基于改進的Adaboost-BP模型在降水中的預測
2017-11-15 06:02:46王軍,費凱,程勇
計算機應用 2017年9期
王 軍,費 凱,程 勇
(1.南京信息工程大學 計算機與軟件學院, 南京 210044; 2.南京信息工程大學 信息化建設與管理處,南京 210044)(*通信作者電子郵箱feikainiust@163.com)
基于改進的Adaboost-BP模型在降水中的預測
王 軍1,2,費 凱1*,程 勇2
(1.南京信息工程大學 計算機與軟件學院, 南京 210044; 2.南京信息工程大學 信息化建設與管理處,南京 210044)(*通信作者電子郵箱feikainiust@163.com)
針對目前分類算法對降水預測過程存在著泛化能力低、精度不足的問題,提出改進Adaboost算法集成反向傳播(BP)神經網絡組合分類模型。該模型通過構造多個神經網絡弱分類器,賦予弱分類器權值,將其線性組合為強分類器。改進后的Adaboost算法以最優化歸一化因子為目標,在提升過程中調整樣本權值更新策略,以此達到最小化歸一化因子的目的,從而確保增加弱分類器個數的同時降低誤差上界估計,通過最終集成的強分類器來提高模型的泛化能力和分類精度。選取江蘇境內6個站點的逐日氣象資料作為實驗數據,建立7個降水等級的預報模型,從對降雨量有影響的眾多因素中,選取12個與降水相關性較大的屬性作為預報因子。通過多次實驗統計,結果表明基于改進的Adaboost-BP組合模型具有較好的性能,尤其對58259站點的適應性較好,總體分類精度達到81%,在7個等級中,對0級降雨的預測精度最好,對其他等級的降雨預測有不同程度的精度提升,理論推導及實驗結果證明該種改進可以提高預測精度。
分類器;改進Adaboost;BP神經網絡;組合模型;權值調整;歸一化因子
0 引言
隨著社會經濟發展以及人類本身對氣象服務要求不斷提升,氣象領域的氣象數據采集渠道日益豐富,數據規模不斷增加,且其具有的空間屬性、高維性、不穩定性,為研究傳統氣象預報模式增加巨大難度,尤其在研究各氣象要素之間內部聯系時,尤為乏力,從而導致獲取到的大量氣象資料并未有效利用,對于推動氣象模式預報發展并未有實質性作用。
氣象數據是典型的時間序列數據,天氣系統的內部相互影響條件錯綜復雜,對于大量的采集數據進行分析處理時,傳統的氣象研究模式無法發現其隱含的價值,而數據挖掘技術為研究大量氣象數據提供了新途徑,為氣象領域中發現各屬性聯系發揮著重要作用,分類挖掘技術通過有監督的學習探索歷史氣象數據中潛在的規律,可以提高氣象預報模式的準確率[1]。
