基于引導Boosting算法的顯著性檢測
2017-11-15 06:02:44葉子童范賜恩
計算機應用 2017年9期
葉子童,鄒 煉,顏 佳,范賜恩
(武漢大學 電子信息學院,武漢 430072)(*通信作者電子郵箱zoulian@whu.edu.cn)
基于引導Boosting算法的顯著性檢測
葉子童,鄒 煉*,顏 佳,范賜恩
(武漢大學 電子信息學院,武漢 430072)(*通信作者電子郵箱zoulian@whu.edu.cn)
針對現有的基于引導學習的顯著性檢測模型存在的訓練樣本不純凈和特征提取方式過于簡單的問題,提出一種改進的基于引導(Boosting)的算法來檢測顯著性,從提升訓練樣本集的準確度和改進特征提取的方式來達到學習效果的提升。首先,根據顯著性檢測的自底向上模型產生粗選樣本圖,并通過元胞自動機對粗選樣本圖進行快速有效優化來建立可靠的引導樣本,完成對原圖的標注建立訓練樣本集;然后,在訓練集上對樣本進行顏色紋理特征提取;最后,使用不同特征不同核的支持向量機(SVM)弱分類器生成基于Boosting學習一個強分類器,對每幅圖像的超像素點進行前景背景分類,得到顯著圖。在ASD數據庫和SED1數據庫上的實驗結果顯示該模型能對復雜和簡單的圖像生成完備清晰的顯著圖,并在準確率召回率曲線和曲線下面積(AUC)測評值上有較大提升。由于其準確性,能應用在計算機視覺預處理階段。
顯著性檢測;boosting;自底向上模型;粗選樣本優化;顏色特征提取
0 引言
顯著性檢測在計算機視覺中常被作為一種預處理手段,在圖像分割[1-2]、目標識別[3]、圖像檢索[4]、自適應壓縮[5]、內容感知[6]等領域有著廣泛的應用。顯著性檢測模型可以分為自底向上的目標驅動模型[7-10]和自頂向下的任務驅動模型[11-13]。前者與人類視覺系統對外界的自下而上、快速的、任務無關的階段相對應,從底層視覺信息出發,對細節信息的檢測比較好;后者與人類視覺系統對外界視覺感知的自上而下、意識驅動、任務相關的階段相對應,一般從訓練樣本中獲取更典型的特征,通常比較粗糙但能有較好的全局形狀。
顯著圖反映了圖像中不同區域的顯著程度,而理想的顯著性檢測模型是得到顯著性目標和背景的二值圖,在這樣的任務驅動下,自頂向下的顯著性檢測可以是對于圖像的有意識帶需求的訓練學習。采用學習的方法來進行顯著性檢測能夠取得較好的全局表現,但是需要參考樣本。對圖像進行標記建立參考然后從大量樣本中學習特征的方式顯然過于復雜,不足以應對實時快速的處理要求。考慮到基于自底向上的顯著性檢測模型能生成原圖的弱顯著圖,盡管該顯著圖缺乏全局信息,檢測效果具有局限性,但是可以作為原圖的粗糙參考,引導學習(Bootstrap Learning, BL)[14]算法提出可以采用自底向上的模型生成的樣本來引導特征學習,即采用弱顯著圖對原圖作一次簡單的標記(根據圖中像素塊的顯著性值設定正負種子),利用原圖中選取的正負樣本種子訓練一個分類器。這種方法使得監督學習的過程可以變為無監督的,省去了繁瑣的人工標注和離線訓練。但是用于引導的樣本的準確性很大程度上決定了特征學習的效果,在原算法中存在參考過于粗糙導致樣本選擇不純凈和分類器的特征提取方式過于簡單的問題。針對以上問題,本文提出:1)采用優化處理后的樣本來進行引導以減少誤分類,提升顯著性檢測的效果;2)改進特征提取的方式。本文將學習的過程限定在每幅圖像中,可以適應每幅圖像的差異性,且去掉了人工標注的過程,是一種自生成參考的學習模型。
將基于自底向上的檢測模型生成的顯著圖作為粗選樣本圖,本文提出對于粗選樣本圖進行快速有效的優化處理得到引導樣本圖,對每幅圖像建立參考。引導樣本圖是基于底層圖像特征生成且演化更新的,雖然缺少完善的形狀信息但是在細節上表現優異,其中有部分很準確的前景背景點。同時本文選用了新的顏色特征描述子,并在學習的過程中加上了紋理特征,新的顏色特征描述方式避免了原有的特征選取中由于超像素點內像素值間顏色差異較大時帶來的訓練效果偏差。利用Boosting算法從多個弱分類器學習一個強分類器對原圖的所有超像素點進行分類,對結果加以平滑后得到最終的顯著圖。
如圖1所示,原算法選用粗糙的參考樣本進行學習,由于訓練樣本的不純凈,錯誤的樣本種子可能導致學習效果的下降,最終得不到顯著性物體或者誤將背景作為前景。

