基于卷積神經網絡的謠言檢測
2018-01-08 08:50:45衛志華張韌弦
計算機應用 2017年11期
劉 政,衛志華,張韌弦
(1.同濟大學 計算機科學與技術系,上海 201804; 2.嵌入式系統與服務計算教育部重點實驗室(同濟大學),上海 201804)
基于卷積神經網絡的謠言檢測
劉 政1,2,衛志華1,2*,張韌弦1,2
(1.同濟大學 計算機科學與技術系,上海 201804; 2.嵌入式系統與服務計算教育部重點實驗室(同濟大學),上海 201804)
人工檢測謠言通常需要耗費大量的人力物力,并且會有很長的檢測延遲。目前現存的謠言檢測模型一般根據謠言的內容、用戶屬性、傳播方式人工地構造特征,而人工構建特征存在考慮片面、浪費人力等現象。為了解決這個問題,提出了基于卷積神經網絡(CNN)的謠言檢測模型。將微博中的謠言事件向量化,通過卷積神經網絡隱含層的學習訓練來挖掘表示文本深層的特征,避免了特征構建的問題,并能發現那些不容易被人發現的特征,從而產生更好的效果。實驗結果表明,所提方法能夠準確識別謠言事件,在準確率、精確率與F1值指標上優于支持向量機(SVM)與循環神經網絡(RNN)等對比算法。
微博;謠言檢測;謠言事件;卷積神經網絡
0 引言
隨著在線社交媒體的迅速發展, 大量不可靠的信息得以快速和廣泛地在人群中傳播。社交媒體上謠言泛濫可能導致人們難以從紛繁的信息中甄別得到可信的信息, 進而影響人們正常的生活秩序。 特別是在面臨突發公共事件 (自然災害、事故災難、公共衛生事件、社會安全事件、經濟危機等)時, 廣泛傳播的謠言可能會具有極大的破壞性。在微博中,信息內容主要通過人與人之間建立的“關注-被關注”網絡進行傳播。人與人之間的互聯、人與信息之間的互聯高度融合,人人參與到信息的產生與傳播過程,這種傳播方式使得一條信息能夠在短時間內傳播到數百萬計的用戶[1]。因此, 自動高效地識別社交媒體中的謠言意義重大。
社交媒體的自動謠言檢測是基于推特信息的可靠性檢測而來的[2],Kwon等[3]介紹了一個基于時間屬性的時間序列適應模型;Ma等[4]使用動態時間序列擴展了該模型;Zhao等[5]通過使用線索詞如“not true” “unconfirmed”等來進行早期的謠言檢測;Ma等[6]提出了利用循環神經網絡(Recurrent Neural Network, RNN)進行謠言檢測,實驗結果表明RNN方法優于現有的基于人工構造特征的謠言檢測模型。
近年來,卷積神經網絡(Convolutional Neural Network, CNN)在圖像處理、目標檢測、圖像語義分割等領域取得了一系列突破性的研究成果,其強大的特征學習與分類能力引起了廣泛關注,具有重要的分析與研究價值。早期的CNN結構相對簡單,主要應用在手寫字符識別、圖像分類等相對單一的計算機視覺應用領域中[7]。隨著研究的不斷深入,CNN的結構不斷優化,其應用領域也逐漸得到延伸。
2012年,Krizhevsky等[8]提出的AlexNet在大型圖像數據庫ImageNet[9]的圖像分類競賽中以準確度超越第二名11%的巨大優勢奪得了冠軍,使得CNN成為了學術界的焦點;并且,CNN不斷與一些傳統算法相融合,加上遷移學習方法的引入,使得CNN的應用領域獲得了快速的擴展。一些典型的應用包括:CNN與RNN結合圖像的摘要生成[10-11]; 自然語言處理方面,卷積神經網絡模型在語義分析[12]、搜索結果提取[13]、句子分類[14]、句子建模[15]、句子預測[16]和其他的傳統自然語言處理任務[17]中都取得了很好的結果。
