)域的存儲空間被占滿,又有新的紋理對象加載時需要一個合理調(diào)度策略進行置換。本文通過計算紋理對象的置出優(yōu)先級來進行紋理對象的調(diào)度,優(yōu)先級高的則被優(yōu)先置出。優(yōu)先級Pgpu的計算模型如下:
Pgpu=kd×min{s×dstand,m×dmov}+kl×L
(2)
上述計算模型(2)考慮了紋理對象所對應(yīng)體塊與切片的空間位置關(guān)系以及其自身分辨率對緩存和調(diào)度策略的影響。其中,Kd和Kl分別為空間位置關(guān)系與分辨率級別的影響因子,dstand和dmov分別為當前紋理對象所對應(yīng)體塊到靜止切片和移動切片的距離,s、m分別為靜止距離系數(shù)與移動距離系數(shù)。通過與1.1節(jié)類似的參數(shù)實驗,設(shè)置Kd=1,Kl=2,s=1.5,m=1。由于紋理對象優(yōu)先級的比較分別在StableArea、ActiveArea和UnusedArea內(nèi)部進行比較,同一區(qū)域內(nèi)部的紋理對象被訪問時間大致相同,因此,沒有將時間因素納入紋理對象的優(yōu)先級計算模型。
當上述某個分區(qū)空間被占滿并且有新的紋理對象加入該區(qū)域時,則選取該區(qū)域中Pgpu值最大的紋理對象置出。如圖4所示,從StableAre區(qū)域置出的紋理對象被放入ActiveArea,從ActiveArea置出的紋理對象被移動到UnusedArea,而從UnusedArea置出的紋理對象將被從顯存中移除。
2 兩階段切片實時交互與漸進繪制
在大規(guī)模地震體可視化中,始終存在繪制效率與顯示質(zhì)量的矛盾,該矛盾在計算資源有限的普通計算平臺上尤為突出。為了平衡繪制效率與顯示質(zhì)量之間的矛盾,本文設(shè)計了面向兩階段的切片實時交互與漸進繪制策略,并且針對漸進細化階段應(yīng)用信息熵對體塊的細化過程進行優(yōu)化,有效地提高了繪制質(zhì)量。
2.1 兩階段繪制策略
面向兩階段的切片實時交互與漸進繪制策略將切片的交互繪制分為兩個階段——交互階段與漸進細化階段,處理流程如圖5所示。首先,在交互階段為了滿足交互的實時性,適應(yīng)性地預(yù)留部分內(nèi)存作為常駐內(nèi)存來使用:即根據(jù)系統(tǒng)內(nèi)存大小,分配一定比例空間來存放整個體數(shù)據(jù)相應(yīng)層次的體塊數(shù)據(jù)(例如用系統(tǒng)20%的內(nèi)存來存放第3級分辨率的數(shù)據(jù)塊)。當切片移動時,使用該層次體塊數(shù)據(jù)進行切片的繪制與顯示,從而可以減少 輸入/輸出(Input/Output, I/O)操作帶來的消耗,保證交互的流暢性。
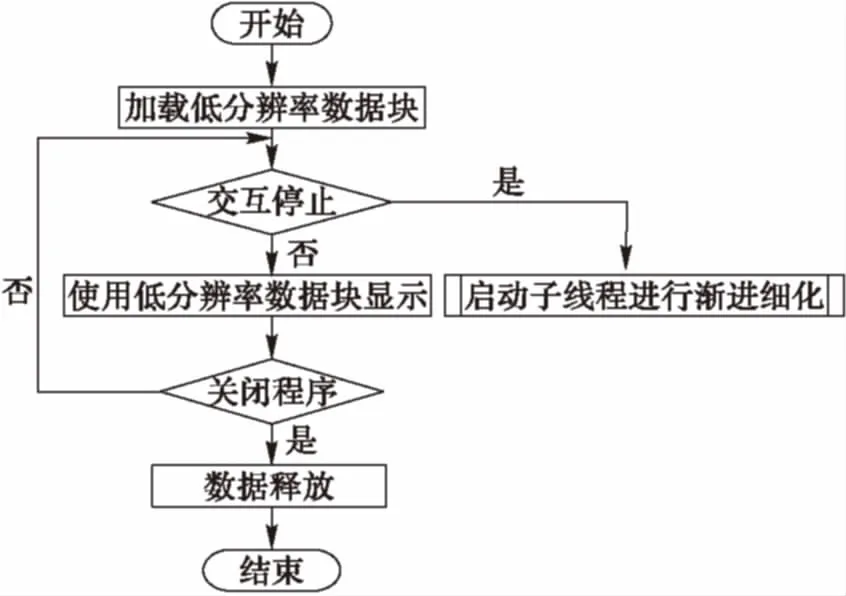
圖5 兩階段繪制策略流程