圖1 粗選樣本圖和優化樣本圖引導Boosting的結果比較
1 研究現狀
人類視覺系統的研究表明,顯著性有關某一場景的唯一性、稀有程度、驚奇度,而這些是由如色彩、紋理、形狀等基本特征表達的[15]。在顯著性檢測的自底向上模型中常常從圖像底層線索出發使用各種先驗信息,如對比度先驗[15-16]、邊界先驗、中心先驗[17]和暗通道先驗[18]、背景先驗[19-23]等。Wei等[20]將圖像邊界作為背景并把每個圖像塊與背景的最短距離定義為該區域塊的顯著性值。Zhu等[23]定義了一個有認知幾何解釋的量,即區域在邊界上的周長與該區域面積的平方根之比,稱之為邊界連接度并用以衡量區域的顯著性。Tong等[14]將超像素點與邊界區域的顏色紋理對比度作為超像素點的顯著性值。
自頂向下的顯著性檢測模型由任務驅動,文獻[23]中根據圖像的顯著性檢測問題建立一個最優化模型。文獻[14]中通過從樣本集中學習的一個分類器對圖像中所有超像素點進行顯著性物體和背景的二分類。自底向上模型從底層圖像線索出發,缺乏全局形狀信息,檢測效果有一定的局限性。而基于學習的方法建立自頂向下的模型則具有樣本依賴性,粗糙參考會帶來學習效果下降,精確標注又需要繁瑣的過程,因此本文選擇建立一個優化預處理過程來連接兩種模型。利用底層圖像特征得到的顯著圖作為粗選樣本圖,通過優化過程對粗選樣本圖進行優化,以達到建立可靠參考和選取準確訓練樣本集的目的,盡量降低了學習前訓練樣本集建立的復雜度且提高了樣本的可靠性。 具體的框架如圖2所示。

圖2 本文算法的框架
2 改進的基于引導的Boosting算法
本文的自生成參考的學習模型是通過提升訓練樣本集的準確度和改進特征提取的方式著手來實現學習效果的提升。具體算法為:
步驟1 基于自底向上模型生成粗選樣本圖,并采用元胞自動機的優化策略得到引導樣本圖,生成訓練樣本集;
步驟2 對所有樣本使用改進后的顏色及紋理特征提取方式進行特征提取;
步驟3 對提取的特征進行學習,采用Adaboost的方法訓練強分類器;
步驟4 利用分類器對原圖所有超像素點進行分類,平滑后得到最終的顯著圖。
2.1 訓練樣本集生成
生成訓練樣本集的參照圖分為兩個過程:建立粗選樣本圖,粗選樣本圖是基于自底向上模型得到的顯著圖,是對原圖的粗糙標記;對粗選樣本圖進行優化處理得到引導樣本圖,引導樣本圖是優化后顯著性物體與背景趨于分離的較高質量的顯著圖。最終基于參考圖在原圖中選取關鍵超像素點來建立訓練樣本集。整個過程在每幅圖像中單獨進行。
2.1.1 粗選樣本圖
對于一幅300×400的圖像,對所有的像素點進行計算的時間復雜度過高,采用超像素可以降低時間復雜度。本文中采用了簡單線性迭代聚類(Simple Linear Iterative Clustering, SLIC)[24-25]算法來產生超像素,每幅圖像選取N=300個超像素,提高了計算效率同時對于小尺度的顯著性目標也能兼容,超像素的顏色為超像素集合內的像素點的顏色均值。
自底向上的顯著性檢測模型,從圖像既有的基本特征——顏色特征出發,基于對比度先驗和邊界先驗來計算顯著性值,生成粗選樣本圖。不同于RGB色彩空間,LAB顏色更接近于人類的生理視覺,L分量能夠密切匹配人類的亮度感知,它彌補了RGB色彩模型的色彩分布不均的問題,所以本文中用RGB特征和LAB特征共同描述顏色特征,從而起到相互補充的作用。
超像素點的顯著性值為該超像素點和所有邊界超像素點的兩種顏色對比度之和,計算公式如式(1):