由于CNN的良好表現,所以本文應用于微博自動謠言檢測當中。本文對Kim等[14]提出的句子分類模型進行改進,使其適應于微博謠言檢測,實驗表明本文模型的有效性。
本文的主要貢獻如下:
1) 提出了一種基于卷積神經網絡模型的謠言檢測方法,將謠言事件向量化,通過自動構建謠言的特征來進行模型訓練,從而達到判斷謠言的目的;
2) 提出了一種基于微博的謠言檢測框架,實現微博中的謠言檢測。
1 本文模型
1.1 基本定義
本文的研究對象為謠言事件。所謂謠言事件,就新浪微博而言,本文需要關心的是某個最初始的不實微博(即源頭微博)是否是謠言,并不關心其傳播過程中所衍生出來的微博是否存在不實,或者是否是謠言。最初始微博一經判斷,則與其相關的微博也自然得到判斷。例如,“傳說中麥當勞全國通用無線上網密碼,真的嗎?”這條謠言以及其相關微博“真的么?”“假的”“存了多少次都找不到了”等就構成了一個謠言事件,而本文判斷的僅是“傳說中麥當勞全國通用無線上網密碼,真的嗎?”這條微博是否是謠言,而其相關微博是否是謠言并不關心,或者說其相關微博是作為判斷源頭微博是否是謠言的證據存在。因此,在詳細描述本文的模型之前,本文先給出一些基本的符號解釋和定義。
定義1 謠言事件[6]。定義一個所有事件的集合E={Ei},其中每一個Ei={mij}包含與其相關的所有微博,mij表示謠言事件的某一條微博,本文的任務就是判斷Ei是不是謠言事件。

表1 標記與定義Tab. 1 Notations and definitions
1.2 模型結構
本文的謠言檢測的流程框圖如圖1所示。首先,通過新浪微博官方的辟謠平臺——微博社區管理中心取得某條具體的謠言; 然后,對與其相關的微博進行聚類,得到N個謠言事件,相應地,為了便于分類訓練,取得與謠言事件數目近似相同的M個非謠言事件,將每一個謠言事件作為一個整體,對其中的每一條微博向量化,組成一個輸入矩陣,依此類推,向量化完成之后,作為輸入矩陣,進行卷積神經網絡模型的訓練。
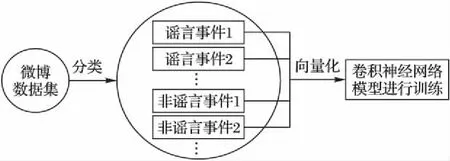
圖1 微博謠言檢測框架Fig. 1 Microblog rumor detection framework
用于謠言檢測的卷積神經網絡如圖2所示。
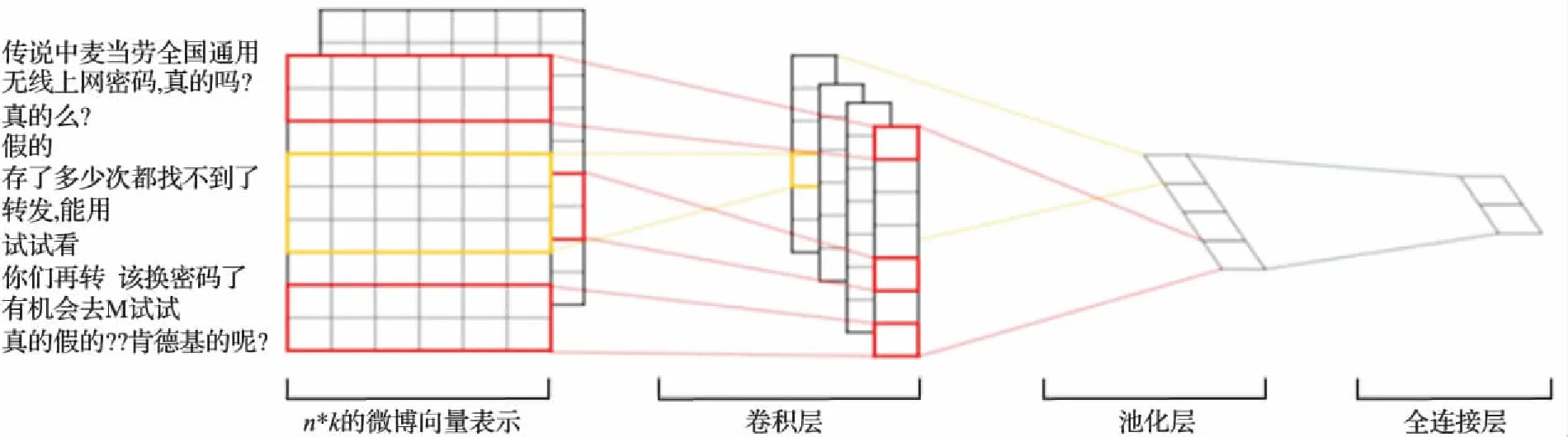
圖2 基于卷積神經網絡的謠言檢測模型Fig. 2 Rumor detection model based on convolutional neural network
令mij∈Rk,其中mij表示某個謠言事件Ei的某條相關微博,用k維的句子向量表示。一個包含n條相關微博的謠言事件可以表示為:
Ei=mi1⊕mi2⊕…⊕min
其中⊕表示串聯操作。
卷積層進行卷積操作,卷積操作就是利用filterw∈Rh×k來產生新的特征。例如事件i中第j條相關微博到第j+h-1條微博所產生的特征ai的計算公式如下:
ai=f(w·mij:i(j+h-1)+wb)
其中:wb是filter的偏置項,f是一個非線性函數,比如ReLU激活函數。filter應用于事件i的每一個窗口{mi1:ih,mi2:i(h+1),…,mi(n-h+1):in} 來生成一個特征矩陣:
a=[a1,a2,…,an-h+1]
池化層進行池化操作。通常在卷積層之后會得到維度很大的特征,將特征切成幾個區域,取其最大值或平均值,得到新的、維度較小的特征。主要作用是下采樣,通過去掉特征矩陣中不重要的樣本來減少參數的數量。本文采用的是max pooling,即對特征矩陣a中的每一個ai取最大值,作為采樣后的樣本值。
最后將池化后的特征矩陣傳入全連接層,進行Softmax操作,最后輸出分類的概率。
