Hadoop技術在云數據中心的應用研究
2018-01-08 06:51:23李自尊馮建湯進
河南科技 2017年21期
李自尊 馮建 湯進
(黃委會信息中心數據中心,河南 鄭州 450000)
Hadoop技術在云數據中心的應用研究
李自尊 馮建 湯進
(黃委會信息中心數據中心,河南 鄭州 450000)
針對大數據時代如何存儲、處理、分析、利用海量的電子數據,以及傳統數據中心向云數據中心轉型進程中大量服務器被閑置的問題,對Hadoop家族中的關鍵技術HDFS、MapReduce、Mahout進行深入研究,并在此基礎上提出了基于云平臺的Hadoop集群應用研究方案。方案包括Hadoop集群拓撲結構、開發運行環境部署流程及基于Hadoop集群的Mahout中貝葉斯分類算法的實現。實驗作為整合數據中心資源進行規模部署Hadoop集群的研究基礎,證明了Hadoop集群的可用性及其在數據分析方面良好的適應性。
Hadoop;云數據中心;Mahout;貝葉斯
1 研究背景
隨著大數據時代的到來,如何存儲、處理、分析、利用海量的電子數據,成為各個行業亟待解決的問題。Ha?doop是由Apache基金會開發的一個開源分布式系統的基礎架構,提供用于構建分布式系統的數據存儲、數據分析及協調處理工具,在大數據分析領域應用廣泛,已經積累了大量用戶[1]。國內外知名企業如Google、Facebook、eBay、百度及阿里巴巴等,都基于Hadoop進行數據挖掘和分析,許多高校和研究機構也將Hadoop應用到教學、實驗和研究中[2]。
云數據中心采用云計算理念和虛擬化技術,集成整合數據中心現有基礎資源,構建存儲備份資源池、計算資源池,對資源統一管理、調配,具有高效、高可用及彈性部署等特點。傳統數據中心向云數據中心轉型的過程中,業務系統逐步由單臺獨立的服務器遷移至云平臺,而這會導致大量的服務器閑置。整合舊有服務器,部署Ha?doop集群環境,可以有效利舊原有設備資源,實現資源的綠色循環使用[3]。
本文通過對Hadoop框架構建技術進行研究,綜合利用數據中心云平臺高效、彈性的特點,從研究實驗的角度搭建基于云平臺的Hadoop分布式運行環境,并開展基于機器學習算法的數據分析研究,同時基于桌面云服務,提供開發環境的快速部署,作為整合數據中心資源進行規模部署Hadoop集群的研究基礎。
2 Hadoop關鍵技術
Hadoop作為開源的分布式系統基礎架構,主要由分布式存儲(HDFS)、分布式計算(MapReduce)等組成。用戶可以在不了解Hadoop框架底層細節的情況下,利用Hadoop框架來開發分布式程序,適用于擁有大量計算機且偶爾有大量數據需要存儲、分析的場景。
Hadoop已經發展成為包含很多項目的集合,雖然核心項目是HDFS和MapReduce,但與Hadoop相關的HBase、Pig、Hive、ChuKwa、Zookeeper等項目也是不可或缺的。它們提供了互補性服務或在核心層上提供了更高層的服務[4]。
2.1 HDFS