其次,為了得到更高的繪制質(zhì)量,在切片交互停止之后,啟動漸進細化線程,根據(jù)切片繪制所使用的體塊與視點的空間位置關(guān)系,逐漸完成切片的細化,得到更高分辨率的圖像。如圖6所示,根據(jù)體塊與視點的距離,優(yōu)先細化距離視點更近的區(qū)域,圖中區(qū)域一為細化完成部分,區(qū)域二正在細化的區(qū)域,區(qū)域三為待細化的區(qū)域。如果在切片漸進細化過程中,再次進行切片交互操作,則立即暫停細化線程,響應(yīng)用戶的交互操作,使用常駐內(nèi)存的較低分辨率的體塊進行繪制。
上述兩個繪制階段側(cè)重點有所不同。交互階段注重提高繪制效率保證實時交互,漸進繪制階段則著重于繪制更高分辨率圖像以提高顯示效果。該策略可以有效地平衡交互效率與繪制質(zhì)量之間的矛盾,使得在普通計算平臺上可以更高效地進行大規(guī)模地震體交互操作并得到較高的繪制質(zhì)量。
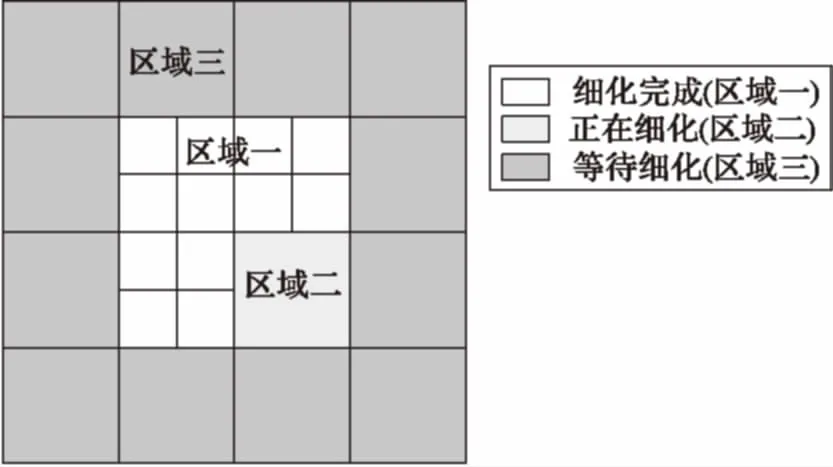
圖6 切片逐區(qū)域漸進細化示意圖
2.2 基于信息熵的體塊細化
盡管地震體的八叉樹結(jié)構(gòu)中包含大量體塊,但從應(yīng)用角度看它們的“價值”是不同的,其中某些是“低價值”體塊,例如體塊數(shù)據(jù)中地質(zhì)屬性值單一的體塊。如圖7所示,在地層1與地層5中被虛線框包圍的體塊即為“低價值”體塊。這些體塊所蘊含的信息量較少,對其進行細化會占用大量的存儲空間并且對最終的可視化效果提升不明顯。而用戶會更多地關(guān)注位于地層交界區(qū)域蘊含信息較多的體塊。
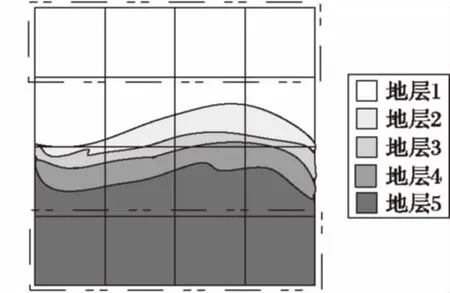
圖7 地震體中地層分布示意圖
信息論中用“信息熵”來描述一個系統(tǒng)所蘊含的信息量。“信息熵”越大,系統(tǒng)所包含的信息量也越大。用戶對含有信息量較大即“信息熵”較大的體塊更“感興趣”。梁榮華等[13]在基于統(tǒng)一劃分的分塊策略中,采用香農(nóng)熵進行自適應(yīng)分塊的多分辨率選擇,得到了較好的繪制質(zhì)量。本文運用信息熵對八叉樹體塊的細化過程進行優(yōu)化,面向應(yīng)用降低“低價值”體塊的細化級別,可以減少系統(tǒng)資源的占用,使含有較多信息的用戶感興趣區(qū)域能夠得到更充分細化,從而獲得更高的繪制質(zhì)量。“信息熵”的計算模型為:
(3)
上述計算模型(3)中,p(xi)為屬性值xi在系統(tǒng)中出現(xiàn)的概率。在地震體數(shù)據(jù)的預(yù)處理階段,統(tǒng)計體塊中每個體素的屬性值xi出現(xiàn)的概率p(xi),再對p(xi)進行對數(shù)運算,最后進行加權(quán)平均計算得到體塊信息熵的值H,并將體塊的信息熵保存下來。
在體塊細化過程中,根據(jù)設(shè)置的信息熵下限閾值(如Hmin=0.1),進行以下處理:
1)首先根據(jù)體塊與視點的空間位置關(guān)系判斷該體塊是否需要進行細化;
2)如果該體塊需要進行細化,則從外存中讀取該體塊信息熵的值H,并與閾值Hmin進行比較;
3)若H>Hmin則對該體塊進行細化;
4)否則,認為該體塊所蘊含的信息量過少,不對其進行細化。
基于信息熵的體塊細化調(diào)優(yōu)可以有重點地對用戶感興趣區(qū)域進行細化,在內(nèi)存資源有限的普通計算平臺上得到更高的繪制質(zhì)量。如圖8所示,優(yōu)化后與優(yōu)化前相比,在地層交界處有更高的分辨率,有效提高了切片的顯示質(zhì)量。