(1)
其中:dk(si,sj)是超像素點si和sj在第k顏色空間的歐氏距離,NB是邊界超像素的個數。
以超像素點的顯著性值為其像素值,就得到了一幅圖像的粗選樣本圖。粗選樣本圖的計算從對120 000個像素點的計算降低為對300個像素點的計算,且將全局對比度改為只對邊界的對比度,極大地提高了計算效率。從圖3中可以看出粗選樣本中含有較多的分散的噪點,要對原圖有更精確的參考標注,就需要使前景物體和背景各自聚集,將選作訓練樣本的超像素點的置信度盡可能提高。為了得到一些更準確的超像素點用作訓練,下文中提出了訓練集建立前從粗選樣本圖到引導樣本圖的預處理步驟。為保持計算的統一,本文中的所有顯著性值都進行了歸一化處理。
2.1.2 引導樣本圖
粗選樣本圖中存在部分背景超像素點的顯著性值過高,這些超像素容易被當作正樣本引入訓練樣本集,因此對整個粗選樣本圖進行優化處理是有必要的。
顯著性物體總是趨向于聚集的,而元胞自動機[19,26]可以探索鄰居間的本質聯系,并減少相似區域間的差異性,因此利用元胞自動機來優化粗選樣本圖是有效的。將粗選樣本圖中的每個超像素看作一個元胞,對所有元胞的顯著性值進行演化和更新。粗選樣本圖的元胞當前顯著性值組成初始向量S0=[Saliency(s1),Saliency(s2),…,Saliency(sN)]。下一狀態下的顯著性值St+1由周邊元胞和自身元胞共同決定。本文算法以影響因子矩陣和置信度矩陣來表征下一狀態和當前狀態的關系。
影響因子矩陣衡量周邊元胞對元胞下一狀態的影響。F=[fij]N×N是N維矩陣(N為元胞的個數,矩陣的元素表示元胞sj對元胞si的影響因子),矩陣元素計算公式如式(2):
(2)
其中dlab(si,sj)表示元胞si和sj在CIELAB空間的歐氏距離,σ2是一個可調參數用于控制影響程度,文中設定為σ2=0.1。
置信度矩陣C表征元胞下一狀態與當前自身元胞狀態的關系權重。置信度越高下一狀態越依賴當前狀態,置信度矩陣是對角陣,對角元素的計算公式如式(3):
ci=1/max(fij)
(3)
得到置信度矩陣和影響因子矩陣后按照如下規則使元胞自動更新演化。設定更新公式為:
St+1=C·St+(I-C)·F·St
(4)
其中:I為單位矩陣,初始狀態S0就是粗選樣本中的超像素點的顯著性值向量。一般進行N1=15次的更新就可以取得較好的效果。最終狀態下SN1的就是優化后的超像素點的顯著性值向量。將每個超像素值平均到每個像素點上,就可以得到較為精準的引導樣本圖。影響因子矩陣的計算復雜度為O(N2),更新過程只需進行15次矩陣運算,整體復雜度很低,因而元胞自動機的優化處理是高效的。
如圖3(b)所示,粗選樣本圖中會在背景點處出現較亮的點,基于一定的樣本選取規則,若采用粗選樣本圖作為參考會導致樣本集的不純凈,帶來學習效果的下降。因此用優化后的引導樣本圖建立訓練樣本集和引導隨后的Adaboost學習強分類器更為可靠。