近些年,多種分類挖掘技術被應用于氣象領域,如決策樹、關聯規則、貝葉斯等[2-3]。文獻[4]將支持向量機(Support Vector Machine, SVM)分類方法應用于降水預測中,結合多個相關因子,利用四川盆地降水量數據建立分類預測模型,在短氣候預測中有著不錯的性能。文獻[5]研究通過決策樹對與降水密切相關的濕度、溫度、大氣壓、風速和露點溫度等眾多氣象要素的采集數據進行預報建模,改進后的模型具有較好的適應性;文獻[6]將樸素貝葉斯分類器與降雨量問題相結合,將貝葉斯模型用于降雨量分類預測研究,以鄭州市34年氣象數據建立分類預測模型,預測精度略好于短期氣候中常用的回歸分析;文獻[7]提出一種改進SVM算法的二進制分類核函數(BInary and ORdinal classification Kernel method, BIORK)模型,將該模型用于降雨等級預測,并且證明該模型在氣象要素合適的情況下有較好的預測精度,尤其是無降雨天氣預測。但是該些模型共同點是基于較小的數據集為前提才獲取到較好的效果,不適用于規模較大和多站點的數據集。文獻[8]運用SVM分類算法研究局部氣象數據,提出基于Adaboost算法集成SVM分類器的多分類模型,通過多個分類器的協同組合多個基分類器,以此提高單分類模型在降雨中的分類預測精度;文獻[9]提出以Adaboost算法集成BP神經網絡模型預測了湖北某風場風速,對每個弱學習器賦予權值,最終線性組合成強預測器對風速預測,通過該多集成方法提高了學習器的預測能力。相對單個弱學習器而言,數據集較大時,Adaboost集成弱學習器模型具有一定的優勢,但隨著迭代次數的增加,分類器的性能開始下降,出現了性能退化問題,很難達到理想中的要求。
針對上述問題,本文提出一種改進Adaboost-BP(可簡寫為Ada-BP)算法,該算法集成BP神經網絡,使得最終的強分類預測模型泛化能力增強,通過破壞樣本分布的均勻性緩解性能退化問題。該算法核心是在Adaboost算法中線性組合多個神經網絡分類器得到強分類器,并利用該分類器完成分類預測,通過在迭代過程中改變權值分布策略,以優化歸一化因子,降低誤差上界,從而提高強分類器的分類能力[10]。
1 BP神經網絡
BP神經網絡是誤差反向傳播算法,可以逼近任意連續的函數,具有很強的非線性映射能力,它由輸入層、隱含層、輸出層構成,隱含層是介于輸入層和輸出層之間[11]。隱含層可以由多層構成,但隱含層的增加導致模型的復雜性增加,文獻[12]研究發現三層結構的BP神經網絡可以近似任何多元多項式函數,因此,在本文研究過程中使用只包含一層隱含層的BP神經網絡來建立模型,其模型拓撲結構如圖1所示,其中BP神經網絡的學習過程分為兩個部分:正向傳播和反向傳播。當正向傳播的時候,信號通過神經元傳遞到下一層,如果輸出層不能獲得所需的輸出,誤差信號由各神經元反向傳播來調整各神經元參數。通過這兩個交替的過程完成信息提取和存儲,使得輸出層值逼近期望的值。
其中x1,x2,…,xq是網絡輸入層各神經元的輸入值,wij為輸入層到隱含層神經元間的連接權值,wjk為隱含層到輸出層的連接權值,yi為神經網絡的輸出值。