Hadoop由許多不同的文件系統組合而成,它提供了文件系統實現的各類接口,HDFS是眾多文件系統中應用最多的一個文件系統實例,是分布式計算的存儲基石。HDFS支持數據密級型分布式應用,采用主從(Master/Slave)結構模型,由一個命名節點NameNode和若干個數據節點DataNode組成。NameNode作為主服務器,管理文件系統命名空間和客戶端訪問,如打開、關閉、重命名文件或目錄等,以及數據塊到具體DataNode的映射;DataNode負責進行數據存儲的同時,還負責響應客戶端的讀寫請求,并在NameNode的統一調度下進行數據塊的創建、刪除和復制工作。從內部來看,文件被分成若干個數據塊(默認為64MB),而且放在一組DataNode上,由Na?meNode維護文件的元數據信息,具體如圖1所示[5,6]。
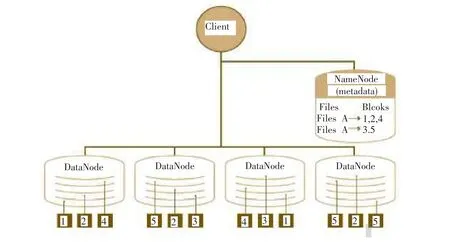
圖1 HDFS數據存儲示例
2.2 MapReduce
MapReduce是一種編程模型,用于大規模數據集的并行運算。Map(映射)和Reduce(化簡),采用分而治之思想,先把任務分發到集群中的多個節點上,執行并行計算,然后再把計算結果合并,從而得到最終結果。多節點計算,涉及的任務調度、負載均衡、容錯處理等,都由MapReduce框架完成。
Map和Reduce函數的輸入輸出都是鍵(key)-值(value)對的形式,而Map的輸出就是Reduce的輸入。Map中輸出的鍵值對中所有鍵相同的值都會傳遞給同一個Reduce進行處理,Reduce將輸入的鍵-值對轉化合并為規模更小的鍵-值對組合[5,6]。
MapReduce計算模型如圖2所示。
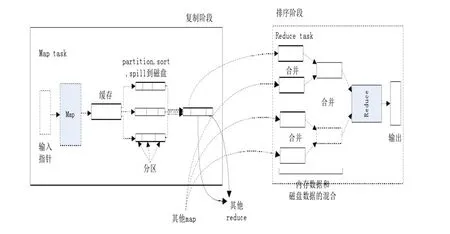
圖2 MapReduce計算模型
2.3 Mahout
Mahout是一個強大的數據挖掘工具,其主要目標是建立可伸縮的機器學習算法,最大的優點就是基于Ha?doop實現,把很多以前運行于單機上的算法轉化為MapReduce模式,大大提升了算法可處理的數據量和處理性能。目前,Mahout項目主要包括以下五部分[7,8]。①推薦引擎(協同過濾):獲得用戶的行為并從中發現用戶可能喜歡的事務;②聚類:將諸如文本、文檔之類的數據分成局部相關的組;③分類:利用已經存在的分類文檔訓練分類器,對未分類的文檔進行分類;④頻繁模式挖掘:挖掘數據中頻繁出現的項集;⑤頻繁子項挖掘:利用一個項集(查詢記錄或購物目錄)去識別經常一起出現的項目。
3 基于云平臺的Hadoop技術應用研究
3.1 基于云平臺的Hadoop集群拓撲結構
云數據中心的建設采用虛擬化技術和云平臺管理理念,新增必需的高性能資源池服務器及共享存儲,集成整合數據中心現有基礎資源,構建存儲備份資源池、計算資源池,實現了物理資源的整合共享、靈活管理,方便了應用系統的部署,同時避免了業務重復建設造成的資源浪費,提高了服務器、存儲的復用率。
在對傳統數據中心進行云化改造的過程中,原有系統從舊有X86服務器逐步遷移至云平臺,傳統業務區將有大量的舊有X86服務器被閑置。Hadoop集群由于其內部冗余及高可靠性的工作機制,可以部署在任意數臺普通的X86服務器中,因此,整合舊有X86服務器,部署Ha?doop集群環境,為偶爾需要進行大數據量的分析提供分布式平臺,可以有效利舊原有設備資源,實現資源的綠色循環使用。