圖3 粗選樣本圖優化的結果
2.1.3 樣本選取規則

2.2 特征提取
選取特征是建立學習模型中關鍵的一步,選取的特征很大程度上決定了學習效果。在顯著性檢測問題中,顏色特征是必不可少的,一般的提取方式為以超像素的顏色值,也就是超像素內所有像素點在R,G,B各個通道上的平均值作為RGB域的三維特征,以RGB特征為例,超像素點si的特征向量Fsi為:
(5)
其中:Nsi為超像素點si內像素點的個數,j為超像素點內的像素點,rj為像素點的r通道顏色值。LAB特征也是如此。但是通過隨機選取多幅圖像,對其按照該方式進行特征提取,發現這種方式舍棄了超像素內的顏色分布信息,當超像素內像素顏色相近時可能問題不大,但是如果超像素內像素間顏色變化過大導致平均值并不能代表超像素的顏色特征時就會產生誤差,甚至可能出現像素點的顏色誤差相互抵消導致正樣本和負樣本具有相同的特征分布的情況,對于分類器的分類效果產生影響。如圖4所示,對于隨機選取的一幅圖像,根據上文中所述建立參考圖基于樣本選取規則得到的正樣本為前29組,負樣本為后216組,以特征的維數作為橫坐標,特征值作為縱坐標,繪制為散點圖,并用加號點表示正樣本,空心點表示負樣本,可以明顯地看出正負樣本的特征區別度不大容易出現交叉,且正樣本的特征分布并不具備較好的一致性,如果用于訓練則會影響到學習的效果。

圖4 三維的RGB特征
2.2.1 顏色特征提取
針對以上問題,在RGB和LAB空間中提取特征時提出新的方式,仍然以RGB域為例:
步驟1 本文首先將原圖在RGB空間進行量化。將原圖在三個通道上都量化至12個bin,bini,k表示k通道下第i個bin的顏色范圍,k∈{r,g,b},i∈{1,2,…,12};
(6)
步驟2 對超像素內的所有像素點分別在三個通道下進行直方圖統計,得到表征顏色值落在每個bin上的像素點個數的3組12維向量;
(7)
步驟3 將這三組向量串聯成為36維向量作為超像素點在RGB空間的特征向量。
Fsi=[Rsi,Gsi,Bsi]
(8)
為了量化的準確性,并非在各個通道的固有范圍上量化,而是計算出每幅圖像在各個通道的最大最小值來作為量化的起點和終點,這樣能減小不必要的誤差,使結果更準確。
特征向量的每一維的值代表了落在固有顏色區間上的像素點個數,既隱式地表征了其顏色值又顯式地表明了超像素點內顏色分布情況。可以兼顧到圖像的顏色變化,背景的超像素點的顏色集中在某些區間,而正樣本往往在多個區間都有顏色分布,缺少顏色的分布信息會帶來誤分類。采取串聯的方式,一是因為本文中的訓練是針對每幅圖像進行的,訓練樣本集中樣本數較少,如果按照量化后的顏色種類進行統計,例如在RGB空間中量化后的顏色種類為123,會出現維數較大與訓練樣本數量不匹配的情況;二是實驗顯示串聯得到的特征向量計算復雜度較低且能較好地表明超像素內的顏色及其分布。如圖6所示,同樣的一幅圖像,采取本文的特征提取方式,繪制出正負樣本的散點圖,加號表示正樣本,空心號表示負樣本,并擬合出正樣本的包絡為虛曲線,負樣本的包絡為實曲線。可以看出正負樣基本沒有交叉,兩者有較大的區分。從圖中也可以看出,正樣本在各個通道中的顏色值分布并非集中在某個值上,如果單獨地采用顏色的均值得到的三維特征,效果就會出現偏差。