圖1 BP神經網絡拓撲結構
2 基于改進的Adaboost-BP模型
Adaboost算法是一種迭代算法,常用于解決分類問題。其核心思想是針對同一個訓練集訓練不同的弱分類器,后將多個弱分類器集成,構成最終的強分類器[13]。該算法迭代的過程是一個對弱分類算法提升過程,重視被錯誤分類的樣本和性能較高的分類器,提高訓練中錯誤樣本的權值和性能較好的分類器權值,反之則降低,分類的結果由多個性能較好的弱分類器決定;同時,在訓練中,對訓練效果較好的樣本降低權重,而訓練效果較差的增加其權重,通過多次訓練迭代,得到由多個弱分類器線性組合的強分類器,以此提高對數據的分類精度。
本文將BP神經網絡作為弱分類器,選取神經網絡中的合適的激勵函數與神經元參數來構造BP神經網絡分類器,利用Adaboost算法多次提升訓練,最終獲得強分類器,其模型結構如圖2。

圖2 Adaboost-BP模型結構
通過研究分析系列Adaboost算法以及原理推導,每次迭代過程中,算法會對錯誤樣本進行加權,隨著迭代次數的增加,當多個易錯樣本被多次錯誤分類后,易錯樣本具有較大的權值,反之樣本的總體誤差的出現了上升趨勢。對于該種退化問題,只能選取弱分類器空間中的唯一參照標準Zt作分析[14]。對Zt作如式(1)推導:
Z1*Z2*Z3*Z4*…*ZT=
(1)
由此可知,歸一化因子雖然具有使樣本呈現概論分布的同時,還可以左右整個分類器的誤差上界,如上面公式推導,實質上歸一化因子的積就是整個分類器的誤差上界。理論上隨著分類器的增加誤差上界將應該下降,但實際上隨著迭代的增加,歸一化因子在后期在持續增長趨勢,從而導致隨著分類器數量的增加性能反而降低的情況。對強分類器的性能優化實質上可以回歸到是對歸一化因子Zt優化,Zt的大小決定著誤差下降的速度,對Zt的優化使得其在每次迭代中都小于1,當分類器的個數達到無窮時,分類器的誤差上界理論值可以達到無限接近0。對于分類器而言,歸一化因子Zt的公式分解為如式(2):


(2)

(3)

(4)

算法詳細步驟如下:
步驟1 設置初始化神經網絡的權值和閾值。
步驟2 數據歸一化處理,使樣本值分布在[0,1]。
步驟3 訓練神經網絡調整隱含層節點數,設定學習率。
步驟4 給出氣象數據樣本集(xi,yi),…,(xm,ym)(y1,y2,…,ym是樣本的期望輸出)。
步驟5 初始化氣象數據樣本權值D(i)=1/N(N是樣本的數量)。
步驟6 fort=1,2,…,T(T是提升的次數)。

步驟8 ifεt>0.5 then 轉步驟5
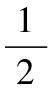
步驟10 通過式(4)更新樣本權值 。
步驟11 跳轉第步驟6,直至結束迭代。

3 實驗及分析
降水形成過程涉及的因素眾多,其中基本氣象要素包括溫度、高度、緯向風、經向風、垂直速度等。利用這些基本氣象要素通過動力診斷獲取與降水相關的平流項、梯度項、渦度、水汽通量、水汽通量散度等近100多個的氣象物理量,在眾多的物理量中選擇與降水相關因子,將直接決定降水分類模型的性能效果,將降水所涉及的所有因子作為屬性將大大削弱模型的性能且增加模型的復雜度,選取與區域降水相關性較大的因子作為降水樣本的屬性集有利于提高分類預報效果。
一般對降水因子的選擇通過逐步回歸的方法,利用Pearson相關系數法對屬性重要性進行排序,在眾多因子中選擇與降水相關性最好的屬性。本文從眾多因子排序中,選擇包括最小相對濕度、平均相對濕度、極大風速、最大風速、日照時數、平均水氣壓、日最低溫度、平均風速、平均氣溫、蒸發量、相對濕度、露點溫度作為樣本屬性中的重要因子,所以在降水分類預測中只選擇12個相關性較大因子。
3.1 降水模型建立
本研究的內容是對降水等級預測,將所選的12個屬性作為網絡的輸入向量,通過所選的重要屬性對降水等級分析,將降水的等級作為網絡的輸出向量,按國家氣象局頒布的降水等級劃分標準,建立7個等級區域降雨預報模型,表1為樣本降水等級統計表。