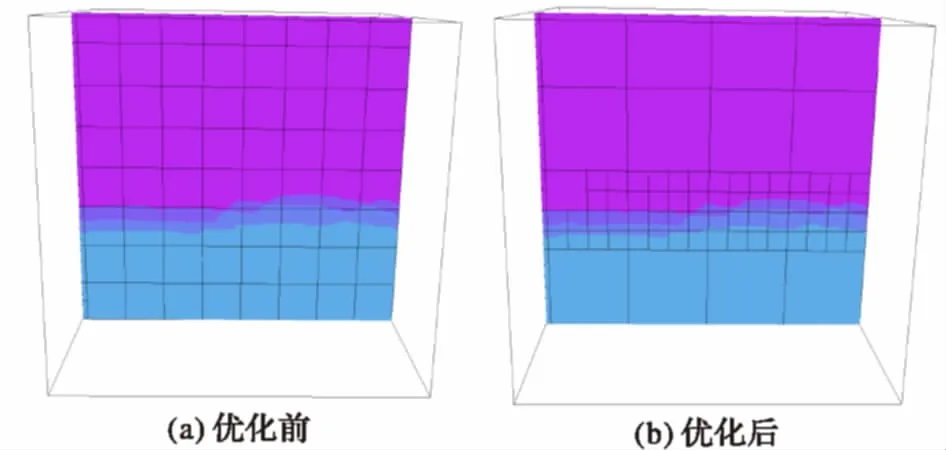
圖8 使用信息熵優(yōu)化前后繪制效果對比
3 測試實例與實驗分析
本文針對數(shù)據(jù)量為500 MB、4 GB、38 GB的sgy數(shù)據(jù)進行預(yù)處理,得到數(shù)據(jù)量分別為771 MB、5.26 GB、46.3 GB的八叉樹結(jié)構(gòu)文件,在此基礎(chǔ)上作為測試數(shù)據(jù)進行實驗與分析。實驗所用計算機為普通便攜式PC,配置如下:CPU為Intel Core i5-2410 M(雙核四線程),主頻為2.3 GHz,4 GB內(nèi)存,NVIDIA GeForce GT520M獨立顯卡(1GB顯存),750 GB硬盤(7 200 轉(zhuǎn)/min)。
在三切片交互顯示場景下,除應(yīng)用LRU算法外,還使用最不經(jīng)常使用(Least Frequently Used, LFU)算法和先進先出(First In First Out, FIFO)算法這兩種基于時間度量的調(diào)度算法與本文算法作對比測試,如圖9所示為不同數(shù)據(jù)規(guī)模下4種算法對體塊平均命中率的影響。實驗中緩沖區(qū)大小設(shè)置為400塊(每塊的大小為64×64×64),在三個方向上的切片交互順序隨機,分別進行30次交互操作。從圖中可以看出,在不同的數(shù)據(jù)集上MDFO調(diào)度策略均有較高命中率,而前三種算法的命中率沒有太大區(qū)別。在不同數(shù)據(jù)集上,MDFO算法與其他三種算法相比,體塊的命中率提升均在10%以上,并且隨著數(shù)據(jù)規(guī)模的增大體塊命中率提升的比例逐漸提高,在38 GB的數(shù)據(jù)集上提升比例可以達到60%以上。平均命中率的具體數(shù)值如表1所示。
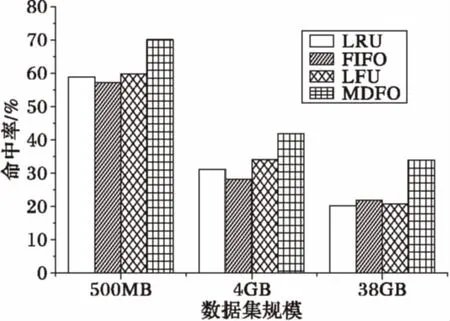
圖9 MDFO與 LRU等其他調(diào)度策略的平均命中率對比
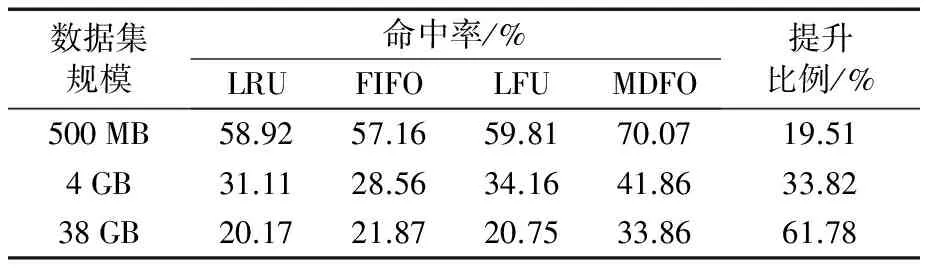
表1 各調(diào)度策略命中率對比
圖10展示了基于距離度量的GPU紋理對象調(diào)度策略與GPU默認的LRU調(diào)度策略在多切片交互時紋理對象命中率的對比。圖中縱軸為紋理對象的命中率,橫軸為紋理對象緩存空間與繪制一幀所使用紋理對象占用的存儲空間的比值(記為R)。由測試結(jié)果可以發(fā)現(xiàn),R減小導(dǎo)致紋理對象的命中率不斷下降。當R為1.5∶1即顯存容量與繪制所需的顯存空間接近時,基于距離的紋理對象緩存調(diào)度算法依舊可以保持12%左右的命中率,而GPU默認的調(diào)度策略僅有不到5%的紋理對象命中率。
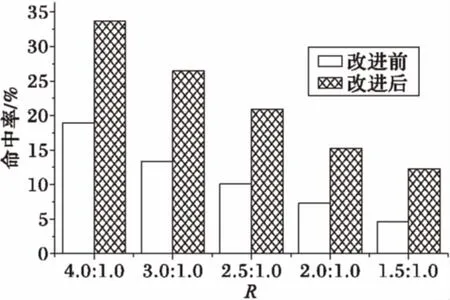
圖10 紋理對象調(diào)度策略改進前后命中率對比