圖5 36維的RGB特征
在CIELAB空間上則只需量化到更少的bin上[27],本文將其分別在三個通道內都量化至8個bin。采用和RGB空間內同樣的方法,將3個8維向量串聯成的24維的特征向量作為超像素點在CIELAB空間內的特征向量。相比文獻[14]中BL的特征選擇方式,本文的方法更能兼顧超像素點內的結構信息和細節,使分類的結果更優。
使用新的顏色特征提取方法和原始的特征提取方法,基于本文算法模型得出的實驗結果對比如圖6。

圖6 顏色特征提取方式不同的結果
2.2.2 紋理特征提取
考慮到顯著性物體和背景可能在顏色上相似而存在著紋理上的區別,算法中添加了紋理特征局部二值模式(Local Binary Mode, LBP)用于分類。相較于BL算法中使用的基本的LBP算子,本文算法選用了旋轉不變的LBP算子,這樣的方式對于圖像的旋轉表現得更為魯棒。對每個像素點取其圓形鄰域,不斷旋轉該圓形鄰域得到一系列初始定義的LBP值,取最小值作為該鄰域的LBP值。將每個超像素內的所有像素點的LBP值賦予0~58的數值;然后統計超像素內的各個像素點的LBP值,這樣就可以得到一個59維的特征向量。
對僅采用顏色算子、采用普通LBP算子和采用旋轉不變的LBP算子進行對比實驗。可以看出當圖像具有顯著性物體和背景顏色近似,但紋理有差別時,使用旋轉不變的LBP算子顯然能得到更優的結果。

圖7 LBP算子對比實驗結果
2.3 Adaboost
考慮到對于不同的特征使用不同核函數的支持向量機(Support Vector Machine, SVM)能使分類的結果更為準確[28],本文算法采用不同特征和不同核的SVM作為弱分類器,然后采用Adaboost的方法訓練得到強分類器。文中采用Nf=Nfeature×Nkernel種不同的標準SVM分類器,其中Nfeature是特征的數量,Nkernal是核函數的數量,本文中采用4種不同的核函數:Linear、Polynomial、徑向基函數(Radial Basis Function, RBF)和Sigmoid。Nf種標準SVM線性組合后的決策函數如式(9)所示:
(9)

(10)

(11)
為了計算系數βj,采用了Adaboost的方法。J表示增強過程的迭代次數。學習的過程如下:
步驟1 將樣本集中每個超像素si的權重初始化為同一個值w0(si)=1/P(i=1,2,…,P),同時為每一個弱分類器設定一組目標函數{zn(s),n=1,2,…,Nf};
步驟2 用弱分類器對樣本進行學習,并計算錯誤率{εn},找到最小的錯誤率εj和對應的弱分類器目標函數zj(s),根據式(12)計算對應弱分類器的結合系數:
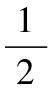
(12)
步驟3 根據式(13)來更新樣本權重,并跳轉回步驟2進行下一次的迭代直至完成J次迭代:

(13)
J次迭代之后, 即得到了J組βj和zj(s)的值,生成了一個強分類器。用強分類器對所有超像素進行分類得到超像素級別的灰度圖,并生成像素級別的顯著圖。對該顯著圖進行圖割平滑:采用最大流分割算法[29]來得到顯著圖的二值分割圖,加在原顯著圖上作為最終的顯著圖。
3 實驗結果
將算法在數據集ASD和SED1上進行實驗驗證。ASD數據集是來自于MASR數據集的1 000張圖片,其中多為單一目標且背景比較簡單的圖像。而SED1數據集中有包含單個目標背景較復雜的100張圖片,規模小但是難度比較大。本文采用定量測評的方式,按照[0,255]的所有閾值將顯著圖進行二值化,計算每個閾值下的平均準確率值和召回率值, 從而得到準確率-召回率曲線和曲線下面積(Area Under Curve, AUC)值。將本文算法(Ours)的結果和其他8種模型,即BL,BSCA (Background Single Cellular Automata)[19]、FT(Frequency-Tuned algorithm)[30]、GC(Global Contrast method)[15]、HC(Histogram Contrast method)[15]、LC方法[31]、RC(Region Contrast method)[15]、SR(Spectral Residual approach)[32]得到的顯著性結果進行比較。如圖8所示。