本文模型采用了多個filter來獲得多種特征。值得注意的是,傳統的卷積神經網絡模型filter遍歷每一種圖片的所有局部塊如圖3(a)所示。而在本文模型之中,filter遍歷每個謠言事件的長度為h的所有窗口,而filter寬度通常等于輸入矩陣的寬度,如圖3(b)所示。這樣設置的理由如下:因為本文模型的輸入矩陣每一行表示事件的某一條微博的微博向量,將微博向量當作最小單位,有助于更好地挖取相關微博之間的特征,以及謠言的傳播特征;反之,若是filter掃描局部塊,則更注重的是謠言事件中所有詞之間的關系,不能從整體上把握謠言傳播的時序特點。因為Kim[14]的工作表明,對于文本分類任務,含有一層卷積層的卷積神經網絡已經表現得很好,所以本文模型僅采用一個卷積層與一個池化層。
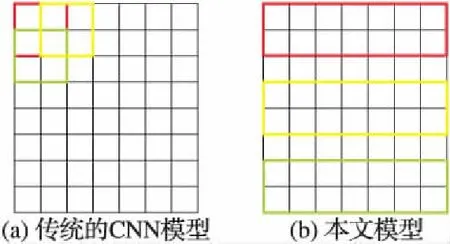
圖3 兩種模型過濾器遍歷輸入矩陣的方式Fig. 3 Way of filter traversing input matrix in two models
2 實驗與分析
2.1 數據收集
通過研究新浪微博發現數據獲取的方式可以通過以下步驟:
1)首先在微博社區管理中心,找得到不實信息的微博,如圖4所示。
圖4 微博社區管理中心Fig. 4 Microblog community management center
2)根據不實微博的公示信息,獲得原文,如圖5所示。
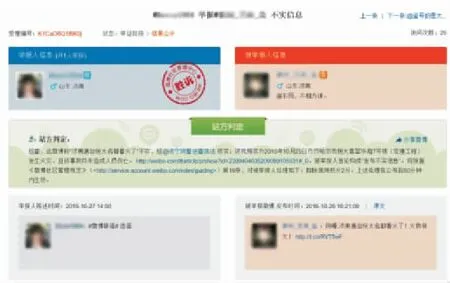
圖5 某條謠言微博的公示信息Fig. 5 Public information of a rumor microblog
3)根據原文信息,進行具體謠言事件的相關微博信息的抓取。
為了便于本文模型與其他模型的比較,本文采用Ma等[6]公開的數據集。該數據集包含2 313個謠言事件與2 351個非謠言事件,共包含3 805 656條微博。由于微博本身含有很大的噪聲,包含@某某人、超鏈接等無關信息,所以本文通過正則表達式匹配的方法對該數據集進行了降噪等預處理。
2.2 實驗設置
本文將本文模型與Ma等[6]的工作進行了對比:
Ma等的模型 Ma等提出了采用循環神經網絡模型來進行微博謠言的檢測,分別實現了tanh-RNN(tanh-Recurrent Neural Network)、LSTM(Long Short-Term Memory)、GRU(Gated Recurrent Unit)等模型,并取得了良好的效果。此外,Ma等基于本文所采用的數據集,重現了之前較經典的謠言檢測的工作,便于進行模型的比較。
本文模型 本文的卷積神經網絡模型,包含一個卷積層和一個池化層,且輸入矩陣是使用Doc2Vec訓練好的向量矩陣。
超參數設置 本文采用ReLU激活函數,filter窗口高度分別采用3、4、5,dropout rate為0.5。每一條微博的維度k設置為50,由于不同的謠言事件或者非謠言事件含有的微博數目不同,所以本文對于微博數目小于最大微博數的事件,采用補充零向量的方式,使輸入矩陣的大小一致。
預處理的句子向量 對于每一條微博,本文進行預處理之后,進行分詞,之后利用Doc2Vec方法,將微博轉化為句子向量。
評價指標 模型的評價指標采用自然語言處理中常用的準確率(accuracy)、召回率(recall)、精確率(precision),以及F1值,它們針對謠言的定義如下:



本文的卷積神經網絡是通過TensorFlow實現。為了便于與Ma等的模型作對比,本文同樣地分別選取10%的謠言事件與非謠言事件用于模型的調整;將剩下的數據的30%作為訓練集,10%作為測試集。
2.3 實驗結果