表1 降水等級劃分
實驗數據來源于江蘇省氣象局,該數據集為2001年—2010年10年間的實況觀測數據,實驗中選取江蘇境內包括南通(58259)、徐州(58027)、鹽城(58154)、淮安(58141)、泰州(58246)、揚州(58245)共6個站點逐日降水資料作為降水實驗數據,實況數據數據集共包含19 863條記錄,將實驗數據按比例分為訓練數據與預測數據,同時對降水數據中各類別按比例劃分訓練數據與測試數據。由于氣象數據存在的特點,經過預處理后的各個站點的數據量并不相同,各等級間的數據非均勻分布。
其中整個網絡采用12-N-7的三層網絡結構 ,輸入層分別將上述的12個特征因子作為網絡輸入的特征向量,其中的N為隱含層神經元數目,N的值結合經驗公式,在一定的范圍內采取試算的原則,輸出層設置7個神經元,將輸出層中7個降水等級作為神經網絡的輸出向量,神經網絡選用的傳遞函數為tansig函數,學習規則采用梯度下降法,在神經網絡訓練前,通常會對數據進行歸一化處理,在訓練模型時先將數據預處理歸一化到0~1[15]。
3.2 實驗結果分析
為了驗證本算法的先進性,通過Matlab編制程序,將本文提出的改進Ada-BP與傳統Ada-BP算法作實驗對比,說明改進的Ada-BP優于傳統的Ada-BP;同時,與性能較好的文獻[7]中所用的BIORK算法做對比分析來說明本文提出的方法先進性。為保證實驗可比性,實驗中采用相同的數據集,將實驗獲得的結果作統計分析。
經過對BP神經網絡訓練最終確定單個性能較好的神經網絡參數,選擇較好的BP神經網絡模型作為訓練過程中的弱分類器。首先,對比改進后的Adaboost算法與改進前的Adaboost算法提升不同次數準確率之間的統計比較,如圖3所示,隨著弱分類器個數的增加,強分類器對樣本的分類精度也隨之提高,改進后的Adaboost算法弱分類器個數達到20~30時,性能趨于穩定,當T=20時,性能達到最高,改進后的Adaboost算法的分類精度穩定地高于傳統Adaboost算法3%,但兩者在隨著弱分類器數量增加以后同時出現性能飽和情況。

圖3 弱分類器上精度比較
圖4分別統計了改進后Ada-BP、Ada-BP、BIORK三種模型在不同樣本集容量下的性能:改進后的Ada-BP分類器性能隨著樣本的增加而上升,最終性能達到飽和,穩定在77%~79%;Ada-BP模型隨著樣本的增加,性能呈上升趨勢,最終也到達飽和水平,但隨著樣本數量的增加,傳統Adaboost集成的強分類器模型性能出現退化,低于性能峰值較多,最終穩定在74%~76%;BIORK 單分類器模型的性能在樣本集較少時,擁有明顯的優勢,隨著樣本的增加,BIORK模型的分類性能逐漸趨于穩定,最終飽和于75%左右。從統計結果看,隨著樣本集數量的增加,改進后Ada-BP算法在總體分類精度上具有明顯優勢。

圖4 樣本容量與性能關系比較
圖5統計了三種算法對每個類樣本的分類預測精度,從總體趨勢顯示:改進的Ada-BP算法對所有等級的分類預測性能都好于傳統Ada-BP和BP兩種算法;與其他等級相比,三種算法對0級降水同時表現出較好的性能,對6級的降水表現的性能最差,但改進后的Ada-BP算法在降水為量0級優勢較明顯,降水等級為2、3時略低于BIORK分類模型。由于樣本集數據所占比重不同,導致分類器對每個等級呈現不同的性能,但三種模型同時表現出對0級的樣本預測精度最高,6級的預測精度最低,由于等級為6的數據占比最少,且大暴雨級別及以上等級的降雨形成原因復雜,不能僅僅根據十幾個相關性較強的因子作為判斷依據,從而導致樣本預測效果較差。

圖5 各降水等級樣本預測性能對比
圖6統計了三種算法對各區站點的預測精度:改進的Ada-BP在各個站點中的預測準確率較為穩定,總體性能在78%以上,其中主要對南通站(58259)的預測精度較高,對揚州站(58245)的預測精度略低;BIORK模型在淮安站(58141)與揚州站(58245)略高于改進的Ada-BP模型;但改進的Ada-BP模型對其余站點的適應性優于其他兩種模型,所有站點的預測精度有一定程度的提高,其中改進的模型在南通站(58259)與徐州站的優勢最大,明顯高于Ada-BP與BIORK兩種模型。從各站點實驗結果表明,改進的Ada-BP模型優于其他兩種模型。