圖11為面向兩階段繪制策略的交互階段與漸進繪制完成后的顯示效果對比。可以看出在交互階段切片的繪制質(zhì)量不高,并且沒有針對地層交界區(qū)域進行細化。而經(jīng)過漸進細化階段后得到的圖像繪制質(zhì)量明顯提高,并且針對地層交界區(qū)域也進行了細化。
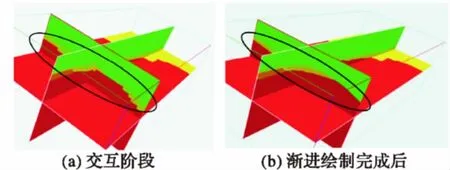
圖11 交互階段與漸進繪制完成后顯示效果對比
表2記錄了針對不同數(shù)據(jù)集所進行的單階段繪制與兩階段繪制效率對比。

表2 單階段繪制與兩階段繪制效率對比
實驗中使用八叉樹中第3層節(jié)點對應(yīng)的體塊數(shù)據(jù)作為緩存進行交互階段的繪制。從結(jié)果可以看出,隨著數(shù)據(jù)集規(guī)模的不斷增長,交互階段依舊可以保持較高的繪制效率;而漸進細化繪制階段的耗時有所增加,但該過程可以隨時終止。單階段繪制在交互繪制過程中需要進行頻繁的數(shù)據(jù)加載,導(dǎo)致交互繪制效率較低,而兩階段繪制在交互階段使用緩存進行繪制,因而可以達到較高的繪制效率。傳統(tǒng)的單階段繪制由于工作集中體塊數(shù)量的限制,在38 GB數(shù)據(jù)集上進行交互繪制時只能細化到八叉樹的第6層。在應(yīng)用信息熵進行優(yōu)化后,兩階段繪制的細化階段則可以細化到八叉樹的第7層(最精細層),因此可以實現(xiàn)更高的繪制質(zhì)量。
4 結(jié)語
針對在內(nèi)存和顯存等資源有限的通用計算機平臺上進行大規(guī)模地震體切片實時交互與高質(zhì)量顯示存在的問題,本文采用多層多分辨率的八叉樹結(jié)構(gòu)對原始地震體數(shù)據(jù)進行重新組織,設(shè)計了基于距離度量的體塊緩存與調(diào)度機制以及GPU紋理對象的緩存與調(diào)度策略。與傳統(tǒng)調(diào)度策略相比,該方法有效提高了體塊數(shù)據(jù)與紋理對象的命中率,減少了外存到內(nèi)存以及內(nèi)存到顯存的數(shù)據(jù)加載次數(shù),提高了可視化交互與顯示的效率。同時設(shè)計了面向兩階段的切片實時交互與漸進繪制策略,進一步平衡了在計算資源有限的普通計算平臺上進行大規(guī)模地震體可視化時繪制效率與顯示質(zhì)量之間的矛盾,并且通過信息熵優(yōu)化了體塊的細化過程,保證了用戶關(guān)心區(qū)域以更高的分辨率進行繪制。
進一步研究將結(jié)合領(lǐng)域特點和用戶需求優(yōu)化體塊多分辨率篩選機制,即用戶通過設(shè)定部分高優(yōu)先級體塊作為興趣區(qū)域,根據(jù)選定的興趣區(qū)平滑選擇剩余體塊,通過這種可定制的多分辨率顯示機制,使切片交互顯示在效率和質(zhì)量上更適合于大規(guī)模地質(zhì)勘探數(shù)據(jù)的應(yīng)用。
References)
[1] CHAMBERS H, BROWN A L. 3D visualization continues to advance integrated interpretation environment [J]. First Break, 2003, 21(5): 67-70.