在進行研究階段,借助云平臺高效、彈性等特點,在云上部署Hadoop集群進行初步探索。同時,利用云平臺的基于模板快速部署開發環境的特點,可以將配置復雜的Hadoop開發運行環境制作成模板,便捷發布,提高實驗及開發效率。
3.2 Hadoop集群搭建
3.2.1 環境配置。①硬件環境配置:部署3個節點Hadoop集群開展實驗研究,開通3臺虛擬服務器,配置均為vCPU4個,內存8G,磁盤200G。②網絡環境配置:Mas?ter作為NameNode、ResourceManager;Node1及Node2作為DataNode、NodeManager;3個節點的IP均在10.4.234.xx網段。③軟件環境配置(見表1)。

表1 軟件配置表
3.2.2 Hadoop開發運行環境部署流程。Hadoop開發運行環境搭建主要包括4部分內容,即軟硬件環境準備、Hadoop集群部署、開發環境配置及Mahout模塊配置,具體流程如圖3所示。
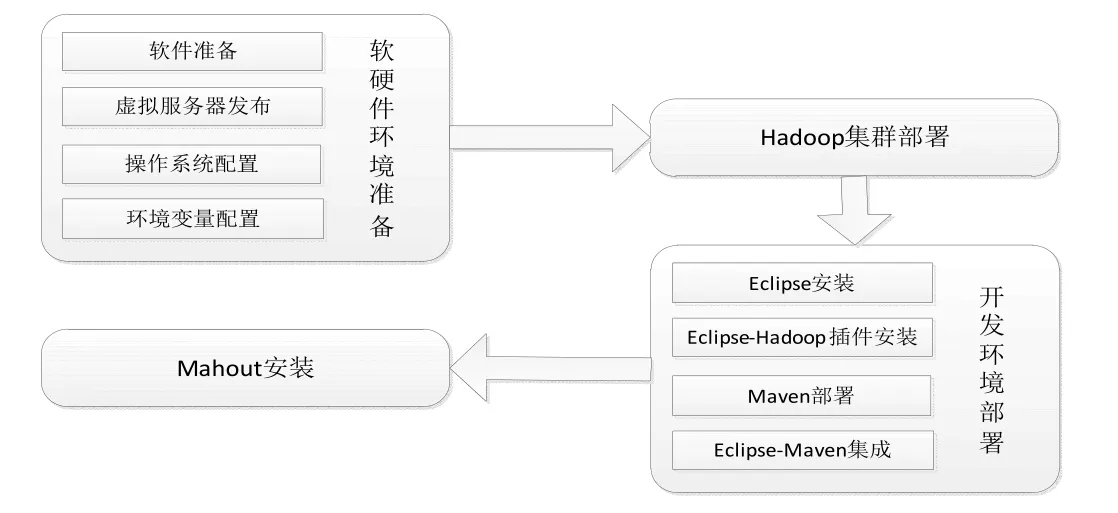
圖3 Hadoop開發運行環境部署流程圖
3.2.3 Hadoop集群部署。Hadoop集群的配置過程主要包括三個步驟:前期環境準備、Hadoop集群軟件安裝、安裝效果驗證。前期環境準備工作包括服務器防火墻設置、network及hosts文件配置及SSH配置;Hadoop集群軟件安裝工作包括Hadoop主節點軟件部署、配置文件修改及從節點配置同步分發;安裝效果驗證工作包括Ha?doop集群初始化、集群啟動、進程和管理界面檢查及任務執行。
在部署過程中,需要修改的配置文件主要有5個,分別為:①hadoop-env.sh配置,指定JDK的安裝位置;②core-site.xml:Hadoop核心的配置文件,配置HDFS的地址及端口號;③hdfs-site.xml:HDFS配置,配置副本數為2份;④mapred-site.xml:MapReduce配置文件,配置Job?tracker的地址及端口號;⑤yarn-site.xml:yarn配置文件,配置yarn進行資源管理調度的地址及端口號。
3.3 Hadoop技術應用
3.3.1 樸素貝葉斯算法實現。樸素貝葉斯算法是基于貝葉斯定理與特征條件獨立假設的分類方法,其分類的思想基礎是:對于給出的待分類項,求解在此項出現的條件下各個類別出現的概率哪個最大,就認為此待分類項屬于哪個類別[9,10]。
本實驗以20NewsGroup為例,針對文檔分類的具體問題,在Hadoop集群上運行Mahout中的樸素貝葉斯算法,實現對文檔分類模型的訓練,并測試模型分類的效果。
20NewsGroup包含了被分成20個新聞組的20 000個新聞組文檔,20個新聞組按照20個不同的類型進行組織,不同的類對應不同的主題。其中,60%用來進行訓練貝葉斯分類算法,40%用來測試分類模型。具體實驗流程如圖4所示。
第一,準備數據,并將數據上傳至HDFS。
//解壓后得到20news-bydate-train和20news-bydatetest兩個文件夾,上傳至HDFS;
#tar-zvxf 20news-bydate.tar.gz.
#hdfs dfs-put 20news-bydate-train.
#hdfs dfs-put 20news-bydate-test.