圖6 各區站預測精度對比
通過上述實驗表明,本文提出的改進Adaboost-BP算法性能高于另外兩種算法,在降水等級預測中取得良好效果,但在不同的站點和降水等級中表現出差異性,在一定程度上改進了傳統Adaboost算法集成BP神經網絡和現有的分類預測算法對氣象數據挖掘的局限性。
4 結語
本文提出的改進Adaboost-BP模型,在集成迭代過程中調整樣本權值更新方式,以最小化歸一化因子為目標,減輕強分類器的性能退化現象。實驗結果表明,該模型優于現有的降雨預測模型,一定程度上克服氣象分類挖掘算法精度較低的缺陷,提高了對不同樣本的分類預測能力,但對復雜的、降雨量大的天氣預測精度較低。對算法作改進來提高其預測的精度有較大難度,將成為以后降水預測模型的研究方向。但總體而言,本文提出的模型確實提高了預報的準確率,具有較高的工程價值。
References)
[1] OLAIYA F, ADEYEMO A B. Application of data mining techniques in weather prediction and climate change studies [J]. International Journal of Information Engineering & Electronic Business, 2012, 4(1): 304-310.
[2] GUO Z Y, DAI X Y, LIN H. Application of association rule in disaster weather forecasting [J]. Geographic Information Sciences, 2004, 10(1): 68-72.
[3] CANO R, SORDO C, GUTIéRREZ J M. Applications of Bayesian networks in meteorology [M]// Advances in Bayesian Networks. Berlin: Springer, 2004: 309-328.
[4] 楊淑群,芮景析,馮漢中.支持向量機(SVM)方法在降水分類預測中的應用[J].西南農業大學學報(自然科學版),2006,28(2):252-257.(YANG S Q, RUI J X, FENG H Z. Application of Support Vector Machine (SVM) in rainfall categorical forecast [J]. Journal of Southwest Agricultural University (Natural Science), 2006, 28(2): 252-257.)
[5] PRASAD N, KUMAR P, NAIDU M. An approach to prediction of precipitation using Gini index in SLIQ decision tree [C]// Proceedings of the 2013 4th International Conference on Intelligent Systems, Modelling and Simulation. Washington, DC: IEEE Computer Society, 2013: 56-60.
[6] 何偉,孔夢榮,趙海青.基于貝葉斯分類器的氣象預測研究[J].計算機工程與設計,2007,28(15):3780-3782.(HE W, KONG M R, ZHAO H Q. Research on meteorological prediction with Bayesian classifier [J]. Computer Engineering and Design, 2007, 28(15): 3780-3782.)
[8] 滕少華,樊繼慧,陳瀟,等.SVM多分類器協同挖掘局域氣象數據[J].廣西大學學報(自然科學版),2014(5):1131-1137.(TENG S H, FAN J H, CHEN X, et al. Application of SVM-based muti-classifiers in mining cooperatively local area meteorological data [J]. Journal of Guangxi University (Natural Science Edition), 2014(5): 1131-1137.)
[9] 吳俊利,張步涵,王魁.基于Adaboost的BP神經網絡改進算法在短期風速預測中的應用[J].電網技術,2012,36(9):221-225.(WU J L,ZHANG B H,WANG K. Application of Adaboost-based BP neural network for short-term wind speed forecast [J]. Power System Technology, 2012, 36(9): 221-225).
[10] ZHU J, ROSSET S, ZOU H, et al. Multi-class AdaBoost [EB/OL]. [2017- 01- 03]. https://web.stanford.edu/~hastie/Papers/samme.pdf.
[11] 張丹,韓勝菊,李建,等.基于改進粒子群算法的BP算法的研究[J].計算機仿真,2011,28(2):147-150.(ZHANG D, HAN S J, LI J, et al. BP algorithm based on improved particle swarm optimization [J]. Computer Simulation, 2011, 28(2): 147-150.)
[12] JIANG C. Review of back propagation neural network applied to athletics [C]// Proceedings of the 2012 24th Chinese Control and Decision Conference. Piscataway, NJ: IEEE, 2012: 2371-2375.
[13] LI X, WANG L, SUNG E. AdaBoost with SVM-based component classifiers [J]. Engineering Applications of Artificial Intelligence, 2008, 21(5): 785-795.
[14] 廖紅文,周德龍.AdaBoost及其改進算法綜述[J].計算機系統應用,2012,21(5):240-244.(LIAO H W, ZHOU D L. Review of AdaBoost and its improvement [J]. Computer System & Applications, 2012, 21(5): 240-244.)
[15] LI J, WU X H, QIN C H, et al. The design of image compression with BP neural network based on the dynamic adjusting hidden layer nodes [J]. Advanced Materials Research, 2012, 433/434/435/436/437/438/439/440: 3797-3801.