[2] PLATE J, TIRTASANA M, CARMONA R, et al. Octreemizer: a hierarchical approach for interactive roaming through very large volumes [C]// Proceedings of the 2002 Symposium on Data Visualisation. Aire-la-Ville, Switzerland: Eurographics Association, 2002: 53-60.
[3] 原達,劉日晨,袁曉如.探地數(shù)據(jù)可視化研究[J].計算機輔助設(shè)計與圖形學(xué)學(xué)報,2015,27(1):36-45.(YUAN D, LIU R C, YUAN X R. Seismic visualization [J]. Journal of Computer-Aided Design & Computer Graphics, 2015, 27(1): 36-45.)
[4] WONG P C, SHEN H W, CHEN C, et al. Top ten interaction challenges in extreme-scale visual analytics [J]. IEEE Computer Graphics and Applications, 2012, 32(4): 197-207.
[5] LIU B, CLAPWORTHY G J, DONG F, et al. Octree rasterization: accelerating high-quality out-of-core GPU volume rendering [J]. IEEE Translations on Visualization and Computer Graphics, 2013, 19(10): 1732-1745.
[6] CULLIP T J, NEUMANN U. Accelerating volume reconstruction with 3D texture hardware [EB/OL]. [2017- 01- 02]. http://graphics.usc.edu/cgit/publications/papers/Volume_textures_93.pdf.
[7] LAMAR E, HAMANN B, JOY K. Multiresolution techniques for interactive texture-based volume visualization [C]// VIS’99: Proceedings of the 10th IEEE Visualization 1999 Conference. Washington, DC: IEEE Computer Society, 1999: 355-361.
[8] BOADA I, NAVAZO I, SCOPIGNO R. Multiresolution volume visualization with a texture-based octree [J]. The Visual Computer, 2001, 17(3): 185-197.