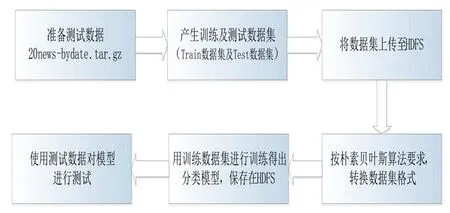
圖4 基于Hadoop集群的文檔分類流程圖
第二,轉換數據集格式。
//轉換為序列文件(sequence files)
#mahoutseqdirectory-i20news-bydate-train-o 20news-bydate-train-seq
#mahoutseqdirectory-i20news-bydate-test-o 20news-bydate-test-seq
//轉換為tf-idf向量
#mahoutseq2sparse-i20news-bydate-train-seqo 20news-bydate-train-vector-lnorm-nv-wt tfidf
#mahoutseq2sparse-i20news-bydate-test-seq-o 20news-bydate-test-vector-lnorm-nv-wt tfidf
第三,訓練樸素貝葉斯模型。
#mahouttrainnb-i20news-bydate-train-vector/tfidf-vectors-o model-li labelindex-ow.
第四,測試樸素貝葉斯模型。
#mahout testnb-i 20news-bydate-train-vector/tfidfvectors-m model-l labelindex-ow-o test-result.
3.3.2 結果分析。通過上述實驗,基于Hadoop集群運行Mahout中的貝葉斯算法對文檔進行分類,生成分類結果向量模型表,并得到分類結果的準確率及標準差。可見,在云平臺環境中的Hadoop集群搭建成功,可以進行數據的分布式存儲及并行計算,同時對機器學習算法具有良好的兼容性。
4 結論
本文提出了一種基于云平臺搭建Hadoop集群進行實驗研究的方法,通過采用虛擬化技術和云平臺管理理念,快速部署Hadoop集群運行開發環境,并采用其家族成員Mahout中的機器學習算法,構建文檔分類模型,對基于Hadoop集群的數據分析模式進行研究,是整合數據中心資源進行規模部署Hadoop集群的有效探索途徑。
[1] 王偉,陶然.基于虛擬化技術的Hadoop集群搭建與應用[J].軟件導刊,2016(4):50.
[2] 牛怡晗,海沫.Hadoop平臺下Mahout聚類算法的比較研究[J].計算機科學,2015(6A):465.
[3] 李自尊,馮建,湯進.基于虛擬化技術的云數據中心基礎設施規劃方案[J].河南科技,2015(3):1.
[4] 費珊珊.基于云計算Hadoop平臺的數據挖掘研究[D].北京:北京郵電大學,2013.
[5] 道客巴巴.基于Hadoop的大數據應用分析[EB/OL].(2016-04-02)[2017-10-09].http://www.docin.com/p-1514875735.html.
[6] Tom White.Hadoop權威指南[M].北京:清華大學出版社,2015.
[7] 陸嘉恒.Hadoop實戰[M].北京:機械工業出版社,2012.
[8] Naive Bayes[EB/OL].[2017-10-09].http://mahout.apache.org/users/classification/bayesian.html.
[9] 王慧.基于Hadoop的并行挖掘算法的研究[D].北京:首都師范大學,2013.
[10] 曾宇平,徐飛龍.基于Hadoop的分布式樸素貝葉斯智能診斷系統[J].醫學信息學雜志,2015(7):53.
The Hadoop Technology Application Research on Cloud Data Center
Li ZizunFeng JianTang Jin
(Data Center,The Yellow River Conservancy Commission Information Center,Zhengzhou Henan 450000)
To solve the issues of how to store,process,analyze and utilize the vast amount of electronic da?ta in the big data era,and utilize the large number of servers in the transition process of traditional data center to cloud data center,the article advanced a set of Hadoop cluster application research scheme based on cloud platform through in-depth study of the key technologies of HDFS,MapReduce,Mahout in the Hadoop family.The scheme includes the topology of the Hadoop cluster,the development process of development and operating environment,and the implementation of the bayesian classification algorithm in Mahout based on Hadoop cluster.
Hadoop;cloud data center;Mahout;bayesian algorithm
TP311.13
A
1003-5168(2017)11-0025-04
2017-10-09
李自尊(1990-),女,碩士,工程師,研究方向:數據中心運維管理。
猜你喜歡
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中國生殖健康(2020年6期)2020-02-01 06:28:50
新世紀智能(英語備考)(2019年12期)2020-01-13 06:07:18
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中國生殖健康(2019年11期)2019-01-07 01:28:02
中國生殖健康(2018年6期)2018-11-06 07:09:28
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