PredictionofrainfallbasedonimprovedAdaboost-BPmodel
WANG Jun1,2, FEI Kai1*, CHENG Yong2
(1.CollegeofComputerandSoftware,NanjingUniversityofInformationScienceandTechnology,NanjingJiangsu210044,China;2.InformationConstructionandManagementDepartment,NanjingUniversityofInformationScienceandTechnology,NanjingJiangsu210044,China)
Aiming at the problem that the current classification algorithm has low generalization ability and insufficient precision, a combination classification model combining Adaboost algorithm and Back-Propagation (BP) neural network was proposed. Multiple neural network weak classifiers were constructed and weighted, which were linearly combined into a strong classifier. The improved Adaboost algorithm aimed to optimize the normalization factor. The sample weight update strategy was adjusted during the lifting process, to minimize the normalization factor, increasing the number of weak classifiers while reducing the error upper bound estimate was ensured, and the generalization ability and classification accuracy of the final integrated strong classifier was improved. A daily precipitation model of 6 sites in Jiangsu province was selected as the experimental data, and 7 precipitation models were established. Among the many factors influencing the rainfall, 12 attributes with large correlation with precipitation were selected as the forecasting factors. The results show that the improved Adaboost-BP combination model has better performance, especially for the site 58259, and the overall classification accuracy is 81%. Among the 7 grades, the prediction accuracy of class-0 rainfall is the best, and the accuracy of other types of rainfall forecast is improved. The theoretical derivation and experimental results show that the improvement can improve the prediction accuracy.
classifier; improved Adaboost; BP neural network; combined model; weight adjustment; normalization parameter
2017- 03- 17;
2017- 05- 18。
國家自然科學基金資助項目(61402236, 61373064);江蘇省農業氣象重點實驗室開放基金資助項目(KYQ1309);江蘇省“六大人才高峰”項目(2015-DZXX-015,2013-DZXX-019);江蘇省產學研前瞻性聯合研究項目(BY2014007-2);公益性行業(氣象)科研專項(GYHY201106037)。
王軍(1970—),男,安徽銅陵人,教授,碩士,CCF會員,主要研究方向:無線傳感網、大數據; 費凱(1990—),男,江蘇連云港人,碩士研究生,主要研究方向:大數據氣象領域應用; 程勇(1980—),男,重慶人,高級工程師,博士,CCF會員,主要研究方向:無線傳感網、大數據。
1001- 9081(2017)09- 2689- 05
10.11772/j.issn.1001- 9081.2017.09.2689
TP399
A
This work is partially supported by the National Natural Science Foundation of China (61402236, 61373064), Opening Foundation of Jiangsu Key Laboratory of Agricultural Meteorology (KYQ1309), Six Talent Peaks Project in Jiangsu Province (2015-DZXX-015, 2013-DZXX-019), the Prospective Joint Research Project of Jiangsu Province (BY2014007-2), Special Fund for Meteorological Research in Public Interest (GYHY201106037).
WANGJun, born in 1970, M. S., professor. His research interests include wireless sensor network, big data.
FEIKai, born in 1990, M. S. candidate. His research interests include application of big data in meteorological field.
CHENGYong, born in 1980, Ph. D., senior engineer. His research interests include wireless sensor network, big data.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