圖8 準確率-召回率曲線
從圖8(b)中可以看出,本文的模型在準確率-召回率曲線上有很好的表現。如表1所示,通過計算8種不同顯著性檢測方法的AUC值可以看出對于結構和背景比較簡單或者復雜的圖像,本文算法都能取得很好的檢測效果。
單獨采用自底向上的顯著性檢測模型時間效率都較高但是檢測效果較差,如果采用自底向上模型結合自頂向下模型的算法則會耗時更多效果更好。本文中采用的由底至上模型和優化策略都采用了較為高效的算法,力求快速建立可靠參考,而超像素分割和學習的過程則計算開銷較大。由于BL算法中采用多尺度顯著圖融合,本文的算法效率更高。使用配置為i7-6700,3.40 GHz,內存為8 GB的CPU的PC機上進行實驗,部分算法平均運行時間如表2所示。

表1 8種方法在ASD和SED1數據庫上的AUC測評值

表2 各種方法的運行時間和實現語言
為了進一步展示算法結果的改進,本文還將最終顯著圖與其他幾種算法的顯著圖進行對比,對比的結果如圖9。從圖9中可以看出,本文的方法在全局上有很好的效果,得到的顯著圖的輪廓最接近真值,而且細節部分也比較清晰,具有較為分明的前景和背景區分,能夠很好地反映一幅圖像的顯著性物體。本文的算法能克服原有的基于學習的顯著性檢測模型的不足,從主觀圖像和客觀評價上顯示出本文算法具有一定的優越性。
4 結語
本文中提出了一種改進的基于引導的Boosting算法來構建顯著性檢測模型。針對基于各種先驗的檢測模型建立的粗選樣本圖,對其優化加強來得到引導樣本圖,為原圖建立參考用于學習。本文中還采用了新的特征提取方式,使訓練效果得到提升。根據AdaBoost算法訓練強分類器能夠整合不同的特征和不同的核,避免了使用單一核對不同特征進行學習時的局限性。從原始圖像到最終的顯著圖,本文建立了一種自生成參考的學習模型。粗選樣本的優化解決了Boosting時樣本選擇不純凈帶來的誤識別,而新的特征選擇方式也能更準確地體現出正負樣本的區別以提升學習的效果。本文算法的最終結果既具有完善的全局形狀又具有準確的局部細節信息,且很接近于真值。在兩個數據庫上的實驗驗證了本文算法有一定的優越性。
文中還存在一些待解決的問題,例如對于多目標的顯著性檢測效果有待提升,對于全背景(無顯著性目標)的圖像的處理也需要深入研究。