[9] GUTHE S, WAND M, GONSER J, et al. Interactive rendering of large volume data sets [C]// VIS’02: Proceedings of the 2002 Conference on Visualization. Washington, DC: IEEE Computer Society, 2002: 53-60.
[10] SCHNEIDER J, WESTERMANN R. Compression domain volume rendering [C]// VIS’03: Proceedings of the 2003 14th IEEE Visualization. Washington, DC: IEEE Computer Society, 2003: 293-300.
[11] 魏嘉,唐杰,武港山,等.三維地震數(shù)據(jù)體多分辨率數(shù)據(jù)組織與管理技術(shù)研究[J].石油物探,2010,49(3):240-244.(WEI J, TANG J, WU G S, et al. Multi-resolution organization and management of massive 3D seismic data volume [J]. Geophysical Prospection for Petroleum, 2010, 49(3): 240-244.)
[12] XUE J, KE L. Volume visualization for out-of-core 3D images based on semi-adaptive partitioning [C]// Proceedings of the 2015 IEEE International Conference on Image Processing. Piscataway, NJ: IEEE, 2015:1503-1507.
[13] 梁榮華,薛劍鋒,馬祥音.自適應(yīng)分塊細節(jié)水平的多分辨率體繪制方法[J].計算機輔助設(shè)計與圖形學(xué)學(xué)報,2012,24(3):314-322.(LIANG R H, XUE J F, MA X Y. Multi-resolution volume rendering based on adaptive bricking LOD [J]. Journal of Computer-Aided Design & Computer Graphics, 2012, 24(3): 314-322.)
Optimizingmulti-slicereal-timeinteractivevisualizationforout-of-coreseismicvolume
JI Lianen*, ZHANG Xiaolin, LIANG Shiyi, WANG Bin
(DepartmentofComputerScienceandTechnology,ChinaUniversityofPetroleum,Beijing102249,China)
During multi-slice interactive visualization for out-of-core seismic volume on common computing platform, traditional cache scheduling approaches, which take no account of the spacial relationship between blocks and slices, lead to the low cache hit rate while interacting. And it’s also difficult to achieve high rendering quality by use of common multi-resolution rendering methods. In view of these problems, a cache scheduling strategy named Maximum Distance First Out (MDFO) was designed. Firstly, according to the spatial position of the interactive slice, the scheduling priority of the block in the cache was improved, which ensures that the candidate block has a higher hit rate when the slice interacts continuously. Then, a two-stage slice interaction method was proposed. By using the fixed resolution body block to ensure the real-time interaction, the final display quality was improved by the step-by-step refinement, and the information entropy of the block data was further combined to enhance the resolution of the user’s region of interest. The experimental results show that the proposed method can effectively improve the overall hit rate of the body block and reach the proportion of more than 60%. Meanwhile, the two-stage strategy can achieve higher quality images for application-oriented requirements and resolve the contradiction between interaction efficiency and rendering quality for out-of-core seismic data visualization.
volume visualization; multi-slice interaction; cache scheduling; two-stage rendering; information entropy
2017- 03- 14;
2017- 04- 17。
國家自然科學(xué)基金資助項目(60873093)。
紀連恩(1972—),男,山東高唐人,副教授,博士,CCF會員,主要研究方向:可視化技術(shù)、計算機圖形學(xué)、人機交互; 張笑林(1991—),男,山東濱州人,碩士研究生,主要研究方向:可視化技術(shù)、計算機圖形學(xué); 梁適宜(1992—),男,遼寧錦州人,碩士研究生,主要研究方向:可視化技術(shù)、計算機圖形學(xué); 王斌(1993—),男,黑龍江大慶人,碩士研究生,主要研究方向:可視化技術(shù)、計算機圖形學(xué)。
1001- 9081(2017)09- 2621- 05
10.11772/j.issn.1001- 9081.2017.09.2621
TP391.41
A
This work is partially supported by the National Natural Science Foundation of China (60873093).
JILianen, born in 1972, Ph. D., associate professor. His research interests include visualization techniques, computer graphics, human-computer interaction.
ZHANGXiaolin, born in 1991, M. S. candidate. His research interests include visualization techniques, computer graphics.
LIANGShiyi, born in 1992, M. S. candidate. His research interests include visualization techniques, computer graphics.
WANGBin, born in 1993, M. S. candidate. His research interests include visualization techniques, computer graphics.