本文的模型CNN訓練集和測試集比例為3∶1,與其他模型的實驗結果比較如表2所示。其中,“- 1”“- 2”表示隱含層層數,“- 1”表示一層,“- 2”表示兩層。
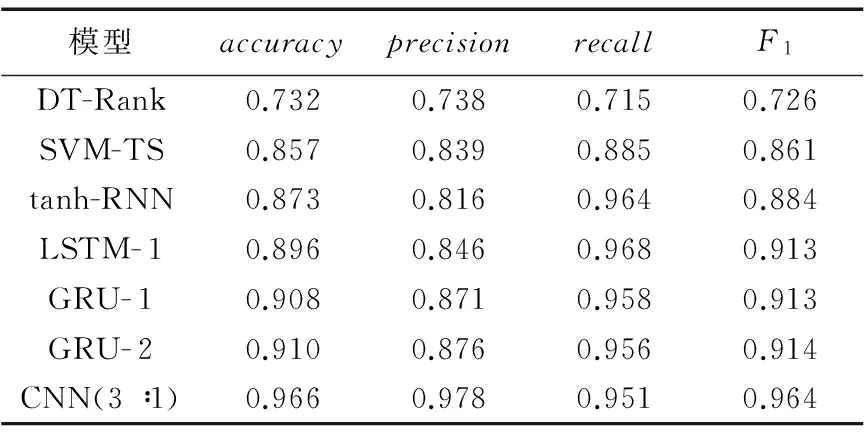
表2 CNN模型與其他模型的實驗結果比較Tab. 2 Result comparison of CNN model with other models
從表2中可以看出:就人工構造特征與模型自動構造特征而言,人工構造特征中基于時間序列的支持向量機模型(Support Vector Machine based on Time-Series, SVM-TS)優于決策樹模型DT-Rank,而本文模型與支持向量機模型相比,準確率提高了10.9個百分點,精確率提高了13.9個百分點,召回率提高了6.6個百分點,F1值提高了10.3個百分點。可以得出模型自動構造特征明顯優于人工構造的特征。
就卷積神經網絡模型與循環神經網絡模型而言,可以看出,循環神經網絡模型中,GRU- 2模型優于其他模型,而本文的模型與GRU- 2模型相比,準確率提高了5.6個百分點,精確率提高了10.2個百分點,召回率與LSTM- 1模型相比降低了1.7個百分點,F1值提高了5個百分點。可以看出除了召回率略低以外,準確率、精確率和F1值都優于循環神經網絡(RNN)模型。所以本文認為在謠言檢測當中,卷積神經網絡模型是通過謠言事件中發現微博之間的關系來構造特征,而循環神經網絡則是通過謠言事件中所有詞之間的關系來構造特征,對于謠言而說,由于其傳播方式等的特點,本文認為按照相關微博來構造特征比按照詞來構造特征更合理,所以認為卷積神經網絡模型優于循環神經網絡模型。
綜上所述,本文認為就謠言檢測而言,模型自構建特征優于人工構建特征,卷積神經網絡模型優于循環神經網絡模型。
此外,本文將訓練集與測試集按照9∶1的分割比例進行了同樣的實驗,如表3所示。從表3中可以看出按照9∶1的分割比例時,訓練的模型實驗結果略好于按照3∶1進行分割的模型。
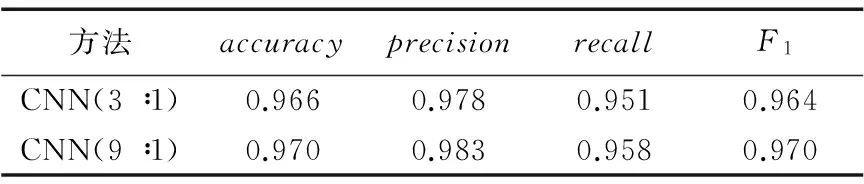
表3 CNN模型不同分割比例之間的結果比較Tab.3 Rusult comparison of CNN models with different split ratios
本文通過劉知遠等[18]的工作了解到,新浪微博中一般人工檢測并確認謠言的時間周期大約在一周左右,圖6是本文的CNN模型訓練過程中的收斂情況,其中實線表示在訓練集中的收斂情況,點線表示在測試集上的收斂情況。從圖中可以看出模型收斂的速度非常快,當訓練到達10 000步時,模型的準確率就已經達到了94.47%,這也正好彌補了人工檢測微博謠言存在較長時間的延遲問題。
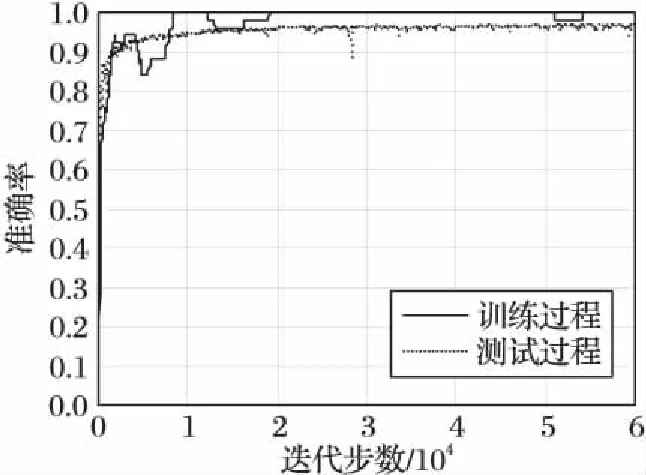
圖6 CNN模型訓練過程Fig. 6 CNN model training process
3 結語
目前在大多數謠言檢測任務中,都是采用人工構建特征的方式,本文提出將卷積神經網絡模型應用于謠言檢測中,從實驗中得出本文的模型優于目前最好的謠言檢測方法,準確率及F1值均高出5%左右。如何將謠言事件下的用戶評價信息加入,以及如何進行卷積神經網絡的層數的選取,將是接下來進一步的研究工作。
References)
[1] 李洋,陳毅恒,劉挺.微博信息傳播預測研究綜述[J].軟件學報,2016,27(2):247-263.(LI Y, CHEN Y H, LIU T. Survey on predicting information propagation in microblogs[J]. Journal of Software, 2016,27(2):247-263)