圖9 本文算法與8種現有算法的顯著圖對比
References)
[1] HAN J, NGAN K N, LI M, et al. Unsupervised extraction of visual attention objects in color images [J]. IEEE Transactions on Circuits & Systems for Video Technology, 2006, 16(1): 141-145.
[2] KO B C, NAM J Y. Object-of-interest image segmentation based on human attention and semantic region clustering [J]. Journal of the Optical Society of America A, Optics, Image Science, and Vision , 2006, 23(10): 2462-2470.
[3] RUTISHAUSER U, WALTHER D, KOCH C, et al. Is bottom-up attention useful for object recognition? [C]// Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2004: 37-44.
[4] CHEN T, CHENG M M, TAN P, et al. Sketch2Photo: Internet image montage [J]. ACM Transactions on Graphics, 2009, 28(5): Article No. 124.
[5] CHRISTOPOULOS C, SKODRAS A, EBRAHIMI T. The JPEG2000 still image coding system: an overview [J]. IEEE Transactions on Consumer Electronics, 2000, 46(4): 1103-1127.
[6] ZHANG G, CHENG M, HU S, et al. A shape-preserving approach to image resizing [J]. Computer Graphics Forum, 2009, 28(7): 1897-1906.
[7] HOU X, ZHANG L. Saliency detection: a spectral residual approach [C]// Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2007: 18-23.
[8] JIANG H, WANG J, YUAN Z, et al. Automatic salient object segmentation based on context and shape prior [EB/OL]. [2016- 12- 21]. http://www.bmva.org/bmvc/2011/proceedings/paper110/paper110.pdf.
[9] KLEIN D A, FRINTROP S. Center-surround divergence of feature statistics for salient object detection [C]// Proceedings of the 2011 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2011: 2214-2219.
[10] TONG N, LU H, ZHANG Y, et al. Salient object detection via global and local cues [J]. Pattern Recognition, 2015, 48(10): 3258-3267.
[11] MARCHESOTTI L, CIFARELLI C, CSURKA G. A framework for visual saliency detection with applications to image thumbnailing [C]// Proceedings of the 2009 IEEE 12th International Conference on Computer Vision. Piscataway, NJ: IEEE, 2009: 2232-2239.
[12] NG A Y, JORDAN M I, WEISS Y. On spectral clustering: analysis and an algorithm [EB/OL]. [2017- 01- 12]. http://www.csie.ntu.edu.tw/~mhyang/course/u0030/papers/Ng%20Weiss%20Jordan%20Spectral%20Clustering.pdf.
[13] 桑農,李正龍,張天序.人類視覺注意機制在目標檢測中的應用[J].紅外與激光工程,2004,33(1):38-42.(SANG N, LI Z L, ZHANG T X. Application of human visual attention mechanisms in object detection [J]. Infrared and Laser Engineering, 2004, 33(1): 38-42.)
[14] TONG N, LU H, XIANG R, et al. Salient object detection via bootstrap learning [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 1884-1892.
[15] CHENG M M, ZHANG G X, MITRA N J, et al. Global contrast based salient region detection [C]// Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2011: 409-416.
[16] CHENG M M, WARRELL J, LIN W Y, et al. Efficient salient region detection with soft image abstraction [C]// Proceedings of the 2013 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2013: 1529-1536.
[17] FENG J. Salient object detection for searched web images via global saliency [C]// Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2012: 3194-3201.
[18] HE K, SUN J, TANG X. Single image haze removal using dark channel prior [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(12): 2341-2353.
[19] QIN Y, LU H, XU Y, et al. Saliency detection via cellular automata [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 110-119.
[20] WEI Y, WEN F, ZHU W, et al. Geodesic saliency using background priors [C]// European Conference on Computer Vision, LNCS 7574. Berlin: Springer, 2012: 29-42.
[21] SUN J, LU H, LI S. Saliency detection based on integration of boundary and soft-segmentation [C]// Proceedings of the 2012 19th IEEE International Conference on Image Processing. Piscataway, NJ: IEEE, 2012: 1085-1088.
[22] JIANG H, WANG J, YUAN Z, et al. Salient object detection: a discriminative regional feature integration approach [C]// Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2013: 2083-2090.
[23] ZHU W, LIANG S, WEI Y, et al. Saliency optimization from robust background detection [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014: 2814-2821.