[2] CASTILLO C, MENDOZA M, POBLETE B. Information credibility on twitter[C]// Proceedings of the 20th International Conference on World Wide Web. New York: ACM, 2011: 675-684.
[3] KWON S, CHA M, JUNG K, et al. Prominent features of rumor propagation in online social media[C]// Proceedings of the 2013 IEEE 13th International Conference on Data Mining. Piscataway, NJ: IEEE, 2013: 1103-1108.
[4] MA J, GAO W, WEI Z, et al. Detect rumors using time series of social context information on microblogging websites[C]// Proceedings of the 24th ACM International on Conference on Information and Knowledge Management. New York: ACM, 2015: 1751-1754.
[5] ZHAO Z, RESNICK P, MEI Q. Enquiring minds: early detection of rumors in social media from enquiry posts[C]// Proceedings of the 24th International Conference on World Wide Web. New York: ACM, 2015: 1395-1405.
[6] MA J, GAO W, MITRA P, et al. Detecting rumors from microblogs with recurrent neural networks[C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence. San Francisco, CA: Morgan Kaufmann, 2016: 3818-3824.
[7] 李彥冬, 郝宗波, 雷航. 卷積神經網絡研究綜述[J]. 計算機應用, 2016, 36(9): 2508-2515.(LI Y D, HAO Z B, LEI H. Survey of convolutional neural network[J]. Journal of Computer Applications, 2016, 36(9): 2508-2515.)
[8] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[C]// Proceedings of the 25th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press,2012: 1097-1105.
[9] DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2009: 248-255.
[10] DONAHUE J, HENDRICKS L A, GUADARRAMA S, et al. Long-term recurrent convolutional networks for visual recognition and description[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE,2015: 2625-2634.
[11] VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: a neural image caption generator[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 3156-3164.
[12] YIH W, HE X, MEEK C. Semantic parsing for single-relation question answering[C]// Proceedings of the 2014 Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2014: 643-648.
[13] SHEN Y, HE X, GAO J, et al. Learning semantic representations using convolutional neural networks for Web search[C]// Proceedings of the 23rd International Conference on World Wide Web. New York: ACM, 2014: 373-374.
[14] KIM Y. Convolutional neural networks for sentence classification[EB/OL].[2016- 11- 20]. http://www.aclweb.org/anthology/D14- 1181.pdf.
[15] KALCHBRENNER N, GREFENSTETTE E, BLUNSOM P. A convolutional neural network for modelling sentences[EB/OL].[2016- 11- 20].http://anthology.aclweb.org/P/P14/P14-1062.pdf.
[16] COLLOBERT R, WESTON J. A unified architecture for natural language processing: deep neural networks with multitask learning[C]// Proceedings of the 25th International Conference on Machine Learning. New York: ACM, 2008: 160-167.
[17] COLLOBERT R, WESTON J, KARLEN M, et al. Natural language processing (almost) from scratch[J]. Journal of Machine Learning Research, 2011, 12(1):2493-2537.
[18] 劉知遠, 張樂, 涂存超, 等. 中文社交媒體謠言統計語義分析[J]. 中國科學: 信息科學, 2015, 45(12):1536-1546.(LIU Z Y, ZHANG L, TU C C, et al. Statistical and semantic analysis of rumors in Chinese social media[J]. Scientia China: Informationis Sciences, 2015, 45(12):1536-1546.)
This work is partially supported by the National Natural Science Foundation of China (61573259, 61673301, 61573255, 61673299), the Program of Further Accelerating the Development of Chinese Medicine Three Year Action of Shanghai (ZY3-CCCX-3-6002), the Natural Science Foundation of Shanghai (15ZR1443800).
LIUZheng, born in 1992, M. S. candidate. His research interests include natural language processing.
WEIZhihua, born in 1979, Ph. D., associate professor. Her research interests include machine learning, text mining, image content analysis.
ZHANGRenxian, born in 1976, Ph. D., associate professor. His research interests include natural language processing, social networking, data mining.
Rumordetectionbasedonconvolutionalneuralnetwork
LIU Zheng1,2, WEI Zhihua1,2*, ZHANG Renxian1,2
(1.DepartmentofComputerScienceandTechnology,TongjiUniversity,Shanghai201804,China;2.KeyLaboratoryofEmbeddedSystemandServiceComputingofMinistryofEducation(TongjiUniversity),Shanghai201804,China)
Manual rumor detection often consumes a lot of manpower and material resources, and there will be a long detection delay. At present, the existing rumor detection models construct features manually according to the content, user attributes, and pattern of the rumor transmission, which can not avoid one-sided consideration, waste of human and other phenomena. To solve this problem, a rumor detection model based on Convolutional Neural Network (CNN) was presented. The rumor events in microblog were vectorized. The deep features of text were mined through the learning and training in hidden layer of CNN to avoid the problem of feature construction, and those features that were not easily found could be found to produce better results. The experimental results show that the proposed method can accurately identify rumor events, and it is better than Support Vector Machine (SVM), Recurrent Neural Network (RNN) and other contrast algorithms in accuracy rate, precision rate and F1 score.
microblog; rumor detection; rumor event; Convolution Neural Network (CNN)
2017- 05- 16;
2017- 06- 05。
國家自然科學基金資助項目(61573259, 61673301, 61573255, 61673299);上海市中醫藥三年行動計劃重點項目(ZY3-CCCX- 3- 6002);上海自然科學基金資助項目(15ZR1443800)。
劉政(1992—),男,山東濟南人,碩士研究生,CCF會員,主要研究方向:自然語言處理; 衛志華(1979—),女,山西晉中人,副教授,博士,CCF會員,主要研究方向:機器學習、文本挖掘、圖像內容分析; 張韌弦(1976—),男,浙江鄞縣人,副教授,博士,主要研究方向:自然語言處理、社交網絡、數據挖掘。
1001- 9081(2017)11- 3053- 04
10.11772/j.issn.1001- 9081.2017.11.3053
(*通信作者電子郵箱zhihua_wei@tongji.edu.cn)
TP391.41
A
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