[24] YANG F, LU H, CHEN Y W. Human tracking by multiple kernel boosting with locality affinity constraints [C]// Proceedings of the 2010 10th Asian Conference on Computer Vision. Berlin: Springer. 2010: 39-50.
[25] 汪成,陳文兵.基于SLIC超像素分割顯著區域檢測方法的研究[J].南京郵電大學學報(自然科學版),2016,36(1):89-93.(WANG C, CHEN W B, et al. Salient region detection method based on SLIC superpixel segmentation [J]. Journal of Nanjing University of Posts and Telecommunications (Natural Science Edition), 2016, 36(1): 89-93.)
[26] WOLFRAM S. Statistical mechanics of cellular automata [J]. Reviews of Modern Physics, 1983, 55(3): 601-644.
[27] YILDIRIM G, SüSSTRUNK S. FASA: fast, accurate, and size-aware salient object detection [C]// Asian Conference on Computer Vision, LNCS 9005. Berlin: Springer, 2014: 514-528.
[28] BACH F R, LANCKRIET G R G, JORDAN M I. Multiple kernel learning, conic duality, and the SMO algorithm [C]// Proceedings of the 21st International Conference on Machine Learning. New York: ACM, 2004: 6.
[29] BOYKOV Y, KOLMOGOROV V. An experimental comparison of min-cut/max-flow algorithms for energy minimization in vision [C]// Proceedings of the 3rd International Workshop on Energy Minimization Methods in Computer Vision and Pattern Recognition. London: Springer, 2001: 359-374.
[30] ACHANTA R, HEMAMI S, ESTRADA F, et al. Frequency-tuned salient region detection [C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2009: 1597-1604.
[31] ZHAI Y, SHAH M. Visual attention detection in video sequences using spatiotemporal cues [C]// Proceedings of the 14th ACM International Conference on Multimedia. New York: ACM, 2006: 815-824.
[32] HOU X, ZHANG L. Saliency detection: a spectral residual approach [C]// Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2007: 1-8.
SaliencydetectionbasedonguidedBoostingmethod
YE Zitong, ZOU Lian*, YAN Jia, FAN Ci’en
(ElectronicInformationSchool,WuhanUniversity,WuhanHubei430072,China)
Aiming at the problem of impure simplicity and too simple feature extraction of training samples in the existing saliency detection model based on guided learning, an improved algorithm based on Boosting was proposed to detect saliency, which improve the accuracy of the training sample set and improve the way of feature extraction to achieve the improvement of learning effect. Firstly, the coarse sample map was generated from the bottom-up model for saliency detection, and the coarse sample map was quickly and effectively optimized by the cellular automata to establish the reliable Boosting samples. The training samples were set up to mark the original images. Then, the color and texture features were extracted from the training set. Finally, Support Vector Machine (SVM) weak classifiers with different feature and different kernel were used to generate a strong classifier based on Boosting, and the foreground and background of each pixel of the image was classified, and a saliency map was obtained. On the ASD database and the SED1 database, the experimental results show that the proposed algorithm can produce complete clear and salient maps for complex and simple images, with good AUC (Area Under Curve) evaluation value for accuracy-recall curve. Because of its accuracy, the proposed algorithm can be applied in pre-processing stage of computer vision.
saliency detection; boosting; bottom-up model; coarse reference optimization; color feature extraction
2017- 03- 15;
2017- 05- 25。
葉子童(1993—),女,湖北襄陽人,碩士研究生,主要研究方向:顯著性檢測、圖像檢索; 鄒煉(1975—),男,湖北武漢人,副教授,博士,主要研究方向:圖像檢索、語音識別; 顏佳(1984—),男,湖北天門人,講師,博士,主要研究方向:圖像質量評估、顯著性檢測; 范賜恩(1975—),女,浙江慈溪人,副教授,博士,主要研究方向:圖像修復、圖像超分辨率重建。
1001- 9081(2017)09- 2652- 07
10.11772/j.issn.1001- 9081.2017.09.2652
TP391.4
A
YEZitong, born in 1993, M. S. candidate. Her research interests include saliency detection, image retrieval.
ZOULian, born in 1975, Ph. D., associate professor. His research interests include image retrieval, speech recognition.
YANJIA, born in 1984, Ph. D., lecturer. His research interests include image quality assessment, saliency detection.
FANCi’en, born in 1975, Ph. D., associate professor. Her research interests include image restoration, image super-resolution reconstruction.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
